ver1版がだいぶ古くなっていたので書き直しました。
とりあえずマニュアルを隅から隅まで読みましょう
見落としがちですが、メニューの下の方にも結構色々重要(?)なものがあります。
- コールバック
- EarlyStopping、各エポックでのモデル保存、学習率の調整、、etc
- Applications
- 事前学習済みのモデル
- 可視化
- モデルを画像化してくれるやつ
などなど。
読むと楽しいソース
Examples
だいぶ色々入ってます。VAEとかHRNNとかBidirectional LSTMとか。
事前学習済みのモデル(の実装)
新しいのも結構ぽろぽろ追加されてます。v2.2.0でMobileNetV2とか。
細かいノウハウ(?)やコピペ用コード片など
importの仕方
Keras 2.0以上なら(?)、
import keras
だけでほとんどのものが使えます。
(2.2以前はpreprocessing配下だけは改めてimportする必要がありましたが、2.2以降は要らなそうです。)
マニュアルとかexamplesとかでは from keras.~~ import ~~ も多用されてますが、個人的には import keras と、せいぜい import keras.backend as K くらいで書くのが好み。
TensorFlow使用時にメモリを使い尽くさないようにする設定
import keras.backend as K
import tensorflow as tf
config = tf.ConfigProto(allow_soft_placement=True)
config.gpu_options.allow_growth = True
K.set_session(tf.Session(config=config))
最初とかK.clear_session()後とかに。
モデルのsave/load
モデルのsave/loadは、ググると重みとモデル(json or yaml)を別々に保存したりしている例がよく出てきますが(要出典)、model.save()とload_model()でいけます。
model.save('model.h5', include_optimizer=False)
model = keras.models.load_model('model.h5', compile=False)
保存したものをその後予測しかしないなら include_optimizer=False を指定しておくとmomentumとかが保存されないのでサイズが半分とか以下になる。momentumとかを復元して学習を再開したい場合だけsave時に include_optimizer=True (既定値)、load時にcompile=True (既定値)にするとよい。(個人的には今のところそんなケースは無い)
何か特殊なLayerとかを使ったりしていてsaveがコケる場合は model.save_weights() を使うといいかも。
あとどちらで保存したやつでも普通にモデルを作ってから model.load_weights() で読むこともできます。
レイヤーの自作
自分でレイヤーを作るのも結構簡単です。
https://keras.io/ja/layers/writing-your-own-keras-layers/
class Scaling(keras.layers.Layer):
"""回帰で出力をスケーリングするために作った適当レイヤー"""
def __init__(self, mean, std, **kwargs):
self.mean = float(mean)
self.std = float(std)
assert self.std > 0
super().__init__(**kwargs)
def build(self, input_shape):
self.W = self.add_weight(name='W', shape=(1,),
initializer=keras.initializers.Constant(self.std),
trainable=True)
super().build(input_shape)
def call(self, x, mask=None):
return x * self.W + self.mean
def get_config(self):
config = {'mean': float(self.mean), 'std': float(self.std)}
base_config = super().get_config()
return dict(list(base_config.items()) + list(config.items()))
自作したレイヤーを含むmodelをsaveしたあとload_modelすると「レイヤーが見つからん」と怒られるので、load_modelのときにdictで渡してあげたりCustomObjectScopeを使ったりするといいようです。
model = keras.models.load_model('model.h5', custom_objects={'Scaling': Scaling})
クロスバリデーション
昔はmodel.get_weights()とmodel.optimizer.get_weights()で学習前の状態を取っておいて検証後に戻すとかできたのですが、どうも2.0くらい(?)から学習前だとmodel.optimizer.get_weights()が空っぽになっているようなので、素直に各foldでモデルごと作り直すのが良さそうです。
kf = sklearn.model_selection.StratifiedKFold(n_fold, shuffle=True)
for train_indices, test_indices in kf.split(X, y):
# モデルを作る(割愛)
model = ...
