はじめに
2022年ごろから、モデルの重みを変更せずに入力を工夫する「プロンプトエンジニアリング」のアプローチが大きく普及した1。しかし、AIの実用化(特にビジネスへの組み込み)が進むにつれ、LLMの「内部知識(パラメータ内の記憶)」のみに依存するアプローチの限界が明確になりはじめた。
- 知識のカットオフと閉鎖性: 事前学習した時点以降の最新情報や、企業の非公開データ(社内ドキュメントなど)には答えることができない。
- ハルシネーション(幻覚): 確率的に単語を予測するLLMの性質上、知らない情報に対しても、もっともらしい「嘘」を自信満々に出力してしまう。
- コンテキスト長の限界: 全ての社内資料をプロンプトに詰め込もうとしても入力上限があり、無理に入力しても中間情報の見落とし(Lost in the Middle)や計算コストの増大を招いてしまう。
そこで注目されたのが、「人間は、自分の記憶にない専門的な質問をされたとき、適当に推測して答えるのではなく「辞書や資料を検索して」から回答を作成する。AIモデルにも同様に、外部のデータベースから正確な知識を検索(Retrieval)させ、その事実に基づいて回答を生成(Generation)させるべきだ」という思想に基づくRAG(Retrieval-Augmented Generation:検索拡張生成)というアプローチである。本記事では、このRAGを中心とした検索拡張に関する技術をまとめた。
検索拡張技術の起源
モデルの巨大化による知識の丸暗記は、最新情報の更新コストやニッチな記憶の効率、ハルシネーションの制御に限界がることが知られていた。そこで、高度な推論能力と具体的な事実データを分離し、効率的で信頼性の高い知能システムを構築する目的から、外部から情報を検索(Retrieval)してきて、言語モデル(LM)を強化する手法の研究が進んでいた。
kNN-LM
通常、言語モデルが「次の単語」を予測するときはパラメータ内の確率に従うとされる。しかし、2019年ごろStanford大学とFacebook AI Researchから、「テキストを生成するまさにその瞬間、外部データベースから最も似ている文章(Nearest Neighbor: kNN)を検索し、その単語の出現確率をブレンドする」というアプローチが提案された2。
