はじめに
前回、HerokuのDBについての記事を書いてみました。
その後、Heroku上のDBをバックアップしたい、さらに別の再現環境やテスト環境のDBにデータを流し込みたい...といったことも出てきました。
今回は、この方法について紹介してみます。
(基本はHerokuの公式サイトにある情報が中心です)
やりたいのはこんなこと
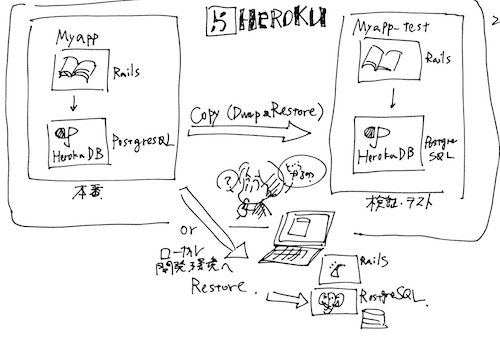
はじめる前の注意点
DBのバックアップは意外と簡単です。
逆に、リストアの方が難しかったり、想定外のことが起きやすかったりします。
-
リストアについての注意
-
この記事を読んで試してみようかな...と思った場合は、特にリストアについてはご注意を。
-
いきなり本番や重要なアプリケーション / データベースに対しては行わず、必ず練習をしてどういう指定、どういう仕組みでリストアされるのかを確認してください。
-
バックアップについての注意
-
バックアップについては、重要な情報が含まれるケースやアプリケーションでの暗号化がされていない場合は注意してください!
-
Heroku側でのバックアップデータがどこに置かれるかについても触れていますので、管理方法や取得だけでなく削除のスケジュールも考慮するといいと思います。
プランを確認しておきましょう
DBのバックアップは、ご利用のプランに関わらず実施できます。
実際はHerokuのアプリケーションではなく、DB側のプランでチェックします。
プランの差で変わってくるのは、HerokuのDBにリストアする際のオプションや、レプリケーションが作成できるかといった点になります。
バックアップしてみよう!
standard / hobby (無償プラン)どちらでもバックアップ方法は同じです。
さらに、管理画面とCLIから、以下のように取得できます。
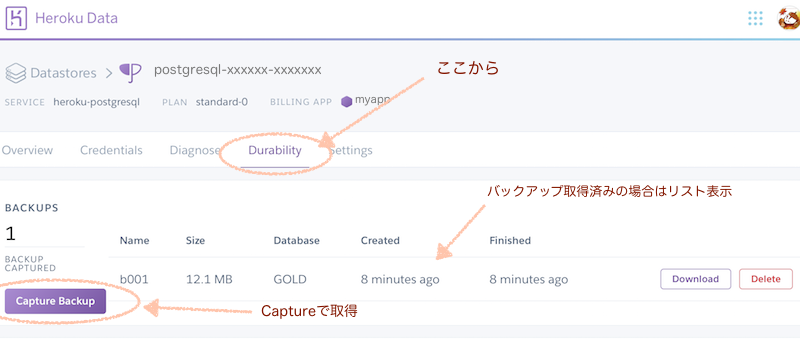
管理画面からのバックアップ
管理画面からのバックアップも、結果自体はCLIと変わりません。
- 違いはバックアップデータの保存期間になります
- データはs3にダンプされます
- heroku cliでコマンドラインからでもバックアップ取得ができます
- 画面からは Durability のタブから実施できます
Heroku CLIを使ってバックアップ
heroku cliを使うと、コマンドラインからバックアップの取得が出来ます。
また、バックアップの一覧も確認できます。
# コマンドラインツールのバージョンの確認
$ heroku version
heroku-cli/6.15.31-958455a (darwin-x64) node-v9.7.1
バックアップ済みの一覧の確認
- heroku pg:backups で取得済みのバックアップの一覧が表示されます
- heroku pg:backups:capture --app アプリケーション名で、バックアップを実行します
- 実行したバックアップは s3 上に配置されます
# アプリケーション名 = myappの例
$ heroku pg:backups -a myapp
=== Backups
ID Created at Status Size Database
──── ───────────────────────── ─────────────────────────────────── ─────── ────────
a061 2018-03-22 17:04:23 +0000 Completed 2018-03-22 17:04:49 +0000 18.54MB GOLD
a060 2018-03-21 17:02:52 +0000 Completed 2018-03-21 17:03:21 +0000 18.41MB GOLD
a059 2018-03-20 17:02:35 +0000 Completed 2018-03-20 17:03:00 +0000 18.29MB GOLD
=== Restores
No restores found. Use heroku pg:backups:restore to restore a backup
=== Copies
No copies found. Use heroku pg:copy to copy a database to another
バックアップの実施
バックアップの取得は、 heroku pg:backups capture --app アプリケーション名 で実行します。
上記の管理画面に対応するアプリケーション(アプリケーション名 = myapp) を例にすると、
$ heroku pg:backups capture --app myapp
となります。
$ heroku pg:backups:capture --app myapp
▸ Continuous protection is already enabled for this database. Logical backups of large databases are likely to fail.
