はじめに
動画を読み込んで骨格検知して検出した動きを3Dモデルに当てはめてみようと思います。
(といってるけど、この記事ではアルゴリズムの内容の把握とデモを動かすだけにとどまる。)
なお、当記事は前回の記事にも記載したSMPLの準備が必須になっています。
(前回の記事は↓↓↓)
https://qiita.com/akaiteto/items/b5c8c3d5eb5ca3849c5d
前回記事でダウンロードしたソースは使いませんが、
同梱しているpklというバイナリ化された3Dモデルのファイルが必要なのでそちらを準備して下さい。
TCMR
はじめに
https://github.com/hongsukchoi/TCMR_RELEASE
今回試してみるのはCVPR2021に出展していた研究です。

https://arxiv.org/pdf/2011.08627.pdf
論文も読みますがひとまずデモソースを動かしてみましょう。
前提条件
私の環境は以下の通り
googleアカウント
何でもいい。
google colab
pythonをブラウザから実行できるとんでもサービス。
pipのコマンドはもちろん、apt-getなどのLinux系のコマンドも実行できるしGPUも使える。
あまりにも研究向けの無料サービス
SMPLのモデルファイル
前回の記事参照
とりあえずデモ動かす
githubに手順が書かれているのでそのとおりに行えば良いだけです。
が、google colabで行うので自分のために備忘録として残します。
3Dモデルアップロード
google colabのサーバーに3Dモデルをアップロードします。
この3Dモデルに最終的な骨格が当てはめられるので必須の作業です。
まず、赤枠を選択してpklファイルを選択します。
上述していますが、pklファイル(3Dモデル)はSMPLからダウンロードしてください。(前提条件参照)
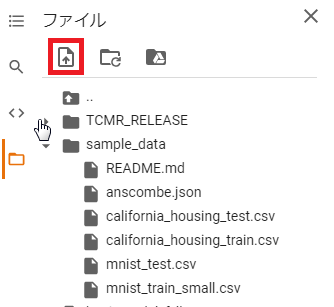
pklのファイルを選択します。3つありますが男か女か程度の差異なので適当に選びます。
このファイルには3Dモデルの情報がバイナリ化されて入っています。

アップロード中。左下のプログレスバーが完了するまで待ちます。
時間がかかります。待たずにやると当然ですがファイルが不完全なので、
プログラムの実行部分で読み込みエラーが出ます。待ちましょう。
実行環境準備
ソースを引っ張ってきて必要なライブラリを実行します。
google colabを使う前提なので、コマンドのまえにビックリマークがついています。
!git clone https://github.com/hongsukchoi/TCMR_RELEASE
!pip install numpy==1.17.5 torch==1.4.0 torchvision==0.5.0
!pip install git+https://github.com/giacaglia/pytube.git --upgrade
!pip install -r TCMR_RELEASE/requirements.txt
なお、公式を見るとシェルを叩いて環境を構築しますが、
google colabの環境だとどうにも上手く行かなかったので内容を手打ちしています。
手打ちで省いた箇所は、仮想環境構築の部分です。
google colabはサイクルで環境がリセットされるのでこれで問題有りませんが、
自分のPCでやる方は仮想環境を・・・というかシェルから実行しましょう。
3Dモデル配置
「3Dモデルアップロード」の手順で実行しているはずですが、
pklファイルをアップロードしてください。
デモ環境準備
デモソースを実行するための準備をします。
! mkdir output ; cd output ; mkdir demo_output
! mkdir data ; cd data ; mkdir base_data
! mv basicmodel_f_lbs_10_207_0_v1.1.0.pkl data/base_data/basicmodel_f_lbs_10_207_0_v1.1.0.pkl
! cp data/base_data/basicmodel_f_lbs_10_207_0_v1.1.0.pkl data/base_data/SMPL_NEUTRAL.pkl
!source TCMR_RELEASE/scripts/get_base_data.sh
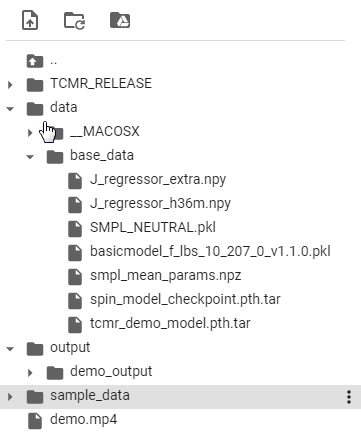
最終的にこのようになってればOK。
やってることは出力先のフォルダ作ってリネームしただけです。
また、get_base_data.shで必要な入力動画データと学習済みのモデルをダウンロードしてます
最終的にこうなってればOK
デモ環境準備
!python TCMR_RELEASE/demo.py --vid_file demo.mp4 --gpu 0
これを実行して成功すればでも完了です。
実行します。
エラー1:ファイル破損
Traceback (most recent call last):
File "TCMR_RELEASE/demo.py", line 376, in <module>
main(args)
File "TCMR_RELEASE/demo.py", line 103, in main
hidden_size=1024
File "/content/TCMR_RELEASE/lib/models/tcmr.py", line 131, in __init__
self.regressor = Regressor()
