会議終了後、録音の聞き返して議事内容の修正やフォーマット整形、PDF出力、そして共有フォルダへのアーカイブ保存までの「事務作業」に工数を奪われてはいないでしょうか。これらの定型業務は、慣れない担当者にとっては負担となり、プロジェクト全体の生産性を押し下げます。
昨今、生成AIの普及により、議事録の「作成」自体のハードルは下がりました。しかし、AIがドラフトを作成しても、整形し、適切な場所に格納する工程が手動のままでは、真の業務効率化とは言えません。
本記事では、Notion AIによる構造的な要約から、PDFの自動生成、そしてGitHubをSSOT(単一の信頼できる情報源)とした管理までを、GitHub Actionsでシームレスに完結させるパイプラインの構築手法を解説します。
1. 議事録パイプラインで実現できること
本システムは、「会議から納品までの時間軸」に沿って、人間とAI、そして自動化システムが順々に繋いでいく設計になっています。どのようなタイムラインで議事録が公式ドキュメント(PDF/Markdown)へと変わるのかみていきましょう。
ステップ1:会議実施とAIによる構造化(Notion AI フェーズ)
まず、Notionの議事録ページを新設して、出席者やアジェンダなどの事前情報を記入しておきます。そして、お客様とのオンライン会議が始まったら、まずはNotionで「ミーティングノート」を起動します。
会議終了時にレコーディングを停止すると、Notion AIが音声データの文字起こしを開始します。ここで重要なのがカスタムプロンプトによる構造化です。事前に設定したテンプレートに沿って、AIが「決定事項」「宿題事項」「議事詳細」を整理し、バラバラな発言記録を「読める議事録」のドラフトへと変換します。
↓会議前のnotionの議事録ページ(※メモに出席者やアジェンダは事前に記載しておきます)
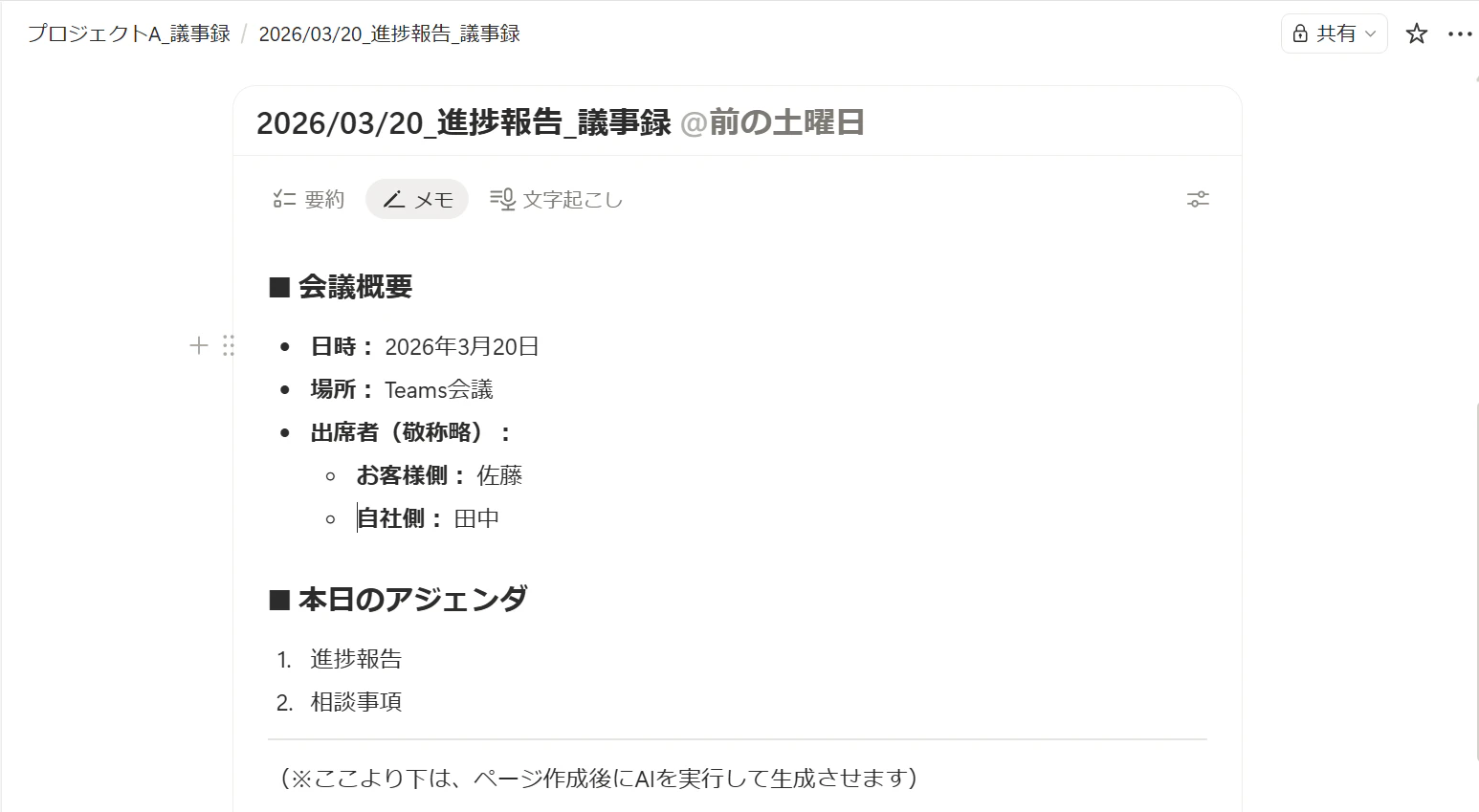
↓会議終了後、文字起こしをして、テンプレートに沿ってAIが整えた議事録ページ
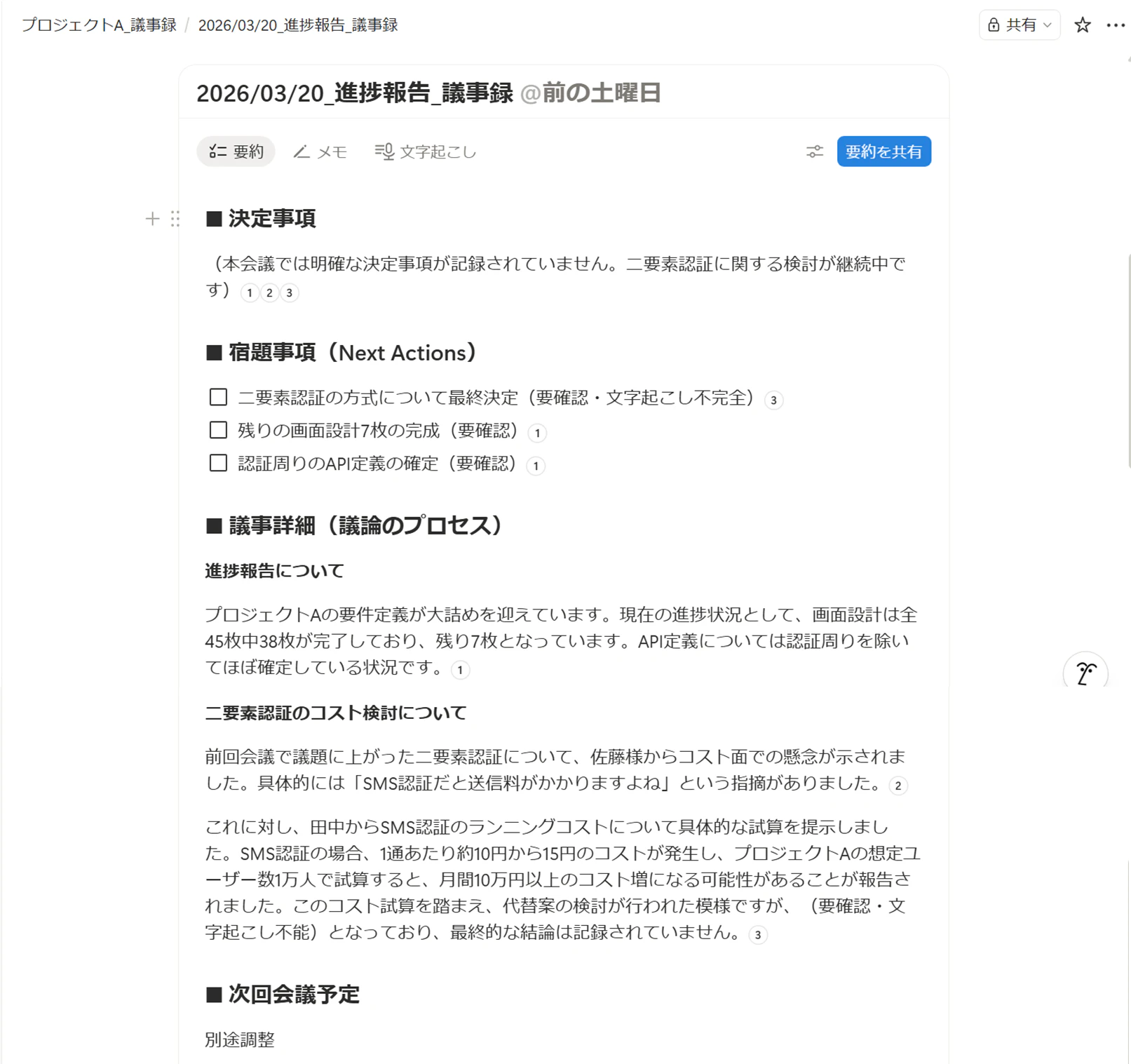
デモとしてNotion AIに吹き込んだ会議内容
エンジニア: お疲れ様です。プロジェクトAの要件定義もいよいよ大詰めですね。現在の進捗ですが、画面設計が45枚中38枚完了。API定義書については、認証周りを除いてほぼFixしています。
お客様: ありがとうございます。認証といえば、前回「二要素認証」の話が出ましたが、あれはコスト的にどうですか? SMS認証だと送信料がかかりますよね。
エンジニア: おっしゃる通りです。SMS認証だと1通あたり約10円〜15円のランニングコストが発生します。プロジェクトAの想定ユーザー数1万人で試算すると、月間10万円以上のコスト増になる可能性があります。
そこで検討した結果、決定として、追加コストのかからない「Google Authenticator」による二要素認証を採用します。これなら運用コストは0円です。
お客様: それは助かります。実装の手間はどうですか?
