この記事はSnowflake Advent Calendar 2023シリーズ2の13日目です。
みんなでアドベントカレンダーを埋め尽くそうぜ!
はじめに
クマ、怖いですよね。
一部の自治体ではクマ目撃情報をオープンデータとして公開しており、宮城県もサイトで公開してくれています…が、Excelファイルなどでの配布になっています。
とてもありがたいのですがそのままだと分析しやすさはイマイチなので、これをSnowflakeに取り込んでみましょう。
処理の流れ
以下のような流れで処理していきます。
- Python UDFsでExcelファイルを取り込む
- Native Appを使ってジオコーディングする
- Native Appを使ってクラスター分析などを試してみる
Python UDFs(ユーザ定義関数)はSQL文から呼び出せる独自関数をPythonで自作できる機能です。
また、Native Appは他の開発者が作成したアプリケーションを自分のSnowflakeアカウントで使えるようにする機能です。
Native AppはGUIで操作できるアプリケーションらしいアプリケーションから、独自関数を提供してくれる3rdパーティーライブラリのようなものまで色々存在します。
また、処理したものを確認するために合間合間でStreamlitとFoliumを組み合わせて可視化してみましょう。
Python UDFsでExcelファイルを取り込む
まずはExcelファイルを取り込んでみます。
手元でExcelファイルを開いてみると、ヘッダーやフッター、あまり使わなそうな列などがあるので、それもこのタイミングでざっくりと加工できるとよさそうですね。
今回は以下のような設定値で試していきます。
BEAR_DB.MIYAGI.UPLOADにアップロードしたExcelファイルをBEAR_DB.MIYAGI.SOURCE_TABLEにロードしていきます。
| オブジェクト | 名前 |
|---|---|
| データベース | BEAR_DB |
| スキーマ | MIYAGI |
| テーブル | SOURCE_TABLE |
| ステージ | UPLOAD |
ソースコードは以下のようになりました。
OpenPyXLというライブラリでExcelファイルを開いて、データを加工して、save_as_tableでテーブルに書き込むUDFを定義します。
続いてそのUDFをcallすることでExcelファイルを取り込むことができます。
CREATE OR REPLACE PROCEDURE BEAR_DB.MIYAGI.READ_EXCEL(file_path string)
RETURNS STRING
LANGUAGE PYTHON
RUNTIME_VERSION = '3.8'
PACKAGES = ('snowflake-snowpark-python','pandas', 'openpyxl')
HANDLER = 'run'
AS
$$
from snowflake.snowpark.files import SnowflakeFile
import pandas as pd
def run(session, file_path):
with SnowflakeFile.open(file_path, 'rb') as file:
# 年がないので2023年として読み込む
FILE_YEAR = 2023
# 県名をハードコーディングする
PREFECTURE = '宮城県'
# 元データを読み込む
df = pd.read_excel(file, skiprows=[0,1,2], header=None, names=['id', 'month', 'day', 'time', 'office', 'city', 'address', 'area', 'reserved1', 'bear1', 'bear2', 'bear3', 'status', 'trace', 'plan'])
# 1列目が数値でない行を削除
df = df[~pd.to_numeric(df["id"], errors="coerce").isnull()]
# 日付と住所をそれぞれ結合
df['date'] = pd.to_datetime({'year': FILE_YEAR, 'month': df['month'], 'day': df['day']})
df['fulladdress'] = PREFECTURE + df['city'] + df['address']
# 不要な列を削除
df = df.drop(columns=['month', 'day', 'time', 'office', 'reserved1', 'bear3', 'status', 'trace', 'plan'])
# Snowpark DataFrameに変換
df_table = session.create_dataframe(df)
# テーブルに書き込む
df_table.write.mode("overwrite").save_as_table("BEAR_DB.MIYAGI.SOURCE_TABLE")
return session.sql("SELECT COUNT(*) FROM BEAR_DB.MIYAGI.SOURCE_TABLE").collect()
$$;
call BEAR_DB.MIYAGI.READ_EXCEL(
build_scoped_file_url(@BEAR_DB.MIYAGI.UPLOAD, 'koukaiyou.xlsx')
);
本当に取り込めたか確認してみましょう。
SELECT * FROM BEAR_DB.MIYAGI.SOURCE_TABLE LIMIT 10;

無事に取り込めたようです!