File "/content/TCMR_RELEASE/lib/models/spin.py", line 229, in __init__
create_transl=False,
File "/content/TCMR_RELEASE/lib/models/smpl.py", line 65, in __init__
super(SMPL, self).__init__(*args, **kwargs)
File "/usr/local/lib/python3.7/dist-packages/smplx/body_models.py", line 188, in __init__
encoding='latin1'))
_pickle.UnpicklingError: could not find MARK
はいエラー。smplxのモデルの読み込みのところでエラーが出ています。
https://github.com/vchoutas/smplx/blob/77cf2a7010370c1e44141fab5d15ad8a0841bc9d/smplx/body_models.py#L2348
このあたりでエラーが出ている模様。
ファイルの存在チェック諸々はされているので、ファイルの存在云々ではなさそう。
## pip install smplx==0.1.13
## pip install chumpy
from smplx import SMPL as SMPL
SMPL_MODEL_DIR = 'data/base_data'
smpl = SMPL(
SMPL_MODEL_DIR,
batch_size=64,
create_transl=False
).to('cpu')
今のままだと調査しづらいのでエラー箇所を抽出します。
アップロードしてる最中にファイルが壊れたかな?ローカル環境で実行したところ、
問題なく動作しました。ファイルを再アップロードします。
余談ですが、SMPLの3DモデルにはSMPL,SMPLX,SMPLHの3つがあるようで、
はじめインストールしているライブラリ名からして、SMPLXのモデルじゃないことが原因かと思いましたが、
通常のSMPLのモデルでも問題なさそうです。
更に余談ですが、
smplで一番初めにインスタンを立ち上げる際、3Dモデルを指定する部分で
フォルダ名で指定すると、モデル名はデフォルトで「SMPL_NEUTRAL.pkl」で読み込もうとするので注意です。
エラー2:GPUエラー
Traceback (most recent call last):
File "TCMR_RELEASE/demo.py", line 376, in <module>
main(args)
File "TCMR_RELEASE/demo.py", line 103, in main
hidden_size=1024
File "/content/TCMR_RELEASE/lib/models/tcmr.py", line 134, in __init__
pretrained_dict = torch.load(pretrained)['model']
File "/usr/local/lib/python3.7/dist-packages/torch/serialization.py", line 529, in load
return _legacy_load(opened_file, map_location, pickle_module, **pickle_load_args)
File "/usr/local/lib/python3.7/dist-packages/torch/serialization.py", line 702, in _legacy_load
result = unpickler.load()
File "/usr/local/lib/python3.7/dist-packages/torch/serialization.py", line 665, in persistent_load
deserialized_objects[root_key] = restore_location(obj, location)
File "/usr/local/lib/python3.7/dist-packages/torch/serialization.py", line 156, in default_restore_location
result = fn(storage, location)
File "/usr/local/lib/python3.7/dist-packages/torch/serialization.py", line 132, in _cuda_deserialize
device = validate_cuda_device(location)
File "/usr/local/lib/python3.7/dist-packages/torch/serialization.py", line 116, in validate_cuda_device
raise RuntimeError('Attempting to deserialize object on a CUDA '
RuntimeError: Attempting to deserialize object on a CUDA device but torch.cuda.is_available() is False. If you are running on a CPU-only machine, please use torch.load with map_location=torch.device('cpu') to map your storages to the CPU.