エンジニア: 実装には追加で「3人日」ほど工数をいただきますが、現在バッファを5日持っているので、全体納期への影響はありません。
お客様: わかりました。ではその方針で進めてください。あ、それとデータベースの移行についてですが、旧システムのデータがCSV形式で20GBほどあるんです。これを一気に流し込めますか?
エンジニア: 20GBですか……。そのまま流すとタイムアウトする恐れがあります。宿題として、来週の金曜、3月27日までに「バルクインサートによる段階的な移行プラン」を検討し、佐藤様に共有します。 その際、データのクレンジングが必要になるかもしれないので、その見積もりも添えますね。
お客様: 了解です。期待しています。次回の定例は、いつもの4月3日14時からTeamsで。
ステップ2:人間による品質担保(エンジニアフェーズ)
AIが自動で議事録を作成するといっても、人間がチェックを行います。AIは万能ではありません。音声が乱れた箇所にAIが自動付与する (要確認) マークを参考に、担当者が内容を微調整して議事録を完成させます。
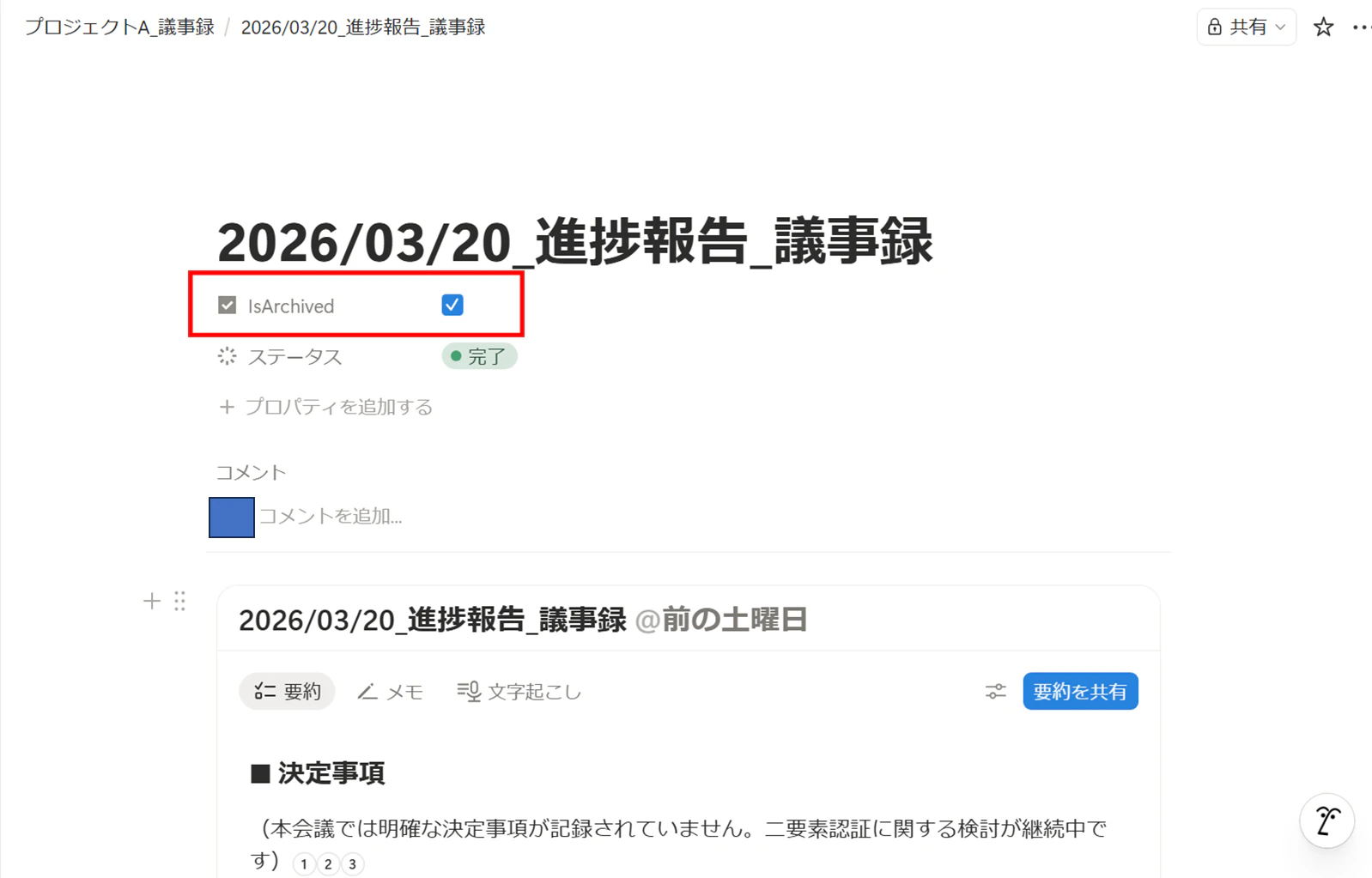
人間のレビューが終わったら、ステータスを 「完了」 に変更します。この時、ステータスが「完了」かつIsArchivedチェックボックスが 「false(未チェック)」であるページがPDF変換対象として抽出され、自動回収されることになります。
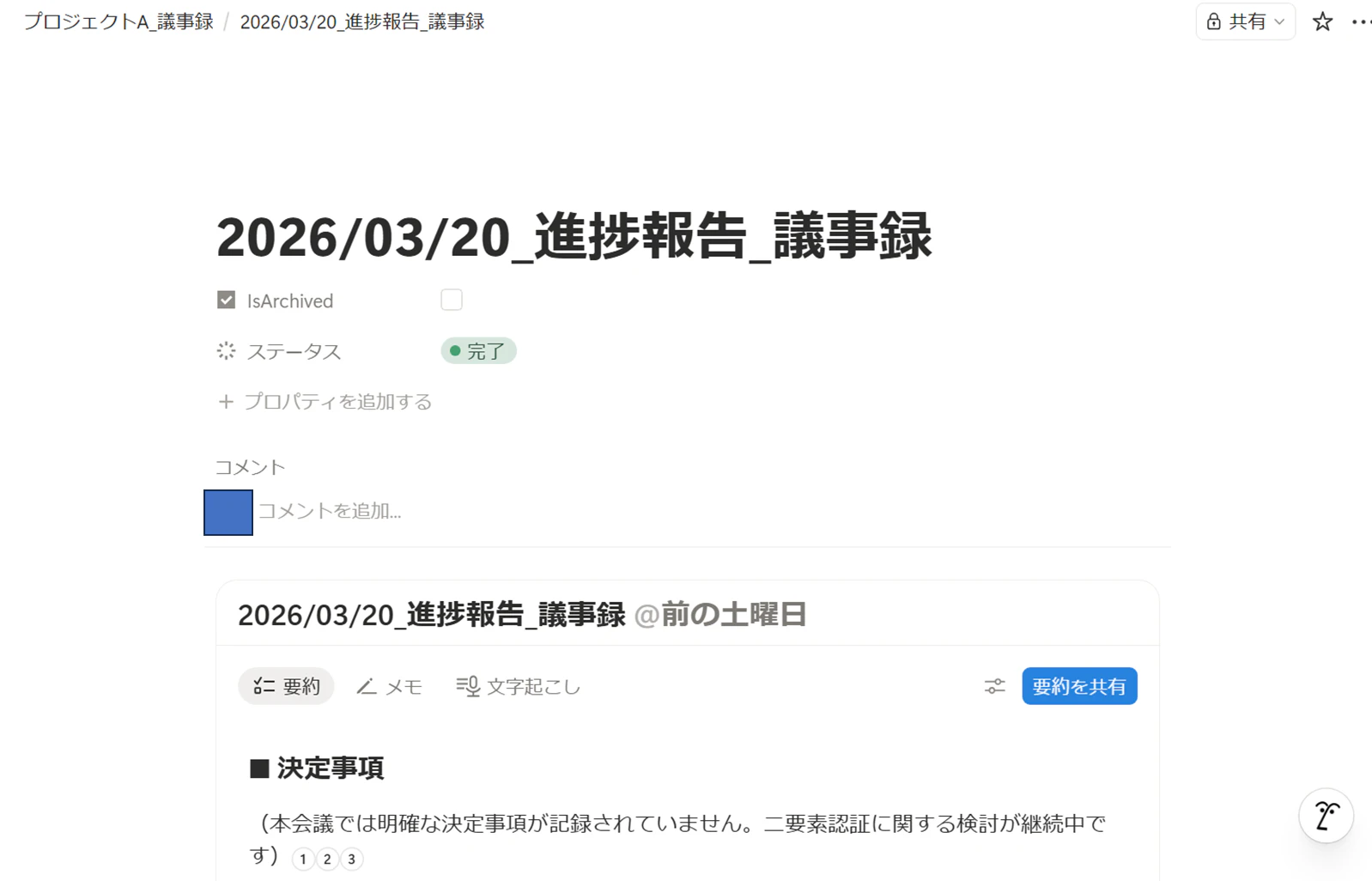
ステップ3:17:00の自動検知とビルド(Actions フェーズ)
夕方17:00になると、GitHub Actionsのタイマーが作動し、パイプラインが自動起動します。PythonがNotion APIを経由してデータベースをスキャンし、条件に当てはまるページを抽出します。その後、スクリプトがブロック構造を解析してMarkdownを生成します。さらに、Pandoc と 議事録の見た目を整える用のcss を組み合わせ、きれいなレイアウトのPDFとMarkdownを作成します。
完成した .md と .pdf は、リポジトリの minutes/ ディレクトリへ自動コミット・プッシュされます。プッシュが完了すると、システムは再びNotion APIを叩き、対象ページの IsArchived を true(チェック済み)へ更新します。この後処理により、次回の定期実行では処理対象から外れます。ちなみに、手動でもGithub actionsを起動できます。
↓markdown

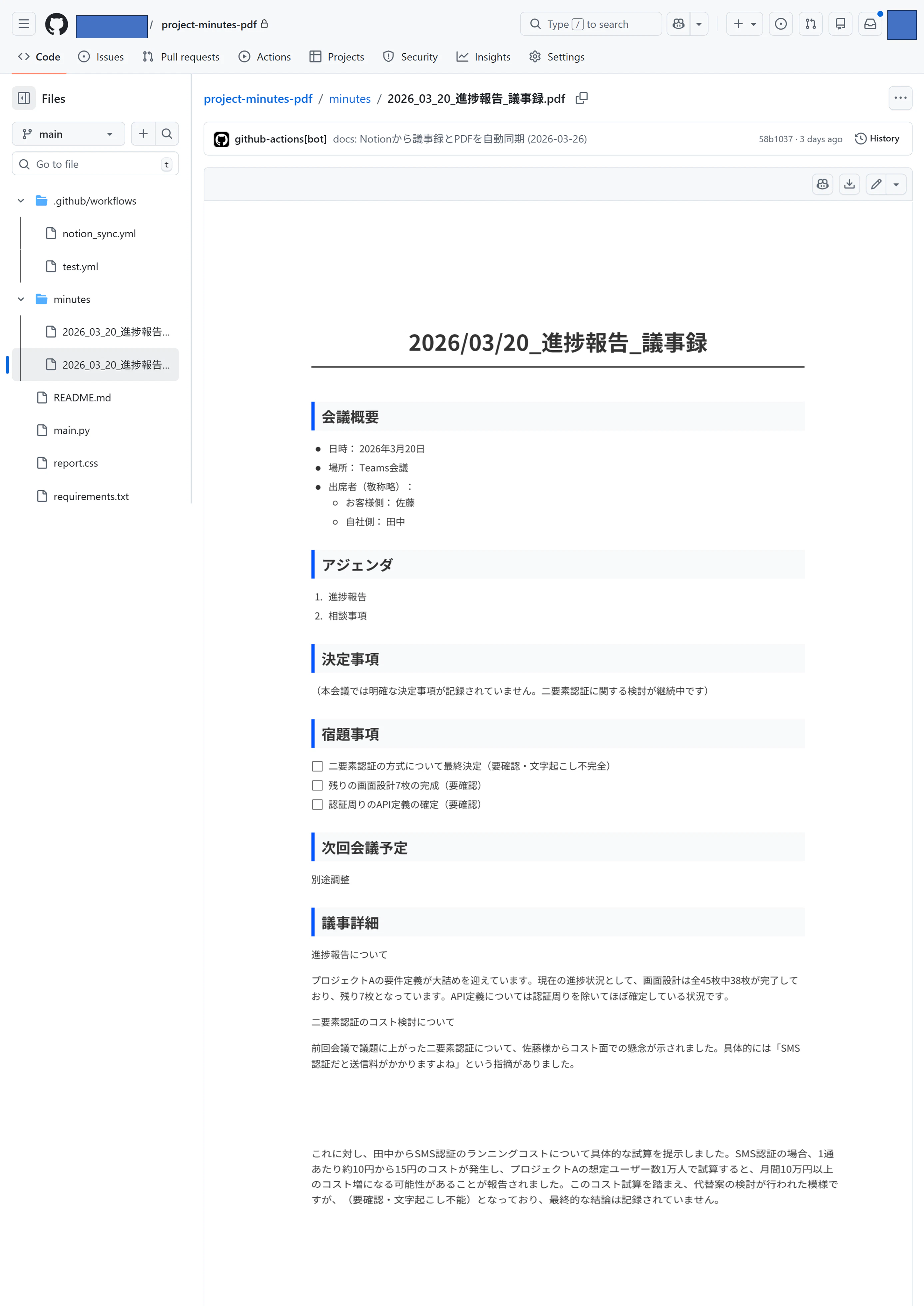
※(要確認)が残ってますが、人のレビュー時に修正する想定です。
2. 議事録パイプライン導入のメリット
このパイプラインを導入することで得られるメリットは、事務作業の削減だけではありません。チーム全体に「規律」と「ガバナンス」をもたらします。
① 「17時の定期実行」が業務リズムを作る
本システムでは、Github actionsが毎日 17:00に実行されるようスケジュールしました。午前中~昼過ぎに会議を行い、午後の隙間時間にレビューを済ませます。17:00にシステムが自動回収・PDF化することで、会議の当日17時過ぎにはお客様の手元にPDFの議事録が届くようなイメージをしてます。
このスピード感と習慣が、顧客との信頼関係を築きます。逆に「議事録作成は後でいいや」という妥協は、情報の鮮度を落とします。システムが自動で締め切りを作ってくれることで、「その日のエビデンスはその日のうちに」という規律がチームに浸透します。
② AIと人間の「責任分界点」を最適化する
「AIに全部任せる」のではなく、「AIが得意なこと」と「人間にしかできないこと」を切り分けました。AIが浸透しより効率的な業務が求められました。結果、人間がメモと音声をもとに議事録を0からつくることは時代に逆行しています。人間は「内容が正しいか」という判断に専念します。タイピングや書式設定といった付加価値のない作業は、AIに丸投げです。
③ GitHubを「SSOT(単一の信頼できる情報源)」にする