これにより、モデルを追加学習(ファインチューニング)させることなく、外部知識ベースを「参照」させるだけで、言語モデルの予測精度(Perplexity)が劇的に向上することが示された。
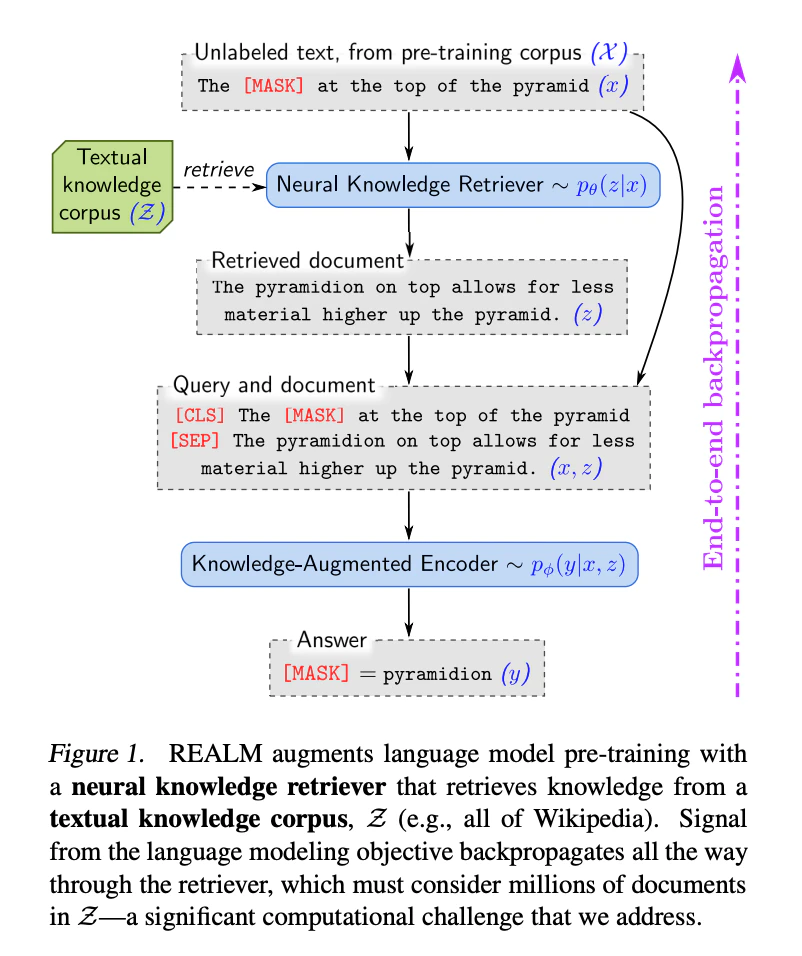
REALM (Retrieval-Augmented Language Model pre-training)
2020年ごろGoogle Researchから、これまで「完成したAIモデルに後付けで検索を組み合わせる」のが主流だったのに対し、「AIの事前学習(Pre-training)の段階から、検索エンジン(Retriever)を組み込んで一緒にトレーニング(End-to-End学習)してしまおう」という提案がされた3。
BERTのような言語モデルが、Wikipediaから自ら知識を検索しながら賢くなっていく仕組みを作り、オープンドメインQAで当時の最高精度(SOTA)を達成した。
RAG (Retrieval-Augmented Generation)
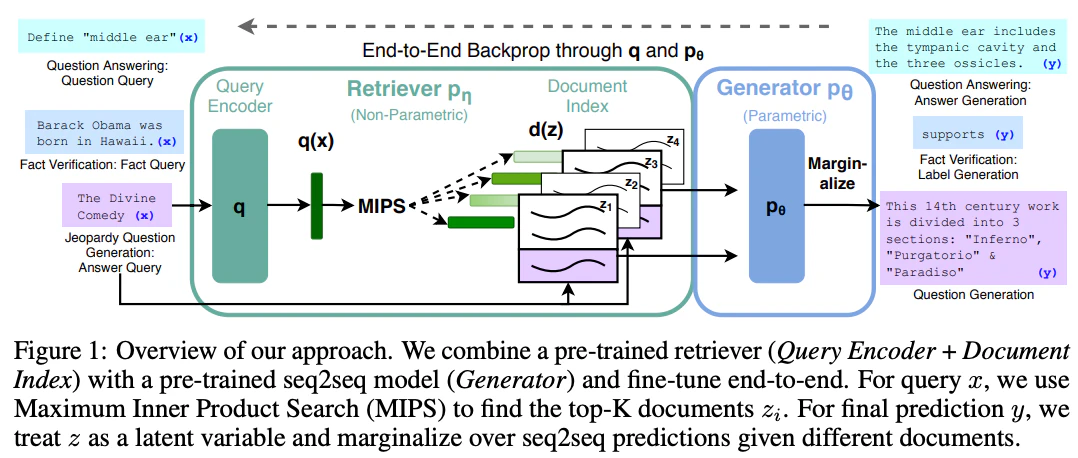
モデルのパラメータに蓄えられた知識(パラメータメモリ)と、外部の文書群をベクトル化した知識(非パラメータメモリ)を組み合わせることで、知識の直接的な修正や拡張、アクセスの追跡を可能にするという発想に基づき、2020年にFacebook AI Researchのチームが外部知識を検索して利用する手法をタスクへ柔軟に適用できる汎用的なファインチューニングのレシピとして拡張した4。
ゼロから構造を学習させるのではなく、検索器と生成器の双方に広範な知識を保持した「事前学習済みモデル」を採用することで、追加の訓練なしに最初から知識へアクセスできる能力を持たせてはいるものの、この時点では検索器(Retriever)と生成器(Generator)の2つのモジュールを、エンドツーエンド(一気通貫)で同時にファインチューニングできることがポイントとされている。