エラーが出ましたがメッセージ変わりましたね。さっきのエラーは潰せました。
このエラー典型的な「お前GPUもってないやないか!」というメッセージです。
googlecolabでもGPUは使えますが、使用回数限られているのでCPUで動かすようコードを変えます。
# TCMR_RELEASE/lib/models/tcmr.py
# 134行目
# pretrained_dict = torch.load(pretrained)['model']
# 以下のように変更
pretrained_dict = torch.load(pretrained,map_location=torch.device('cpu'))['model']
# TCMR_RELEASE/demo.py
# 108行目
# ckpt = torch.load(pretrained_file)
ckpt = torch.load(pretrained_file,map_location=torch.device('cpu'))
エラー3:次元エラー
Traceback (most recent call last):
File "TCMR_RELEASE/demo.py", line 378, in <module>
main(args)
File "TCMR_RELEASE/demo.py", line 113, in main
model.load_state_dict(ckpt, strict=False)
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py", line 830, in load_state_dict
self.__class__.__name__, "\n\t".join(error_msgs)))
RuntimeError: Error(s) in loading state_dict for TCMR:
size mismatch for regressor.smpl.shapedirs: copying a param with shape torch.Size([6890, 3, 10]) from checkpoint, the shape in current model is torch.Size([6890, 3, 300])
エラーが出ました。
学習済みのモデルを読み込もうとしたら次元が違うらしい。
このエラーは実装の内容理解してからじゃないととけないかもしれないー。
この節の続きに追記がなかったら、多分失敗している・・・
追伸.時間がないので後で書く。20210727
前提知識
論文を読みます。・・・の前に、前提知識を整理します。
Residual Network(ResNet)
さて、2015年ごろの研究ではVGGの研究成果により、
CNNの層を従来よりもかなり深くしたことでより高度で細かい特徴の抽出に成功しました。
ResNetでも同じように階層深くしようぜ!!・・・と思ってやってみたが、どうにも上手く行きません
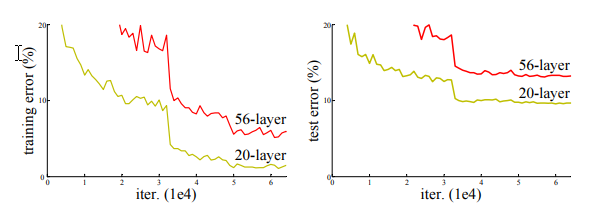
そこで考え方を変えましょうよ、と。
一般的なニュートラルネットワークは出力される値に付随するパラメータを学習することで最適な解を得るけれど、
ResNetでは出力される値に入力の値も加えて学習するらしい。(なぜそういう解決法の発想に至ったかは知らない)
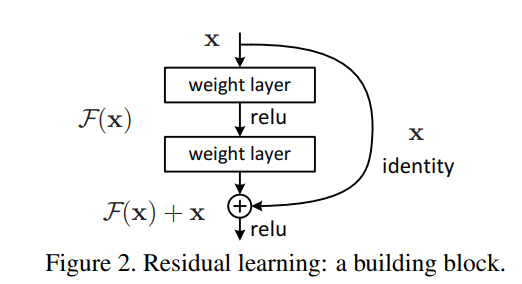
上図で言うところの入力を加えている矢印が「residual connection」。
後述する「residual connection」です。なお、上図のひとかたまりを「residual block」と呼びます。
Resnetを導入したことにより、階層を増やしてもしっかり学習ができ、
かつ高度な細かい特徴も抽出できるようになったので表現力があがりました。
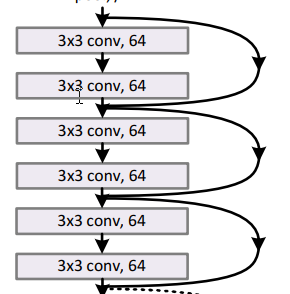
34層の階層(resne340)の実装例を見てみます。
