はじめに
クエリプランというプレビュー機能があるので、それを触ってみることでクエリフォールディングの勉強をしてみました。
PBIJP Power Query 秘密特訓「虎の穴」炎の復活編 #11 で発表しました。
Power Query Onlineからデータフローを新規作成する
Power Query Online = データフローの作成
ワークスペースからデータフローの新規作成を選択し、空のクエリを選択し、下記のPower Queryを記述(コピペ)します。
let
Source = Sql.Database("servername", "database"),
Navigation = Source{[Schema = "Sales", Item = "SalesOrderHeader"]}[Data],
#"Removed other columns" = Table.SelectColumns(Navigation, {"SalesOrderID", "OrderDate", "SalesOrderNumber", "PurchaseOrderNumber", "AccountNumber", "CustomerID", "TotalDue"}),
#"Filtered rows" = Table.SelectRows(#"Removed other columns", each [TotalDue] > 1000),
#"Kept bottom rows" = Table.LastN(#"Filtered rows", 5)
in
#"Kept bottom row
servername とdatabaseを、ご自身の環境に適した名前へ置き換えます。
ただしこれは、Microsoftが用意してくれているAdventureworksのサンプルデータベースを元に記述されているので、アクセス可能なデータベースで試してください。
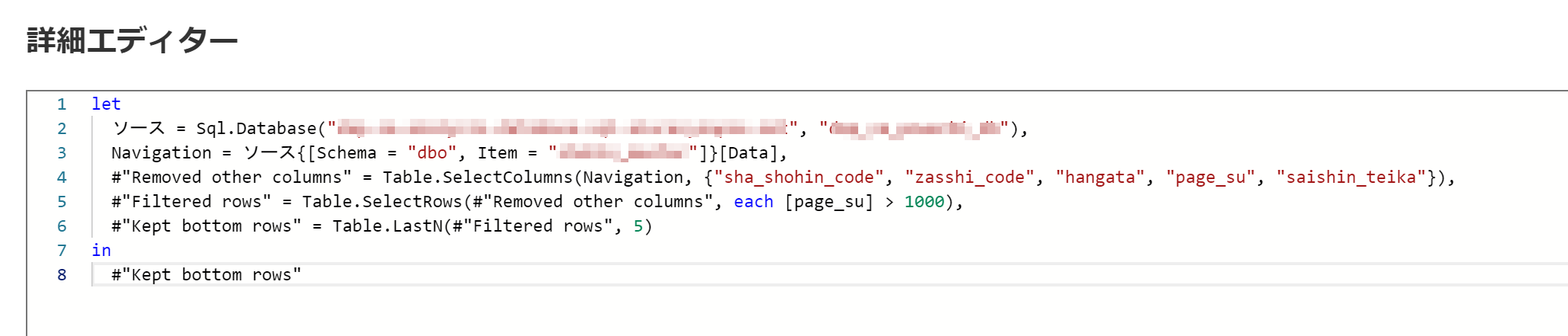
これをPower Query Online から空のクエリを呼び出し貼り付けます。自分の環境では下記のように手元のデータで同じ処理を作成してみました。
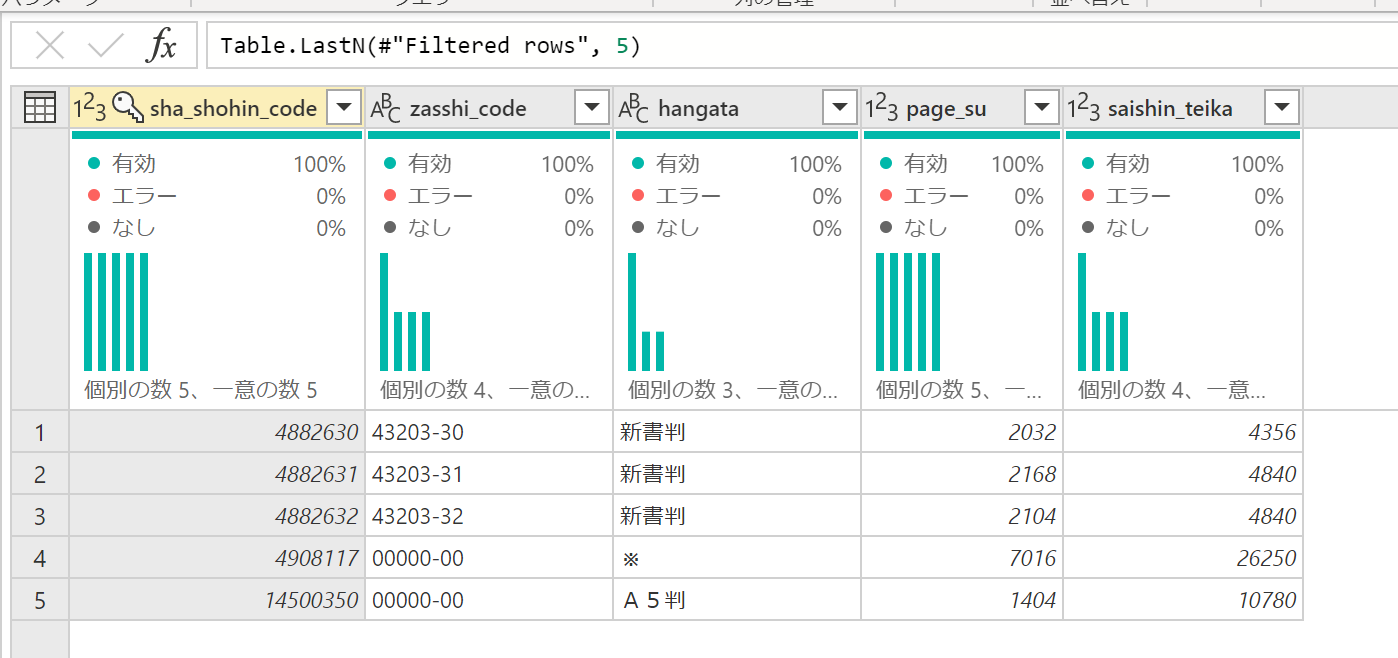
すると、結果はこのようになります。ページ数1000P以上で絞り込んだあとに、Table.LastNでラスト5行に絞り込んでいるので、結果は5行のみのデータです。
※Table.LastN関数
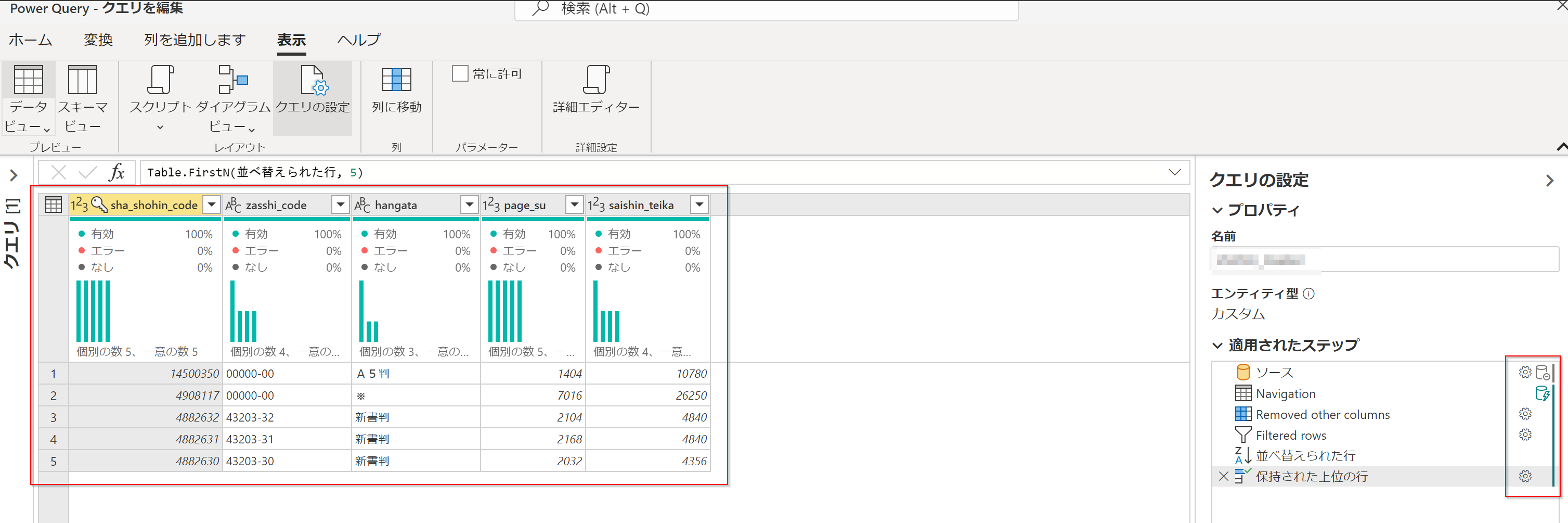
ステップ フォールディング インジケーターを確認
ステップ フォールディング インジケーター 🤔 と言われると難しいですが、「クエリ設定」を押すと右側に出てくるカラムのことです。Power Queryの処理がステップごとに表示されています。