検索拡張の重要な要素である「検索」の技術に関しては、下記のような研究がなされた。
- DPR(Dense Passage Retrieval for Open-Domain Question Answering)5
- それまで主流だった伝統的なキーワード検索に対し、2つのBERT(Dual-Encoder)を使って文章をベクトル化し、その近さ(内積)だけで検索する「密ベクトル検索(Dense Retrieval)」が、圧倒的な精度でBM25を凌駕することを証明した。
- このDPRの仕組みがそのまま、同年末に発表される初代RAG論文4の検索エンジン(Retriever)に採用されている。
- BEIR(BEnchmarking-Information Retrieval)6
- それまで単一のタスクや特定のドメイン(Wikipediaなど)に偏りがちだった情報検索(IR)モデルの評価環境に対し、9つの異なる検索タスク(事実検証、重複質問検出、医療情報検索など)から厳選された18のデータセットからなる、多様で異質な「ゼロショット評価(Out-of-Distributionの汎化性能検証)」のための標準ベンチマークを提案した。
- 検証の結果、MS MARCOなどで事前に大量学習させたDPRをはじめとする高精度な密ベクトル検索(Dense Retrieval)モデルであっても、未知のドメインやタスク(ゼロショット環境)においては、伝統的なキーワード検索である「BM25」の精度を大きく下回ることがある(汎化性能に課題がある)と実証した。
ファインチューニング不要な検索拡張システム
2022年末にChatGPT(OpenAI)が登場したことを皮切りに、さまざまな言語系生成AIがAPI経由で利用されるようになった中、特定分野の知識を組み込みたいが、API経由なのでモデルをいじれず、従来のRAG手法が使えないという課題が発生した。そこで、モデルのパラメータは1ミリも触れない(Frozen)という制約下でも機能する検索拡張のシステムが求められ出した78。
In-Context RALM
