1. この記事は何?
この記事では、Google Cloud の Vertex AI Studio で利用できる Grounding with Google Search オプションを活用し、生成された回答に「参考文献の番号付け」と「回答根拠」を付与する方法をVertex AI SDKを用いてWebアプリに組み込む手順を紹介します。
また実装していくにあたり、Protocol Buffers についての簡単な理解もできたので紹介します。
2. やりたいこと
Vertex AI Studio の Grounding with Google Search オプションを有効化すると、Google 検索結果を根拠とした回答とともに、「参考文献の番号付け」と「回答の根拠」が合わせて出力されます。
本記事では、この機能をWebアプリに組み込むための具体的な手順を解説します。
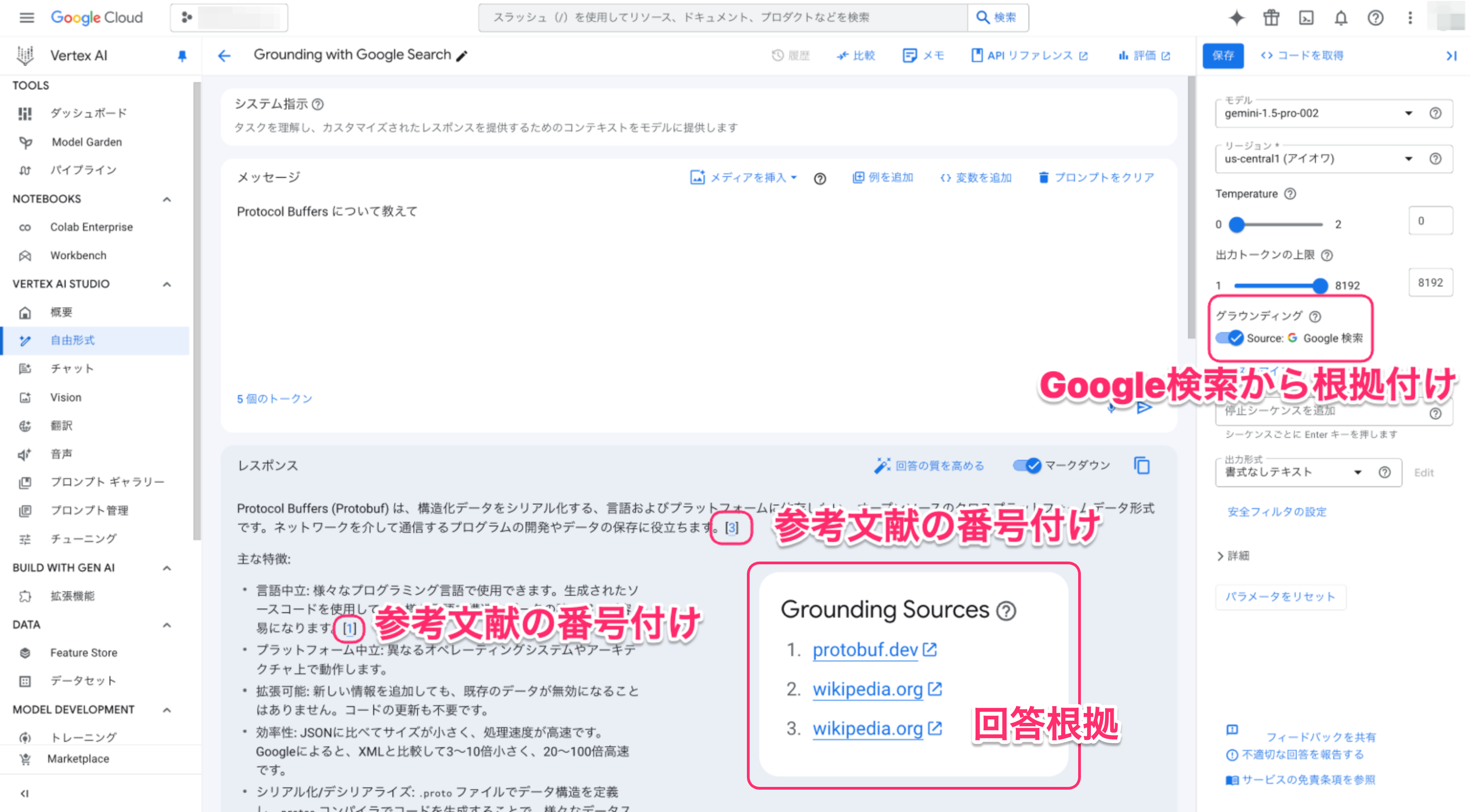
3. 現在の動作の確認
Vertex AI Studio がどのように「参考文献の番号付け」と「回答の根拠」を返しているのか、まずは現状の動作を確認します。