https://github.com/CellEight/PytorchResNet/blob/main/models/ResNet34.py
下記の最初の部分だけ一部適当に抜粋しながら見ます。図の通り、3つのresidual connectionがあるので、
3つの「residual block」がある構成です。
class ResBlock(nn.Module):
def __init__(self,*args,res_transform=None):
super().__init__()
# 畳み込み層、活性化関数などの各処理を一連して行う用セット
self.seq = nn.Sequential(*args)
self.res_transform = res_transform
def forward(self,x):
if self.res_transform:
x0 = self.res_transform(x)
else:
x0 = x
# 出力される値(通常のネットワークの出力)
x = self.seq(x)
# 入力の値も加える。(residual connectionにあたる実装)
return x + x0
class ResNet34(nn.Module):
def __init__(self, n_classes):
# 3つのResidualBlockを定義
self.ResidualBlock1 = ResBlock(nn.Conv2d(64,64,kernel_size=3,stride=1,padding=1,padding_mode='reflect'), \
nn.BatchNorm2d(64), \
nn.ReLU(), \
nn.Conv2d(64,64,kernel_size=3,stride=1,padding=1,padding_mode='reflect'), \
nn.BatchNorm2d(64), \
nn.ReLU())
self.ResidualBlock2 = ResBlock(nn.Conv2d(64,64,kernel_size=3,stride=1,padding=1,padding_mode='reflect'), \
nn.BatchNorm2d(64), \
nn.ReLU(), \
nn.Conv2d(64,64,kernel_size=3,stride=1,padding=1,padding_mode='reflect'), \
nn.BatchNorm2d(64), \
nn.ReLU())
self.ResidualBlock3 = ResBlock(nn.Conv2d(64,64,kernel_size=3,stride=1,padding=1,padding_mode='reflect'), \
nn.BatchNorm2d(64), \
nn.ReLU(), \
nn.Conv2d(64,64,kernel_size=3,stride=1,padding=1,padding_mode='reflect'), \
nn.BatchNorm2d(64), \
nn.ReLU())
def forward(self,x):
# Block
x = self.ResidualBlock1(x)
x = self.ResidualBlock2(x)
x = self.ResidualBlock3(x)
Global Average Pooling
https://qiita.com/mine820/items/1e49bca6d215ce88594a
多すぎるパラメータを減らそうぜ!しかもこれやると、精度も良くなるよ!
という話らしい。
例えば、512枚の大量の画像特徴があると、その画像のピクセルの数分だけ重みの調整が必要になるけど、
画像それぞれを平均とって、その平均値に対してのみ重みつけようぜ!という話みたい。
RNN/LSTM/GRU/bidirectional GRUs
RNN/LSTM
https://qiita.com/akaiteto/items/d5f0d615916877091571