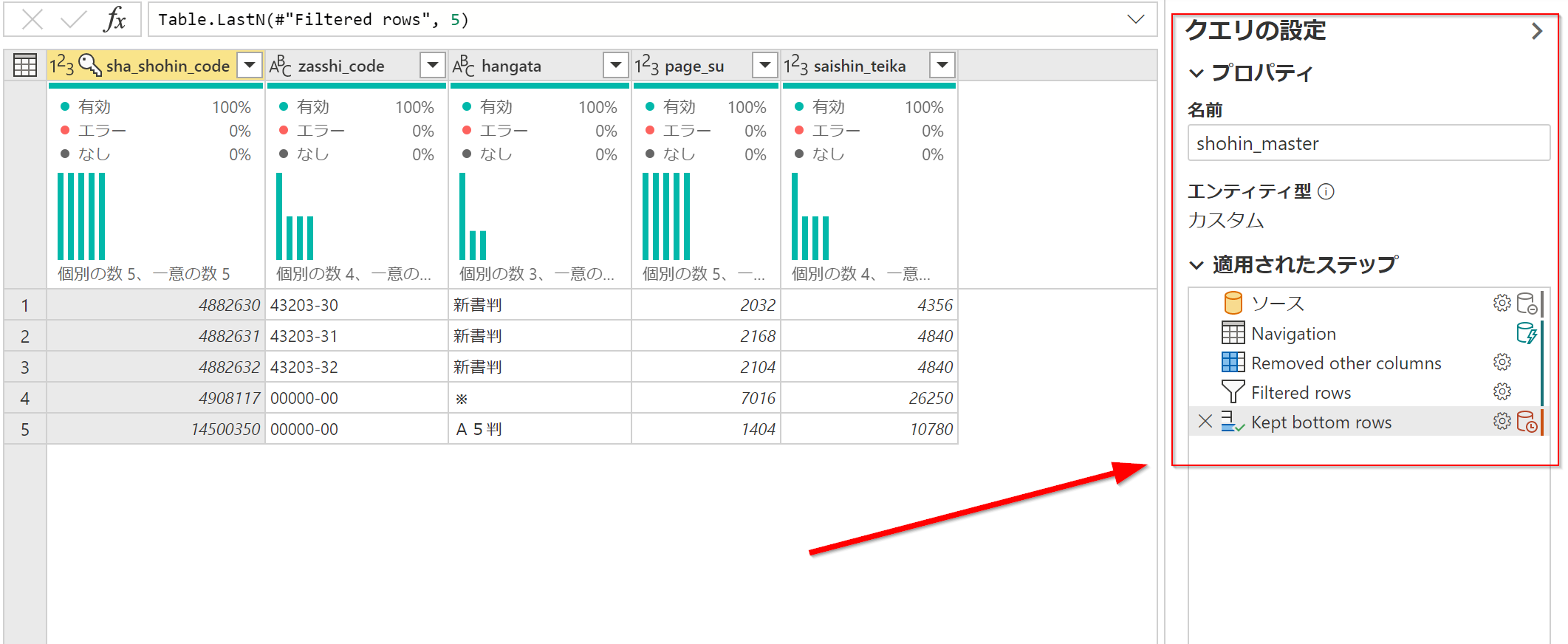
さらに細かくみると、ステップごとの右側に出てくるマークが異なることがわかります。
緑色のマークはクエリフォールディングが行われている部分、赤色はPower Queryエンジン側で処理が行われている部分を表します。
クエリ フォールディングの目的は、クエリの評価の多くを、クエリの変換を計算できるデータ ソースにオフロードまたはプッシュすることです。
クエリ フォールディング メカニズムでは、Mスクリプトをデータ ソースが解釈して実行できる言語に変換することで、この目的を達成します。
次に、その評価をデータ ソースにプッシュし、その評価の結果をPower Queryに送信します。多くの場合この操作によって、データ ソースから必要なすべてのデータを抽出し、Power Queryエンジンで必要なすべての変換を実行するよりもクエリの実行がはるかに高速になります。