3.1 Colab で実行
Vertex AI Studio で実行した内容は右上のコードを取得から、Vertex AI SDK を用いてどのようなコードを書けばいいのかを確認することができます。
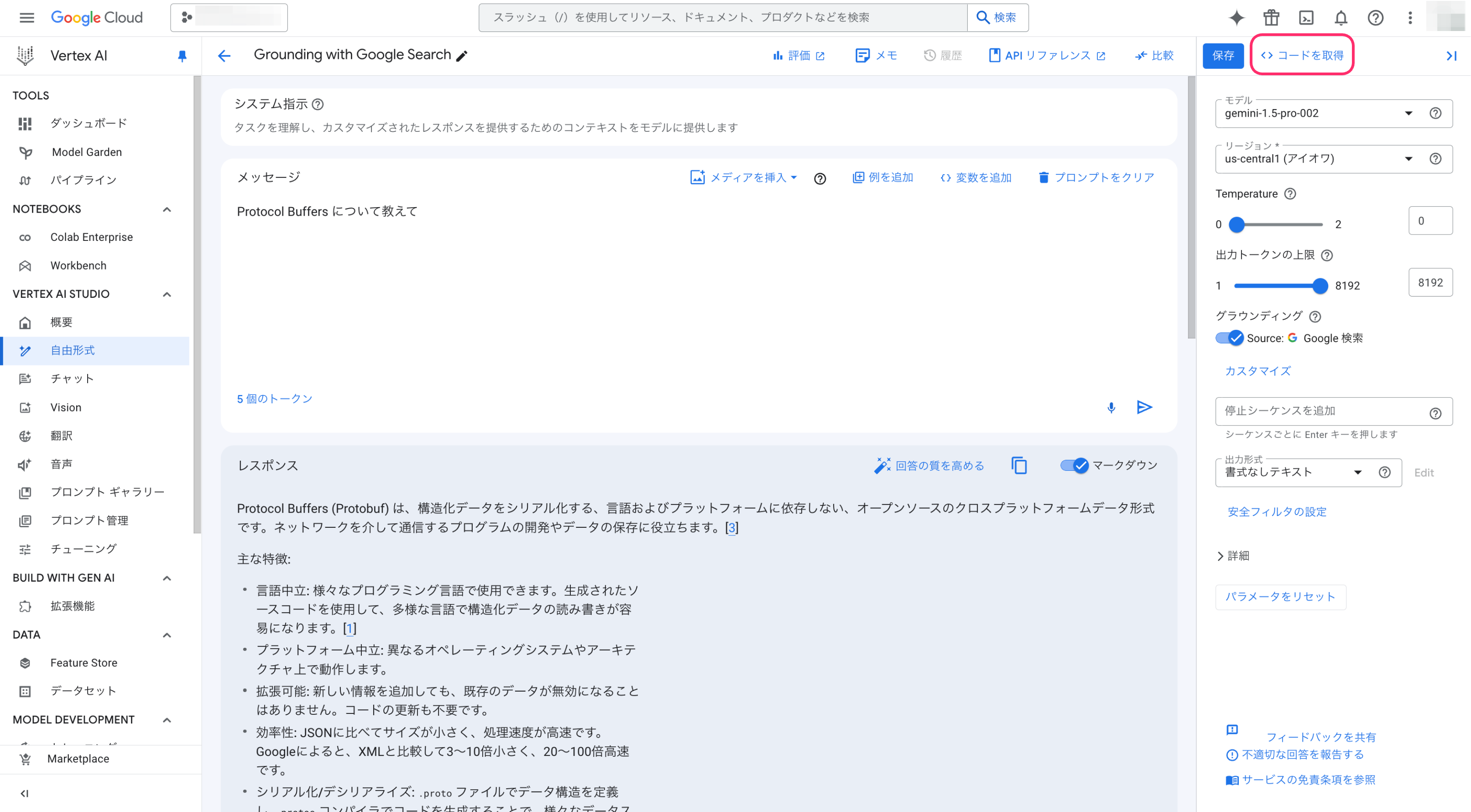
コードを取得を押下すると以下のようなモーダルが開きます。
今回は、Colab を使いたいのでPython を選択します。そのままノートブックを開くを選択します。
Colab が開き、右上のインスタンスの接続が完了したら、コードを実行します。
3.2 レスポンスの確認
レスポンスを確認します。コードブロックにすると長くなってしまうため、ここでは画像で簡単に確認します。
一見するとJSONのように見えますが、実際には Protocol Buffers(Protobuf) というスキーマ言語で表現されたデータになっています。Protobufは、Googleが開発した効率的なデータシリアライズフォーマットで、階層的な構造を持つ点が特徴です。