Native Appを使ってジオコーディングする
先ほど取り込んだテーブルには住所はあるのですが緯度・経度がありません。
分析するときに数値である緯度・経度があると楽なので、緯度・経度を付与してみましょう。
住所から緯度・経度を算出することをジオコーディングと言います。
Snowflakeにはジオコーディングのための機能は用意されていないのですが、MapboxがNative AppとしてMarketplaceで販売しています。
有償なのですが7日間無料でトライアルできるようなので試してみましょう。
まずはMarketplaceで「Mapbox Geocoding & Analysis Tools」を探して取得します。
アプリケーション名はMAPBOXとするのがよさそうです。
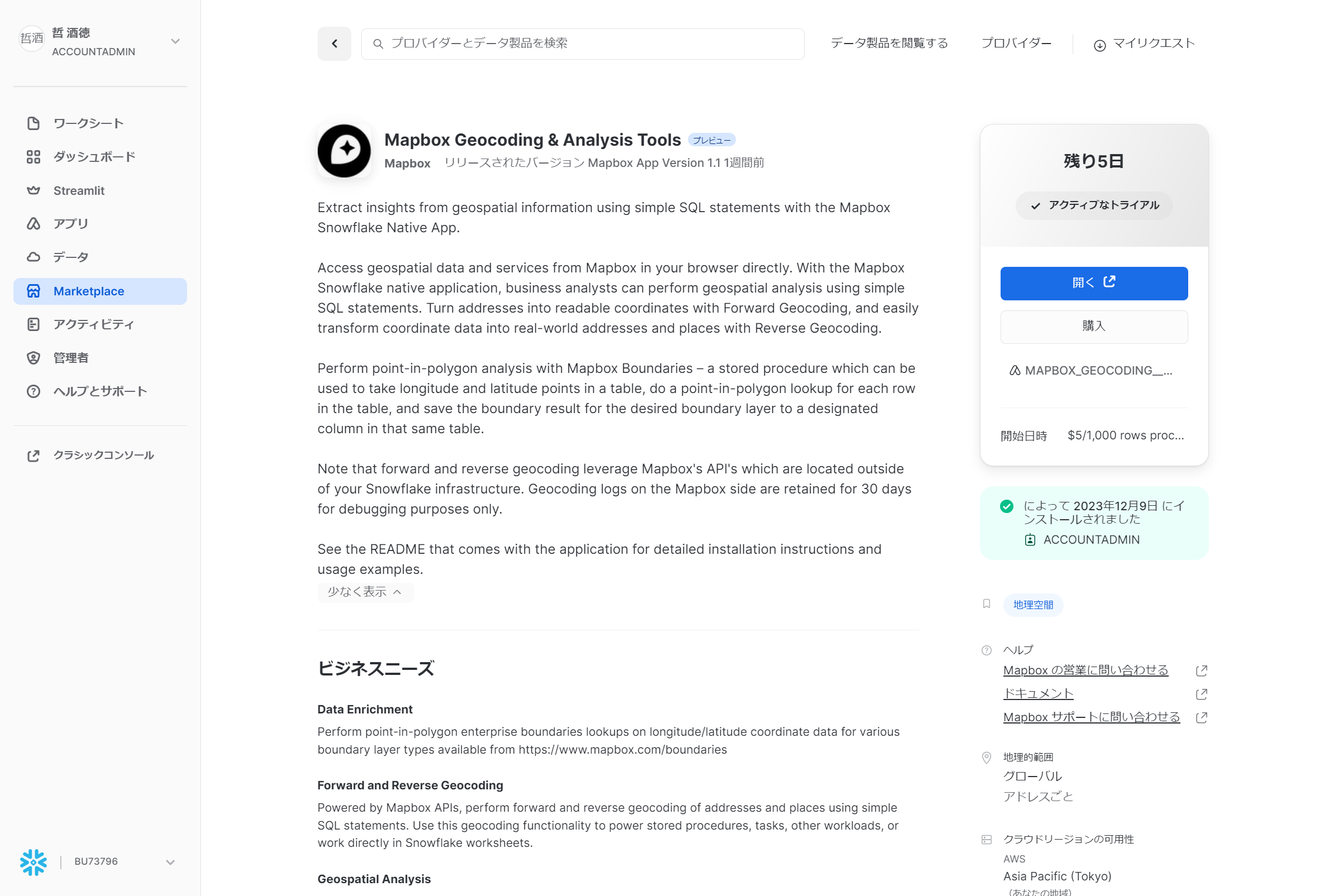
インストールされたら「開く」ボタンからドキュメントを確認して、初期化を行っていきます。
-- MapboxのAPI本体はAWSにあるのでその接続を定義する
CREATE API INTEGRATION mapbox_api_integration
API_PROVIDER = aws_api_gateway
API_AWS_ROLE_ARN = 'arn:aws:iam::234858372212:role/snowflake-mapbox-app-producti-EndpointFunctionRole-8FK34K9GGZTB'
API_ALLOWED_PREFIXES = ('https://tib1ddi7l4.execute-api.us-east-1.amazonaws.com/v1/endpoint')
ENABLED = true;
GRANT USAGE ON INTEGRATION mapbox_api_integration to application MAPBOX;