既存のLLMをそのまま利用し、検索した関連文書をプロンプトの先頭に単に結合して入力するだけで、性能が向上するという研究2。
「LLMを一切いじらなくても、検索頻度やクエリ長の最適化、および軽量なリランカーの配置という「周辺システム側の工夫( document selection の洗練)』だけで、ファインチューニングに匹敵、あるいはそれ以上の圧倒的なRAGの効果を引き出せる」ということを実証した。

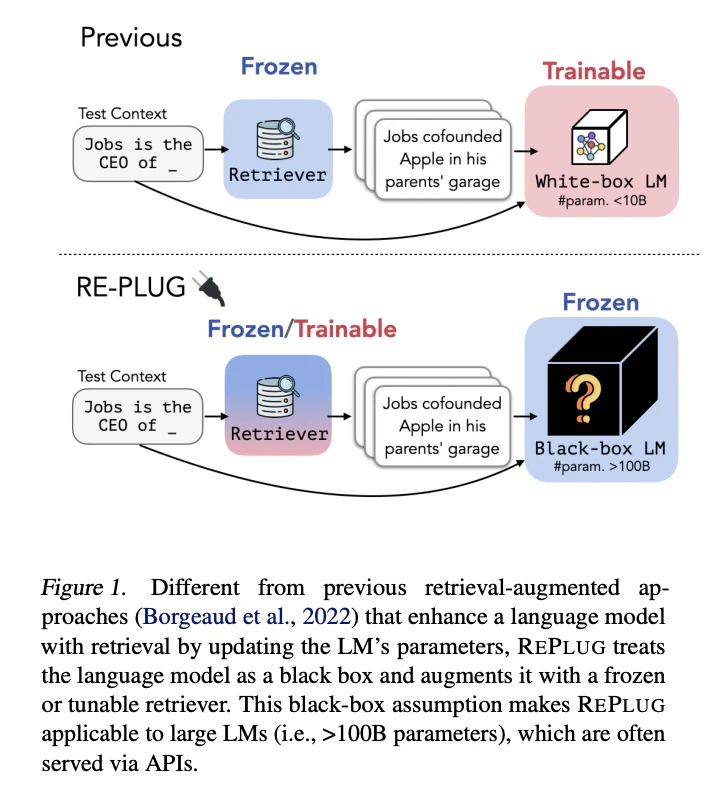
REPLUG (Retrieve and Plug)
LLMを完全な「ブラックボックス(APIモデル)」と割り切り、モデルの重みには1ミリも触れずに、外部の検索器(Retriever)側だけを「LLM協調型」に進化させる検索拡張システムに関する研究8
- 並列アンサンブルによるコンテキスト制限の突破:検索した上位 $k$ 件の文書をすべて一度にプロンプトへ詰め込むのではなく、文書を1件ずつ個別にクエリの先頭に結合し、並列(Parallel)でLLMに入力する。それぞれの出力確率を重み付け平均(アンサンブル)することで、LLMの文脈長の制限(Context Window)に縛られずに大量の外部知識を反映させるシステムを構築した。
- LLMを教師とした検索器の自律チューニング(REPLUG LSR):「どの文書を挿入したときに、LLMの出力性能(Perplexity)が最も向上したか」をスコア化し、それを教師シグナル(KLダイバーシティの最小化)として検索器側のパラメータだけを最適化する(LSR: LM-Supervised Retrieval)。LLM側を一切いじることなく、周辺システム(検索器)側をLLMの「好みの知識」に合わせる工夫だけで、GPT-3(175B)やCodexといった超巨大モデルの性能をさらに数%大幅に引き上げることに成功した
RAGの派生系
前節の流れで、モデルをフリーズしたまま「脳(推論)」と「本棚(検索)」を完全に切り離すこのスタイルは、LLMのパラメーターを書き換えるParametricな手法(ファインチューニングなど)に比べて開発コストを劇的に抑えられるため、現在のLLMアプリケーション開発における主要な技術としてその地位を確立した9。