クエリのステップを選択してそのクエリ プランを確認
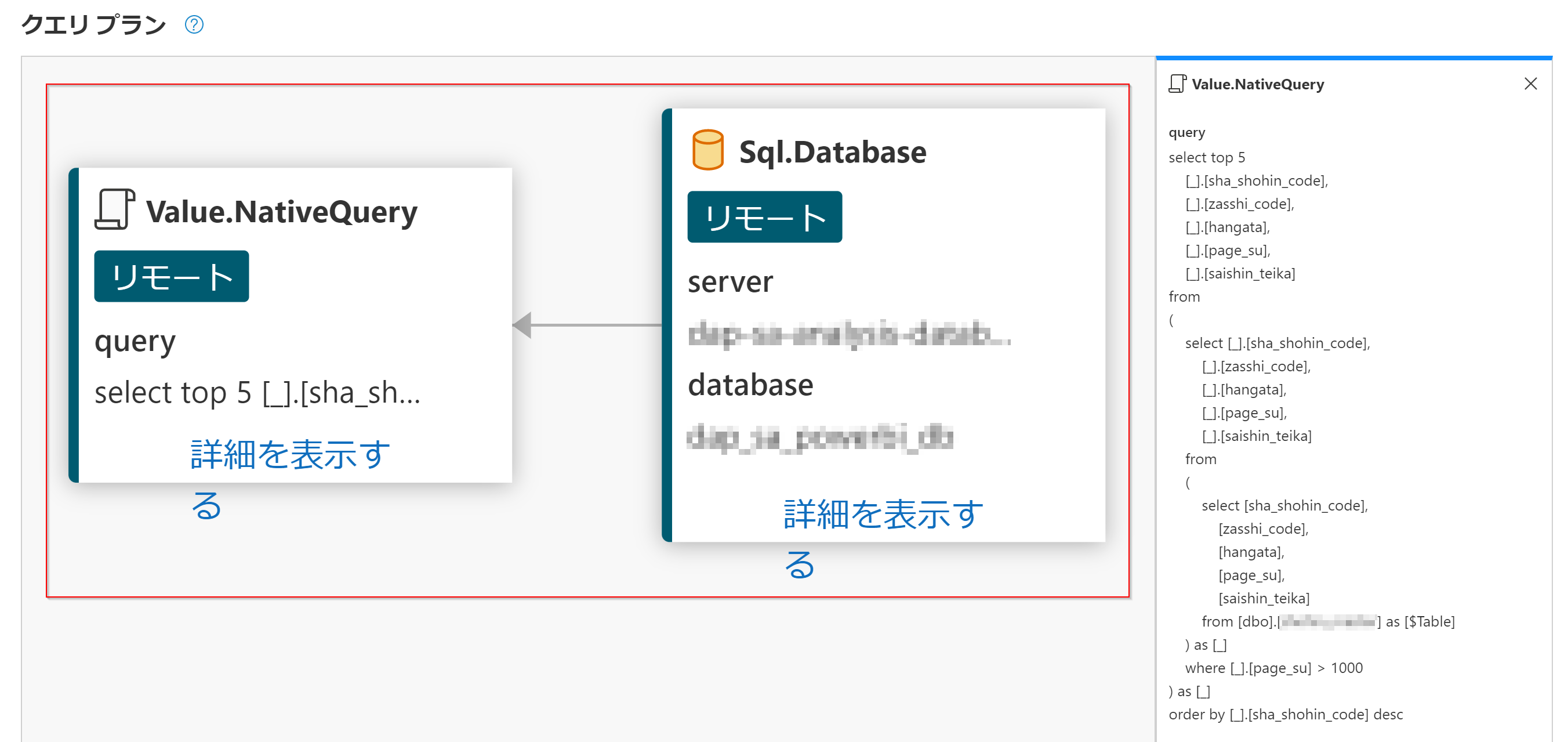
ステップを右クリックしてクエリプランを確認します。
クエリプランがビジュアライズされて表示されます。詳細を表示するをクリックすると実際にSQLサーバーに投げられているネイティブクエリを確認することもできます。
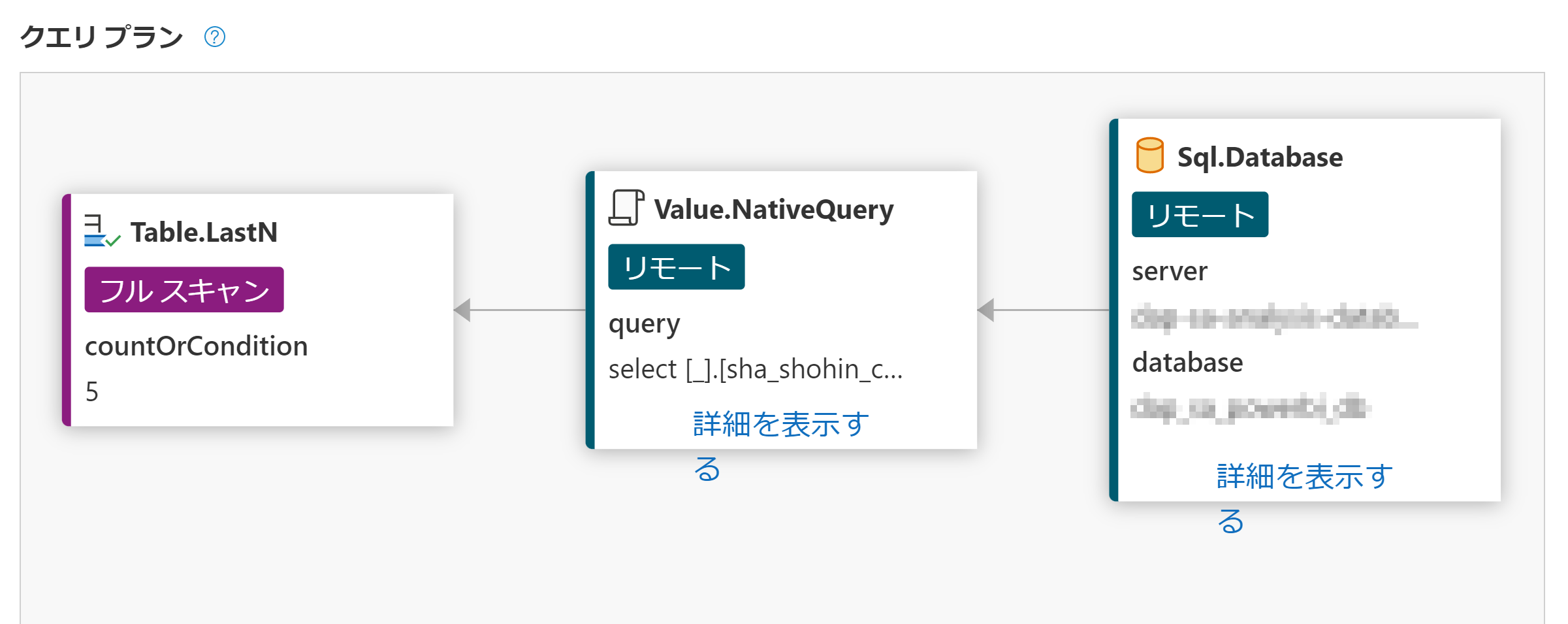
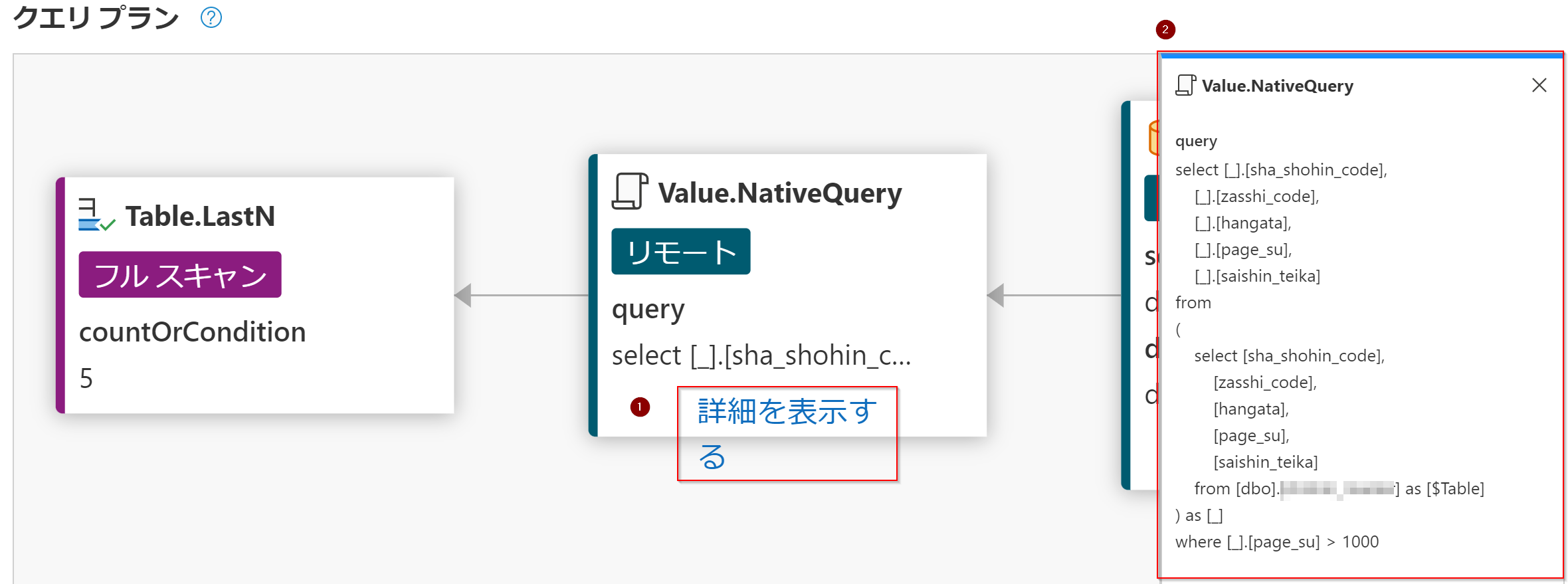
ここで、最後に実行されているTable.LastN関数の処理をみるとフルスキャンという表記があります。これはテーブルに格納されている全行を読み取る処理を行っているということなので、行数が多いデータになればなるほど処理には時間がかかり、制限時間を超えた場合には処理が終わらないということも考えられます。