▸ See https://devcenter.heroku.com/articles/heroku-postgres-data-safety-and-continuous-protection#physical-backups-on-heroku-postgres.
Starting backup of postgresql-xxxxx-xxxx... done
Use Ctrl-C at any time to stop monitoring progress; the backup will continue running.
Use heroku pg:backups:info to check progress.
Stop a running backup with heroku pg:backups:cancel.
Backing up GOLD to b063... done
取得したバックアップの確認は、再び heroku pg:backups -a アプリケーション名 で確認できます
バックアップデータのダウンロード
管理画面から
管理画面からバックアップの一覧、ダウンロードが可能です。
heroku pg:backups:downloadから
コマンドラインからは、heroku pg:backups:download で手元にダウンロードできます。
- アプリケーション名、バックアップIDを指定します
- デフォルトでは、latest.dump というファイル名でダウンロードされます
$ heroku pg:backups:download b063 -a myapp --help
Usage: heroku pg:backups:download [BACKUP_ID] [flags]
downloads database backup
Flags:
-a, --app APP app to run command against
-o, --output OUTPUT location to download to. Defaults to latest.dump
-r, --remote REMOTE git remote of app to use
実際に試してみます。
所得したファイルは、確かにPostgreSQLのdump形式のファイルになっているようです。
$ heroku pg:backups:download b063 -a myapp
Getting backup from ⬢ myapp... done, #63
Downloading latest.dump... ████████████████████████▏ 100% 00:00 1.05MB
$ tree
.
└── latest.dump
0 directories, 1 file
$ file latest.dump
latest.dump: PostgreSQL custom database dump - v1.13-0
URLを取得してcurlから
heroku pg:backups:url コマンドを使うと、s3のデータを取得するためのURLが表示されます。デフォルトでは最新のバックアップのURLを返します。
- このURLはパブリックアクセス可能なので、漏洩しないように注意!
- urlを取得したら、curlなどのAgentでのダウンロードが可能です
$ heroku pg:backups:url --app myapp
https://xxxx.s3.amazonaws.com/とっても長いパブリックアクセス可能なURL
バックアップデータの情報
heroku pg:backups:infoでは、指定したバックアップデータの詳細情報がチェックできます。
こちらには、バックアップにかかった時間、データサイズが表示されます。
$ heroku pg:backups:info b063 -a myapp
=== Backup b063
Database: GOLD
Started at: 2018-03-23 23:04:34 +0000
Finished at: 2018-03-23 23:04:36 +0000
Status: Completed
Type: Manual
Original DB Size: xxx.83MB
Backup Size: xx.05MB (xx% compression)
=== Backup Logs
2018-03-23 23:04:35 +0000 pg_dump: last built-in OID is 16383
2018-03-23 23:04:35 +0000 pg_dump: reading extensions
2018-03-23 23:04:35 +0000 pg_dump: identifying extension members
2018-03-23 23:04:35 +0000 pg_dump: reading schemas
-- [Snip] ---
2018-03-23 23:04:39 +0000 waiting for pg_dump to complete
2018-03-23 23:04:39 +0000 pg_dump finished successfully
バックアップの定期実行
herokuのDBは、どのプランでもバックアップの定期実行が可能です。
公式サイトの情報はこちら。
定期実行になっているかどうかは、pg:backups:schedules で確認できます。(管理画面からは、20180324時点で、定期実行の設定や確認はできない?みたい)
まずは、毎日2時にバックアップされるように設定してみます。
$ heroku pg:backups schedule DATABASE_URL --at '02:00 Asia/Tokyo' --app myapp
Scheduling automatic daily backups of postgresql-xxxx-xxx at 02:00 Asia/Tokyo... done
設定できているか、heroku pg:backups:schedules で確認してみます。
$ heroku pg:backups:schedules -a myapp
=== Backup Schedules
DATABASE_URL: daily at 2:00 Asia/Tokyo
pg_dumpを使ってローカル開発環境からバックアップ
heroku CLIではなくとも、pg_dumpコマンドでも、もちろんデータのバックアップ(ダンプ)は可能です。
この場合は、heroku pg:credentials:url や、管理画面から接続情報を取得して、お手元の環境(私の場合はMac)から、pg_dumpコマンドを使って取得すればOKです。
- 接続情報の取得はこちらにも書きました
$ heroku pg:credentials:url --app アプリケーション名
Connection information for default credential.