この後、さまざまなRAGに関する研究が加熱する。
Self-RAG
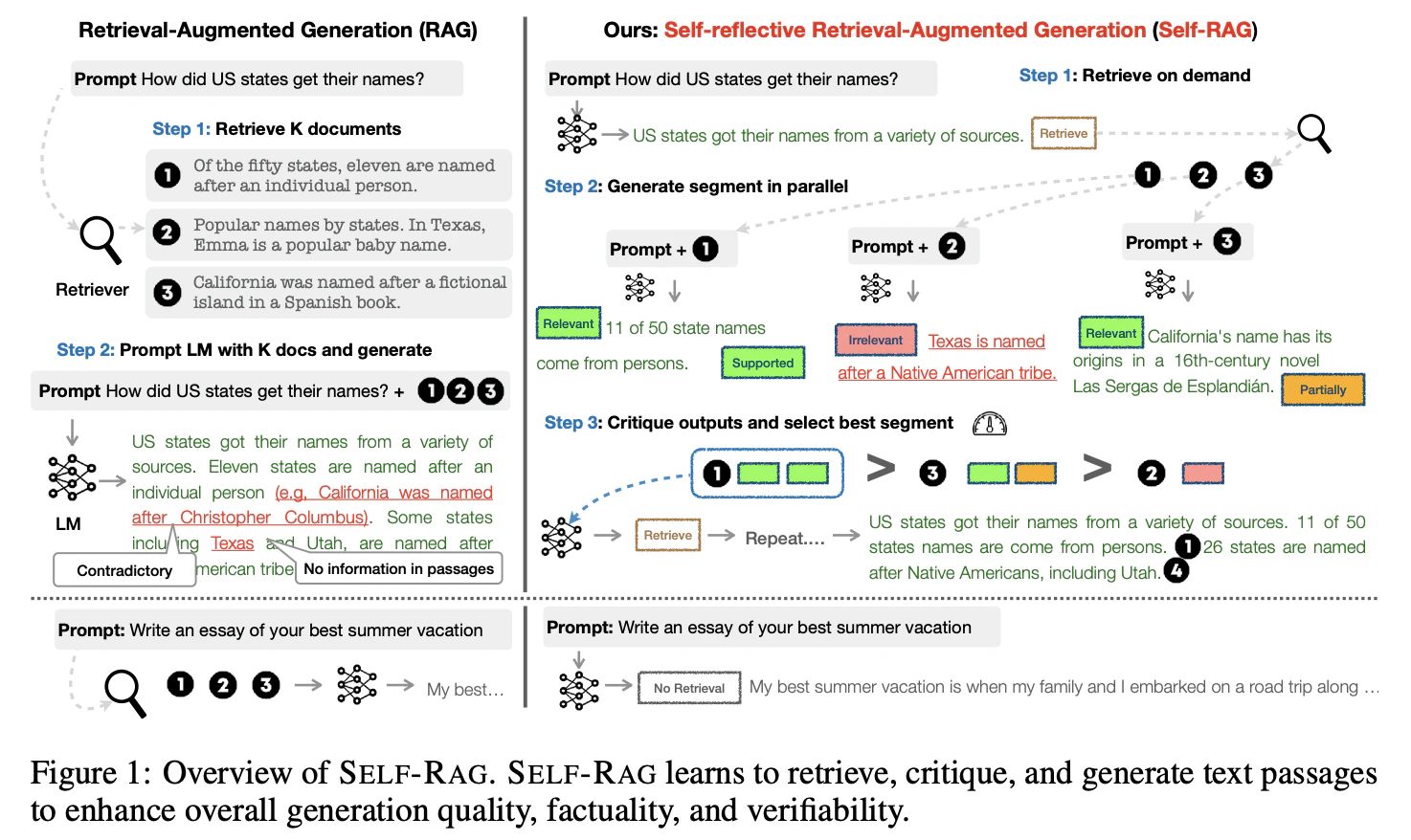
LLM自体が文章の生成プロセスの中に「検索が必要か」「取得した情報が有効か」「生成した回答が正確か」を自分自身で判断・評価(自己反省)するために出力する特殊なトークンであるリフレクショントークンを生成することで、自律的に制御を行うRAG10。
主要な4種類のリフレクショントークンは下記の通り。
Retrieve(検索の必要性)
- 役割: 入力された質問に対して、外部知識を検索すべきかどうかを判断
-
値の例:
[Yes](検索する)、[No](検索せず自身の知識で回答する)
IsRel(検索結果の関連性)
- 役割: 検索によって得られた各文書が、質問に対して本当に役立つ情報(関連性があるか)を評価
-
値の例:
[Relevant](関連あり)、[Irrelevant](関連なし)
IsSup(事実の裏付け=エビデンス)
- 役割: 検索文書を基に生成した回答の一節が、「本当にその文書に書かれている内容(事実)に基づいているか」(ハルシネーションを起こしていないか)を評価
-
値の例:
[Fully Supported](完全に裏付けあり)、[Partially Supported](一部あり)、[No Support](裏付けなし)
IsUse(回答の有用性)
- 役割: 最終的に生成された回答が、ユーザーの質問に対する直接的な答えとしてどれだけ有益かを5段階などで総合評価
-
値の例:
[Utility: 5](非常に有益)〜[Utility: 1](無関係・不十分)
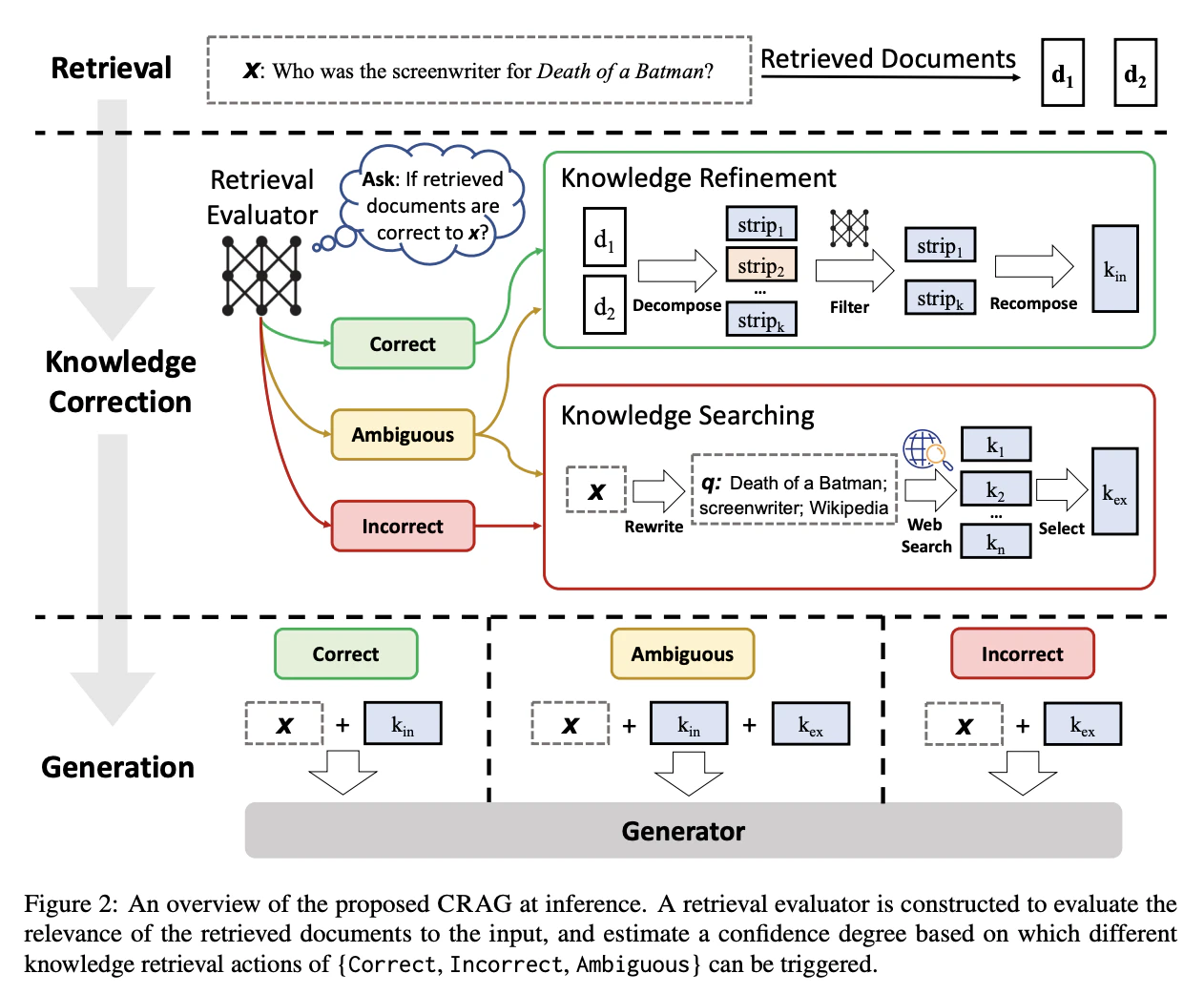
CRAG (Corrective RAG)
「検索結果が間違っている(または不十分な)可能性」を前提に置き、外部の評価器(Evaluator)を使って検索結果を自動修正(Self-Correction)するRAG11。
評価結果は下記の通り。