昔記事に書いてた通り。
RNNは連続で時系列のあるデータを扱うのが得意。
前回の出力結果も今回の計算に含めて計算することで、前回の結果も含めた結果を出すことができる。
ただその場合、
「前回って言うけど、どこまでが前回?
「全フレーム参照する気か?時間かかるし、余計なものも使ってしまいそうだけど。」
という問題に対する対応がLSTM。
各フレームごとに重要度を設定して、重要じゃないフレームは無視するし、
重要なら未来永劫反映させるように設定する。

GRU
https://www.slideshare.net/gakhov/recurrent-neural-networks-part-1-theory
LSTMの変形らしい。利点はLSTMほどメモリ食わないしLSTMよりも高速だとか。
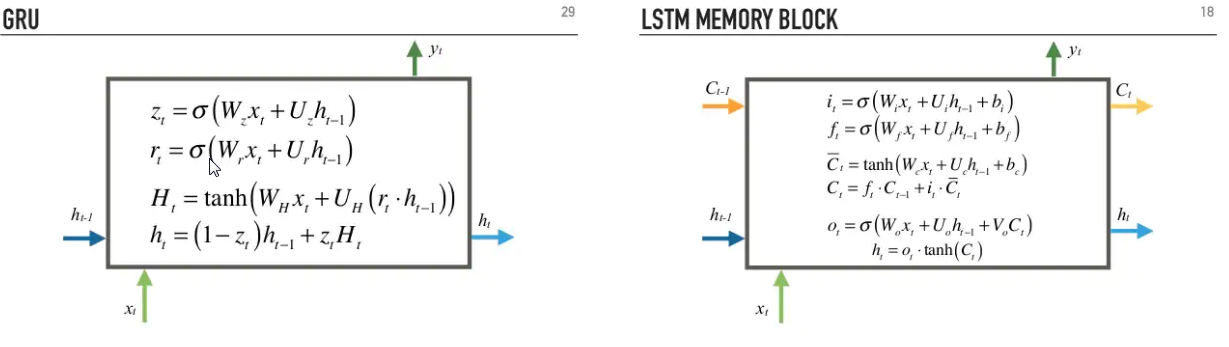
LSTMの$C_t$というのが、各フレームの重要度をもっている関数なんだけど、
GRUではこれがなくなっている。各フレームの重要度を担っていた$C_t$が入出力を司る$h_t$に集約されたのがGRU
bidirectional GRU/RNN/LSTM
pytorch的に言えば、「bidirectional=True」を設定するだけで良いらしい。
https://medium.com/@felixs_76053/bidirectional-gru-for-text-classification-by-relevance-to-sdg-3-indicators-2e5fd99cc341
http://colah.github.io/posts/2015-09-NN-Types-FP/
今までは過去の出力を加えてたけど、未来の出力も活用することで、
現在の状態がどのようになってるか予想しようぜ!という構造のもの。
へぇ。わからんけど、実際の難しい処理はpytorch先生におまかせしよう。
Weak perspective(弱透視)
要するに正射影。
http://www.thothchildren.com/chapter/5c16710c41f88f26724b1748

ピンホールカメラのパラメータとしては、おなじみ内部パラメータ、外部パラメータなどがある。
後の文章に出てくる弱透視カメラのパラメータは・・・なんだろう?
出力として弱透視カメラのパラメータが得られるらしいけど、ピンホールカメラと同じようなもの?
と思いながら論文を読み進むると、スケールと移動の値が出力されるらしいので、
外部パラメータと同じようなものが出力されるらしい。
論文読む
イントロ
これまで多くの研究により、単一の画像から3Dモデルを推定することには成功しました。
その研究の多くは、SMPLの各関節の動きの情報をパラメータとして与えて回帰(予測)することで
動きの推定を行います。
さて、本手法のテーマは「動画」からの人間骨格の推定です。
単一画像を想定した従来方法で動画の動きを推定しようとすると、フレーム単体で推定を行うため、
全体の挙動として動きががなめらかじゃなかったり、一連の動きの一貫性が失われて正確な推定ができません。
これに対して動画に拡張するための手法として下記のような手法が提案されています。
1.全ての入力フレームから骨格に関わる(staticな)特徴を取得。
2.全てのフレームの特徴を時間的な特徴にエンコードするエンコーダーに渡す。
3.エンコードされた時間的な特徴から各入力フレームの骨格を推定する。
(Learning 3D Human Dynamics from Video https://github.com/akanazawa/human_dynamics)
(VIBE :https://github.com/mkocabas/VIBE)
しかしこれらの手法にも問題があります。検出したポースと時間が一致しない問題です。
ポーズと時間が一致しない?…まぁ要するに、それでもやっぱりスムーズにポーズが動かないと。
https://youtu.be/WB3nTnSQDII?t=53
