はじめに
Datadogダッシュボードのウィジェットにおいて、アプリケーションのログベースでAPI Count数等を表示させる際、DatadogのCategory Processorを使って楽しようと模索した方法をまとめます。
この記事の背景
一体どういうこと?というのを少し補足します。
例えばあるサービスのシステムの概況を把握するため、Datadogのダッシュボードを使っています。
Datadogにはアプリケーションサーバのログを流しており、そのログをベースに各パス毎のカウント数(リクエスト数)やduration等をウィジェットとして表示したいとしましょう。
存在するアプリケーションのパスがパラメータを含まないものであれば話は簡単で、path毎にgroup byする以下のようなクエリを書けば良いかもしれません。
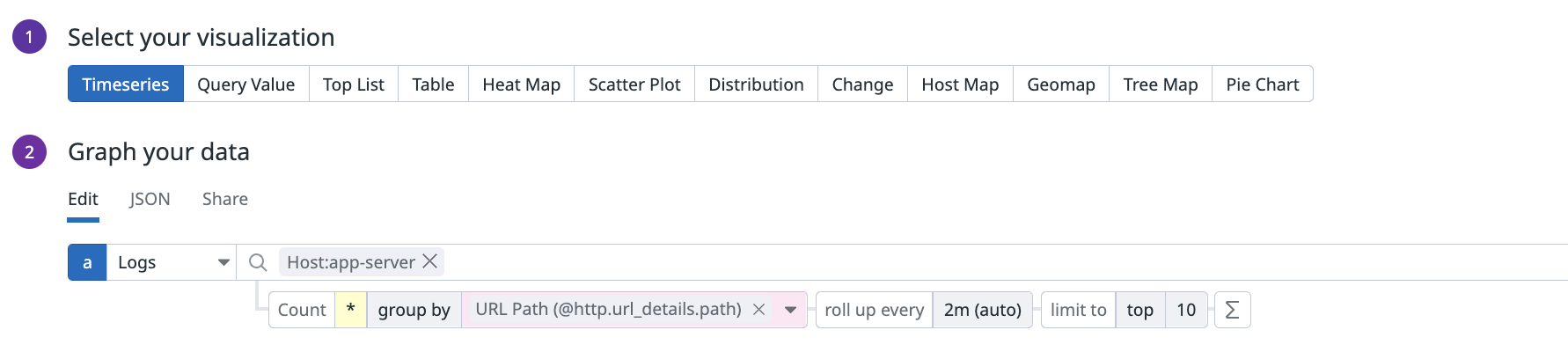
ですが、パスにパラメータを含む場合にこれをやるとどうなるかというと、それぞれがユニークパスとして認識されてしまい、結局どのパスなのか見通しが悪くなります。
なので以下のような指定をせざるを得ない状況があったのですが、これが結構地獄でした。
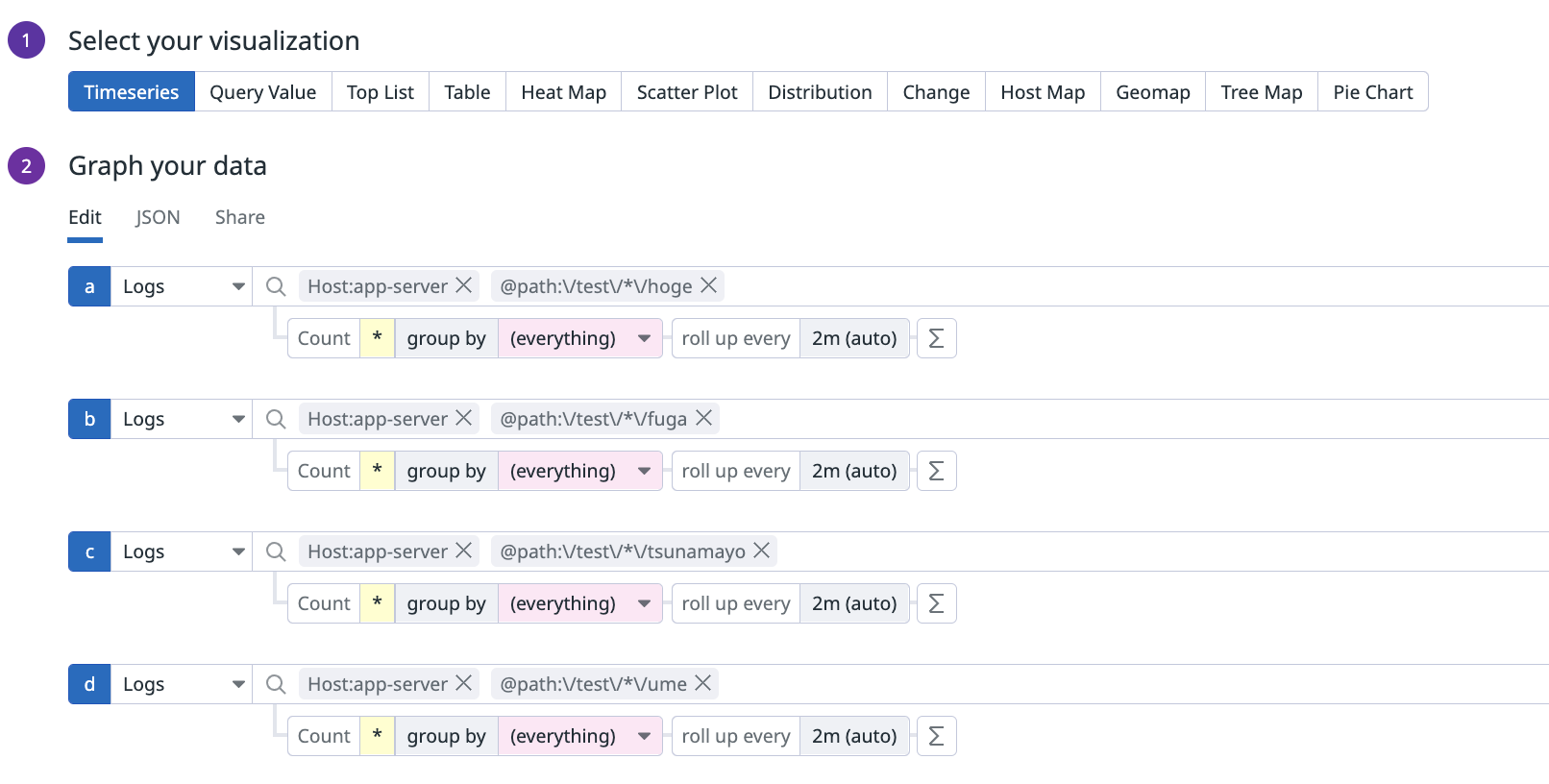
これをダッシュボードに多数存在するウィジェット毎に指定して回るのが面倒なのと、コード管理していてもウィジェット毎にミスコンフィギュレーションが起こりやすいという課題がありました。
どうするか