# 学習
X_train = X[train_indices]
y_train = y[train_indices]
X_test = X[test_indices]
y_test = y[test_indices]
hist = model.fit(X_train, y_train, nb_epoch=nb_epoch, validation_data=(X_test, y_test))
# hist['val_acc'][-1]とかの平均を取るとかmodel.predict()するとか(割愛)
コールバック色々
これも普通にマニュアルが詳しいですが、自分のコピペ用に。
基本のコード
色々追加削除をすることがあるので、以下のような形にして使っています。
callbacks = []
callbacks.append(いろいろ)
callbacks.append(いろいろ)
callbacks.append(いろいろ)
model.fit(略, callbacks=callbacks)
EarlyStopping
下がらなくなったら終わりにするやつ。
callbacks.append(keras.callbacks.EarlyStopping('loss', min_delta=1e-4, patience=1))
実験とかで出来るだけ早く止めたいとき用(?)。
(普通はval_lossの方をmonitorすると思いますが、val_lossはぶれが大きいので個人的には信用してません。)
学習率をちょっとずつ減らす
base_lr = 1e-3 # adamとかならこのくらい。SGDなら例えば 0.1 * batch_size / 128 とかくらい。
lr_decay_rate = 1 / 3
lr_steps = 4
epochs = 300
callbacks.append(keras.callbacks.LearningRateScheduler(lambda ep: float(base_lr * lr_decay_rate ** (ep * lr_steps // epochs))))
最初の頃は float(1e-3 * 0.9 ** ep) などとしていましたが、各学習率でどのくらいちゃんと収束してるのか分かりやすいように、段階的に減らすようにしています。
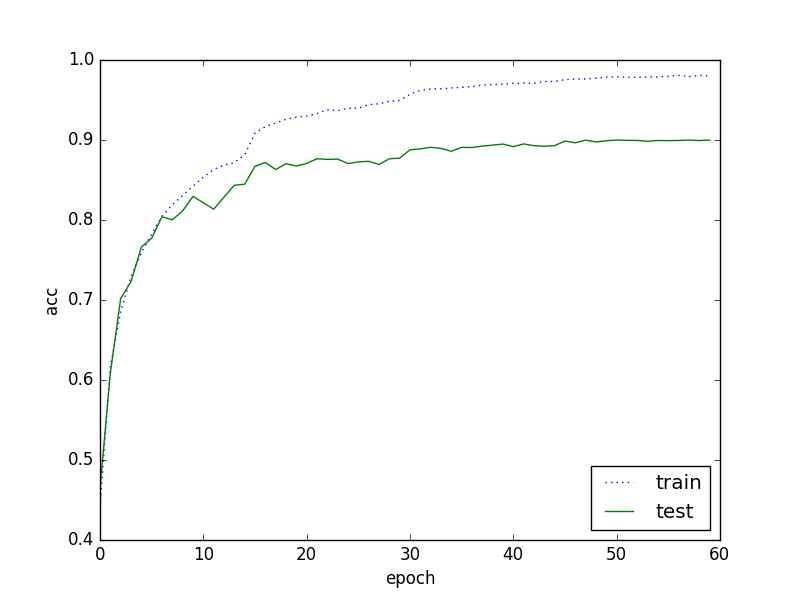
epoch 15、30、45で切り替わっているのが何となく分かります。
あるいは論文とかのCIFAR-10/100で一時期多かった(?)、150epochと225epochで1/10するやつの例。
base_lr = 0.1 * batch_size / 128
epochs = 300
lr_list = [base_lr] * (epochs // 2) + [base_lr / 10] * (epochs // 4) + [base_lr / 100] * (epochs // 4)
callbacks.append(keras.callbacks.LearningRateScheduler(lambda ep: lr_list[ep]))
学習経過をTSV保存
lossなどを保存してくれるもの。csvよりtsvの方がちょっと見やすいのでおすすめ。
callbacks.append(keras.callbacks.CSVLogger('history.tsv', separator='\t'))
TensorBoard用のログ出力
1回やったら飽きましたが一応。
callbacks.append(keras.callbacks.TensorBoard())
SGD+momentum
画像認識界隈(?)ではAdamとかよりSGD+(Nesterov) momentumが使われるのでそんなようなコード例。
optimizer = keras.optimizers.SGD(momentum=0.9, nesterov=True)
model.compile(optimizer=optimizer, loss='categorical_crossentropy', metrics=['acc'])
可視化(モデルの画像化)
keras.utils.plot_model(model, to_file='model.svg', show_shapes=True)
よくあるこういうやつです。
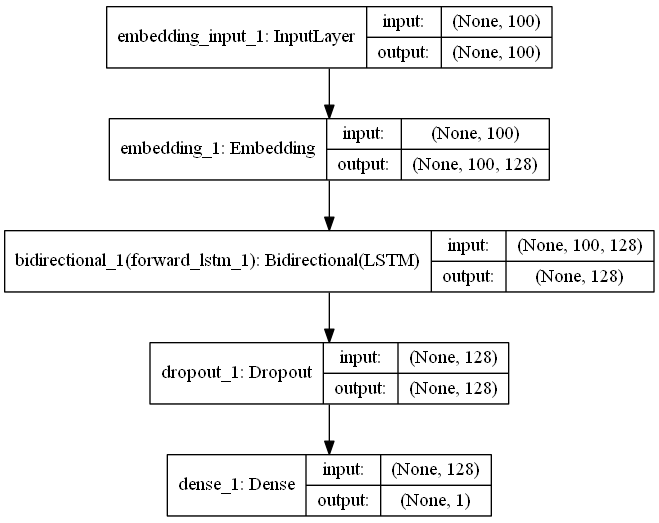
デフォルトはmodel.pngだけど複雑すぎるモデルで落ちたりするので拡張子svgにしてSVG形式で出力するのがおすすめ。
image_data_format
KerasでCNNを使う場合、shapeが(samples, height, width, channels)なのか、(samples, channels, height, width)なのかは変えることができます。
今普通に環境を作るとたぶんデフォルトで前者(channels_last)ですが、古くから使っている環境だとちょっと怪しいです。
設定ファイルとして、~/.keras/keras.jsonのimage_data_formatに書いてあります。
環境構築手順備忘録
-
Minicondaをインストール
全ユーザではなく自分だけにインストールするのがおすすめ。(全ユーザだとpipとかでたまに(?)管理者権限が必要になってしまう)
パスもデフォルトでは通らないけど通しちゃった方が色々楽。(お好みで) -
CUDA Toolkit、cuDNNをインストール
TensorFlowのバイナリの対応状況に合わせたバージョンを。(大抵(?)ちょっと古いバージョンにする必要がある)
古いバージョンはLegacy Releasesボタンから。 -
パッケージをアップデートしたりインストールしたり
conda update --all --yes
pip install tensorflow-gpu keras pydot h5py
マルチGPUの使用
Horovodがおすすめ。