概要
Apache AGE 拡張機能がサポートされたことで Azure Database for PostgreSQL flexible server もグラフデータの保存先として注目され始めています。そのため、グラフ指向データベースとして広く利用される Neo4j からの移行を検証してみました。
なぜ Azure Database for PostgreSQL flexible server なのか
Azure Database for PostgreSQL flexible server (PGFX) に関しては、オープンソースの PostgreSQL データベースエンジンに基づき、Azure で利用可能なフルマネージドのデータベースサービスです。近年、生成 AI 関連のアップデートが行われており、AI と共に使うことが意識され始めています。
ChatGPT などの大規模言語モデル (LLM) の機能を拡張するアーキテクチャの RAG (Retrieval-Augmented Generation) は利用が広がりつつありますが、こちらにおいてベクトル型のデータの保存先は必要不可欠です。PGFX では、この AI が生成する埋め込みをベクター型として保存する pgvector をサポートしていることや、Ignite 2024 において DiskANN のプレビューが発表されました。ベクトルが増えると保存コストが高騰する傾向にありますが、DiskANN は効率的にベクトル検索を行うため、メモリ要件を抑えることができるアルゴリズムです。
Enhanced scalability, security, and AI in Azure Database for PostgreSQL
Azure Database for PostgreSQL - フレキシブル サーバーで diskann 拡張機能を有効にして使用する
その中でも、Advance RAG と紹介され、RAG の発展版としてGraphRAG が提唱されています。グラフ指向データベースで格納される関係性を用いることで、今までの RAG では回答できなかった質問に回答できることが期待されます。
Microsoft GraphRAG でこれまでの RAG にはできなかった質問に回答させるメモ
PGFX ではリレーショナルデータベースとしての機能を持ちつつも、グラフ指向データベースとしても利用可能な Apache AGE 拡張機能が有効です。Apache AGE によって、Cypher クエリも以下の形で実行させることが可能です。
SELECT * FROM cypher('graph_name', $$
MATCH (v:Person)
RETURN v.name
$$) AS (v agtype);
PGFX の AGE 拡張機能は作成日時点ではプレビューでした。サポート状況に関しては、公開情報をご確認ください。
Introducing support for Graph data in Azure Database for PostgreSQL (Preview)
この機能も用いた PGFX における GraphRAG の実装に関しては以下の発表がされており、サンプルのソースコードも公開されていますので、ぜひこちらもご参照ください。
Introducing the GraphRAG Solution for Azure Database for PostgreSQL
今回は Apache AGE 拡張機能の検証も兼ねて、グラフ指向データベースとして広く利用される Neo4j からの移行について試してみました。
本情報の内容(添付文書、リンク先などを含む)は、作成日時点でのものであり、予告なく変更される場合があります。
移行手段
現時点で PGFX にグラフデータベースから移行する方法については、python パッケージの AGEfreighter が利用できます。これによって、Neo4j や csv ファイルなどからグラフデータを PGFX に移行することが可能です。
検証手順
Neo4j の環境構築
移行元となる環境を用意するため、Neo4j の構築から始めました。Neo4j の公式の docker イメージが存在しており、docker で構築することが最も簡単であったことから今回はこちらを利用しています。
docker pull neo4j
docker run -d -p 7474:7474 -p 7687:7687 --name neo4j-container neo4j
Localhost 7474 ポートで接続することで、noe4j のログイン画面に遷移し、初回は、ユーザー、パスワード共に neo4j でログインすることができます。
PGFX のデプロイ
Azure Portal に進み、PostgreSQL と検索すると PGFX を確認することができます。以下の公開情報の通り進めて行けば問題ありません。
クイック スタート: Azure portal で Azure Database for PostgreSQL - フレキシブル サーバー インスタンスを作成する
デプロイが完成したら、AGE を有効化します。[設定] -> [サーバーパラメータ] より extension と検索し、AGE を設定することができます。
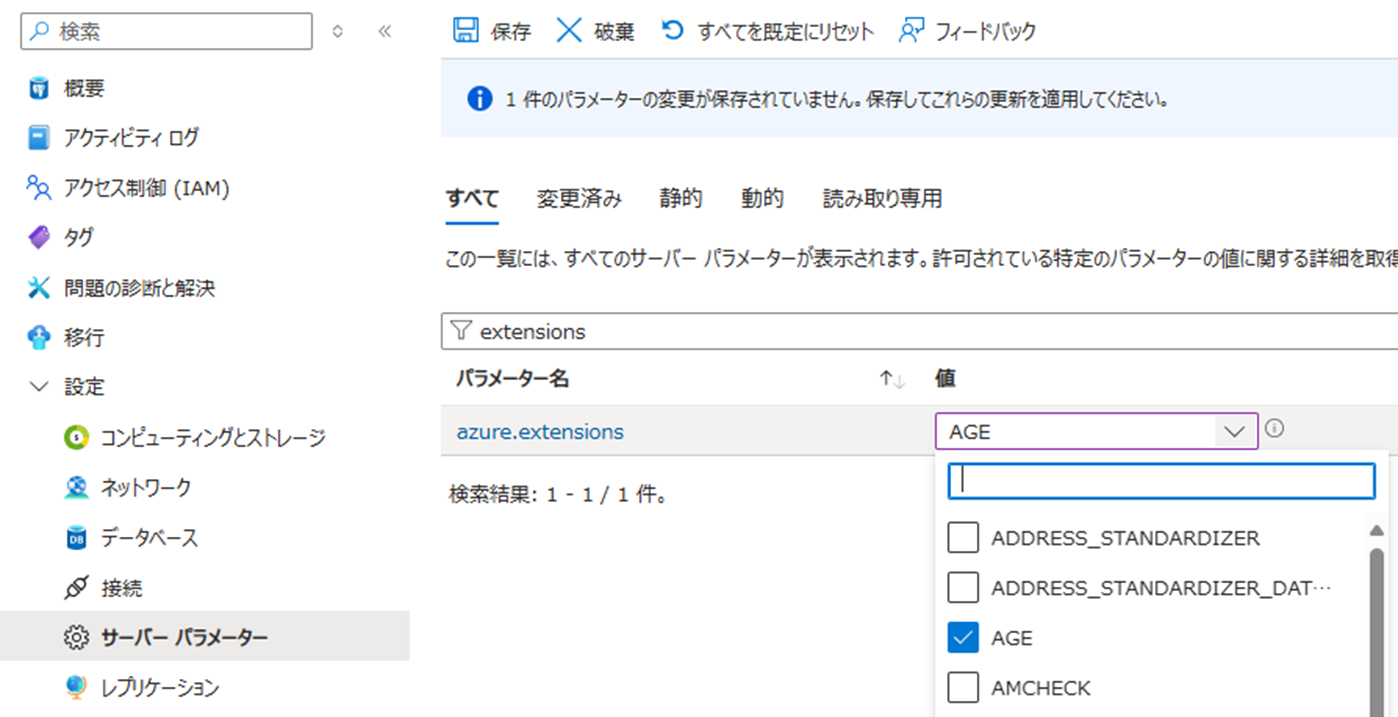
[概要] の [接続] より、データベースに接続することが可能です。
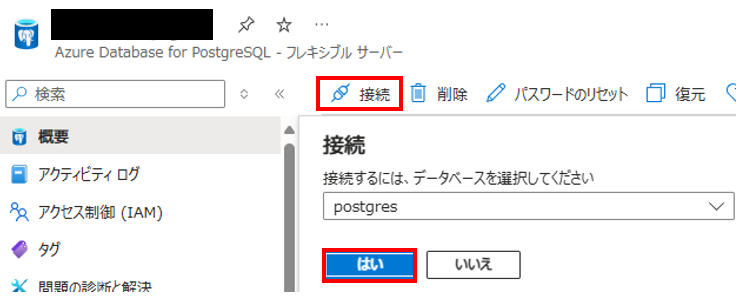
接続したら、以下のクエリを実行して有効化します。
CREATE EXTENSION IF NOT EXISTS age CASCADE;
AGEFreighter の実行
以下の記事を参考に、AGEFreighter の実行を進めていきます。
今回の実行環境は WSL 上の Ubuntu 20.04.3 LTS になります。必要に応じて Python の venv に必要なものを用意しますが、例えば uv の場合は以下でした。
sudo apt-get install libpq-dev
sudo apt-get update
curl -LsSf https://astral.sh/uv/install.sh | sh