今回はDatadogが提供しているCategory Processorというものを使って、ログに新たにフィールドを追加するアプローチを試しました。
(ログはDatadogに流しているCloudWatchログを利用して以降の作業をしましたが、流し込み方については本記事では触れません。)
行った作業としては非常にシンプルで、以下3つです。
- Pipelineの追加
- Category Processorの追加
- ダッシュボードに存在するウィジェットのクエリ定義修正
1.Pipelineの追加
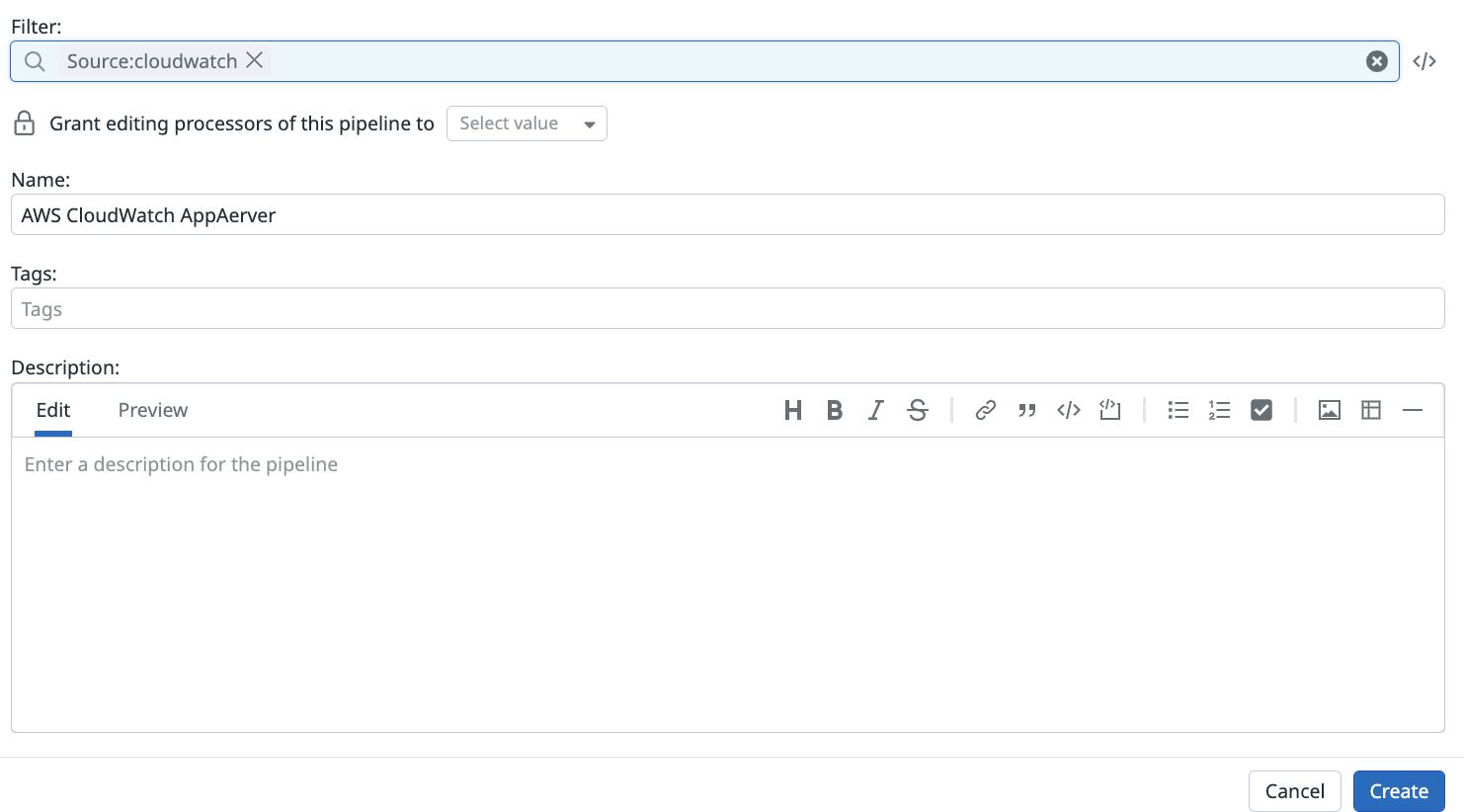
まずは以下のようにPipelineを追加します。
Datadogにログを送るとまず最初にパイプラインを通るのですが、ここで様々な処理を加えることが可能です。
Logs > Configuration > PIPELINESのAdd a new pipelineから新しくパイプラインを追加します。
ひとまず以下を指定しましたが、複数AWSアカウントや複数アプリケーションのログを連携している場合はパイプライン側でアカウントや対象アプリケーションログなどを絞ると良さそうです。(後続の2で設定するプロセッサー側では絞れなかったため)
2.Category Processorの追加
追加したパイプライン対してAdd ProcessorからCategory Processorを追加します。
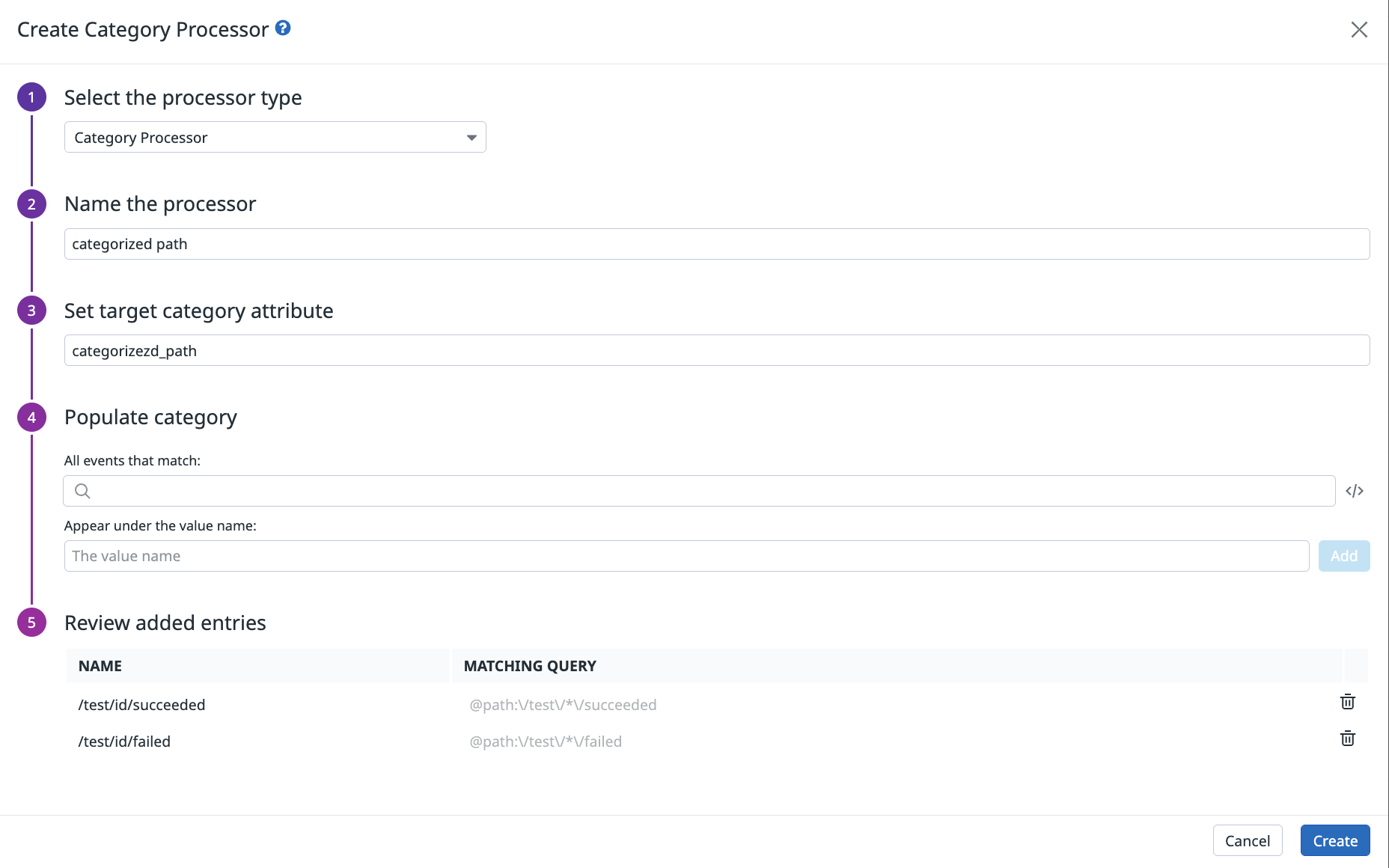
この設定により、MATCHING QUERYで指定した条件に一致したログには③Set target category attribuuteで指定したアトリビュートが追加されます。
