注意:この記事はKeras 1.x.x向けです
とりあえずマニュアル
見落としがちですが、メニューの下の方にも結構色々重要(?)なものがあります。
- コールバック
- EarlyStopping、各エポックでのモデル保存、学習率の調整、、etc
- Applications
- 事前学習済みのモデル
- 可視化
- モデルを画像化してくれるやつ
などなど。
読むと楽しいソース
Examples
だいぶ色々入ってます。VAEとかHRNNとかBidirectional LSTMとか。
事前学習済みのモデル(の実装)
昔はExamplesに入っていた気がするVGGとかResNetとか。
細かいノウハウ(?)やコピペ用コード片など
モデルのsave/load
モデルのsave/loadは、ググると重みとモデル(json or yaml)を別々に保存したりしている例がよく出てきますが(要出典)、新しめのバージョン(?)ではmodel.save()とload_model()でいけます。
model.save("model.h5")
from keras.models import load_model
model = load_model("model.h5")
レイヤーの自作
自分でレイヤーを作るのも結構簡単です。
https://keras.io/ja/layers/writing-your-own-keras-layers/
class Scaling(Layer):
"""回帰で出力をスケーリングするために作った適当レイヤー"""
def __init__(self, mean, std, **kwargs):
self.mean = float(mean)
self.std = float(std)
assert 0 < self.std
super().__init__(**kwargs)
def build(self, input_shape):
self.W = K.variable(self.std * 3) # 適当に3倍
self.trainable_weights = [self.W]
super().build(input_shape)
def call(self, x, mask=None):
return x * self.W + self.mean
def get_config(self):
config = {"mean": float(self.mean), "std": float(self.std)}
base_config = super().get_config()
return dict(list(base_config.items()) + list(config.items()))
自作したレイヤーを含むmodelをsaveしたあとloadすると「レイヤーが見つからん」と怒られるので、load_modelのときにdictで渡してあげるといいようです。
model = load_model("model.h5", {"Scaling": Scaling})
クロスバリデーション
素直に毎回model.compile()してもいいのですが、(特にTheanoだと)重いので、学習前の重みをとっておいてセットし直して使うのが良さそうです。
# 学習前の重みを保存
init_weights1 = model.get_weights()
init_weights2 = model.optimizer.get_weights()
# cross validation
kf = sklearn.model_selection.KFold(n_fold, shuffle=True)
for train_indices, test_indices in kf.split(X, y):
# 学習
X_train = X[train_indices]
y_train = y[train_indices]
X_test = X[test_indices]
y_test = y[test_indices]
hist = model.fit(X_train, y_train, nb_epoch=nb_epoch, validation_data=(X_test, y_test))
# hist["val_acc"][-1]とかの平均を取ったりなんやかんやする(割愛)
# 学習前の重みに戻す
model.optimizer.set_weights(init_weights2)
model.set_weights(init_weights1)
(やったことないけどScikit-Learn APIを使うほうが素直かも?)
コールバック色々
これも普通にマニュアルが詳しいですが、自分のコピペ用に。
https://keras.io/ja/callbacks/
基本のコード
色々追加削除をすることがあるので、以下のような形にして使っています。
callbacks = []
callbacks.append(いろいろ)
callbacks.append(いろいろ)
callbacks.append(いろいろ)
model.fit(略, callbacks=callbacks)
EarlyStopping
val_lossが下がらなくなったら終わりにするやつ。(あまり使っていませんが一応。)
from keras.callbacks import EarlyStopping
callbacks.append(EarlyStopping("val_loss", patience=1))
各epochでのモデルの保存