-- 初期化
CALL MAPBOX.core.setup('mapbox_api_integration');
-- Mapboxが直接テーブルにアクセスできるように許可する
GRANT USAGE ON DATABASE BEAR_DB to application MAPBOX;
GRANT USAGE ON SCHEMA BEAR_DB.MIYAGI to application MAPBOX;
GRANT SELECT ON TABLE BEAR_DB.MIYAGI.SOURCE_TABLE to application MAPBOX;
これでMapboxのAPIを呼び出せるようになったはずなので試してみましょう。
-- 試験接続
SELECT RESULT:latitude, RESULT:longitude
FROM
(
SELECT MAPBOX.core.geocode_forward('白石市大平中目字拾枚田地内') AS RESULT
);

それっぽい緯度・経度が表示されました。
このまますべての行に緯度・経度を付与してみます。
-- ジオコーディングしたものをテーブルに書き出す
CREATE OR REPLACE TABLE BEAR_DB.MIYAGI.GEOCODED_TABLE AS
SELECT "id" as ID, TO_DATE(TO_VARCHAR("date")) AS DATE, "fulladdress" AS FULLADDRESS, RESULT:longitude AS LONGITUDE, RESULT:latitude AS LATITUDE
FROM
(
SELECT "id", "date", "fulladdress", MAPBOX_GEOCODING__ANALYSIS_TOOLS.core.geocode_forward("fulladdress") AS RESULT