- Correct(正しい)
- 状態: 検索結果に確実に正しい情報が含まれていると判断。
- 処理: 文書をそのまま使うのではなく、ノイズを排除するために「知識の洗練(Refinement)」を行う。文書を数文単位の「ストリップ(細切れ)」に分解し、無関係な部分をフィルタリングして重要な部分だけを再構成する。
- Incorrect(間違い)
- 状態: 検索結果がすべて的外れ(無関係)であると判断。
- 処理: ローカルの検索結果をすべて破棄する。代わりに、LLMに検索用キーワードを生成させ、Googleなどの外部Web検索(Web Search API)を使ってインターネットから最新・最適な情報を補給する。
- Ambiguous(曖昧)
- 状態: 正しいか間違っているか、評価器が自信を持てないグレーゾーン。
- 処理: 安全策として、ローカルの検索結果(洗練済み)と、Web検索から得た情報の両方をブレンドしてLLMに渡す。
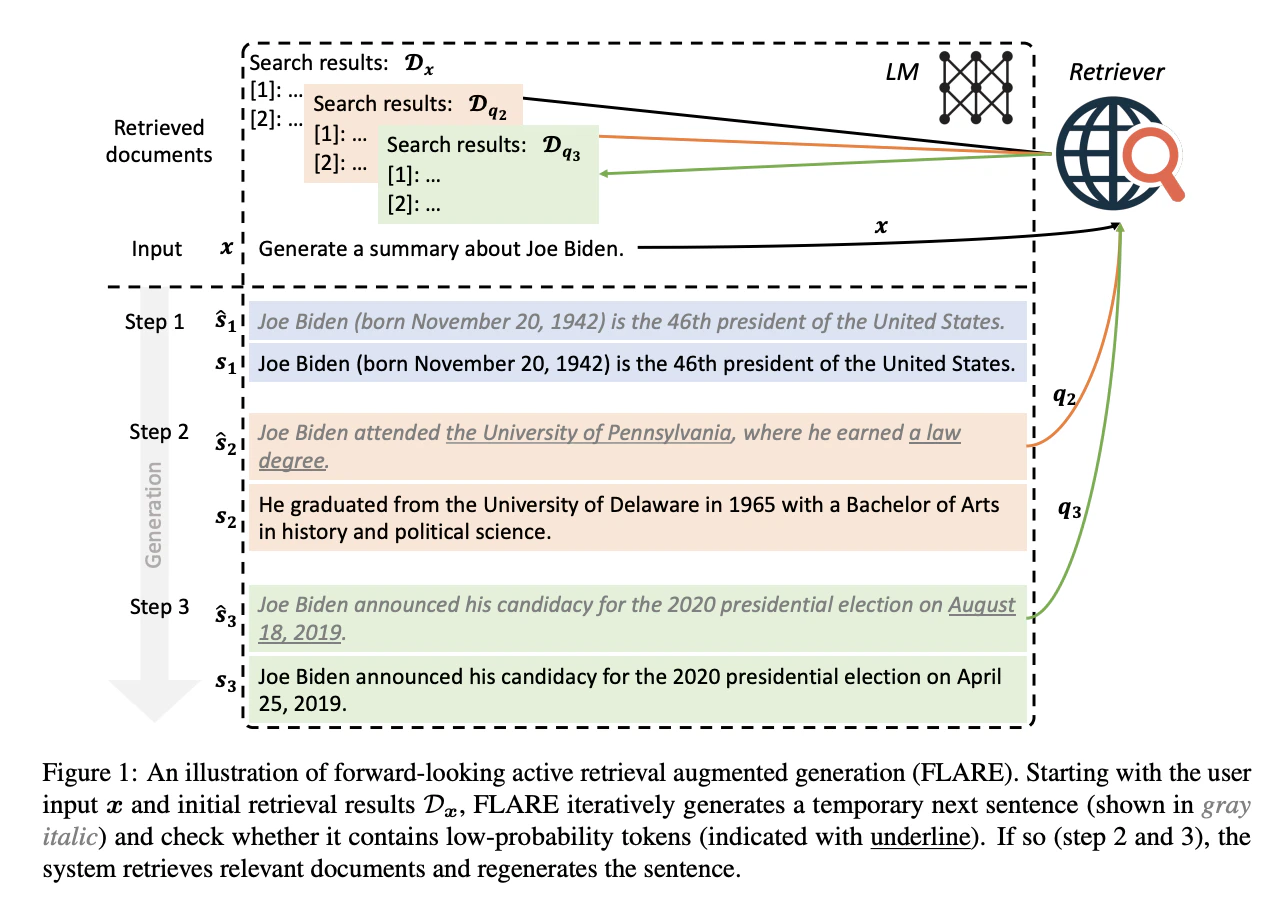
FLARE (Forward-Looking Active REtrieval augmented generation)
従来のRAGの多くは、ユーザーの入力(プロンプト)に対して「1度だけ検索して生成する(Single-time Retrieval)」というアプローチをとっていたが、長文生成においては生成の途中で新たな情報が必要となる。この課題に対し、生成プロセスの途中で「いつ」「何を」検索すべきかをモデル自身が能動的に判断し、反復的に外部知識を検索・取り込みながら文章を生成するRAGの研究事例12。
アルゴリズムの流れ(Direct FLARE)
- 初期検索: ユーザー入力をクエリとして初期検索を行い、第1文を生成
- 仮文の生成: 外部知識を参照せずに、次の文の予測(仮の次の一文 $\hat{s}_t$)を生成
- 信頼度のチェック:
- すべてのトークンの確率がしきい値 $\theta$ 以上 $\rightarrow$ そのまま文を確定し、次のステップへ。
- しきい値未満のトークンがある $\rightarrow$ 検索をトリガー。