Notionは「議論し、育てる場」として優秀ですが、文書の管理にはGitHubが適しています。Notionは「作業場」、GitHubは「成果物」と明確に役割を分けます。Markdown形式で蓄積することで、全文検索が可能になるだけでなく、AIを使った業務で活用することも容易になります。Markdownでドキュメントを残すことで、「AI Ready」な環境をつくります。
また、report.css でレイアウトを一括制御します。誰が作っても、どの案件であっても、「常に同じデザイン」のPDFが出力されます。この一貫性が、組織としてのブランド力を高めます。
④ 高い拡張性と「導入コスト0円」
魅力は、「自由度」と「経済性」にもあります。GitHub Actionsを基盤としているため、プラグイン感覚で機能を拡張できます。例えば「Pushと同時にSlackへ通知する」「格納先をSharePointやBacklogに変更する」といったカスタマイズも、YAMLファイルを書き換えるだけで完結します。また、GitHub Actionsの無料枠内で十分に運用可能です。
3. パイプラインの作り方
ここからは、実際にどのような技術を選定し、どのような手順でパイプラインを構築していくのかを解説します。
業務要件
まずは、システムが満たすべき最低限の要件を整理します。実務運用においては、「何をトリガーにするか」「二重処理をどう防ぐか」というルール作りが重要です。
| 項目 | 内容 |
|---|---|
| 抽出条件 | Notion DBの Status == "完了" かつ IsArchived == false
|
| 実行頻度 | 定期実行(Cron: 毎日 17:00 JST)および 手動実行(Workflow Dispatch) |
| 成果物 |
minutes/ 配下に .md(生データ)と .pdf(閲覧用)を生成 |
| 後処理 | 処理完了後、Notion側の IsArchived を true に自動更新 |
技術要素と選定理由
シンプルかつ柔軟なスタックを選定した背景をまとめています。
| カテゴリ | 選定技術 | 選定の決め手 |
|---|---|---|
| AI | Notion AI | 精度のよい文字起こしに加え、テンプレート機能で「決定事項」等の抽出を構造化・標準化できるため。 |
| 実行基盤 | GitHub Actions | サーバー管理コストをゼロにしつつ、自動実行が可能なため。 |
| 言語 | Python 3.10+ | Notion SDKやファイル操作のライブラリが豊富で、自動化スクリプトの記述に適しているため。 |
| 変換エンジン | Pandoc + wkhtmltopdf | Markdownからビジネス用途に耐えうるPDFを生成するため。 |
| スタイル管理 | CSS3 (report.css) |
汎用的なMarkdownを「AI Ready」なデータとして残しつつ、印刷時は「人間が見やすい」レイアウトを両立させるため。 |
導入方法①Notion側の準備
まずはNotion側の設定を行います。
1.データベースの作成: 議事録管理用のデータベースを作成し、プロパティに「ステータス」と「IsArchived(チェックボックス)」を追加します。「ステータス」は、「進行中」というステータスを削除して、「未着手」と「完了」だけにします。チェックボックスの項目は「IsArchived」に変更します。
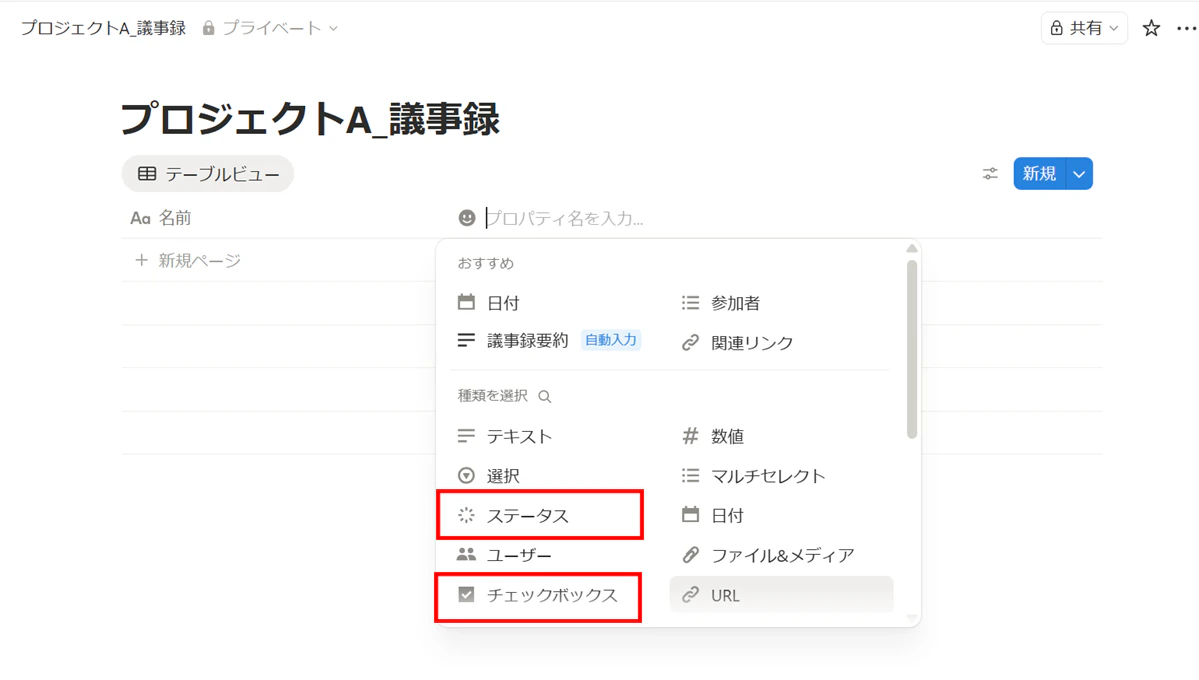
2.テンプレートとAI設定: Notion AIの「カスタムAIブロック」を活用しましょう。文字起こし結果から「決定事項」「宿題事項」「次回予定」を自動抽出するプロンプトを仕込んだテンプレートを作成します。
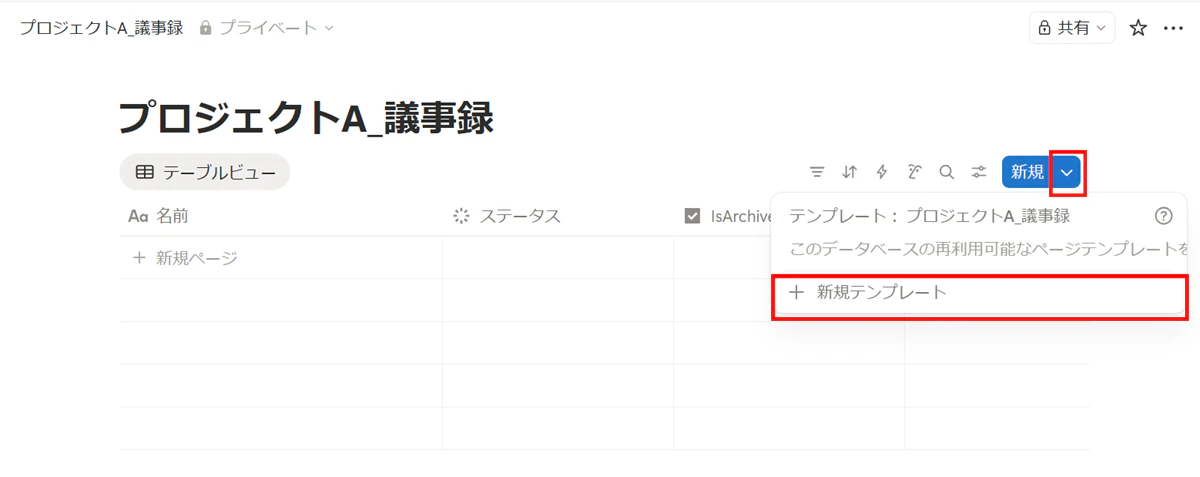
新規ボタンの下向き矢印を押下して、「新規テンプレート」を押下します。
編集画面で、AIミーティングノートを追加(「/meet」と打つとAIミーティングノートのブロックが出現します)したり、メモ欄などをカスタマイズします。