FROM BEAR_DB.MIYAGI.SOURCE_TABLE
)
-- ジオコーディングに失敗するとNULLになるのでそれを省く
WHERE LONGITUDE IS NOT NULL AND LATITUDE IS NOT NULL;
これを可視化してみると…
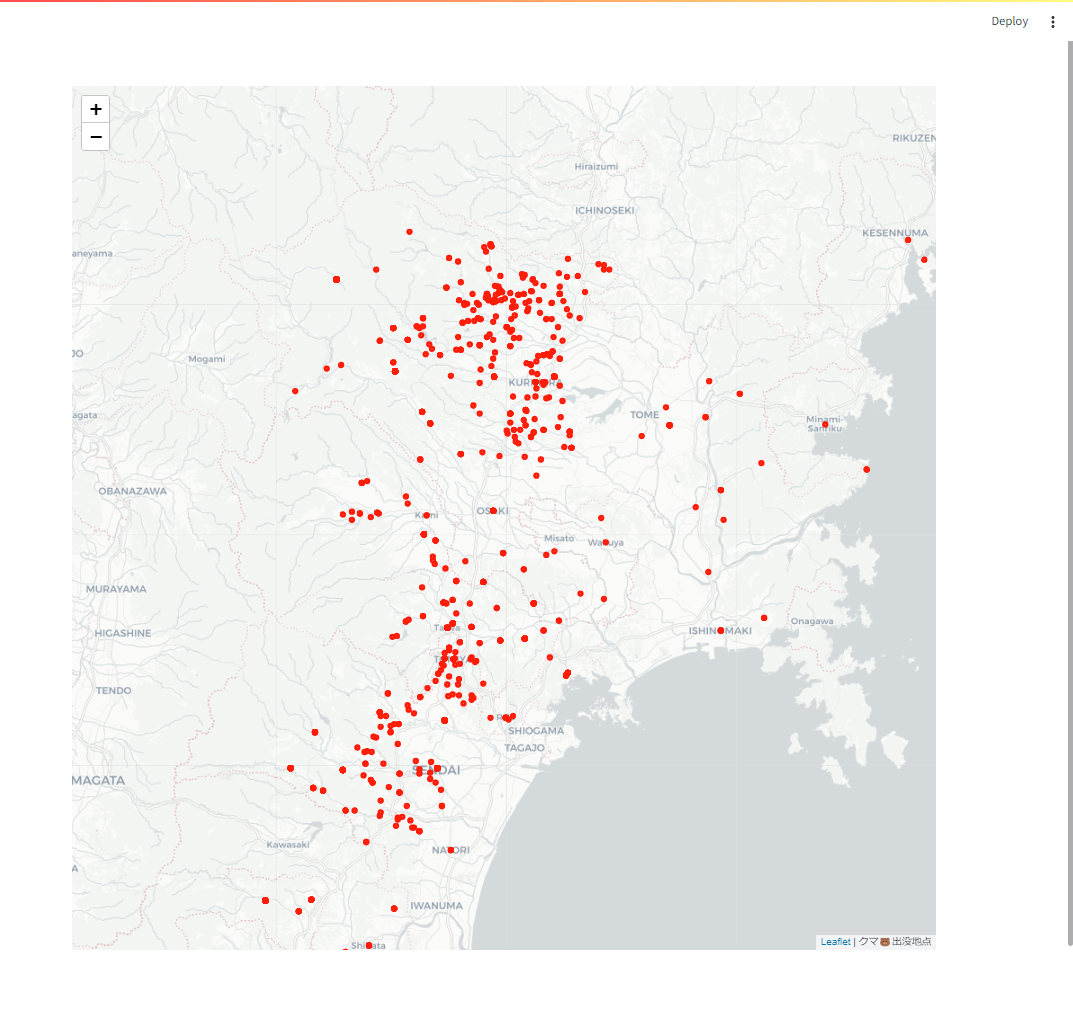
(Streamlit+Foliumで描画)
おお!正しくジオコーディングできているようです!
Native Appを使ってクラスター分析などを試してみる
多数のクマ目撃情報が得られましたが、これだけ見ても「たくさんいるな」って感じですよね。
深堀りするためにクラスター分析でクマをグループ分けしてみましょう。
k-means法を使ってみましょう。k-means法の「k」は多分クマの「k」。知らんけど。
位置情報に対するk-means法のような手の込んだ機能もMarketplaceで公開されています。
今回はCARTOがNative AppとしてMarketplaceで公開しているものを試してみましょう。
Marketplaceで「CARTO Analytics Toolbox Core」を探して取得します。
アプリケーション名はデフォルトのままにするのがよさそうです。
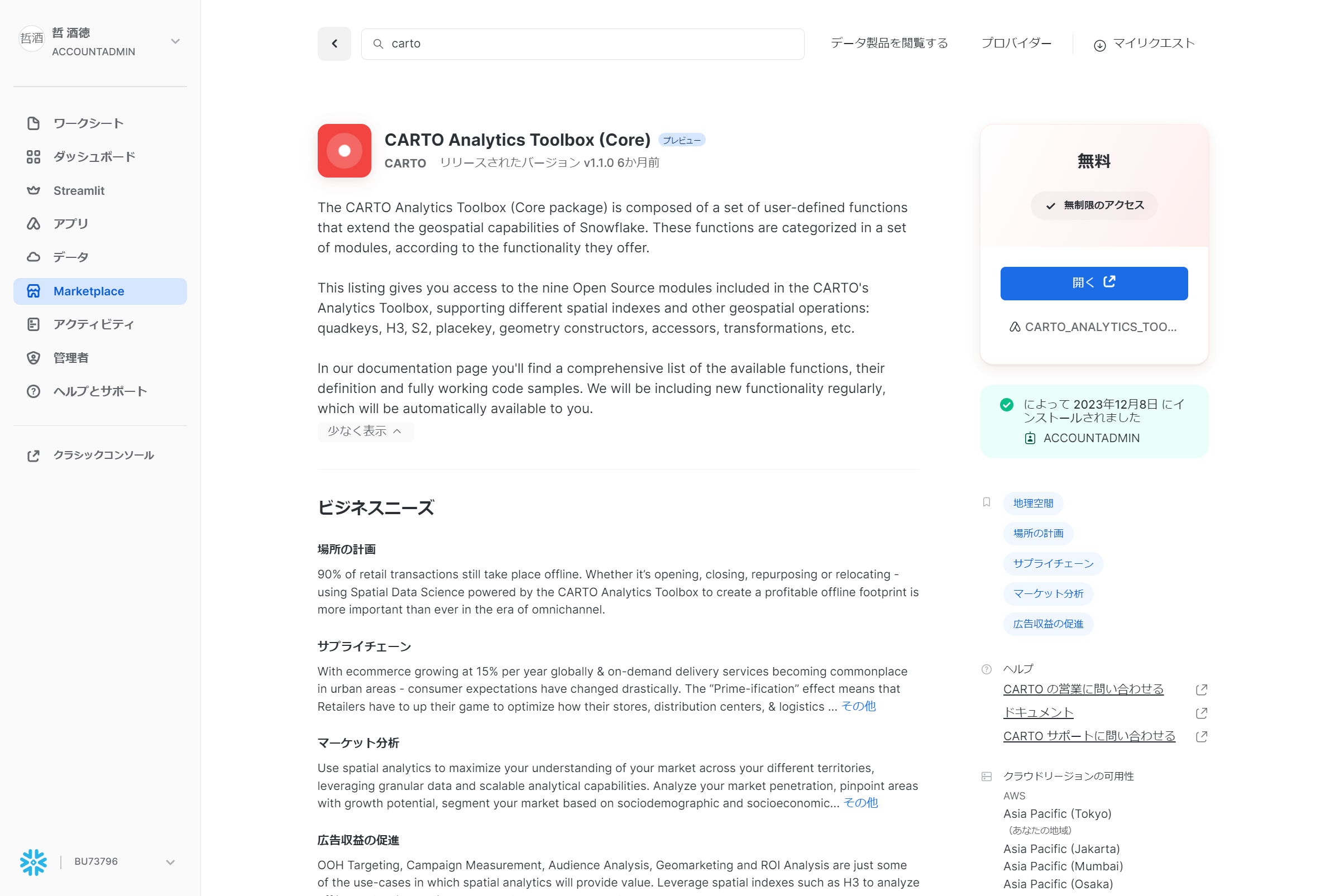
特に初期化は必要ないようなのでこのまま試してみましょう。k-means法はST_CLUSTERKMEANS関数です。
-- グループ分けしたものをテーブルに書き出す
CREATE OR REPLACE TABLE BEAR_DB.MIYAGI.CLUSTERED_TABLE AS
(
WITH SOURCE AS (