↑従来方法(VIBE)と本手法を比較すると顕著ですが、従来方法は動きがどこかスムーズじゃありません。
原因は上記手順の1にある(staticな)特徴と、3の時間的な特徴が一致していないことにあるらしいです
本稿では、その問題の解決を行います。
イントロ(追記)
なぜこのような不一致がおきるのか?曰く、原因は2つあるらしい。
1つ目は、時間的な特徴を計算する際、対象となるフレームの(staticな)特徴に極端に強く依存してしまう点。
直接的な原因は、骨格に関わる(staticな)特徴と上述2番の時間的な特徴、これらをを
結びつける「residual connection」(前提知識参照)にあります。
ResNetをそのまま使うと、時間的な特徴の学習を妨げてしまうらしく、
時間的な特徴の推定の精度がよくないらしい。
時間的な特徴の情報は骨格推定を行う上で重要な情報のひとつなので、
この推定が上手く活用しないと骨格の推定の精度はよくならない。
本稿ではしっかりそのあたりも対策してるのが強み。
2つ目は、時間的な特徴をエンコードするエンコーダーの精度の問題。
まず、現在のフレーム、過去のフレーム、未来のフレームを考えます。
従来方法だと現在のフレームにばかり注目するあまり、過去未来のフレームを
含めた学習ができていないことが問題です。本稿ではしっかりそのあたりも対策してるのが強み。
もう少し読む
動画を読み込んでフレームごとの画像$I_1 \cdots I_T$を取得します。
(staticな)特徴を取得
これについては従来手法におまかせしましょう。
(https://github.com/nkolot/SPIN)
従来研究でトレーニングされているものを使って、単一の画像から(staticな)特徴を取得します。
これに対して、「global average pooling(前提知識参照)」を行うことで更に変換し、$f_1 \cdots f_T \in R^{2048}$を取得します。
(ぶっちゃけ私がやりたいことはこのOSSだけでいい)
時間的な特徴を取得
GRUによる現在過去未来の計算
まず考え方として、フレームを現在、過去、未来と分けて考えます。
現在のフレームは、T個のフレームのうちの$T/2$番目のものを現在のフレームとして定義します。
VIBE "https://github.com/mkocabas/VIBE" では、
双方向ゲート付き回帰ユニット(bi-directional gated recurrent unit )
というものを使って、時間特徴にエンコードします。(前提知識参照)
双方向ゲート付き回帰ユニットとは、要するに
未来方向・過去方向計算された2つの方向のGRUを利用して、対象となる現在の時間的な特徴を計算する方法です。
本稿でも同様に、bidirectionalGRUで計算します。ただし全て同じでは有りません。
本稿の構図としては、$T/2$番目の「現在」と呼ばれる$f_{T/2}$の時間的な特徴を計算すべく、
$f_1 \cdots f_T \in R^{2048}$の過去から未来のすべての入力フレ―ムを使って推定します。
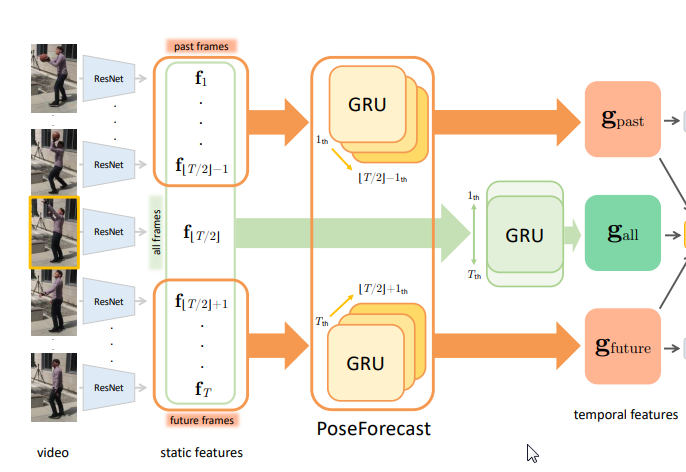
すなわち、$f_{T/2}$からみて過去の$1 \cdots (\frac{T}{2}-1)$をGRUで計算した集合$g_{past}$、
$f_{T/2}$からみて未来の$\frac{T}{2}+1 \cdots T$をGRUで計算した集合$g_{future}$より、
未来と過去の双方向から計算するbidirectionalGRUで、現在の状態を推定します。
VIBEと違う点としては、VIBEでは下図の矢印のようにResNetの「residual connection」を採用しているかいないかの点です。
「residual connection」は、上述の通り滑らかさが欠如する問題の原因となっているので、本稿ではその点を改善しています。
(下図はVIBEの論文。矢印のところが「residual connection」)