- クエリ作成と再生成: 仮文をベースに(マスクや質問生成を通じて)クエリを構築し、外部からドキュメントを取得。その取得したドキュメントを文脈に加えて、次の一文を正しく再生成。
- 文章の終端に達するまで2〜4を繰り返す。
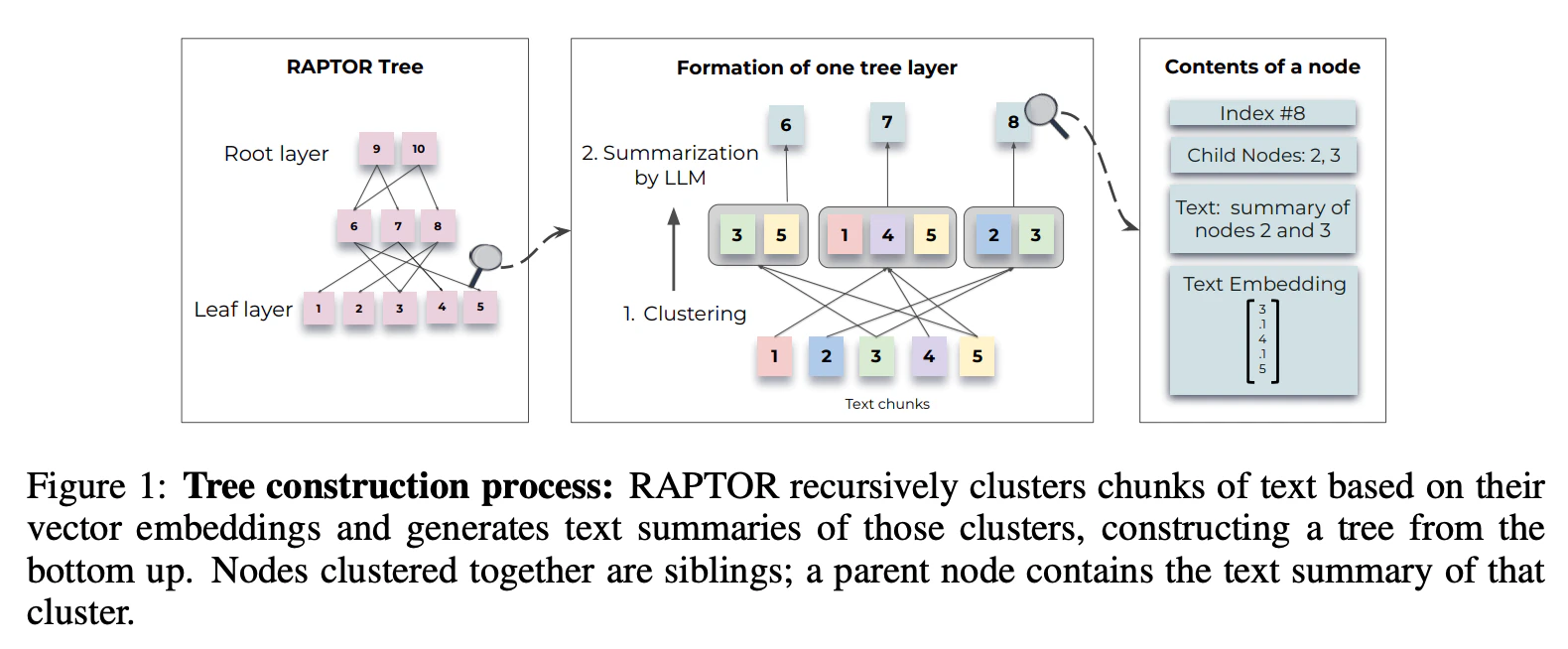
RAPTOR (Recursive Abstractive Processing for Tree-Organized Retrieval)
従来のRAGモデルは、コーパスから連続する短いテキストチャンクのみを検索するため、文書全体の文脈やテーマに沿った「マクロな理解」が難しいという課題があった。これに対し、テキストチャンクを再帰的に埋め込み(Embedding)、クラスタリングし、要約することで、異なる抽象度の要約からなるツリー構造(RAPTORツリー)をボトムアップで構築するというRAGの研究13。
GraphRAG
LLMを用いて外部のプライベートな文書群から「知識グラフ(Knowledge Graph)」を事前に構築し、さらにそのグラフの構造(コミュニティ)ごとにサマリーを自動生成しておく、GraphRAGという手法が提案された14。
従来のRAGがテキストを単純な文章のまとまり(チャンク)として個別にベクトルデータベースへ格納するのに対し、GraphRAGはデータ内の実体(エンティティ)を「ノード」、それらの関係性を「エッジ」とするグラフ構造(知識グラフなど)として情報を管理・検索する。
知識グラフを用いたQA(質問応答)やファクトチェックだけでなく、ドキュメントの要約、分子・医薬品データの解析(サイエンス領域)、ソーシャルネットワーク分析、意思決定計画など、幅広いドメインへ応用されている15。
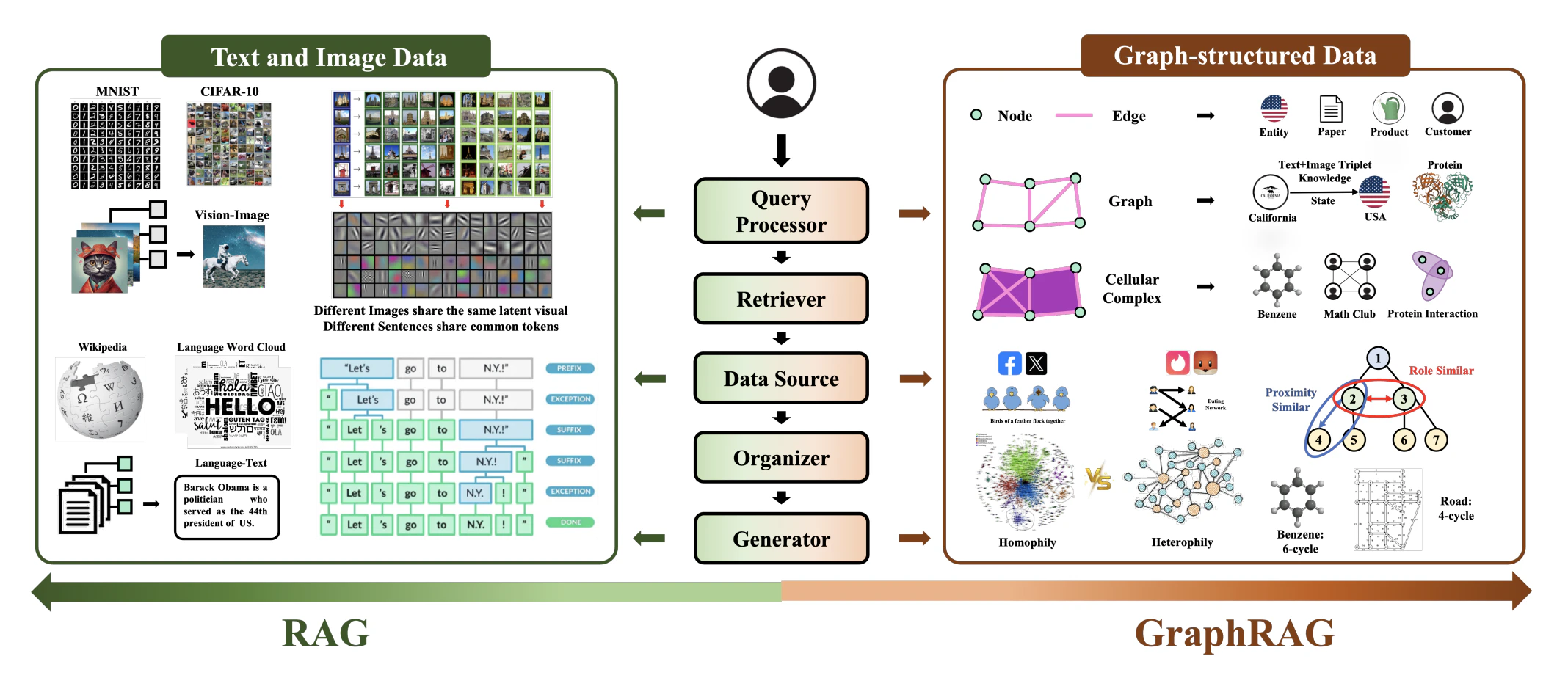
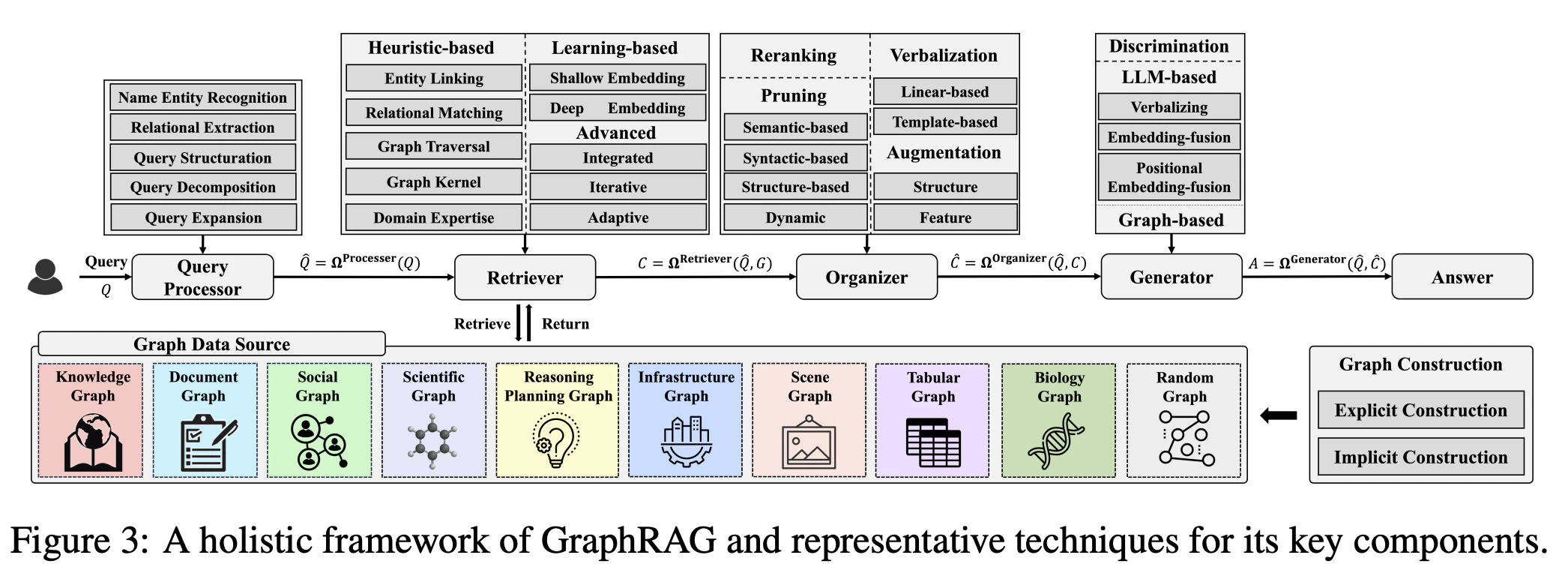
検索拡張の限界