▼例(大分省略しています)
categorized_pathというアトリビュートが追加されています
{
"id": "*********",
"content": {
"timestamp": "2022-12-16T12:21:57.379Z",
"tags": [
"source:cloudwatch",
"forwardername:datadog-log-for-forwarder",
"sourcecategory:aws",
],
"host": "/eks/test/app-server",
"service": "cloudwatch",
"attributes": {
"duration": 1,
"path": "/measurements/abcdefg/succeeded",
"categorized_path": "/measurements/id/succeeded",
"code": 200,
"time": "2022-12-16T12:22:06.063435255Z"
}
}
}
3.ダッシュボードに存在するウィジェットのクエリ定義修正
最終的にはダッシュボードのウィジェットでのクエリ定義を楽にしたいので、追加されたアトリビュートでgroup by指定をします。
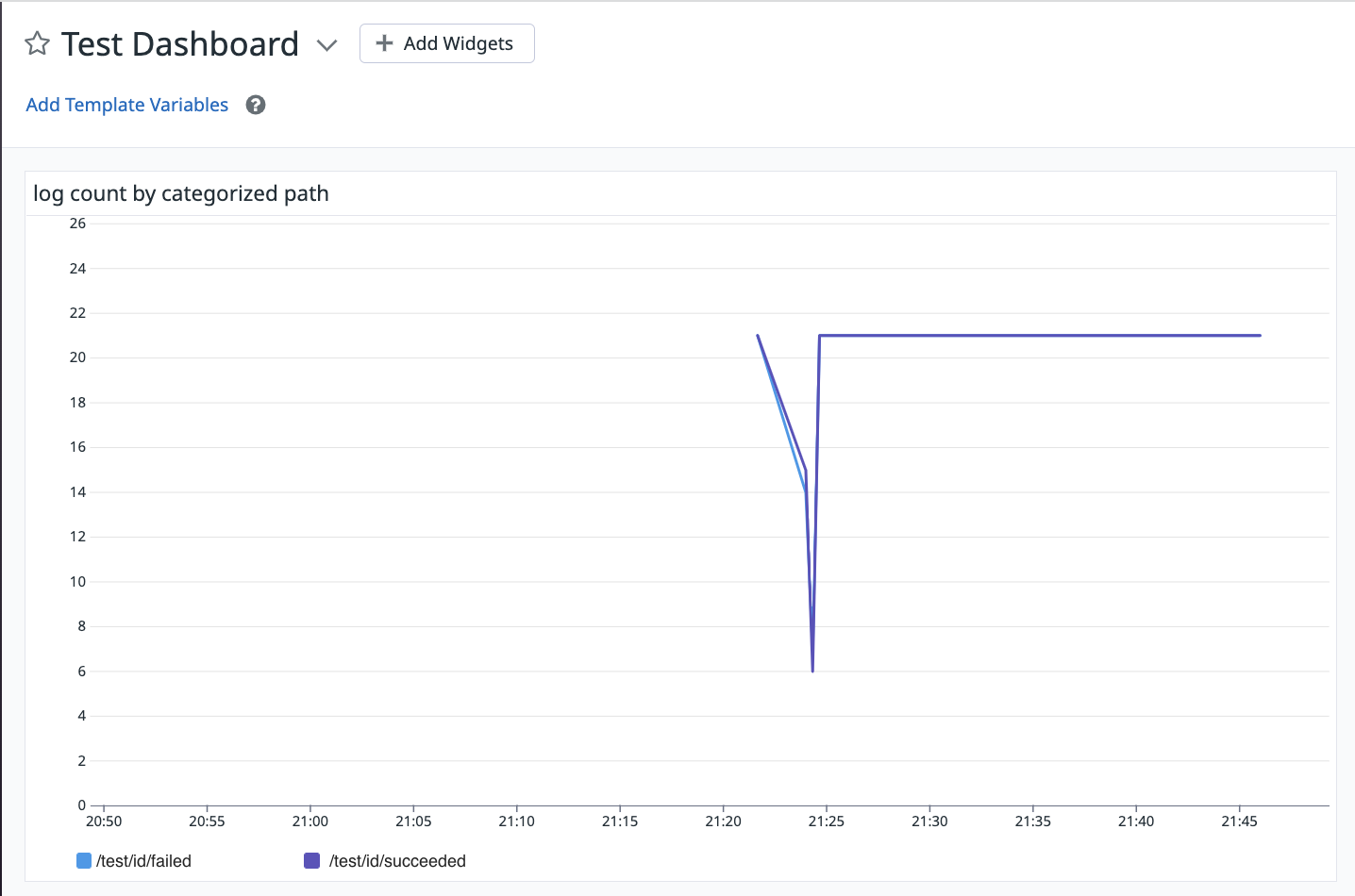
最終的には、以下の様に追加されたアトリビュートの値で表示されるようになります。