Connection info string:
"dbname=xxxxxx host=ec2-xxxxxx.amazonaws.com port=5432 user=xxxxx password=xxxxxx sslmode=require"
Connection URL:
postgres://ユーザ名:パスワード@ホスト名:5432/データベース名
pg_dumpは、そのままだと標準出力に表示されますので、書き込み先を指定して取得してみます。
サイズが大きいと困るので、schema-only オプションを付けてみます。
$ pg_dump -d データベース名 -h ec2-xxxxxx.amazonaws.com -U ユーザ名 \
--schema-only -W > database.dump
Password:
# ファイルタイプの確認
$ file database.dump
database.dump: ASCII text
# 中身をチェックします
$ head database.dump
--
-- PostgreSQL database dump
--
-- Dumped from database version 9.6.1
-- Dumped by pg_dump version 10.1
SET statement_timeout = 0;
SET lock_timeout = 0;
-- [ 以下略 ] ---
バックアップデータの違いについて
上記でheroku cliとpg_dumpを使った2パターンのバックアップを取得してみました。
その際に、fileコマンドでファイルのタイプを確認してみました。
-
heroku pg:backups:captureで取得
-
バイナリ形式 (binary compressed)でダンプされる
-
細かいオプション指定ができない
-
全部ダンプのため、場合によってはファイルのサイズが大きくなる
-
データはまずs3に格納される(サイズが大きい場合はこの方が安心かも)
-
インデックス情報も含まれるが、基本はインデックス再設定
-
pg_dumpで取得
-
フォーマットは指定可能(デフォルトでtext)
-
スキーマのダンプだけのような細かいオプション指定が可能
-
データはローカルに書き出し
ダンプからリストアして、環境を再現したいけど、一部書き換えてから流し込みたい...といった場合は、pg_dumpでテキスト出力して、データを書き換えてからリストア、といったこともできるので、この辺りは使い分けになります。
リストアしてみよう!
ではリストアです。
可能なら、お手元のローカル開発環境に空っぽのPostgreSQLのデータベースを作成しておいたり、空っぽのherokuアプリケーションを用意しておいてください。
いきなり本番のDBのダンプ -> 本番のDBへのリストアといったことは行わず、確認を踏んでから進めてみてください。
heroku cliでのバックアップをローカルのDBにリストア
自分でpg_dumpを使った場合は、通常のPostgreSQLのバックアップ・リストアと変わりません。
heroku cliでのバックアップ(latest.dump) の場合は、バイナリ形式なので、以下の公式サイトの手順に従って、自身のローカル開発環境やHeroku PostgreSQL以外のDBにリストアできます。
- 参考: Importing and Exporting Heroku Postgres Databases with PG Backups
- Heroku PostgresのDBをローカルにコピーする方法 (tarotさま)
- バイナリ形式なので、psql < xxxxxx ではなく、pg_restore を利用します
# exp.
$ pg_restore --verbose --clean --no-acl --no-owner -h DBホスト -d ローカルのDB latest.dump
なお、からっぽのDBに対してのリストアが前提になりますので、注意してください。
他のHerokuアプリケーションにリストアする
heroku上に、検証用のほぼ同じアプリケーションがデプロイされていて、そこにバックアップしたデータを流し込みたい...といったケースもあるかもしれませんね。
(本番用: myapp に対し、検証用: myapp-test とします)
この場合は、一旦取得してs3に上がっているバックアップで最新のものを、heroku pg:backups:restore のオプションで検証用のアプリケーションのDBに流し込むことができます。
# 1. バックアップ取得
$ heroku pg:backups:capture --app myapp
# 2. 検証用アプリケーション側にリストア
$ heroku pg:backups:restore `heroku pg:backups public-url --app myapp` \
--app myapp-test
- 1の作業でバックアップを取ります
- 2の作業で、
heroku pg:backups public-url --app myappのところが、「myappの最新のバックアップのs3上のurl」を取得し、これをソースファイルとしてherokt pg:backups:restoreに渡しています - バックアップ用のデータのURLは、もちろん変更可能です
バックアップ & 他のHerokuアプリケーションに一気にリストアする
上記は一旦バックアップを取得し、その後でリストアを実施しました。
本番の動作に問題がなさそうなら、以下のように、一度にバックアップ & 他のHerokuアプリケーションに一気にリストアすることも可能です。
- 参考: 公式サイト/ Direct database-to-database copies
- heroku pg:copy を利用します
- DATABASE_URLは、herokuのアプリケーションの環境変数です(このままでOK!)