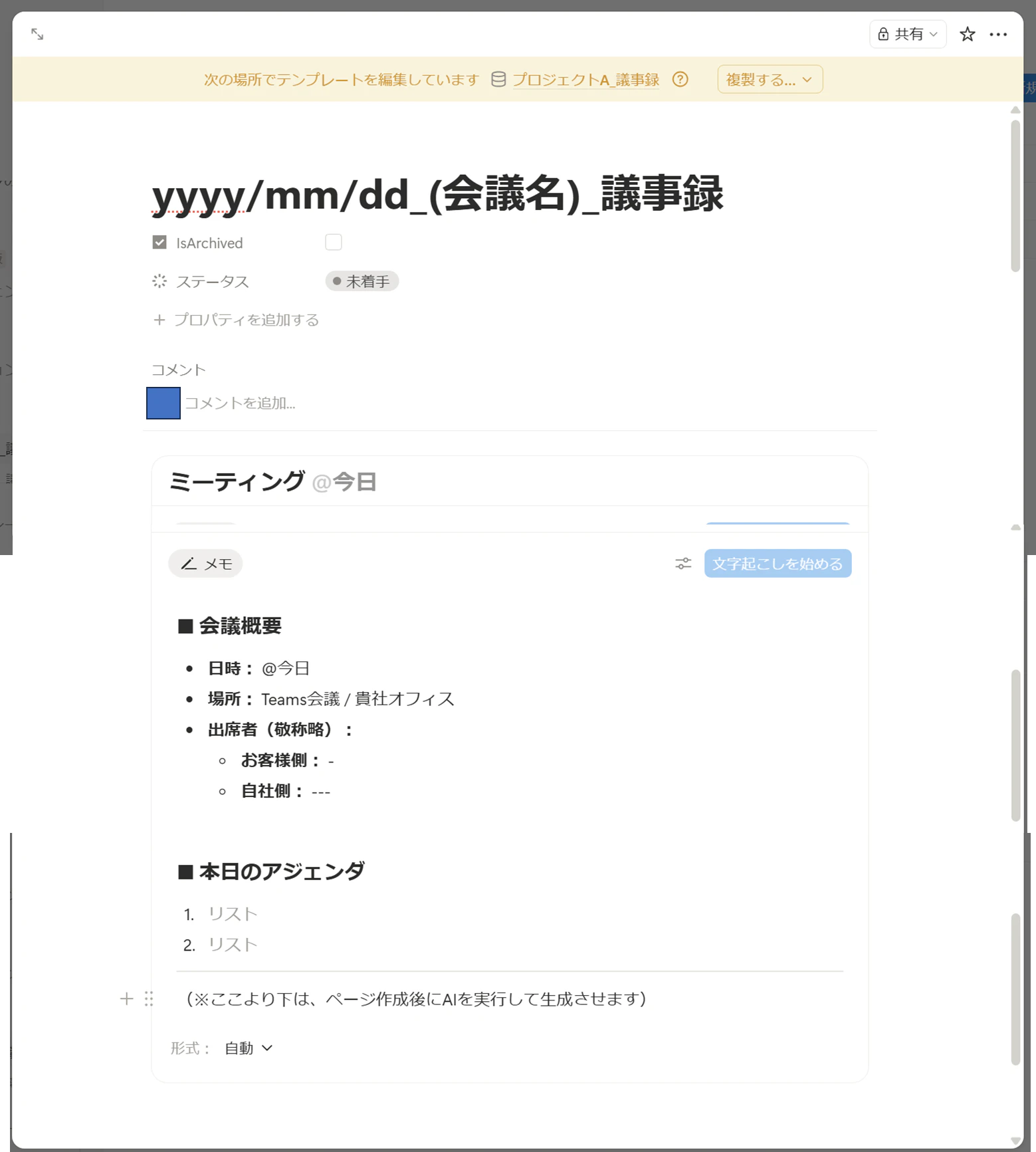
AIミーティングノートのメモ欄のテンプレート
### ■ 会議概要
- **日時:** @今日
- **場所:** Teams会議 / 貴社オフィス
- **出席者(敬称略):**
- **お客様側:** -
- **自社側:** ---
### ■ 本日のアジェンダ
1.
2.
---
(※ここより下は、ページ作成後にAIを実行して生成させます)
次に、要約のチューニングをします。テンプレート編集画面のAI ミーティングノートの一番下に「形式」という要約フォーマットがあります。ここを修正し、AIに議事録用の指示を出します。「形式」の下向き矢印を押下して、「カスタム形式を追加」を押下します。
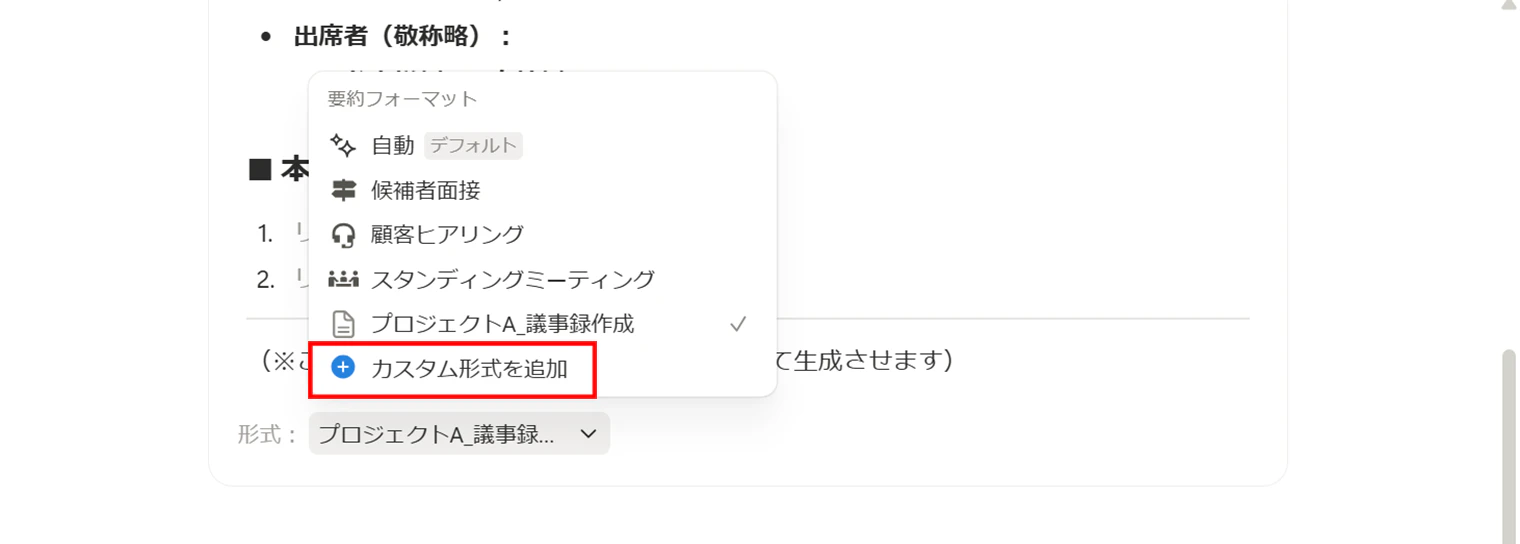
編集画面で以下のように議事録の型を指定します。

AIへの指示テンプレート
# 指示:以下のガイドラインに従い、指定された構造(### 以降)のみを出力してください。
# ※この指示自体や <aside> ブロック、および「📖文脈」「✍️出力フォーマット」などの説明文は出力に含めないこと。
<aside>
💡 **お客様提出用:高精度議事録生成モード**
この出力はPDF化されお客様へ納品されます。QCD(品質・コスト・納期)に関する事実関係の正確性と、議論のプロセス保持を最優先してください。
要約しすぎず、エンジニアが後で修正しやすい「高密度な情報」を抽出してください。
</aside>
📖 文脈
システム開発「プロジェクトA」の定例/仕様検討会議です。出席者は発注元(お客様)と受注側(エンジニア)です。
✍️ 出力フォーマット
以下の見出し構造で、文字起こしデータから情報を抽出・構成してください。
### ■ 決定事項
今回の会議で確定した事項を「[決定]」を付けて記載。特に仕様、納期、スコープ、コストに関する合意を最優先。
### ■ 宿題事項(Next Actions)
「- [ ] (担当者) 内容 (期限)」の形式で抽出。不明な点は「(要確認)」と付記。
### ■ 議事詳細(議論のプロセス)
話の流れがわかるよう、要約しすぎず詳細に記述してください。
- 各トピックの議論の背景(なぜその話になったか)
- 提示された選択肢とそれぞれのメリット・デメリット
- お客様からの具体的な要望・懸念と、エンジニア側の技術的回答
- 5〜10分程度の議論を1つの段落にまとめ、文脈を維持する
### ■ 次回会議予定
決定していれば、日時・場所を記載。未定なら「別途調整」と記載。
🎨 サマリのスタイルと制約
- **マーキング**: 音声不明瞭な箇所は「(要確認・文字起こし不能)」と明記。
- **構造**: Pandoc変換を想定し、見出し(###)と箇条書き(-)を正確に使用。
- **引用**: お客様の重要発言は「 」で直接引用。
- **言語・語尾**: 日本語、ビジネスライクな敬体(です・ます調)。
ここまでで、テンプレートをつくれたので、「プロジェクトA_議事録」のデータベースのページで、テンプレートをデフォルトに設定しましょう。
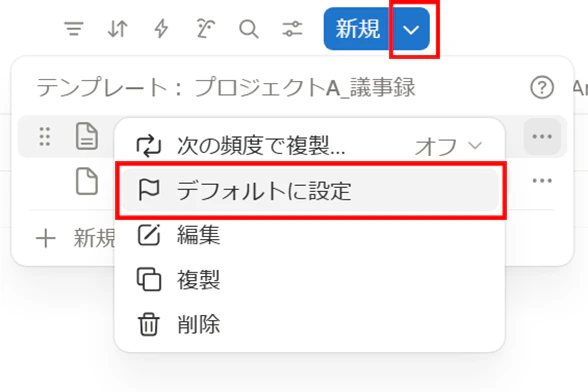
3.インテグレーションの作成: 内部インテグレーションを作成し、API通信に必要な「秘密キー(Token)」を取得します。
設定>コネクト の「インテグレーションを作成または管理する」を押下

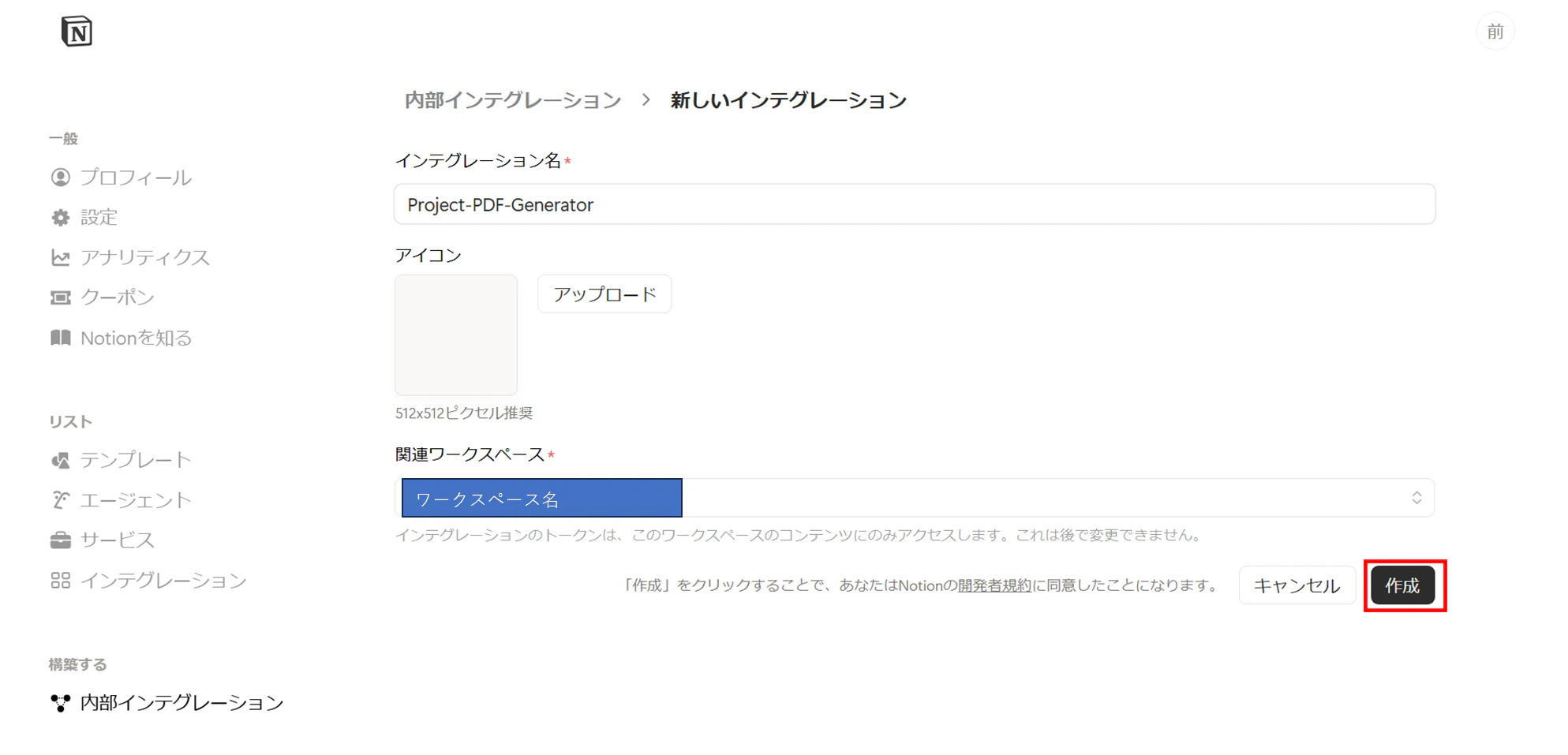
「新しいインテグレーションを作成」を押下し、以下の内容を入力し、「作成」を押下します。
- インテグレーション名:Project-PDF-Generator
- 関連ワークスペース:自分のワークスペース
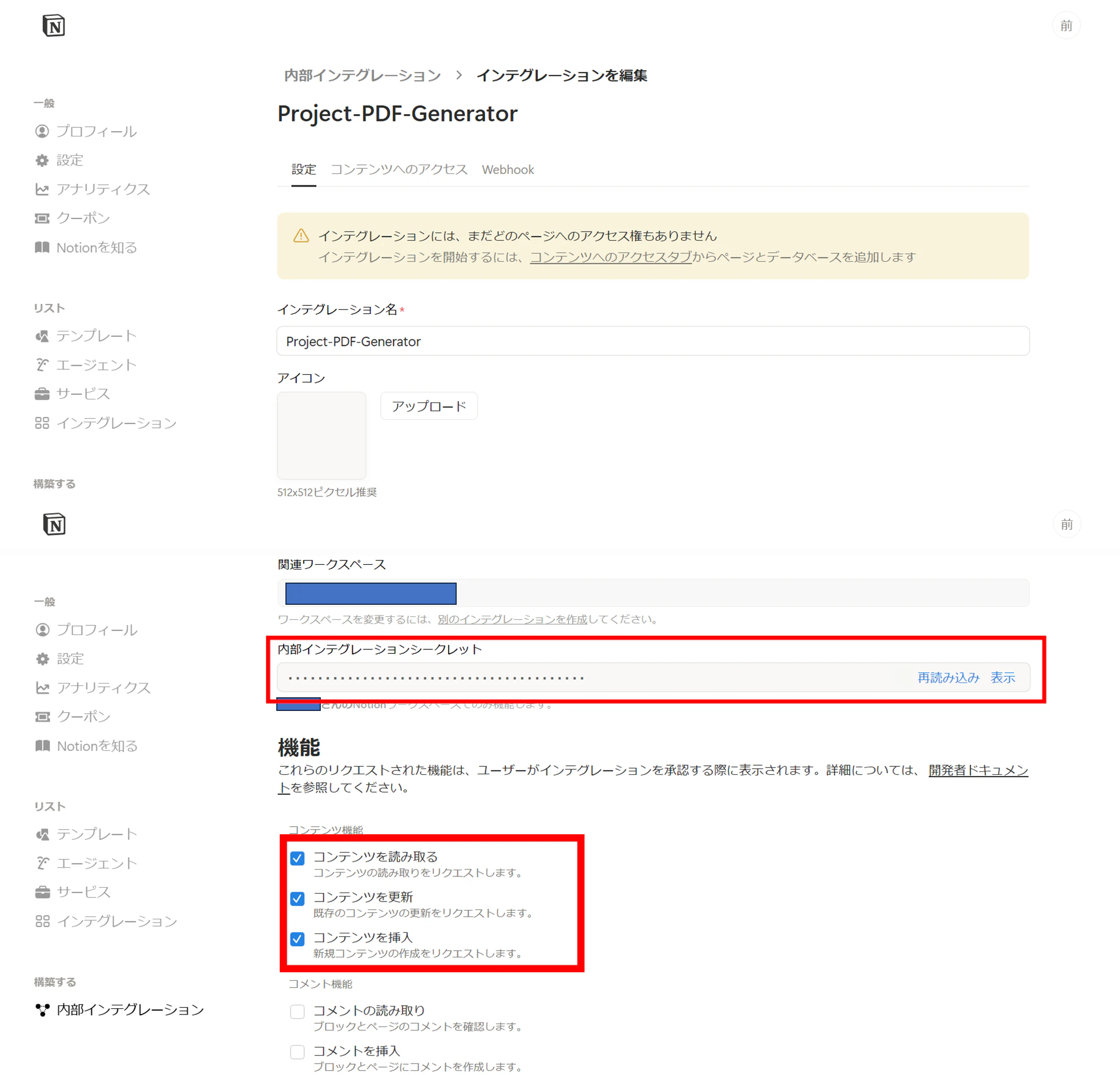
作成ができたので、中身を確認します。
- 内部インテグレーションシークレットの「表示」を押して、「ntn_~」の文字列を控えておきましょう。Githubに設定する際に使用します。
