はじめに
最近pytorchを覚えたので遊んでみます。
やることとしては、点群の位置合わせです。
目的としては、icpは局所解に陥りがちなイメージが個人的にはありますが、
pytorchの最先端な最適化関数なら結構いい線行くんじゃね?
というふわっとした期待の元やってみます。
流れは以下の通りです。
for 点群Bの各ポイント
1.変換行列$P = [R|t]$を定義する。
このパラメータの最適化を行うことで位置合わせをする。
2.点群の最近傍を計算し、最も近いポイントの組を取得する。
3.変換行列$P$を適用した点群Bのポイントと、
点群Aの最近傍のポイント、この2つを損失関数で評価する。
4.最適化処理
最適化された変換行列$P$を適用してもう一度1から実行
以下の流れで検証します。
1.同じ点群を2つ用意して、移動だけ行う(3次元のパラメータの調整)
2.同じ点群を2つ用意して、回転だけ行う(9次元のパラメータの調整)
3.同じ点群を2つ用意して、回転・移動行う(12次元のパラメータの調整)
3.異なる2つの点群を用意して、回転・移動行う(12次元のパラメータの調整)
3.他方にノイズを付与して異なる2つの点群を用意して、回転・移動行う(12次元のパラメータの調整)
結果
・・・と、書きましたが1の段階で失敗しました。
pytorchは未だ使い慣れていないので、何かが足りてないのかもしれません。
tetst.py
import copy
import numpy as np
import open3d as o3d
import random
import math
import torch.nn as nn
import torch.nn.functional as F
import torch
import torch.optim as optim
import matplotlib.pyplot as plt
epoch = 1000
def getPLYfromNumpy(nplist):
pcd = o3d.geometry.PointCloud()
pcd.points = o3d.utility.Vector3dVector(nplist)
return pcd
def write_point_cloud(path, pcl):
assert o3d.io.write_point_cloud(path, pcl), "write pcl error : " + path
def read_point_cloud(path):
pcl = o3d.io.read_point_cloud(path)
if len(pcl.points) == 0: assert False, "load pcl error : " + path
return pcl
def Register_EachPoint_RT(pclA, pclB,testP,criterion,optimizer):
history = {
'train_loss': [],
'test_acc': [],
}
transP = torch.tensor(
[[1.0, 0.0, 0.0, 0.0], [0.0, 1.0, 0.0, 0.0], [0.0, 0.0, 1.0, 0.0], [0.0, 0.0, 0.0, 1.0]],
requires_grad=True)
params = [transP]
optimizer = optimizer(params)
kd_tree_A = o3d.geometry.KDTreeFlann(pclA)
cnt = 0
# ポイント単位でやってみる
for j in range(epoch):
for didx in range(len(pclB.points)):
cnt += 1
optimizer.zero_grad()
# 最近傍の計算
[_, Aidx1, _] = kd_tree_A.search_knn_vector_3d(pclB.points[didx], 1)
ptA_sample = pclA.points[Aidx1[0]]
ptB_sample = pclB.points[didx]
# 同次座標
ptA_sample = np.array([ptA_sample[0], ptA_sample[1], ptA_sample[2], 1])
ptB_sample = np.array([ptB_sample[0], ptB_sample[1], ptB_sample[2], 1])
ptA_sample = ptA_sample.reshape(4, 1)
ptB_sample = ptB_sample.reshape(4, 1)
A_tor = torch.tensor(ptA_sample.tolist(), requires_grad=False)
B_tor = torch.tensor(ptB_sample.tolist(), requires_grad=False)
answer = A_tor
output = torch.mm(transP, B_tor)
loss = criterion(answer, output)
loss.backward()
optimizer.step()
# print( j, cnt, " : 誤差 = ", loss.item(),"\n",transP)
ls = np.linalg.norm(testP - transP.to('cpu').detach().numpy().copy())
history['train_loss'].append(loss)
