前回までにやったこと
前回、Python実行環境構築からSubmit(解析結果の提出)までざっと説明しましたので、今回は解析プログラムについて説明していきます。まだSubmitしたことがない方は、全体の流れを把握するために、前回の記事を一通り試してみてください。
課題:House Prices: Advanced Regression Techniques
お手本:「データ前処理」- Kaggle人気チュートリアル
前回使用した解析プログラム
解析プログラム全体を記載してきますので、まずはコピペで実行してみてください。警告がでるかもしれませんが、『Submit.csv』が作成されたら問題なく実行されているはずです。
※データをこちらからダウンロードしてください。
※このプログラムはプログラム(*.ipynb or *.py)とデータ(train.csvとtest.csv)が同じフォルダにおいていることを前提に書かれていますので、同じフォルダに入れたくない人は相対パスを書き換えてください。
'''ライブラリの読み込み'''
import pandas as pd #CSV読み込みや変数作成などにつかう
import matplotlib.pyplot as plt #グラフを表示するライブラリ
from sklearn.cross_validation import train_test_split #説明変数と目的変数に分けるためのライブラリ
from sklearn import linear_model #線形回帰のためのモジュール
from sklearn.metrics import r2_score #R2を計算するためのモジュール
import warnings #ワーニング関連のモジュール?
warnings.filterwarnings('ignore') #ワーニングが消える?
%matplotlib inline
'''学習用データの読み込み'''
path = './train.csv' #データの保存場所への相対パスが異なる場合は書き換える
df_train = pd.read_csv(path)
'''目的変数と説明変数を作成しそれぞれ学習用と検証用に分割する'''
# 目的変数
y = df_train['SalePrice']
# 説明変数(行列は大文字にするみたい)
X = df_train[['OverallQual', 'YearBuilt', 'TotalBsmtSF', 'GrLivArea']]
# 学習用、検証用データに分割
(X_train, X_test, y_train, y_test) = train_test_split(X, y, test_size = 0.2, random_state = 5)
'''回帰モデルの作成'''
# モジュール読み込み、モデル構築
model = linear_model.LinearRegression()
# モデルの学習
model.fit(X_train, y_train)
# 予測値の算出
y_train_pred = model.predict(X_train) #トレーニングデータでの予測
y_test_pred = model.predict(X_test) #検証用データでの予測
'''予測結果の確認'''
# 決定係数を表示
print('R2(Train) : % 0.3f' % r2_score(y_train, y_train_pred))
print('R2(Test) : % 0.3f' % r2_score(y_test, y_test_pred))
# グラフを描画する
plt.scatter(y_train, y_train_pred)
plt.scatter(y_test, y_test_pred)
plt.show()
'''最終検証用データの読み込み'''
path = './test.csv' #データの保存場所への相対パスが異なる場合は書き換える
df_sub = pd.read_csv(path)
# 欠損値を平均で埋める
index = df_sub[df_sub['TotalBsmtSF'].isnull()].index
df_sub['TotalBsmtSF'][index[0]] = df_sub['TotalBsmtSF'].mean()
'''説明変数を作成する'''
# 説明変数(行列は大文字にするみたい)
X_sub = df_sub[['OverallQual', 'YearBuilt', 'TotalBsmtSF', 'GrLivArea']]
'''予測値の算出'''
y_sub = model.predict(X_sub)
'''予測結果の提出用ファイルを作成する'''
# IDと予測結果を結合する
df_sub_pred = pd.DataFrame(y_sub).rename(columns={0:'SalePrice'})
df_sub_pred = pd.concat([df_sub['Id'], df_sub_pred['SalePrice']], axis=1)
# CSVファイルの作成
df_sub_pred.to_csv("Submit.csv", index=False)
Pythonプログラムの大まかな流れ
まずはPythonプログラムの大まかな流れは書いておきます。機械学習を行うときのPythonプログラムは大体このような流れになると思います。
- 必要なライブラリのインポート
- 学習用データの読み込み
- 目的変数(ベクトル)と説明変数(行列)の作成それぞれモデル作成用とモデル精度確認用に分割
- 回帰モデルの作成
- 回帰モデルの精度を確認
- 提出用データの作成
プログラムの詳細説明
プログラムの詳細を説明していきます。
必要なライブラリのインポート
'''ライブラリの読み込み'''
import pandas as pd #CSV読み込みや変数作成などにつかう
import matplotlib.pyplot as plt #グラフを表示するライブラリ
from sklearn.cross_validation import train_test_split #説明変数と目的変数に分けるためのライブラリ
from sklearn import linear_model #線形回帰のためのモジュール
from sklearn.metrics import r2_score #R2を計算するためのモジュール
import warnings #ワーニング関連のモジュール?
warnings.filterwarnings('ignore') #ワーニングが消える?