クエリフォールディングが機能するようにPower Queryを修正する
このままでは処理が遅いので、最初に書いたクエリを修正していく必要があります。Table.LastN関数はテーブルの最後5行を検索する処理だったので、それと同じことを別の手法で実装します。
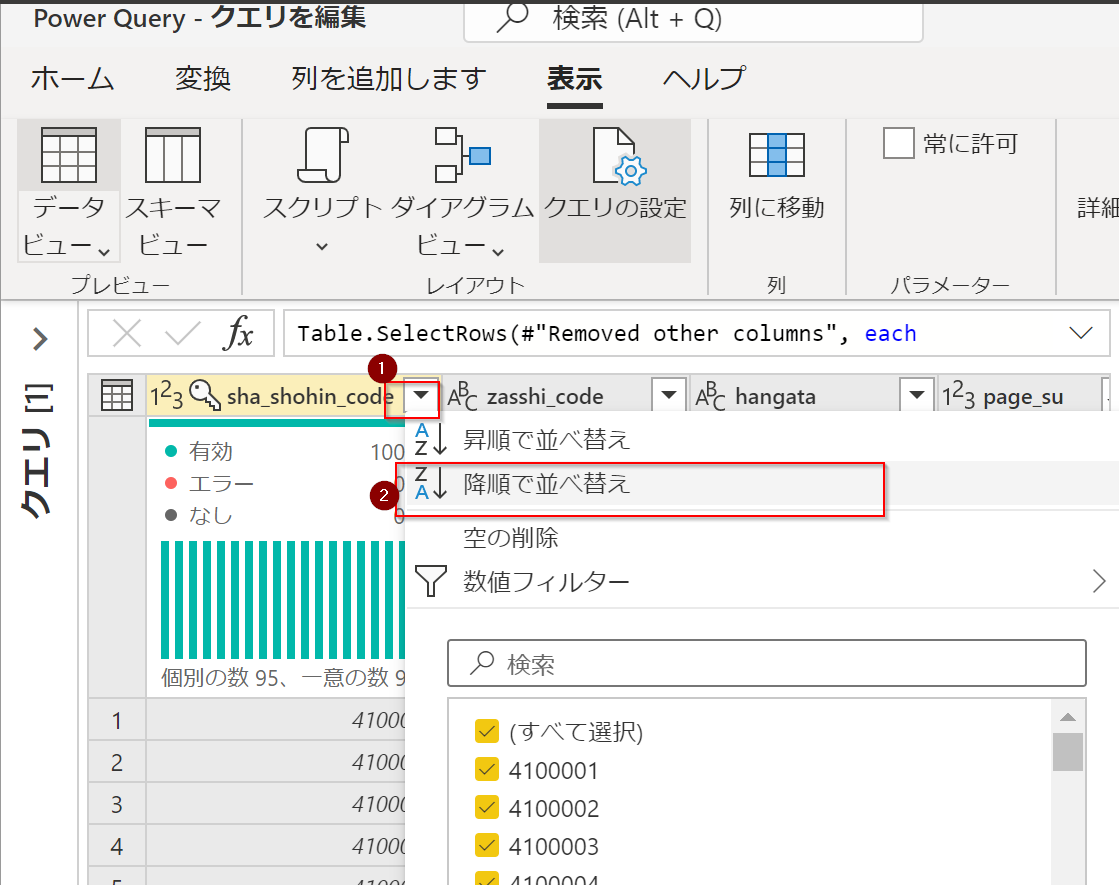
降順で並びかえ
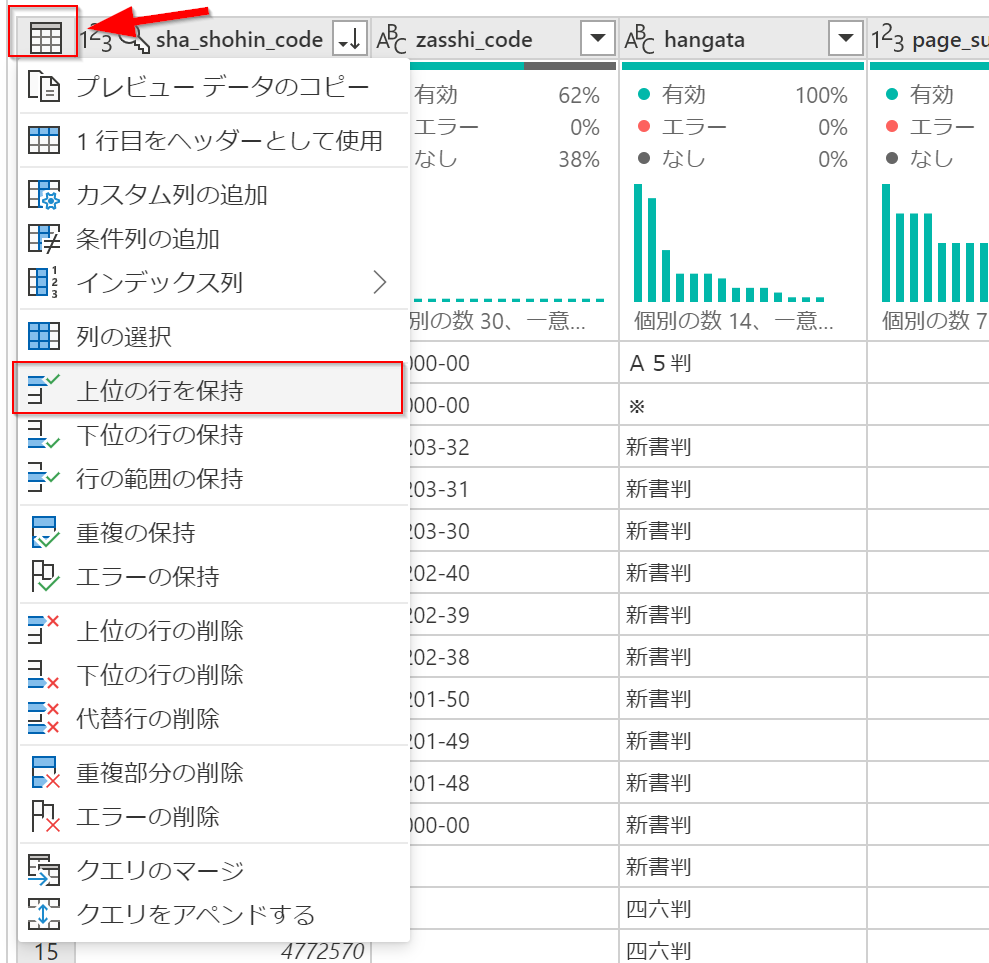
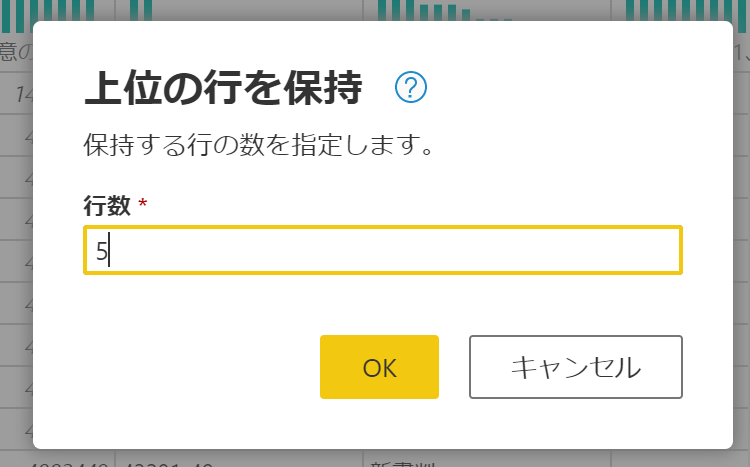
上位の行を保持
ステップ フォールディング インジケーターを確認
赤いマークが出ていない ![]()
クエリプランを確認
フルスキャンの項目がなく、すべてデータソース側での処理となっています。
クエリフォールディングを阻止する処理一覧
これがすべてではない。
- 異なるソースに基づいたクエリの結合。
- 異なるソースに基づいたクエリのアペンド (結合)。