history['test_acc'].append(ls)
print(" : 誤差 = ", loss.item(),"\t 正解の変換行列との誤差 = ",ls)
plt.figure()
plt.plot(range(1, cnt + 1), history['train_loss'], label='train_loss')
plt.xlabel('train_loss')
plt.legend()
plt.savefig('train_loss.png')
plt.figure()
plt.plot(range(1, cnt + 1), history['test_acc'], label='test_acc')
plt.xlabel('test_acc')
plt.legend()
plt.savefig('test_acc.png')
return transP
def Register_EachPoint_T(pclA, pclB,testP,criterion,optimizer):
history = {
'train_loss': [],
'test_acc': [],
}
transP = torch.tensor([[0.0], [0.0], [0.0]],requires_grad=True)
params = [transP]
optimizer = optimizer(params)
kd_tree_A = o3d.geometry.KDTreeFlann(pclA)
cnt = 0
# ポイント単位でやってみる
for j in range(epoch):
for didx in range(len(pclB.points)):
cnt += 1
optimizer.zero_grad()
# 点群Bの各ポイントに対して最も近い点群Aのポイントを取得
[_, Aidx1, _] = kd_tree_A.search_knn_vector_3d(pclB.points[didx], 1)
ptA_sample = pclA.points[Aidx1[0]]
ptB_sample = pclB.points[didx]
# 同次座標
ptA_sample = np.array([ptA_sample[0], ptA_sample[1], ptA_sample[2]])
ptB_sample = np.array([ptB_sample[0], ptB_sample[1], ptB_sample[2]])
ptA_sample = ptA_sample.reshape(3, 1)
ptB_sample = ptB_sample.reshape(3, 1)
# 各ポイントをTensor化
A_tor = torch.tensor(ptA_sample.tolist(), requires_grad=False)
B_tor = torch.tensor(ptB_sample.tolist(), requires_grad=False)
# 点群Bを調整して、点群Aに合わせていく。
answer = A_tor
output = (B_tor + transP)
# 損失計算 -> 最適化
loss = criterion(answer, output)
loss.backward()
optimizer.step()
# 正解の変換行列との比較。(0が望ましい)
ls = np.linalg.norm(testP - transP.to('cpu').detach().numpy().copy())
history['train_loss'].append(loss)
history['test_acc'].append(ls)
print(" : 誤差 = ", loss.item(), "\t 正解の変換行列との誤差 = ", ls)
# 調整結果を反映 -> 次のループで再び最近傍計算
nptransP = transP.to('cpu').detach().numpy().copy().reshape(1,3)
pclB = getPLYfromNumpy(pclB.points + nptransP)
plt.figure()
plt.plot(range(1, cnt + 1), history['train_loss'], label='train_loss')
plt.xlabel('train_loss')
plt.legend()
plt.savefig('train_loss.png')
plt.figure()
plt.plot(range(1, cnt + 1), history['test_acc'], label='test_acc')
plt.xlabel('test_acc')
plt.legend()
plt.savefig('test_acc.png')
return transP
POINT_NUM = 1024
# http://graphics.stanford.edu/data/3Dscanrep/
pclA = read_point_cloud("bun000.ply")
A = np.array(pclA.points)
A = np.array(random.sample(A.tolist(), POINT_NUM))