%matplotlib inline
解析をするときに必要なライブラリーをインポートしておきます。
どれも有名なライブラリなので、詳細はネットで調べてください。
学習用データの読み込み
'''学習用データの読み込み'''
path = './train.csv' #データの保存場所への相対パスが異なる場合は書き換える
df_train = pd.read_csv(path)
Pandasを使って学習用データ(train.csv)を読み込みデータフレーム作成しています。
Jupyter Notebookを使用している場合、以下のコマンドで読み込んだdf_trainの中身などを確認することもできます。
df_train : 中身を確認する
type(df_train) : 型を確認する
df_train.shape : 行数と列数を確認する
目的変数(ベクトル)と説明変数(行列)の作成それぞれモデル作成用とモデル精度確認用に分割
'''目的変数と説明変数を作成しそれぞれ学習用と検証用に分割する'''
# 目的変数
y = df_train['SalePrice']
# 説明変数(行列は大文字にするみたい)
X = df_train[['OverallQual', 'YearBuilt', 'TotalBsmtSF', 'GrLivArea']]
# 学習用、検証用データに分割
(X_train, X_test, y_train, y_test) = train_test_split(X, y, test_size = 0.2, random_state = 5)
pandasのデータフレームの機能を使って、必要な項目のみを抽出しています。目的変数は1項目だけなのでベクトル、説明変数は4項目選んでいるので行列になっています。尚、ベクトルは小文字、行列は大文字にするよう文化があるようなのでそれに従ってみました。この作業は特徴量生成やFeaturingと言われ、このやり方でモデル精度が大きく異なるので、今後の改善ポイントになりますのでいろいろネットで調べてみてください。説明変数の4項目は「データ前処理」- Kaggle人気チュートリアルからアイデアを拝借しています。
データを学習用と検証用に分けているのはホールドアウト検証を行うためです。なぜこのようなことをするかは、過学習、ホールドアウト検証、クロスバリデーション、モデルバリデーション等のキーワードを検索してください。
回帰モデルの作成
'''回帰モデルの作成'''
# モジュール読み込み、モデル構築
model = linear_model.LinearRegression()
# モデルの学習
model.fit(X_train, y_train)
最も簡単な線形回帰(いわゆる重回帰分析)を行っています。モジュールを読み込んでFitするだけで回帰が完了するところがすごいですね。この部分を書き換えるだけでランダムフォレストリグレッションなども簡単に出来るようです。
回帰モデルの精度を確認
# 予測値の算出
y_train_pred = model.predict(X_train) #トレーニングデータでの予測
y_test_pred = model.predict(X_test) #検証用データでの予測
'''予測結果の確認'''
# 決定係数を表示
print('R2(Train) : % 0.3f' % r2_score(y_train, y_train_pred))
print('R2(Test) : % 0.3f' % r2_score(y_test, y_test_pred))
# グラフを描画する
plt.scatter(y_train, y_train_pred)
plt.scatter(y_test, y_test_pred)
plt.show()
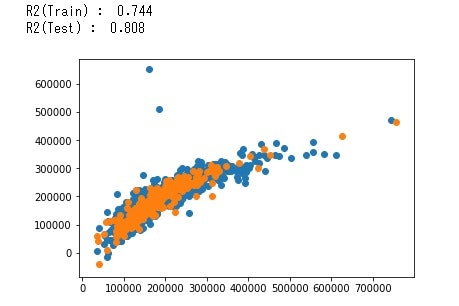
分割した学習用データと検証用データでそれぞれR2を計算しグラフにプロットしています。R2をみるとあまり精度がよくないようですが、R2(Train) < R2(Test)となっているので過学習はしれおらず、説明変数を増やすことでまだ精度の改善が出来るのではないかと思います。また、真値と予測結果が1:1のライン(Y=X)から大きくはずれています。この点についてはランダムフォレスト回帰を行うと1:1のラインに近づいたので次回はその方法を説明したいと思います。
提出用データの作成
'''最終検証用データの読み込み'''
path = './test.csv' #データの保存場所への相対パスが異なる場合は書き換える
df_sub = pd.read_csv(path)
# 欠損値を平均で埋める
index = df_sub[df_sub['TotalBsmtSF'].isnull()].index
df_sub['TotalBsmtSF'][index[0]] = df_sub['TotalBsmtSF'].mean()
'''説明変数を作成する'''
# 説明変数(行列は大文字にするみたい)
X_sub = df_sub[['OverallQual', 'YearBuilt', 'TotalBsmtSF', 'GrLivArea']]
'''予測値の算出'''
y_sub = model.predict(X_sub)
'''予測結果の提出用ファイルを作成する'''
# IDと予測結果を結合する
df_sub_pred = pd.DataFrame(y_sub).rename(columns={0:'SalePrice'})
df_sub_pred = pd.concat([df_sub['Id'], df_sub_pred['SalePrice']], axis=1)
# CSVファイルの作成
df_sub_pred.to_csv("Submit.csv", index=False)
学習用データで作成した回帰モデルに、最終検証用データ(※)から作成した説明変数を入力して予測値の算出。提出用フォーマットのCSVファイルを作成しています。test.csvのTotalBsmtSFに欠損値があるので、欠損値は平均値で埋めていますが、これも「データ前処理」- Kaggle人気チュートリアルからアイデアを拝借しています。
(※)ホールドアウト検証のために、学習用データを学習用データと検証用データに分割し名前が重複するので、test.csvを最終検証用データと呼ぶことにしました。
終わりに
プログラムの大まかな流れは理解していただけましたでしょうか?私はこの記事を書いてなんとなく理解できたような気がします。