- 機能のところに以下の3つにチェックが入っていることを確認してください。
- コンテンツを読み取る
- コンテンツを更新する
- コンテンツを挿入する
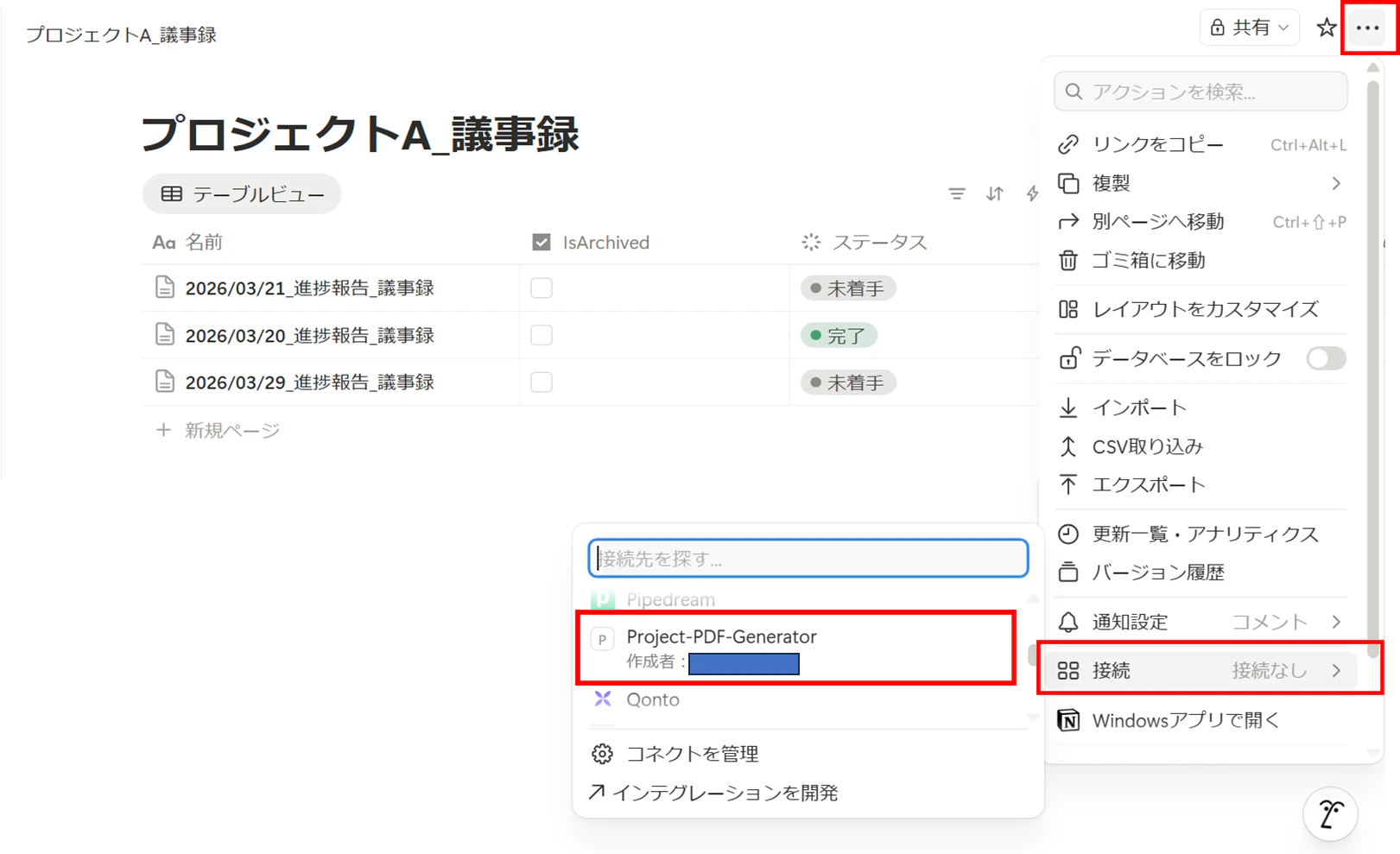
4.DBへのアクセス権付与: 対象データベースの「接続先」メニューから、作成したインテグレーションを追加します。これを忘れるとAPIからDBが見えないので注意が必要です。
データベースのページから右上の「・・・」>「接続」から、作成したインテグレーションを選択します(Project-PDF-Generator)
これでデータベースに対してAPIがアクセスできるようになります。
次に、「どの」データベースを見ればいいかを特定するためのデータベースIDを取得します。
データベースページのURLを見てください。「https://www.notion.so/ ~」となっていると思います。soのスラッシュの後からクエスチョンマークの前までの、32桁の英数字をコピーして控えておいてください。これがデータベースIDです。
https://www.notion.so/ [ここがデータベースID] ?v=...
導入方法②GitHub Actionsの設定
次に「工場」であるGitHub側のリポジトリを構成します。
1.リポジトリの作成します。公開範囲を「プライベート」で作成します(Githubアカウントを作っていない人は作成しましょう)。「project-minutes-pdf」というリポジトリ名にしました。

2.リポジトリ構成: 以下のディレクトリ構造を参考に、ファイルを配置します。
.
├── .github/
│ └── workflows/
│ └── notion_sync.yml # GitHub Actions設定 (Cron: 17:00 JST)
├── minutes/ # 【自動生成】同期されたMarkdownとPDFが保存される
├── main.py # Notion API連携・Markdown生成メインスクリプト
├── report.css # PDFレイアウト用スタイルシート
├── requirements.txt # Python依存ライブラリ (notion-client)
├── .gitignore
└── README.md
2.ワークフローの定義:配置したファイルの中身を記述します。
.github/workflows/notion_sync.yml
name: Notion Sync
on:
schedule:
# 日本時間(JST) 17:00 に実行 (17 - 9 = 8時 UTC)
- cron: "0 8 * * *"
workflow_dispatch: # 手動実行ボタンを表示
jobs:
build:
runs-on: ubuntu-latest
permissions:
contents: write # リポジトリへの書き込み(Push)に必要
steps:
- uses: actions/checkout@v4
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: "3.10"
# --- 1. 変換エンジンのインストール ---
- name: Install Pandoc, PDF Engine & Fonts
run: |
sudo apt-get update
sudo apt-get install -y pandoc wkhtmltopdf fonts-noto-cjk
- name: Install dependencies
run: pip install -r requirements.txt
- name: Run main script
env:
NOTION_API_TOKEN: ${{ secrets.NOTION_API_TOKEN }}
NOTION_DATABASE_ID: ${{ secrets.NOTION_DATABASE_ID }}
run: python main.py