# 難易度が少し上の点群。たぶんこれはまだできない・・・
# pclB = read_point_cloud("bun045.ply")
# B = np.array(pclB.points)
# B = np.array(random.sample(B.tolist(), POINT_NUM))
# # ノイズ付与
# B += np.random.randn(POINT_NUM, 3) * 0.005
# # 点群のUnorder性(順番バラバラ)付与
# np.random.shuffle(B)
# pclB_sample = getPLYfromNumpy(B)
pclA_sample = getPLYfromNumpy(A)
T_Projection = np.array([[1, 0, 0, 0.5],
[0, 1, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 1]])
T_translation = np.array([[T_Projection[0][3]], [T_Projection[1][3]], [T_Projection[2][3]]])
pclA_trans_sample = getPLYfromNumpy(A).transform(T_Projection)
write_point_cloud("A_before.ply", pclA_sample)
write_point_cloud("A_rot_before.ply", pclA_trans_sample)
def testEstimateT(pclA_sample,pclA_trans_sample,T_translation):
optimizer = optim.Adam
# MSELoss
transP = Register_EachPoint_T(pclA_sample, pclA_trans_sample, T_translation, nn.MSELoss(),optimizer)
T_res = np.array([[1, 0, 0, transP[0]],
[0, 1, 0, transP[1]],
[0, 0, 1, transP[2]],
[0, 0, 0, 1]])
pclA_res = copy.copy(pclA_trans_sample)
pclA_res = pclA_res.transform(T_res)
write_point_cloud("TOnlytest_A_rot_after_MSELoss.ply", pclA_res)
# # L1Loss
# transP = Register_EachPoint_T(pclA_sample, pclA_trans_sample, T_translation, nn.L1Loss(),optimizer)
# T_res = np.array([[1, 0, 0, transP[0]],
# [0, 1, 0, transP[1]],
# [0, 0, 1, transP[2]],
# [0, 0, 0, 1]])
# pclA_res = copy.copy(pclA_trans_sample)
# pclA_res = pclA_res.transform(T_res)
# write_point_cloud("TOnlytest_A_rot_after_L1Loss.ply", pclA_res)
def testEstimateRT(pclA_sample,pclA_trans_sample,T_Projection):
optimizer = optim.Adam
# MSELoss
transP = Register_EachPoint_RT(pclA_sample, pclA_trans_sample, T_Projection, nn.MSELoss(),optimizer)
transP = transP.to('cpu').detach().numpy().copy()
pclA_res = copy.copy(pclA_trans_sample)
pclA_res = pclA_res.transform(transP)
write_point_cloud("RTtest_A_rot_after_MSELoss.ply", pclA_res)
testEstimateT(pclA_sample, pclA_trans_sample, T_translation)
# testEstimateRT(pclA_sample, pclA_trans_sample, T_Projection)
exit()
損失関数の出力結果を見てみます。
これだけ見ると、あっという間に0に収束してるように見えます。
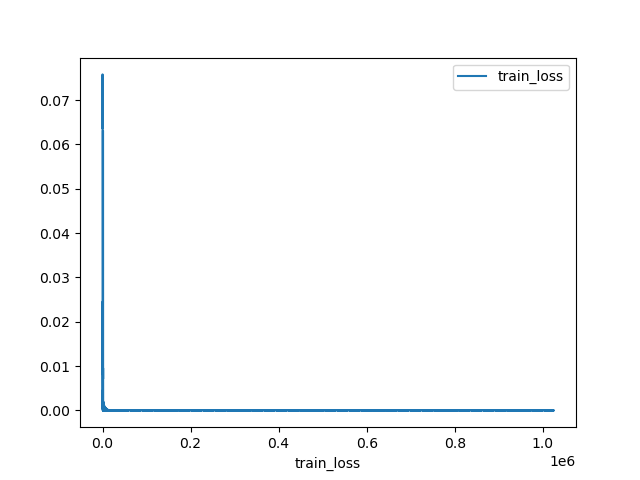
そして最適化により出力された変換行列と、正解の変換行列を比較したものがこれ。
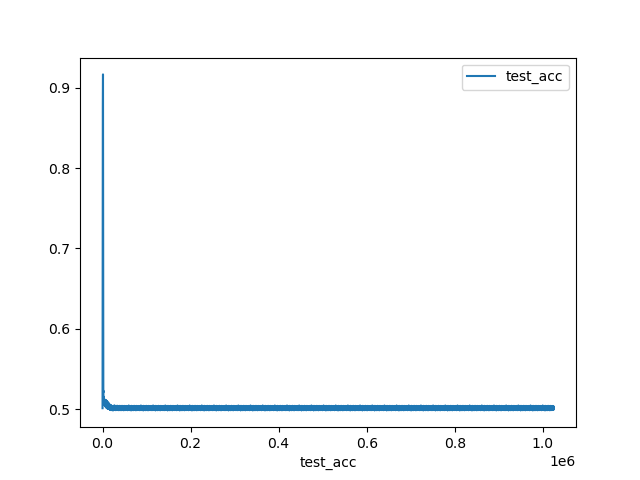
・・・最初ちょっとだけ下がったかと思えば、あとはずっと腹ばいです。0.5と大きめの誤差です。
点群も出力しましたがわずかーーーーに近寄っただけだったので割愛します。
まとめ
外れ値もなく3次元しかないのにどうしてぇ・・・という感じです。
pytorchの使い方を単純に間違えている気もします。
分かる方いたらぜひご連絡を。
次はPointNetのT-netを拡張させたもの、PointNetLKについて勉強します。
https://github.com/wentaoyuan/it-net
https://www.slideshare.net/naoyachiba18/pointnetlk-robust-efficient-point-cloud-registration-using-pointnet-167874587