SELECT * FROM BEAR_DB.MIYAGI.GEOCODED_TABLE
),
-- ST_CLUSTERKMEANS関数を呼び出す。結果はJSON形式になる
CLUSTERED AS (
SELECT CARTO_ANALYTICS_TOOLBOX_CORE.CARTO.ST_CLUSTERKMEANS(ARRAY_AGG(ST_ASGEOJSON(ST_MAKEPOINT(SOURCE.LONGITUDE, SOURCE.LATITUDE))::STRING)) AS LATLNG_JSON
FROM SOURCE
)
-- 結果をフラット化する
SELECT GET(VALUE, 'cluster') AS CLUSTER_ID, GET(VALUE, 'geom') AS FROM CLUSTERED, LATERAL FLATTEN(input => LATLNG_JSON)
);
これを可視化してみると…

(Streamlit+Foliumで描画)
クマがグループ分けされました。
が、まだちょっと分からないので、さらに各グループの重心点を見てみましょう。重心点の計算はST_CENTROID関数です。
-- ST_CENTROID関数を呼び出す
SELECT CLUSTER_ID, CARTO_ANALYTICS_TOOLBOX_CORE.CARTO.ST_CENTROID(ST_COLLECT(TO_GEOGRAPHY(GEOM))) AS CENTER
FROM BEAR_DB.MIYAGI.CLUSTERED_TABLE GROUP BY CLUSTER_ID;
これを可視化してみると…

(Streamlit+Foliumで描画)
なるほど、k-means法を使ってもあまり意味はなさそう!ということが分かりました。
あえて言うなら、以下のような推測はできるかもしれません。できるか?