# --- 2. PDFビルド(今回 main.py が更新した .md のみ。全件変換すると差分だけで毎回コミットされやすい)
- name: Build PDF with Pandoc
run: |
if [ ! -f minutes/.updated_this_run ]; then
echo "No Markdown updated this run; skip Pandoc."
exit 0
fi
while IFS= read -r f; do
[ -n "$f" ] || continue
[ -f "$f" ] || continue
echo "Converting $f to PDF..."
pandoc "$f" -o "${f%.md}.pdf" \
--css=report.css \
--pdf-engine=wkhtmltopdf \
--metadata pagetitle="Meeting Minutes"
done < minutes/.updated_this_run
# 今回 Notion から .md を書いたか(.gitignore のため hashFiles は使わない)
- name: Export status for artifact
id: export_check
run: |
if [ -f minutes/.updated_this_run ]; then
echo "exported=true" >> "$GITHUB_OUTPUT"
echo "This run exported from Notion; artifact will upload."
else
echo "exported=false" >> "$GITHUB_OUTPUT"
echo "No Notion export this run; skip artifact (repo checkout copy is not 'new work')."
fi
# 生成されたファイルがあるか確認(デバッグ用)
- name: Check generated files
run: ls -R minutes/ || echo "No files found in minutes directory."
# この実行で Notion から書き出したときだけ(手元ダウンロード用。ヒット0の実行ではアップロードしない)
- name: Upload artifact
if: steps.export_check.outputs.exported == 'true'
uses: actions/upload-artifact@v4
with:
name: generated-documents
path: |
minutes/*.md
minutes/*.pdf
# リポジトリに自動コミットしてPush
- name: Commit and Push
run: |
git config --local user.email "github-actions[bot]@users.noreply.github.com"
git config --local user.name "github-actions[bot]"
# 一致するファイルがないと git add が pathspec エラーになるため nullglob で扱う
shopt -s nullglob
to_add=(minutes/*.md minutes/*.pdf)
if [ ${#to_add[@]} -eq 0 ]; then
echo "No files under minutes/ to commit."
exit 0
fi
git add "${to_add[@]}"
# 変更がある場合のみコミット
if ! git diff --cached --exit-code --quiet; then
git commit -m "docs: Notionから議事録とPDFを自動同期 ($(date +'%Y-%m-%d'))"
git push
else
echo "No changes to commit."