Actorfilms.csv データのダウンロードし、実行の Python ファイルに対して ../data 配下に配置しておきます。
actorfilms-graph
# make a directory
uv python install 3.11.1
uv init test
cd test
# create venv
uv venv
source .venv/bin/activate
今回実行したコードは、参考にした記事の test_agefreighter.py から Neo4j のテストだけに限定したものになります。
例えば、code などで python ファイルを作成し、以下の内容で migration_test.py としておきます。
code ./migration_test.py
コードを表示
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import os
import sys
import time
sys.path.append(os.path.join(os.path.dirname(__file__), "../src/"))
import asyncio
from agefreighter import AgeFreighter
import networkx as nx
import pandas as pd
# for environment where PostgreSQL is not capable of loading data from local files, e.g. Azure Database for PostgreSQL
# file downloaded from https://www.kaggle.com/datasets/darinhawley/imdb-films-by-actor-for-10k-actors
# actorfilms.csv: Actor,ActorID,Film,Year,Votes,Rating,FilmID
# # of actors: 9,623, # of films: 44,456, # of edges: 191,873
# test for loadFromNeo4j
# create networkx graph from actorfilms.csv
# after creating networkx graph, load it to a graph
async def test_loadFromNeo4j(
af: AgeFreighter,
chunk_size: int = 96,
direct_loading: bool = False,
use_copy: bool = False,
init_neo4j: bool = False,
) -> None:
try:
n4j_uri = os.environ["NEO4J_URI"]
n4j_user = os.environ["NEO4J_USER"]
n4j_password = os.environ["NEO4J_PASSWORD"]
except KeyError:
print(
"Please set the environment variables NEO4J_URI, NEO4J_USER, NEO4J_PASSWORD"
)
return
# prepare test data for neo4j
if init_neo4j:
await loadTestDataToNeo4j(n4j_uri, n4j_user, n4j_password)
start_time = time.time()
graph_name = "actorfilms"
await af.loadFromNeo4j(
uri=n4j_uri,
user=n4j_user,
password=n4j_password,
neo4j_database="neo4j",
graph_name=graph_name,
id_map={"Actor": "ActorID", "Film": "FilmID"},
chunk_size=chunk_size,
direct_loading=direct_loading,
drop_graph=True,
use_copy=use_copy,
)
print(
f"test_loadFromNeo4j : time, {time.time() - start_time:.2f}, chunk_size: {chunk_size}, direct_loading: {direct_loading}, use_copy: {use_copy}"
)
# load test data to neo4j
# file downloaded from https://www.kaggle.com/datasets/darinhawley/imdb-films-by-actor-for-10k-actors
async def loadTestDataToNeo4j(
n4j_uri: str = "",
n4j_user: str = "",
n4j_password: str = "",
) -> None:
from neo4j import AsyncGraphDatabase
batch_size = 1000
df = pd.read_csv("../data/actorfilms.csv")
uniq_actors = df[["ActorID", "Actor"]].drop_duplicates()
uniq_films = df[["FilmID", "Film", "Year", "Votes", "Rating"]].drop_duplicates()
async with AsyncGraphDatabase.driver(
n4j_uri, auth=(n4j_user, n4j_password)
) as driver:
async with driver.session() as session:
# clear the database
await session.run("MATCH (a)-[r]->() DELETE a, r")