- 複雑なロジック によるカスタム列の追加。 複雑なロジックとは、データ ソースに同等の関数を持たない M 関数の使用を意味します。 たとえば、次の式では、OrderDate 列の値を書式設定します (テキスト値を返します)。
Date.ToText([OrderDate], "yyyy")
- インデックス列の追加。
- 列のデータ型の変更。
- Power Query クエリに複数のデータ ソースが含まれる場合、データ ソースのプライバシー レベルに互換性がないためにクエリ フォールディングを実行できない可能性があります。
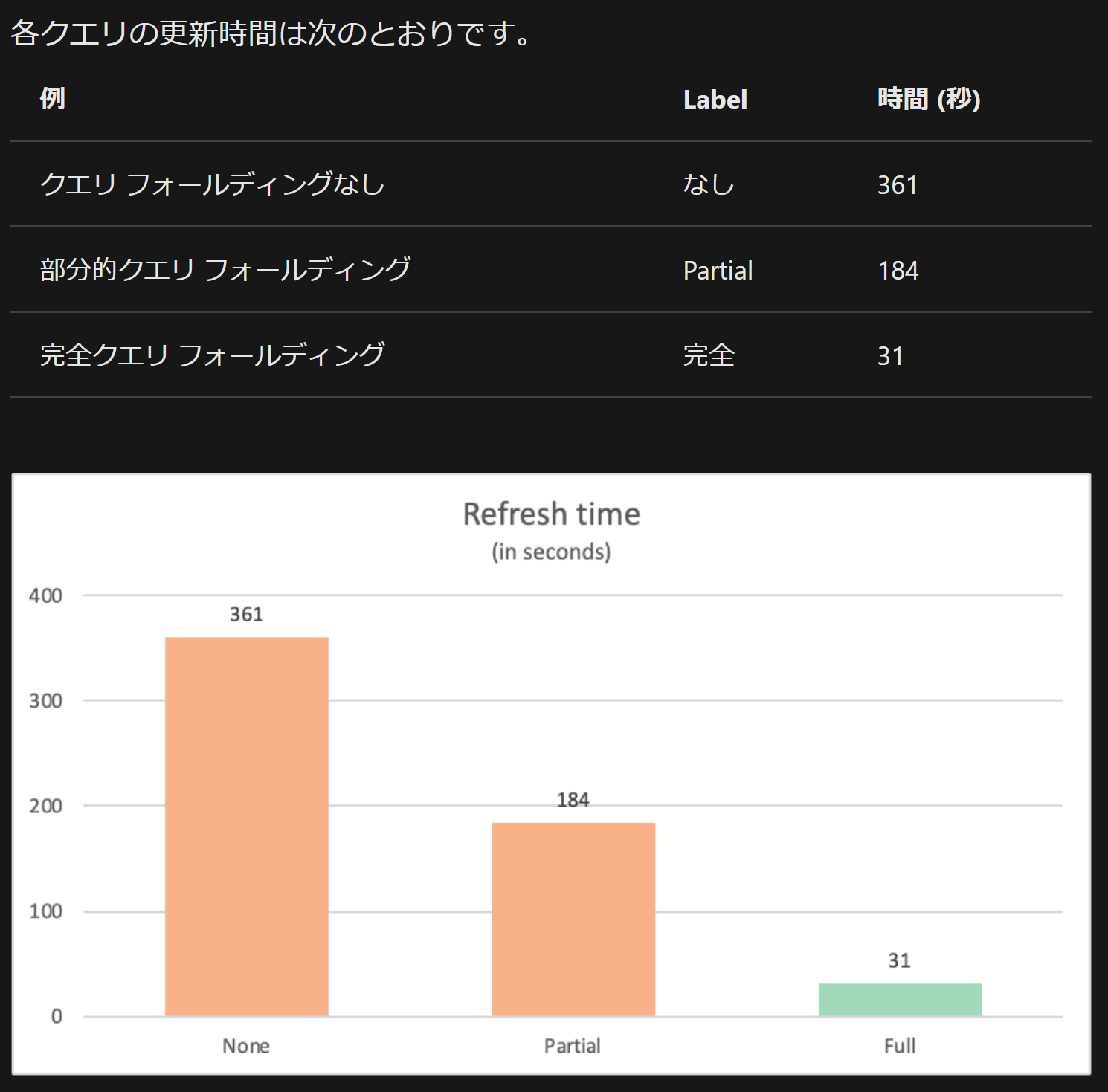
パフォーマンス比較
下記Docsではパフォーマンス比較まで行ってくれています。めちゃ参考になるので必読です ![]() 元のソースで処理をしてからデータがくるので、パフォーマンスが段違い!