from keras.callbacks import ModelCheckpoint
# callbacks.append(ModelCheckpoint(filepath="model.best.h5", save_best_only=True))
callbacks.append(ModelCheckpoint(filepath="model.ep{epoch:02d}.h5"))
学習率をちょっとずつ減らす
nadamなどと組み合わせて使います。
from keras.callbacks import LearningRateScheduler
callbacks.append(LearningRateScheduler(lambda ep: float(1e-3 / 3 ** (ep * 4 // MAX_EPOCH))))
最初の頃は float(1e-3 * 0.9 ** ep) などとしていましたが、各学習率でどのくらいちゃんと収束してるのか分かりやすいように、段階的に減らすようにしています。
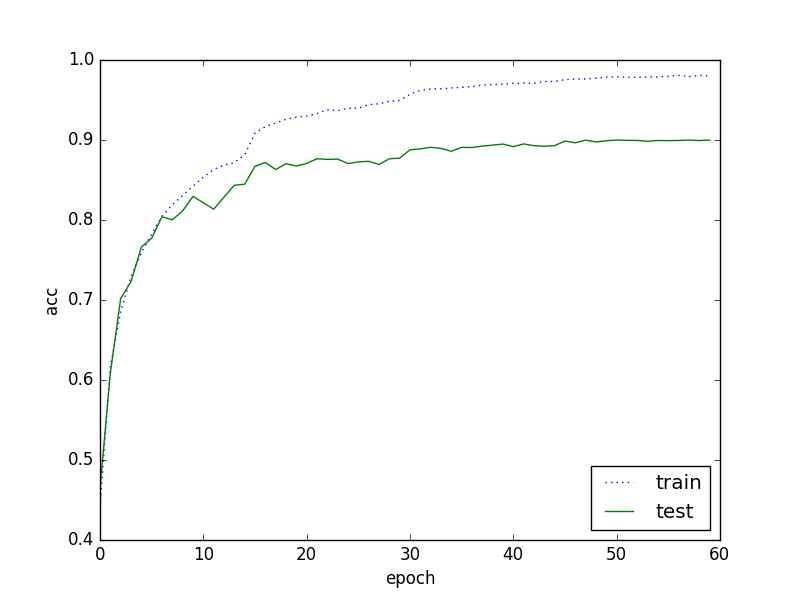
epoch 15、30、45で切り替わっているのが何となく分かります。
学習経過をCSV保存
lossなどをCSVに保存してくれるものです。結果をバージョン管理しておくと、変更して良くなったか悪くなったか分かりやすいのでおすすめ。
from keras.callbacks import CSVLogger
callbacks.append(CSVLogger("history.csv"))
TensorBoard用のログ出力
1回やったら飽きましたが一応。
from keras.callbacks import TensorBoard
callbacks.append(TensorBoard())
SGD
ResNet界隈ではAdamとかよりSGD+Nesterovが使われるという噂なのでやってみたコード。
from keras.optimizers import SGD
optimizer = SGD(decay=1e-6, momentum=0.9, nesterov=True)
model.compile(loss="categorical_crossentropy", optimizer=optimizer, metrics=["accuracy"])
momentumがあるとSGDの割に(?)そこそこ早く進みます。
(しかし結局自分では主にnadam + LearningRateSchedulerを使ってたり。)
可視化(モデルの画像化)
from keras.utils.visualize_util import plot
plot(model, to_file="model.png", show_shapes=True)
よくあるこういうやつです。
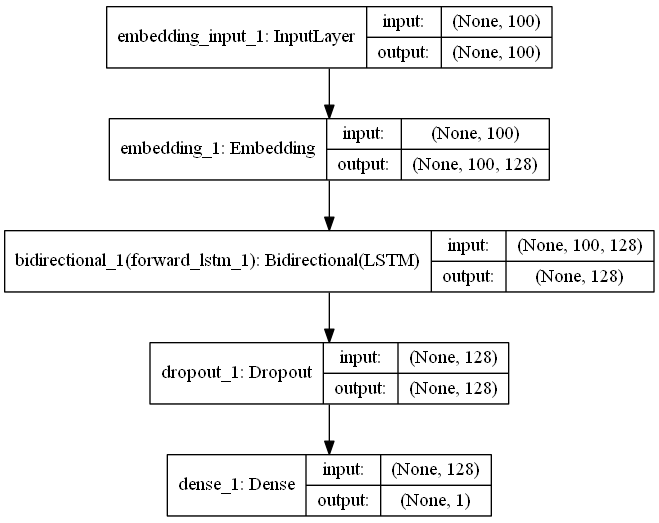
image_dim_ordering
KerasでCNNを使う場合に、shapeが(samples, height, width, channels)なのか、(samples, channels, height, width)なのかは変えることが出来るのですが、環境によってデフォルトが異なるケースがあって、割と注意が必要です。プログラム上で明示的に指定してしまうのが手っ取り早い気がします。
設定ファイルとしては、~/.keras/keras.jsonのimage_dim_orderingの値です。tfなら前者、thなら後者。
TensorFlowとTheanoの名を関していますが、バックエンドとは独立して指定できます。(どの組み合わせが早いとかはよく分かりません…)
プログラム上から設定したり取得したりは、keras.backend.image_dim_ordering()とかを使います。
https://keras.io/ja/backend/#image_dim_ordering
# 設定
from keras import backend as K
K.set_image_dim_ordering("tf")
# 取得
assert K.image_dim_ordering() == "tf"
TensorFlow使用時にメモリを使い尽くさないようにする
from keras import backend as K
import tensorflow as tf
config = tf.ConfigProto(allow_soft_placement=True)
config.gpu_options.allow_growth = True
session = tf.Session(config=config)
K.set_session(session)
環境構築手順備忘録
Windowsの場合。
-
Anaconda3をインストール
Anaconda3-4.2.0-Windows-x86_64.exe
(インストーラーは「管理者として実行」でやらないと上手く行かなかった。) -
CUDA、cudnnをインストール
cuda_8.0.44_win10_network.exe
cudnn-8.0-windows10-x64-v5.1.zip -
パッケージをアップデートしたりインストールしたり
conda update -y conda anaconda --all
pip install graphviz pydot-ng keras tensorflow-gpu