fi
main.py
import json
import os
import re
from notion_client import Client
# 1. 環境変数の取得
# Notion の API トークンと対象データベース ID を環境変数から読み込む。
# DATABASE_ID は半角英数字のみ残すことで、入力時に余分なハイフンなどが入っても扱える。
NOTION_TOKEN = os.environ.get("NOTION_API_TOKEN", "").strip()
RAW_DATABASE_ID = os.environ.get("NOTION_DATABASE_ID", "").strip()
DATABASE_ID = re.sub(r'[^a-zA-Z0-9]', '', RAW_DATABASE_ID)
notion = Client(auth=NOTION_TOKEN)
LATEST_VERSION_HEADER = {"Notion-Version": "2026-03-11"}
UPDATED_MD_MARKER = os.path.join("minutes", ".updated_this_run")
def _log_query_summary(results):
"""IsArchived 切り分け用: API が返した各ページの ステータス / IsArchived を一覧する"""
print(
"--- databases.query サマリ(フィルタ: ステータス==完了 かつ "
"properties.IsArchived==False) ---"
)
print(f"ヒット件数: {len(results)}")
for i, page in enumerate(results):
props = page.get("properties", {})
# Notion データベースのプロパティ名は日本語/英語どちらの場合もあるため両対応で取得する
name_parts = (
props.get("名前", {}).get("title")
or props.get("Name", {}).get("title")
or []
)
name = name_parts[0].get("plain_text", "") if name_parts else ""
st = (
(props.get("ステータス") or {}).get("status")
or (props.get("Status") or {}).get("status")
or {}
)
status_name = st.get("name")
archived_cb = (props.get("IsArchived") or {}).get("checkbox")
top_archived = page.get("is_archived", page.get("archived"))
print(
f" [{i}] id={page.get('id')} "
f"Name={name!r} "
f"ステータス={status_name!r} "
f"properties.IsArchived={archived_cb!r} "
f"page.is_archived={top_archived!r}"
)
print("--- サマリ終わり ---")
def get_block_text(block_id, depth=0):
"""子ブロックを再帰的に取得し、階層構造を保ったままリスト化する"""
# block_id が未定義の場合や深すぎる再帰の場合は無理に続けない
if not block_id or depth > 3:
return []
try:
elements = []
cursor = None
while True:
response = notion.blocks.children.list(
block_id=block_id,
extra_headers=LATEST_VERSION_HEADER,
start_cursor=cursor,
)
children = response.get("results", [])
for child in children:
ctype = child["type"]
data = child.get(ctype, {})
has_children = child.get("has_children", False)
# rich_text を持つブロックのみを Markdown 用に抽出する
if isinstance(data, dict) and "rich_text" in data:
text = "".join([t["plain_text"] for t in data["rich_text"]]).strip()
if not text and not has_children:
continue
el_type = "paragraph"
if ctype.startswith("heading_"):
el_type = "heading"
elif ctype == "bulleted_list_item":
el_type = "list"
elif ctype == "to_do":
el_type = "list"
content = text
if ctype == "bulleted_list_item":
content = f"- {text}"
elif ctype == "to_do":
checked = "x" if data.get("checked") else " "
content = f"- [{checked}] {text}"
elif text.startswith("[ ]") or text.startswith("[x]"):
content = text.replace("[ ]", "- [ ]").replace("[x]", "- [x]")
el_type = "list"
elements.append({"type": el_type, "content": content, "depth": depth})
if has_children:
elements.extend(get_block_text(child["id"], depth + 1))
if not response.get("has_more"):
break
cursor = response.get("next_cursor")
return elements
except Exception as e:
print(f"⚠️ get_block_text error: block_id={block_id!r} depth={depth} {e}")
return []
def format_meeting_notes(title, elements):
"""要素を解析し、指定された順番とルールで結合する"""
order = ["会議概要", "アジェンダ", "決定事項", "宿題事項", "次回会議予定", "議事詳細"]
sections = {k: [] for k in order}
sections["その他"] = []
current_section = "その他"
for el in elements:
content = el["content"]
if any(k in content for k in order) and (content.startswith("#") or "■" in content):
for k in order:
if k in content:
current_section = k
break
continue
if content in ["文字起こし", "メモ", "要約"] or "ここより下は" in content:
continue
sections[current_section].append(el)
final_md = f"# {title}\n\n"
for k in order:
if not sections[k]: continue
final_md += f"## {k}\n\n"
for i, el in enumerate(sections[k]):
content = el["content"]
indent = " " * el["depth"]
if k == "アジェンダ":
final_md += f"{i+1}. {content}\n"
elif el["type"] == "list":
final_md += f"{indent}{content}\n"
if i + 1 < len(sections[k]) and sections[k][i+1]["type"] != "list":
final_md += "\n"
else:
final_md += f"{indent}{content}\n\n"
if not final_md.endswith("\n\n"): final_md += "\n"
return final_md
def main():
# 実行前に必須環境変数が揃っているか確認する
if not NOTION_TOKEN or not DATABASE_ID:
print(
"❌ NOTION_API_TOKEN と NOTION_DATABASE_ID の両方が必要です。"
" 環境変数を確認してください。"
)
return
print(f"🔍 実行中... (Target DB: {DATABASE_ID})")
try:
if os.path.isfile(UPDATED_MD_MARKER):
os.remove(UPDATED_MD_MARKER)
# --- フィルタ条件: Status="完了" かつ IsArchived=False ---
query_response = notion.databases.query(
database_id=DATABASE_ID,
filter={
"and": [
{"property": "ステータス", "status": {"equals": "完了"}},
{"property": "IsArchived", "checkbox": {"equals": False}}
]
},
extra_headers=LATEST_VERSION_HEADER,
)
results = query_response.get("results", [])
_log_query_summary(results)
if os.environ.get("NOTION_LOG_FULL_QUERY") == "1":
print("--- databases.query レスポンス(JSON・全文) ---")
print(json.dumps(query_response, ensure_ascii=False, indent=2))
print("--- databases.query レスポンス終わり ---")
for page in results:
p_id = page.get("id")
if not p_id:
print("⚠️ skipped page without id in query results")
continue
properties = page.get("properties", {})
title_parts = (
properties.get("名前", {}).get("title")
or properties.get("Name", {}).get("title")
or []
)
title = title_parts[0].get("plain_text", "(無題)") if title_parts else "(無題)"
print(f"🚀 処理中: {title}")
response = notion.blocks.children.list(block_id=p_id, extra_headers=LATEST_VERSION_HEADER)
blocks = response.get("results", [])
all_elements = []
for block in blocks:
# transcription ブロックを探し、サマリ/ノート用のサブブロック ID を取り出す
if block["type"] == "transcription":
data = block.get("transcription", {})
c_ids = data.get("children") or {}
if isinstance(c_ids, dict):
all_elements += get_block_text(c_ids.get("summary_block_id"))