await session.run("MATCH (a) DELETE a")
await session.run("DROP INDEX actor_index_id IF EXISTS")
await session.run("DROP INDEX film_index_id IF EXISTS")
await session.run(
"CREATE INDEX actor_index_id FOR (n:Actor) ON (n.ActorID)"
)
await session.run("CREATE INDEX film_index_id FOR (n:Film) ON (n.FilmID)")
# create actor nodes
for idx in range(0, len(uniq_actors), batch_size):
actors = [
{"Actor": actor, "ActorID": actorid}
for i, (actor, actorid) in enumerate(
zip(
uniq_actors["Actor"][idx : idx + batch_size].tolist(),
uniq_actors["ActorID"][idx : idx + batch_size].tolist(),
)
)
]
await session.run(
"""UNWIND $actors AS row
CREATE (a:Actor)
SET a += row""",
actors=actors,
)
# create film nodes
for idx in range(0, len(uniq_films), batch_size):
films = [
{
"Film": film,
"FilmID": filmid,
"Year": year,
"Votes": votes,
"Rating": rating,
}
for i, (film, filmid, year, votes, rating) in enumerate(
zip(
uniq_films["Film"][idx : idx + batch_size].tolist(),
uniq_films["FilmID"][idx : idx + batch_size].tolist(),
uniq_films["Year"][idx : idx + batch_size].tolist(),
uniq_films["Votes"][idx : idx + batch_size].tolist(),
uniq_films["Rating"][idx : idx + batch_size].tolist(),
)
)
]
await session.run(
"""UNWIND $films AS row
CREATE (f:Film)
SET f += row""",
films=films,
)
# create edges
for idx in range(0, len(df), batch_size):
acted_ins = [
{"from": actorid, "to": filmid}
for i, (actorid, filmid) in enumerate(
zip(
df["ActorID"][idx : idx + batch_size].tolist(),
df["FilmID"][idx : idx + batch_size].tolist(),
)
)
]
await session.run(
"""UNWIND $acted_ins AS row
MATCH (from:Actor {ActorID: row.from})
MATCH (to:Film {FilmID: row.to})
CREATE (from)-[r:ACTED_IN]->(to)
SET r += row""",
acted_ins=acted_ins,
)
async def main() -> None:
# export PG_CONNECTION_STRING="host=your_server.postgres.database.azure.com port=5432 dbname=postgres user=account password=your_password"
try:
connection_string = os.environ["PG_CONNECTION_STRING"]
except KeyError:
print("Please set the environment variable PG_CONNECTION_STRING")
return
try:
af = await AgeFreighter.connect(dsn=connection_string, max_connections=64)
# Strongly reccomended to define chunk_size with your data and server before loading large amount of data
# Especially, the number of properties in the vertex affects the complecity of the query
# Due to asynchronous nature of the library, the duration for loading data is not linear to the number of rows
#
# Addition to the chunk_size, max_wal_size and checkpoint_timeout in the postgresql.conf should be considered
test_set = [
[True, False],
]
chunk_size = 128
do = True
if do:
[
await test_loadFromNeo4j(
af,
chunk_size=chunk_size,
direct_loading=direct_loading,
use_copy=use_copy,
init_neo4j=True,
)