LLM(大規模言語モデル)の進化に伴い、外部知識をシームレスに取り込む仕組みとして「RAG(検索拡張生成)」はシステム構築においてデファクトスタンダードとなった。しかし、現場での運用が進むにつれ、単純に「関連文書を検索してLLMに詰め込む」という従来の標準RAGアプローチが、構造的な限界に直面し出した1617。
- ノイズ情報混入による低精度化
- 不十分な証拠によるハルシネーション
すなわち、情報が多すぎても少なすぎても、精度が低下してしまう可能性があるという点である。
これらのことから、受動的なコンテキスト注入を排し、LLMに自律的な思考ルーチンを組み込むエージェント技術に注目が集まるきっかけとなった。
関連記事
-
Generalization through Memorization: Nearest Neighbor Language Models ↩ ↩2 ↩3
-
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks ↩ ↩2 ↩3
-
Dense Passage Retrieval for Open-Domain Question Answering ↩
-
BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models ↩
-
REPLUG: Retrieval-Augmented Black-Box Language Models ↩ ↩2 ↩3
-
Retrieval-Augmented Generation for Large Language Models: A Survey ↩ ↩2
-
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection ↩ ↩2
-
RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval ↩ ↩2
-
From Local to Global: A Graph RAG Approach to Query-Focused Summarization ↩
-
From RAG to Agentic RAG for Faithful Islamic Question Answering ↩