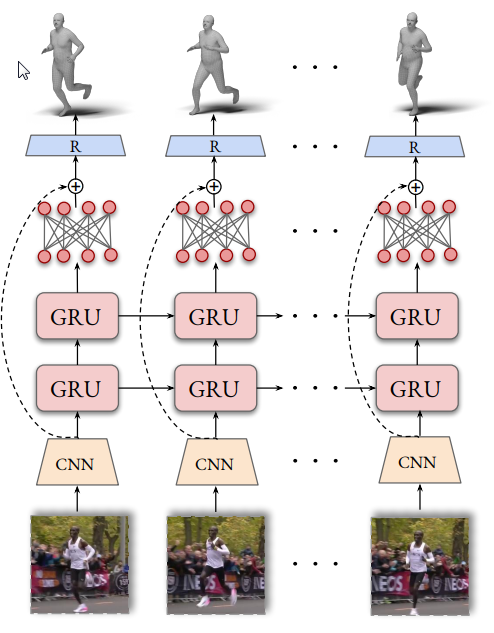
現在過去未来のGRU計算結果の統合
さて、過去、現在、未来のGRUの結果が格納された$g_{past}$、$g_{future}$、$g_{all}$を1つに統合します。
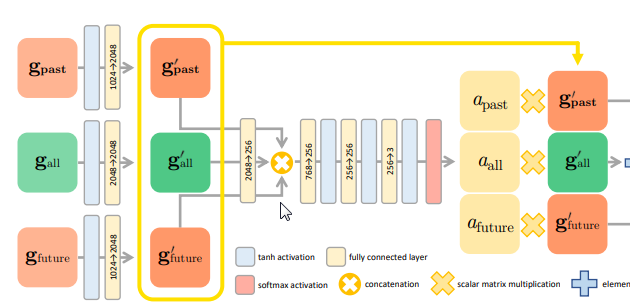
まず、活性化関数(Relu)を使って$g_{past}^{\prime}$、$g_{future}^{\prime}$、$g_{all}^{\prime}$を計算します。
そこからさらに、Attentionレイヤーでtanhとソフトマックス関数で加工し、「attention values」の$a_{past}$、$a_{future}$、$a_{all}$を
現在過去未来ごとに出力します。(詳細省略)
「attention values」は、現在・過去・未来のそれぞれの出力結果にどれくらいの重みをつけるか、
どれくらい反映させるかを決定します。
これらを統合したものが最終的な出力$g_{int}$です。
トレーニング
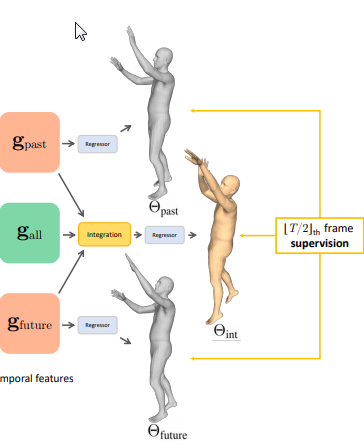
トレーニングの段階では、
$g_{past}$、$g_{future}$、$g_{all}$をregressorに渡して、$\Theta$という出力を得ます。
$\Theta$は各パラメータの和集合で構成されており、SMPLを動かすための角度の情報と、
弱透視カメラのパラメータ(スケール、平行移動)[weak-perspective camera parameter]、
アイデンティティパラメータ(なにそれ)の出力結果が、過去未来現在ごとに格納されます。
損失関数
損失は現在過去未来の最終的な出力と、正解の値とをL2損失で計算します。
より詳細には、3次元の関節の座標、2次元の関節の座標、そしてSMPLパラメータから計算します。
2次元の関節の座標については、3次元の関節の座標より、取得した弱透視カメラモデルのパラメータで計算します。
実際の実装
以下箇条書き。
・VIBEに従いフレーム間隔$T$は16にセット。
・ビデオのFPSは26-30
・単一画像からの姿勢推定はhttps://github.com/nkolot/SPINを使用。モデルも多分同じ。
・最適化関数はAdamでミニバッチサイズは32。
・(staticな)特徴を取得では、Resnetでトリミングされた画像から計算することで時間とメモリを節約している。
・すべての回転情報は、Zhou etalの6D回転表現で予測し、最終的にはSMPL向けにaxis-angle 表現の回転表現に変換します。
ソースを見る
ソース見ながら内容を見てみます。完全に私のメモ代わりの書き置きです。
あと、デモソース動かしたときにエラーがでたので原因をダメ元でしらべたい…。
人物のトラッキング
https://github.com/hongsukchoi/TCMR_RELEASE/blob/8078b3c39c22cae39eb19c0e1eb70e09c60ecea7/demo.py#L82
下記OSSで動画から複数人のトラッキングを行います。YOLOV3 & MaskRCNNによる人間の検出
https://github.com/mkocabas/multi-person-tracker
TCMRモデル準備1
https://github.com/hongsukchoi/TCMR_RELEASE/blob/8078b3c39c22cae39eb19c0e1eb70e09c60ecea7/demo.py#L98
TCMR(この記事の技術)のモデルを呼び出します。
TCMRの内部には、「時間的な特徴」と「Regressor」の2つのネットワークがあります。
TemporalEncoderネットワーク:時間的な特徴
https://github.com/hongsukchoi/TCMR_RELEASE/blob/8078b3c39c22cae39eb19c0e1eb70e09c60ecea7/lib/models/tcmr.py#L88