おまけ: 1~3の作業をTerraformで書くとどうなるか
実はモニターやダッシュボードはTerraformでコード化してきているのですが、この辺の設定はコード化できていなかったので試しにやってみました。
リソースは主にdatadog_logs_custom_pipeline (Resource)を使うと良さそうです。
パス表記の/test/*/succeededでスラッシュをエスケープするためのバックスラッシュをさらにエスケープしなければならなかったのですが、そのことに気づくまでに少々詰まってしまいました。
terraform {
required_providers {
datadog = {
source = "DataDog/datadog"
version = "3.18.0"
}
}
}
# ---- omit
resource "datadog_logs_custom_pipeline" "AWS_CloudWatch_AppServer" {
filter {
query = "source:cloudwatch"
}
name = "AWS CloudWatch App Server"
is_enabled = true
processor {
category_processor {
target = "category_processor_path"
category {
name = "/test/id/succeeded"
filter {
query = "@path:\\/test\\/*\\/succeeded"
}
}
category {
name = "/test/id/failed"
filter {
query = "@path:\\/test\\/*\\/failed"
}
}
name = "category processor path"
is_enabled = true
}
}
}
# Using data source to set pipeline order
resource "datadog_logs_pipeline_order" "lpo" {
name = "lpo"
pipelines = [
datadog_logs_integration_pipeline.AWS_ELB_Access.id,
datadog_logs_integration_pipeline.AWS_Lambda.id,
datadog_logs_custom_pipeline.AWS_CloudWatch_AppServer.id #ここも追加する
]
}
おわりに
ウィジェット毎にパスを指定する苦行は免れましたが、APIが増えた時にCategory Processorにパスを追加する作業は依然として残りそうです。なので、やはりCategory Processorは対象が少ない場合には使いやすくて良さそうです。
Datadogでは他にもGrok Parserが提供されており、こちらを使えばその問題を解消できるのではと思っているので、時間を見つけてまた検証してみたいと思います。
とはいえこれまでCatgory Processorは使ったことがなかったので、そういう意味では良い機会になりました。
参考