違うディレクトリファイルの中に、
同じキーワードを含むファイルの存在があるか、
チェックする方法です!
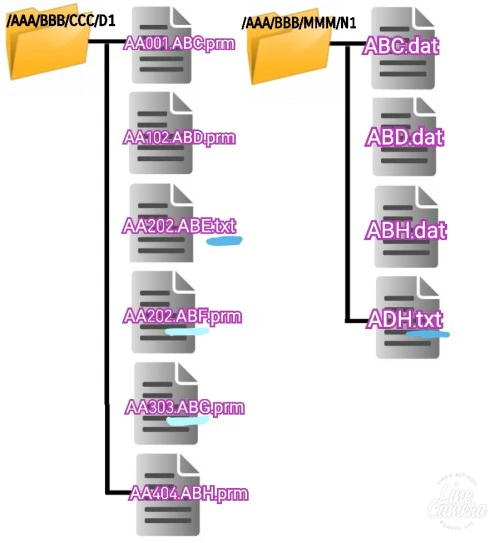
D1、D2ファイルには、それぞれ.txtファイルも含まれていて、
キーワードの違うファイルも存在している例とします。
作業内容
・/AAA/BBB/CCC/D1 ディレクトリ内の.prmファイルに含まれるキーワード
・/AAA/BBB/MMM/N1 ディレクトリ内の.datファイルに含まれるキーワード
それぞれのキーワードが一致するファイルの存在をチェックする
作業手順
①ファイルが入っているディレクトリの存在チェック
・ディレクトリが存在する→存在確認表示、作業を続行
・ディレクトリが存在しない→存在未確認表示、作業を中断
※ディレクトリの存在確認の方法については、こちらで説明をしていますので、
今回は省略させていただきます。
②ファイルリスト取得
・/AAA/BBB/CCC/D1/ディレクトリ中の”.prm”ファイル
・/AAA/BBB/MMM/N1/ディレクトリ中の”.dat”ファイル
③ファイルのキーワード取得
③-1 /AAA/BBB/CCC/D1ディレクトリ内の.prmファイルの
6~8バイト目のキーワードを取得
例:AA001.ABC.prm → ABC (0バイト数からのカウントとする)
③-2 /AAA/BBB/CCC/D2ディレクトリ内の.datファイルの
0~2バイト目のキーワードを取得
例:ABC.dat → ABC (0バイト数からのカウントとする)
④同じキーワードを含むファイル名か、比較チェック
同じ→存在確認表示:OK , ベース比較キーワード+ファイル名表示 = 比較キーワード+ファイル名表示
違う→存在未確認表示:NG , ベース比較キーワード+ファイル名表示
# 初期設定
#格納ディレクトリ
DIR_prm ='/AAA/BBB/CCC/D1/'
DIR_dat ='/AAA/BBB/MMM/N1/'
# ファイルリスト取得
#".prm"ファイルリスト
list_prm = $(ls ${DIR_prm} | grep ".prm")
#".dat"ファイルリスト
list_dat = $(ls ${DIR_dat} | grep ".dat")
# ファイルのキーワード取得(.prm D1内ファイルの数分に合わせて.dat N1ファイルも確認)
#ファイル数分ループ(.prm D1)
for file_prm in ${list_prm[@]}
do
#ファイル名抽出
file_name_prm = $(basename ${file_prm})
#キーワード抽出 (6~8バイト目)
file_key_prm = ${file_prm:6:8}
# echo 'file_key_prm = ${file_key_prm} <${file_name_prm}>'
chk_flg = 0
#ファイル数分ループ(.dat N1)
for file_dat in ${list_dat[@]}
do
#ファイル名抽出
file_name_dat = $(basename ${file_dat})
#キーワード抽出 (0~2バイト目)
file_key_dat = ${file_dat:0:2}
# echo 'file_key_dat = ${file_key_dat} <${file_name_dat}>'
#キーワード比較
#一致する
if ["${file_key_prm}" = "${file_key_dat}" ]:then
echo "OK : prm-dat:${file_key_prm}<${file_name_prm}> = ${file_key_dat}<${file_name_dat}>"
chk_flg = 1
else
echo "NO : prm-dat:${file_key_prm}<${file_name_prm}>"
break
fi
done
echo "-----------------------------------------------------"
#ファイルのキーワード取得(.dat N1内ファイルの数分に合わせて.prm D1ファイルも確認)
#ファイル数分ループ(.dat N1)
for file_dat in ${list_dat[@]}
do
#ファイル名抽出
file_name_dat = $(basename ${file_dat})
#キーワード抽出 (6~8バイト目)
file_key_dat = ${file_dat:0:2}
# echo 'file_key_dat = ${file_key_dat} <${file_name_dat}>'
chk_flg = 0
#ファイル数分ループ(.prm D1)
for file_prm in ${list_prm[@]}
do
#ファイル名抽出
file_name_prm = $(basename ${file_prm})
#キーワード抽出 (0~2バイト目)
file_key_prm = ${file_prm:6:8}
# echo 'file_key_prm = ${file_key_prm} <${file_name_prm}>'
#キーワード比較
#一致する
if ["${file_key_dat}" = "${file_key_prm}" ]:then
echo "OK : dat-prm:${file_key_dat}<${file_name_dat}> = ${file_key_prm}<${file_name_prm}>"
chk_flg = 1
break
fi
done
#一致しない
if [ ${chk_flg} -eq 0]:then
echo "NO : dat-prm:${file_key_dat}<${file_name_dat}>"
fi
done
説明
① grep ".rog"によって、".rog"を含むリストを作成し、
そのリストの中で"ABC"などのキーワードを含むファイルの存在をチェックしています。
② 片方のディレクトリファイル内(D1またはN1)のファイル数分
ループするようにしているので、D1ファイル数分ベースの確認が終わったら、
N1ファイル数分もループするようにしています。
③ chk_flg による判定 0 → 存在しない 1 → 存在する
④ 個人的に結果が分かりやすいように、②のループベースが一つ終わったら、
`-------の仕切りをつけています。