$f_1 \cdots f_T \in R^{2048}$のT枚の画像の特徴情報をわたして、
現在過去未来ごとにGRUの計算結果$g_{all},g_{past},g_{future}$を取得します。
そしてここからは下記画像の部分。
https://github.com/hongsukchoi/TCMR_RELEASE/blob/8078b3c39c22cae39eb19c0e1eb70e09c60ecea7/lib/models/tcmr.py#L93
まず$g_{all},g_{past},g_{future}$をReluで活性化させつつ、次元が2048になるように変換し、
$g_{past}^{\prime}$、$g_{future}^{\prime}$、$g_{all}^{\prime}$を計算します。
https://github.com/hongsukchoi/TCMR_RELEASE/blob/8078b3c39c22cae39eb19c0e1eb70e09c60ecea7/lib/models/tcmr.py#L95
そして3つの情報を2048×256に統合し、
https://github.com/hongsukchoi/TCMR_RELEASE/blob/8078b3c39c22cae39eb19c0e1eb70e09c60ecea7/lib/models/tcmr.py#L11
attentionレイヤーで「attention values」の3つを出力。
そのまま、図と同じように$g_{past}^{\prime}$、$g_{future}^{\prime}$、$g_{all}^{\prime}$とtorch.mulで乗算。
Regressorネットワーク:SMPLのパラメータ「等」を予測する
個々の実装の詳細は論文のどこに書いてるんだぁ・・?別記事でかこう
TCMRモデル準備2
https://github.com/hongsukchoi/TCMR_RELEASE/blob/8078b3c39c22cae39eb19c0e1eb70e09c60ecea7/demo.py#L106
そして事前に学習した重みを読み込ませます。
ここには「attention values」が入ってる・・・はず?
あれ?ちがうかも?
SPINモデル準備
https://github.com/hongsukchoi/TCMR_RELEASE/blob/8078b3c39c22cae39eb19c0e1eb70e09c60ecea7/demo.py#L124
ここまでの説明で言うところの、「(staticな)特徴」を出力するネットワークを準備する。
下記の既存の研究を呼び出している。
https://github.com/nkolot/SPIN
人ごとに全フレームの骨格を取得
https://github.com/hongsukchoi/TCMR_RELEASE/blob/8078b3c39c22cae39eb19c0e1eb70e09c60ecea7/demo.py#L164
全フレーム読み込んで人単位で骨格を取得。
最終的な出力の初期化。
https://github.com/hongsukchoi/TCMR_RELEASE/blob/8078b3c39c22cae39eb19c0e1eb70e09c60ecea7/demo.py#L180
ここで初期化されている値がpredict(予測)される出力値。regressorから帰ってくる$\Theta$が入ってる。
SMPLのパラメータ${\theta , \beta}$、そして、弱透視カメラのパラメータ${s,t}$(スケール、移動量)、
それからSMPLの3次元上の関節座標と、それを二次元平面に投射した2次元上の関節座標が入ってきます。
最終的な出力の初期化。
TCMRモデルに骨格の特徴を与えて、本稿のアルゴリズムに従い
過去未来現在のGRUを計算することで時間的な特徴を取得し、$g_{int}$を取得します。
まとめ
いやー。デモ動きませんでしたー笑
ソースも軽くしかおってないので、次回もうちょっとおいます。