all_elements += get_block_text(c_ids.get("notes_block_id"))
break
if not all_elements:
print(
f"⚠️ transcription block not found or empty for page {title!r} "
f"(id={p_id})"
)
continue
content = format_meeting_notes(title, all_elements)
output_dir = "minutes"
os.makedirs(output_dir, exist_ok=True)
safe_title = re.sub(r'[\\/:*?"<>|]', "_", title)
filename = os.path.join(output_dir, f"{safe_title}.md")
with open(filename, "w", encoding="utf-8") as f:
f.write(content)
print(f"✅ 保存完了: {filename}")
with open(UPDATED_MD_MARKER, "a", encoding="utf-8") as mf:
mf.write(filename + "\n")
# --- 処理完了後、Notion側の IsArchived を true に更新 ---
notion.pages.update(
page_id=p_id,
properties={"IsArchived": {"checkbox": True}},
extra_headers=LATEST_VERSION_HEADER,
)
print(f"📦 Notionアーカイブ完了: {title}")
except Exception as e:
print(f"❌ メイン処理エラー: {e}")
if __name__ == "__main__":
main()
report.css
/* 議事録用標準スタイルシート (report.css)
A4サイズ・ビジネス向けレイアウト
*/
@page {
size: A4;
margin: 25mm 20mm; /* 上下左右の余白 */
}
body {
font-family:
"Noto Sans CJK JP", "Hiragino Kaku Gothic ProN", "Hiragino Sans", Meiryo,
sans-serif;
line-height: 1.7;
color: #333;
max-width: 100%;
margin: 0 auto;
font-size: 10.5pt;
}
/* タイトル (H1) */
h1 {
font-size: 24pt;
text-align: center;
margin-bottom: 50px;
padding-bottom: 10px;
border-bottom: 2px solid #333;
}
/* セクション見出し (H2) */
h2 {
font-size: 16pt;
margin-top: 30px;
margin-bottom: 15px;
padding-left: 10px;
border-left: 5px solid #0055ff; /* アクセントカラー:青 */
background-color: #f8f9fa;
line-height: 2;
}
/* 小見出し (H3) */
h3 {
font-size: 13pt;
margin-top: 20px;
border-bottom: 1px solid #ddd;
}
/* 箇条書きリスト */
ul,
ol {
padding-left: 25px;
margin-bottom: 15px;
}
li {
margin-bottom: 5px;
}
/* タスクリスト ([ ] [x]) */
li input[type="checkbox"] {
margin-right: 8px;
}
/* 議事詳細の段落 */
p {
margin-bottom: 15px;
text-align: justify; /* 両端揃えで綺麗に見せる */
}
/* 強調 */
strong {
color: #d32f2f; /* 決定事項などが目立つように赤系に */
}
/* コードブロック(API定義など) */
pre {
background-color: #f4f4f4;
padding: 15px;
border-radius: 5px;
border: 1px solid #ddd;
font-size: 9pt;
overflow-x: auto;
white-space: pre-wrap;
}
/* 改ページ制御:H2の前で改ページさせない、または適切な場所で切る */
h2 {
page-break-after: avoid;
}
/* 署名欄や日付用の右寄せクラス(必要に応じてMarkdown内で使用) */
.text-right {
text-align: right;
}
requirements.txt
notion-client==2.2.1
.gitignore
# CI 用マーカー(コミットしない)
minutes/.updated_this_run
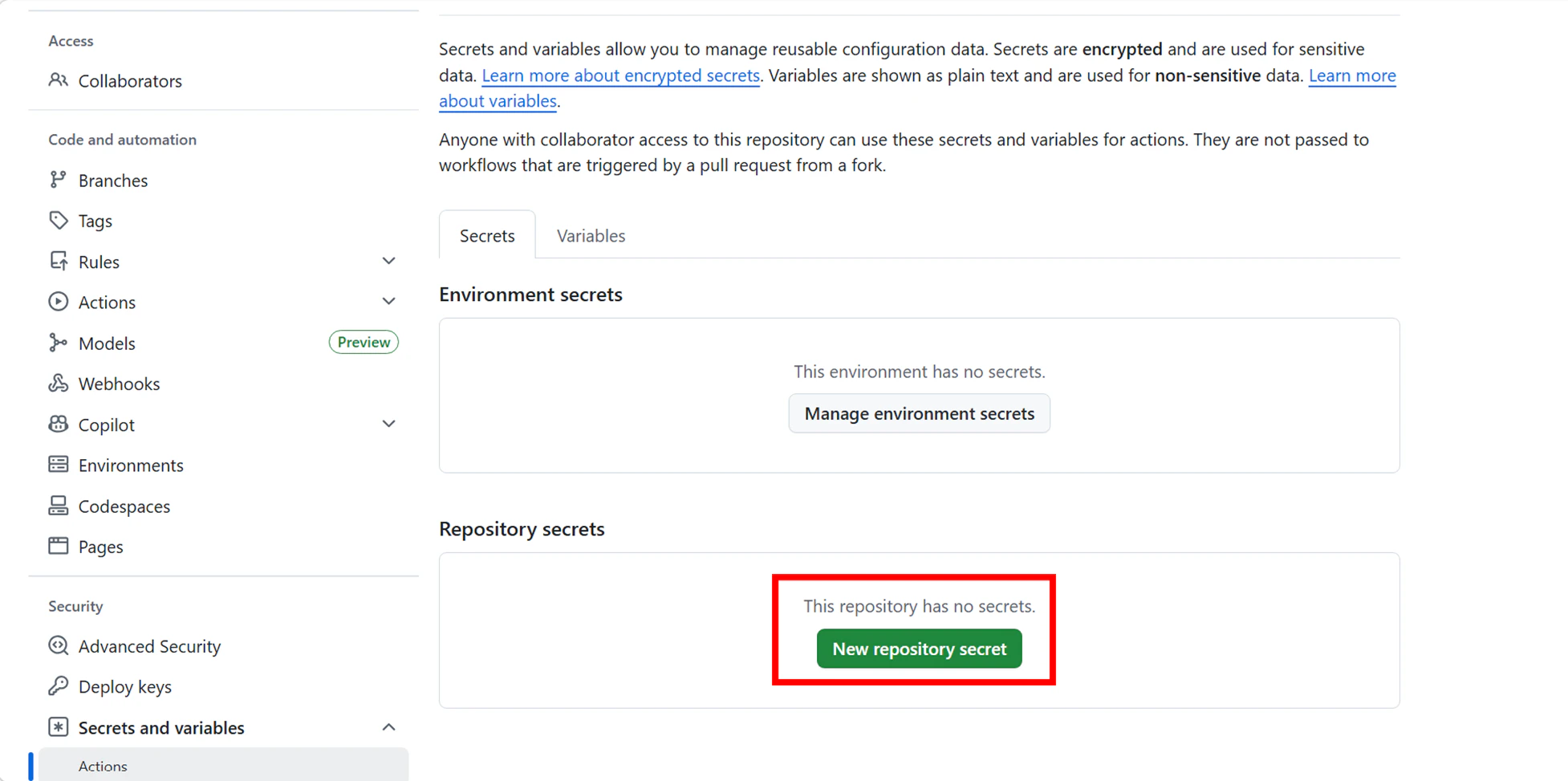
3.Secretsの登録: リポジトリの Settings > Secrets and variables > Actions に NOTION_API_TOKEN と NOTION_DATABASE_ID を登録します。機密情報をコードにベタ書きしないためのステップです。
作成したリポジトリの画面上部にある [Settings] タブをクリック。左側のメニューから [Secrets and variables] → [Actions] を選択します。
[New repository secret] ボタンをクリックし、APIトークンとデータベースIDを1つずつ登録します。
- ① Notion APIトークンの登録
- Name: NOTION_API_TOKEN
- Secret: 先ほど控えた 「ntn_...」 で始まるインテグレーションシークレットを貼り付け
- [Add secret] をクリック
- ②データベースIDの登録
- Name: NOTION_DATABASE_ID
- Secret: 先ほど控えた32桁の英数字(データベースID)を貼り付け
- [Add secret] をクリック
導入方法③動作確認
設定が完了したら、いよいよ「動作確認」です。
1.テストデータの作成: Notion側でテスト用の議事録を作成し、内容を確認してステータスを「完了」に変更します
2.手動実行(workflow_dispatch): GitHubのActionsタブからワークフローを選択し、「Run workflow」をクリックします。17時を待たずに即時テストが可能です
Githubの議事録リポジトリから Actions >Notion Sync 押下し、「Run workflow」から「Run workflow」を押下します。
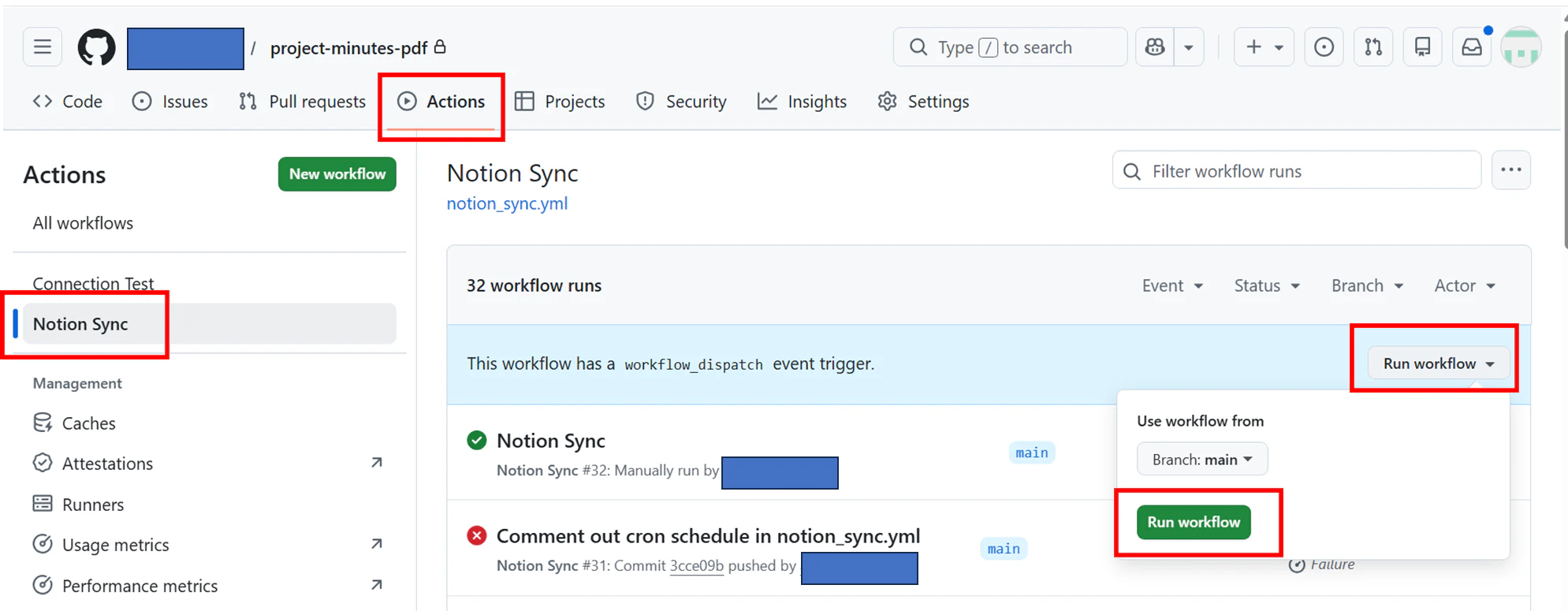
statusがSuccessになればコード自体は動きました。

3.成果物の確認: 1分後、リポジトリの minutes/ フォルダに新しい .md と .pdf がコミットされていれば成功です!
4.アーカイブ処理の確認: 最後にNotion側を見て、IsArchived プロパティが自動で「チェック済み」に更新されていることを確認してください。
4. 【技術ハイライト】実務運用に耐えうるための工夫
ここでは、試行錯誤したところを記載します。
① 実行環境での「日本語消失」問題
GitHub Actionsの実行環境(Ubuntu)で最初にPDFを生成したとき、出力されたのは「文字が消えた真っ白なPDF」でした。
- 原因: クラウド上のUbuntuサーバーには日本語フォントが標準搭載されていないため、PDFレンダリング時にフォントが見つからず、すべて空文字として処理されていました
- 突破策: ワークフロー定義(
notion_sync.yml)内で、PDF生成の直前にapt-getを実行し、fonts-noto-cjkを明示的にインストールするようにしました
② 変換エンジン選定:最新よりも「枯れた技術」の安定性
当初は、モダンな WeasyPrint を検討していましたが、Ubuntu 24.04(noble)環境では依存ライブラリ(libpango 等)のバージョン競合により、パッケージが見つからないエラーに直面しました。
- 葛藤: 最新のライブラリで実装したい気持ちもありましたが、環境構築の複雑化はメンテナンスコストを上げます
- 決断: 最終的には、インストールが容易で動作も安定している
wkhtmltopdfを採用しました
③ Notion API の「最新バージョン」への追従
Notion APIを使用していて、特定のプロパティが取得できたりできなかったりと、挙動が不安定になる場面がありました。
- 突破策: APIリクエストのヘッダーに、明示的に最新の
Notion-Version: 2026-03-11を指定しました - 背景: APIの進化が非常に速いサービスでは、バージョンを固定(あるいは最新を明示)しないと、実行時のデフォルト挙動に振り回されるリスクがあります。
④ 冪等性(べきとうせい)の確保:二重実行を許さない設計
自動実行(Cron)と手動実行(Workflow Dispatch)を併用する際、怖いのが「同じ議事録が二度プッシュされる」ことです。
- 工夫:
IsArchivedフラグによる排他制御を行いました- 抽出時に「未アーカイブ」のみを狙い撃つ
- 納品完了直後に「アーカイブ済み」へ更新する
- メリット: この設計により、万が一17時の自動実行が失敗して手動で再実行(連打)したとしても、二重にPDFが生成されることはありません。この「何度叩いても結果が壊れない(冪等性)」が、運用者への安心感に繋がっています
5. おわりに
本パイプラインの導入で真の自動化が進んだと思います。もちろん、これが完成形ではありません。今回の基盤をベースに、以下のような拡張も視野に入れています。
- Slack連携: PDF生成と同時に、要約内容をSlackへ自動投稿し、チーム内での即時共有を強化する。
- 高度なタグ管理: 議事録内の「宿題事項」を自動でGitHub IssuesやNotionのタスクDBへ起票する。
- マルチプロジェクト対応: 案件ごとに保存先リポジトリやディレクトリを自動で振り分ける。
- 格納先をGoogleドライブやSharePointに変更する。
「面倒なことを自動化する」のは、楽しい瞬間の一つです。議事録作成という、泥臭い事務作業ですが、そこにAIと自動化をかけ合わせることで、効率化することができます。この記事が誰かの役に立ったら幸いです。
最後まで読んでいただいた方、ありがとうございました。
参考文献
notion公式ドキュメント(公開日不明)「AI ミーティングノート(ベータ版)」, https://www.notion.com/ja/help/ai-meeting-notes 2026年4月7日アクセス.
notion公式ドキュメント(公開日不明)「Working with page content」, https://developers.notion.com/guides/data-apis/working-with-page-content 2026年4月7日アクセス.
TEMP,円谷様、もい様(2025年9月24日)「【無料テンプレ】Notionで議事録を管理する方法|AIを使った効率化についても解説」, https://temp.co.jp/blog/2023-10-26-meeting-notes 2026年4月7日アクセス.
TEMP,円谷様(2025年5月4日)「Notionインテグレーショントークンの取得方法・コネクト設定方法」, https://temp.co.jp/blog/2024-01-21-notion-integration-connect 2026年4月7日アクセス.
「暮らしとnotion」Rei様(2026年3月7日)「Notionの「AIミーティングノート」で議事録を自動化しよう!使い方や活用法を徹底解説」 https://kurashi-notion.com/blogs/notion/notionai-meetingnotes?srsltid=AfmBOop60jECN0GZLDQ52oZ22n8JHKZ_fl5ccy0eF41FLBdr-WDv1UYa 2026年4月7日アクセス.