4. Protocol Buffers について(スキップ可能)
さて、ここでProtocol Buffers(Protobuf)とは何かを説明しJSON との比較を行います。
普段の開発でGolang やgRPC を扱っている方であれば馴染みあるものかもしれませんが、私はProtobuf の存在を知らず苦戦しました。
4.1 Protocol Buffers とは?
公式ドキュメントはこちらです。
Protocol buffers are Google’s language-neutral, platform-neutral, extensible mechanism for serializing structured data – think XML, but smaller, faster, and simpler.
Protocol Buffers とはGoogle が開発した構造化データをシリアライズするための技術です。
話が脱線してしまうので、特徴を簡単にまとめると以下の通りです。
- Google が開発
- バイナリ形式でシリアライズ・デシリアライズが可能
- テキスト形式でもシリアライズできる
今回のColab で出力された内容はこの「テキスト形式」のProtobuf によるものです。テキスト形式の仕様についてはこちら で確認できます。
4.2 JSON との比較
テキスト形式のProtobufとJSONを比較すると、以下のような違いがあります。一見すると、似ていますが異なる構造をしています。
Protobuf Text Formatの例
candidates {
content {
role: "model"
parts {
text: "Protocol Buffersは..."
}
}
avg_logprobs: -0.0708988039512334
finish_reason: STOP
}
JSONの例
{
"candidates": [
{
"content": {
"role": "model",
"parts": [
{
"text": "Protocol Buffersは..."
}
]
},
"avg_logprobs": -0.0708988039512334,
"finish_reason": "STOP"
}
]
}
5. レスポンス構造の理解
ここでは、コンソールで表示される「参考文献の番号付け」や「回答根拠」はレスポンスからどの部分に含まれているのか確認します。
5.1 レスポンス全体の構造
以下はVertex AIのレスポンス例です。
candidates {
content {
role: "model"
parts {
text: "Protocol Buffers (Protobuf) は、Google によって開発された構造化データをシリアライズする..."
}
}
avg_logprobs: -0.0708988039512334
finish_reason: STOP
}
grounding_metadata {
web_search_queries: "Protocol Buffers"
}
grounding_chunks {
web {
uri: "https://example.com/protobuf-doc"
title: "Protocol Buffers Documentation"
}
}
grounding_supports {
segment {
start_index: 0
end_index: 76
text: "Protocol Buffers (Protobuf) は、Google によって開発された..."
}
grounding_chunk_indices: 0
confidence_scores: 0.95
}
5.2 着目するポイント
-
partsのtext- 生成AI からの回答がここに格納されています
-
grounding_chunks- Grounding した際に根拠としたWebページとページタイトルが格納されています
-
grounding_supports-
parts.textの特定部分に対して、どの参考文献が根拠となったかを示します-
segment-
start_index: 関連部分が始まる位置 -
end_index: 関連部分が終わる位置 -
text: 関連部分の具体的なテキスト
-
-
grounding_chunk_indices- どの
grounding_chunksをに対応しているかをindex で示します
- どの
-
-
これらのレスポンスを使用して、コンソールでは参考文献の根拠付けを行なっていたことがわかりました。
6. 実装
それでは実際にコードを書いていきましょう。
6.1 Protobuf → 辞書形式 の変換
デフォルトではProtobufで返ってきてしまうため、Python 側で扱いやすくするため辞書式に変換してあげます。
# Protobuf形式のレスポンスを辞書形式へ変換
response_dict = response.to_dict()
すると画像のように辞書形式で返却されます。

6.2 参考文献の番号付けと回答根拠の実装
辞書形式でレスポンスを扱えるようになったので、次に「参考文献の番号付け」と「回答根拠の実装」を行います。
6.2.1 レスポンステキストの抽出
まず、レスポンスからテキスト部分を抽出します。
# レスポンステキストの抽出
response_text = response_dict['candidates'][0]['content']['parts'][0]['text']
6.2.2 参考文献の抽出と番号付け
次に、レスポンスに含まれる参考文献情報を抽出し、番号を付与します。
# 参考文献の抽出と番号付け
grounding_chunks = response_dict['candidates'][0].get('grounding_metadata', {}).get('grounding_chunks', [])
references = {}
for i, chunk in enumerate(grounding_chunks):
if 'web' in chunk:
references[chunk['web']['uri']] = f"[{i+1}] {chunk['web']['title']}: {chunk['web']['uri']}"
6.2.3 レスポンステキスト内の参照箇所に参考文献番号を挿入
最後に、レスポンステキスト内の該当箇所に参考文献番号を挿入します。
# レスポンステキスト内の参照箇所に参考文献番号を挿入
numbered_response = ""
for line in response_text.split("\n"):
modified_line = line
if 'grounding_supports' in response_dict['candidates'][0]['grounding_metadata']:
for support in response_dict['candidates'][0]['grounding_metadata']['grounding_supports']:
if support['segment']['text'] in line:
for chunk_index in support['grounding_chunk_indices']:
if 'web' in grounding_chunks[chunk_index]:
uri = grounding_chunks[chunk_index]['web']['uri']
if uri in references:
modified_line = modified_line.replace(support['segment']['text'], f"{support['segment']['text']} {references[uri].split(' ')[0]}")
numbered_response += f"{modified_line}\n"
6.3 結果の出力
最後に、整形されたレスポンステキストと参考文献リストを出力します。
# 結果の出力
print("回答:")
print(numbered_response)
print("\n参考文献:")
for ref in references.values():
print(ref)
実行結果を確認すると、Vertex AI Studio と同様に「参考文献の番号付け」と「回答の根拠」が出力することに成功しました👏

7. おわり
Vertex AI SDK を用いた回答根拠付きのAPI 実装についての紹介は以上となります。
今回は、Grounding with Google Search(Google 検索)を例に挙げましたが、データソースを指定した場合でも同様の構造で返ってくるため、Google Cloud を用いてRAGアプリケーションを構築する際はお役に立てれば幸いです。
参考
今回作成したコード全体は以下になります。
import vertexai
from vertexai.preview.generative_models import GenerativeModel, SafetySetting, Tool
from vertexai.preview.generative_models import grounding
generation_config = {
"max_output_tokens": 8192,
"temperature": 0,
"top_p": 0.95,
}
safety_settings = [
SafetySetting(
category=SafetySetting.HarmCategory.HARM_CATEGORY_HATE_SPEECH,
threshold=SafetySetting.HarmBlockThreshold.OFF
),
SafetySetting(
category=SafetySetting.HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT,
threshold=SafetySetting.HarmBlockThreshold.OFF
),
SafetySetting(
category=SafetySetting.HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT,
threshold=SafetySetting.HarmBlockThreshold.OFF
),
SafetySetting(
category=SafetySetting.HarmCategory.HARM_CATEGORY_HARASSMENT,
threshold=SafetySetting.HarmBlockThreshold.OFF
),
]
tools = [
Tool.from_google_search_retrieval(
google_search_retrieval=grounding.GoogleSearchRetrieval()
),
]
def generate():
vertexai.init(project="{プロジェクト名}", location="{リージョン}")
model = GenerativeModel(
"gemini-1.5-pro-002",
tools=tools,
)
response = model.generate_content(
["Gemini について教えて(プロンプト例)"],
generation_config=generation_config,
safety_settings=safety_settings,
)
# Protobuf形式のレスポンスを辞書形式へ変換
response_dict = response.to_dict()
# レスポンステキストの抽出
response_text = response_dict['candidates'][0]['content']['parts'][0]['text']
# 参考文献の抽出と番号付け
grounding_chunks = response_dict['candidates'][0].get('grounding_metadata', {}).get('grounding_chunks', [])
references = {}
for i, chunk in enumerate(grounding_chunks):
if 'web' in chunk:
references[chunk['web']['uri']] = f"[{i+1}] {chunk['web']['title']}: {chunk['web']['uri']}"
# レスポンステキスト内の参照箇所に参考文献番号を挿入
numbered_response = ""
for line in response_text.split("\n"):
modified_line = line
if 'grounding_supports' in response_dict['candidates'][0]['grounding_metadata']:
for support in response_dict['candidates'][0]['grounding_metadata']['grounding_supports']:
if support['segment']['text'] in line:
for chunk_index in support['grounding_chunk_indices']:
if 'web' in grounding_chunks[chunk_index]:
uri = grounding_chunks[chunk_index]['web']['uri']
if uri in references:
modified_line = modified_line.replace(support['segment']['text'], f"{support['segment']['text']} {references[uri].split(' ')[0]}")
numbered_response += f"{modified_line}\n"
# 結果の出力
print("回答:")
print(numbered_response)
print("\n参考文献:")
for ref in references.values():
print(ref)
generate()