元のソースで処理をしてからデータがくるので、パフォーマンスが段違い! ![]()
処理行数比較
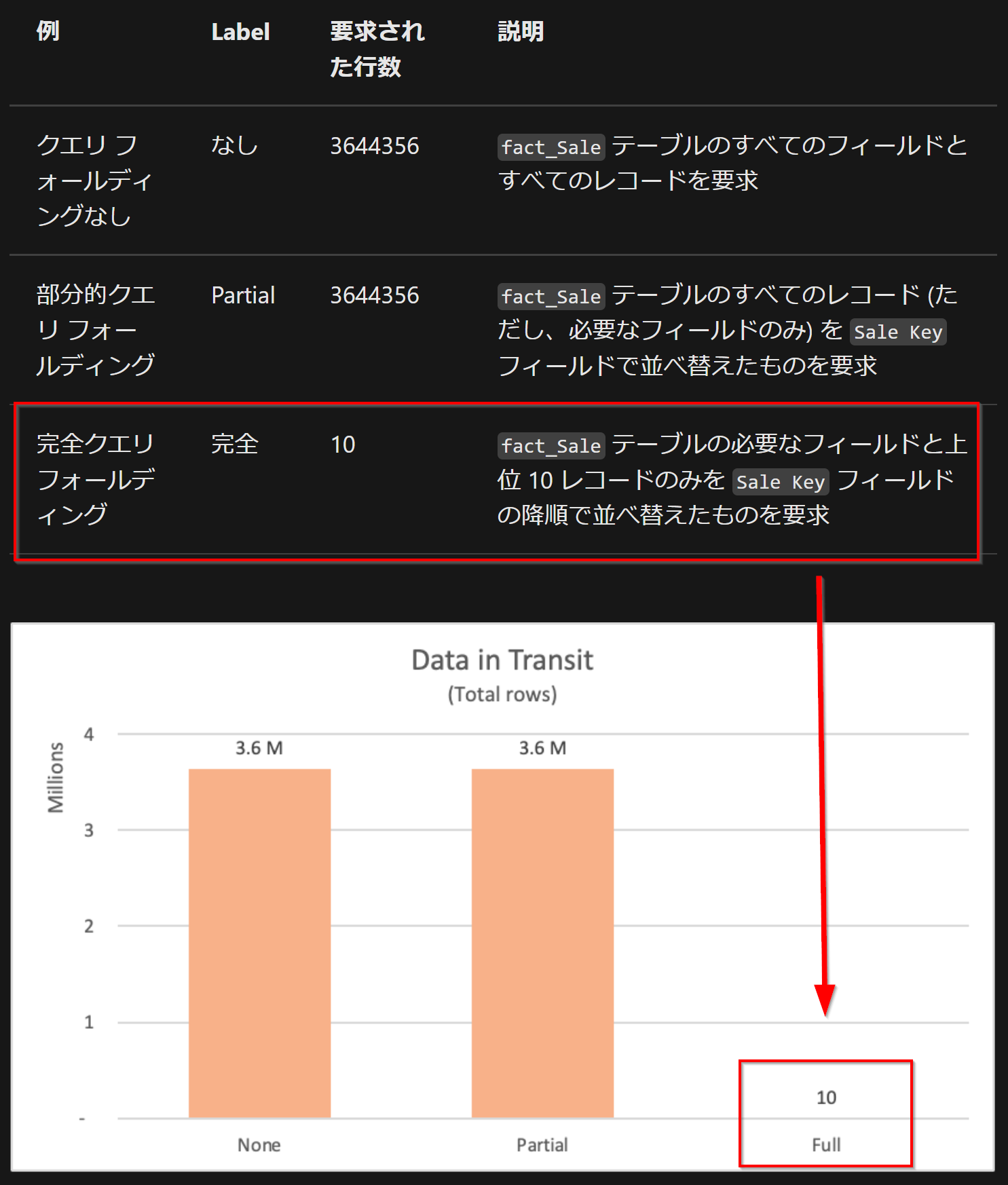
処理時間比較
まとめ
元のソースで処理をするのが大事、クエリフォールディング大事・・・と何度も言われてきたけどわかっていませんでした ![]()
実際に手を動かして、調べみるのがもっと大事・・という話。
参考資料