for idx, (direct_loading, use_copy) in enumerate(test_set)
]
print(
"test_loadFromNeo4j done\n"
"##### The duration for test_loadFromNeo4j depends on the performance of the neo4j server. #####\n"
)
finally:
await af.pool.close()
if __name__ == "__main__":
asyncio.run(main())
python ファイルの作成が完了したら、PG_CONNECTION_STRING、NEO4J_URI、NEO4J_USER、NEO4J_PASSWORD を環境に合わせて編集します。
今回は docker で動かしているので、NEO4J_URI は localhost の 7687 ポートになります。
# add AGEFreighter
uv add agefreighter
# export an env var
# Azure
export PG_CONNECTION_STRING="<host=your_server>.postgres.database.azure.com port=5432 dbname=postgres user=<account> password=<your_password>"
# Neo4j
export NEO4J_URI="neo4j://localhost:7687"
export NEO4J_USER="neo4j"
export NEO4J_PASSWORD="<your_password>"
chmod 755 migration_test.py
./migration_test.py
実行が終わると以下のような結果が返されます。
test_loadFromNeo4j : time, 263.38, chunk_size: 128, direct_loading: True, use_copy: False
test_loadFromNeo4j done
実際にデータが移行されているかどうかを PGFX にログインして確認します。
psql -h <your_server>.postgres.database.azure.com -p 5432 -d postgres -U <account>
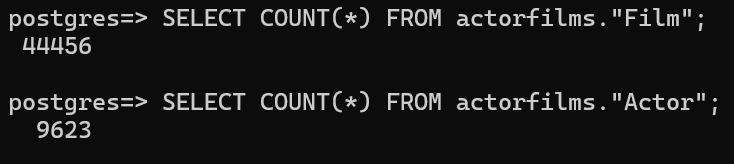
ログインが完了したら、データベースにて以下のクエリを実行することで Film ノードと Actor ノードの数を確認できます。
SET search_path = ag_catalog, "$user", public;
SELECT COUNT(*) FROM actorfilms."Film";
SELECT COUNT(*) FROM actorfilms."Actor";
今回のデータでは、移行が成功すると以下のような結果が返ってくることが期待されます。
また、以下のような Cypher クエリを実行すると関係が ACTED_IN である Actor と Film を抽出可能です。なお、PGFX 上でグラフデータは、出力結果にあるように id でそれぞれがテーブルに管理されています。そのため、リレーショナルデータベースのインデックスを貼ることができ、パフォーマンスチューニングを実施可能です。
SELECT * FROM cypher('AgeTester', $$ MATCH p=()-[r:ACTED_IN]->() RETURN (p) LIMIT 2 $$) as (p agtype);
p
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
[{"id": 844424930132557, "label": "Actor", "properties": {"id": "nm0000012", "Actor": "Bette Davis"}}::vertex, {"id": 1407374883553281, "label": "ACTED_IN", "end_id": 1125899906843796, "start_id": 844424930132557, "properties": {}}::edge, {"id": 1125899906843796, "label": "Film", "properties": {"id": "tt0023856", "Film": "Bureau of Missing Persons", "Year": "1933", "Votes": "1106", "Rating": "6.7"}}::vertex]::path
[{"id": 844424930132557, "label": "Actor", "properties": {"id": "nm0000012", "Actor": "Bette Davis"}}::vertex, {"id": 1407374883553282, "label": "ACTED_IN", "end_id": 1125899906843797, "start_id": 844424930132557, "properties": {}}::edge, {"id": 1125899906843797, "label": "Film", "properties": {"id": "tt0024785", "Film": "The Working Man", "Year": "1933", "Votes": "952", "Rating": "7.4"}}::vertex]::path
(2 rows)
まとめ
生成 AI アプリケーションのデータベースとして注目される Azure Database for PostgreSQL flexible server へ、AGEFreighter を用いた Neo4j からの移行を検証しました。Cypher クエリも実行することができ、リレーショナルデータベースにおけるチューニングも適用できることから、グラフデータベースとして期待がされます。今後は、PGFX での GraphRAG 関連のアップデートに関して触れてみたいと思います。