- DATABASE_URLはデフォルトでherokuアプリケーション作成時に割当たるDBのURLです
$ heroku pg:copy コピー元のアプリケーション::DATABASE_URL DATABASE_URL -a コピー先のアプリケーション
$ heroku pg:copy myapp::DATABASE_URL DATABASE_URL -a myapp-test
▸ WARNING: Destructive action
▸ This command will remove all data from DATABASE
▸ Data from DATABASE will then be transferred to DATABASE
▸ To proceed, type myapp-test
▸ WARNING: Destructive action or re-run this command with --confirm myapp-test
> myapp-test
Starting copy of DATABASE to DATABASE... done
Copying... done
上記のコマンドでは、このような処理を行います。
- myappのアプリケーションのSettings -> 環境変数DATABASE_URLに指定があるDBからダンプ
- myapp-testのアプリケーションのSettings -> 環境変数DATABASE_URLに指定があるDBにリストア
コマンドラインの中で、DATABASE_URLになにか値をセットする必要はありません。
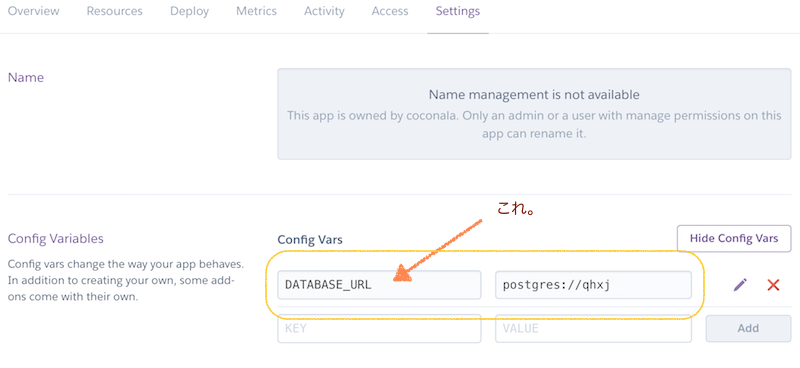
また、公式サイトの例ではこのようになっていますので、少し補足してみます。
heroku pg:copy COBALT GREEN --app sushi
This would copy all data from the COBALT database to the GREEN database in the sushi app.
この場合は、sushiというアプリケーションで、COBALTという環境変数名で指定されているデータベースから、
GREENという名前の環境変数で指定されているデータベースへバックアップ -> リストアします。
$ heroku pg:copy sushi::ORANGE GREEN --app sushi-staging
You can also transfer directly from a database on another app:
This would copy data from the ORANGE database of the sushi app to the GREEN database in sushi-staging. This could be used to copy production data into a staging app for testing purposes.
この場合は、sushiというアプリケーションで、ORANGEという環境変数名で指定されているデータベースから、
sushi-stagingというアプリケーションのGREENという名前の環境変数で指定されているデータベースへ
バックアップ -> リストアします。
本番環境からステージング・検証環境のアプリケーションへデータをコピーするような場合に利用します。
デフォルトではHerokuのアプリケーションは、環境変数: DATABASE_URLに設定された値をDBとして利用しますが、任意の環境変数を設定して、切り替えたりすることも可能です。
(参考: Rails4.1以上の場合)
なお、本番のDBは有償プラン、コピーする先のアプリケーションのDBは無償プランという場合でも、リストア自体は可能ですが、無償プランには行数の制限があるので、制限の行数を超えるとリストアしてもReadOnlyになってしまいます。
参考:フォロワーデータベースについて
HerokuのPostgreSQLは、デフォルトではバックアップ設定はされていません。
バックアップの世代保持や保持期間は、プランによって制限がありますが、できれば毎日定期バックアップを設定しておくといいかと思います。
このほかに、Standardプラン以上 になると、フォロワーデータベースというものが利用できます。
こちらは、いわゆるRead Onlyのレプリカを用意する形になります。
ただし、本番利用のデータベースの規模(プラン)に応じたプランで、もう1つDBを立ち上げることになるので、課金が倍になります。
-
参考: (Creating and Managing Heroku Postgres Follower Databases)[https://devcenter.heroku.com/articles/heroku-postgres-follower-databases]
-
本番がわDBに障害があった場合には、勝手には切り替わりません
-
オペミスでの論理データ破壊は、同じように同期されますので、やはりバックアップも必要です...
まとめ
以上、HerokuのDBのバックアップ&リストアについて触れてみました。
基本はs3 / ec2といったAWSを裏側のプラットフォームとして使っています。アプリケーションだけでなく、少しだけインフラ側に目を向けてみると、面白い発見があるかもしれません。
また、本番稼動して、実データがたまってくると、そこからしか分からない / 開発段階では見えてこなかった点も出てきます。
最初に触れてた通り、バックアップデータの扱い / リストア作業いずれも注意しつつ、うまくデータを利用して、アプリケーションを改善できたらいいなと思っています。
※誤字や不備な点かありましたら、ご指摘いただけますと幸いです!