- 目撃があまりない地域は人が少ない可能性もあるかも?
- クマの一般的な縄張りサイズを考慮してグループ分けすれば人里に現れるクマの推定頭数が得られるかも?
おわりに
SnowflakeはPython UDFsやNative Appによって高い拡張性を有しています。
これを活用することでクマ目撃情報をSnowflakeに取り込んで、さらに分析することができました。
一方で、それぞれの処理段階で扱うデータの形式が変わるあたりにSnowflakeの地理空間機能の未成熟さがにじみ出ている気もしました。
現状の地理空間機能を上手く使いこなすノウハウを共有しながら、将来のアップデートでもっと使いやすくなることに期待しましょう!
参考:可視化ソースコード
以下のようなプログラムで可視化しました。
import streamlit as st # type: ignore
import pandas as pd # type: ignore
import folium # type: ignore
from streamlit_folium import st_folium # type: ignore
from folium.features import CustomIcon # type: ignore
import json
import re
st.set_page_config(layout="wide")
st.title("Kumalit")
# クラスター分析したデータをdf_clusteredに格納
# 重心点のデータをdf_centerに格納
# GEOM列に格納されているJSONを展開して、coordinatesの値を取得する。二重にエンコードされていることに注意
df_clustered['LATITUDE'] = df_clustered['GEOM'].apply(lambda x: json.loads(json.loads(x)).get('coordinates')[1])
df_clustered['LONGITUDE'] = df_clustered['GEOM'].apply(lambda x: json.loads(json.loads(x)).get('coordinates')[0])
# 色のパターンを用意
color_pattern = ["red", "blue", "green", "purple", "orange", "black", "pink", "cadetblue"]
# 地図を作成
vizmap = folium.Map(
location=[38.368579, 140.972072],
tiles='https://d.basemaps.cartocdn.com/light_all/{z}/{x}/{y}.png',
attr='クマ🐻出没地点',
zoom_start=10
)
# クラスター分析したデータを地図にプロット
for _, row in df_clustered.iterrows():
# 緯度・経度を取得
lat = row['LATITUDE']
lon = row['LONGITUDE']
# 丸形のマーカーを地図に追加
folium.CircleMarker(
[lat, lon],
radius=3,
color=color_pattern[row['CLUSTER_ID'] % len(color_pattern)],
fill_color=color_pattern[row['CLUSTER_ID'] % len(color_pattern)],
fill=True
).add_to(vizmap)
# 重心点のデータを地図にプロット
for i, row in df_center.iterrows():
# カスタムアイコンは毎回初期化する必要がある
bear_icon = CustomIcon(
icon_image = './kumalit/bear.png',
icon_size = (40, 40),
icon_anchor = (20, 20),
popup_anchor = (3, 3)
)
# POINT(140.972072 38.568579)のような形式の値から、緯度経度を取得する
lat = float(re.search(r'POINT\((.*) (.*)\)', row['CENTER']).group(2))
lon = float(re.search(r'POINT\((.*) (.*)\)', row['CENTER']).group(1))
# 重心点をカスタムアイコンとして地図に追加
folium.Marker(
[lat, lon],
icon=bear_icon
).add_to(vizmap)
# Streamlit上に地図を表示
st_folium(vizmap, width=1000, height=1000)