はじめに
- 最近「WordCloudで可視化してみた」という記事が結構公開されているので、自分も最近作ったWordCloudを記事にしてみました。
- この記事でのACLは自然言語処理のトップカンファレンスの1つを指しており、サッカーとは一切関係ありません。
可視化の意義
学生時代のとある1日
教授 「君、今年のACLの論文、何か面白い論文あった?」
私 「(えっ?公開されたの昨晩なんですけど?!)・・・いえ、まだ見てないです・・・」
教授 「じゃあ、来週、今年の傾向と面白そうな論文1本紹介してね。」
私 「・・・はい」
可視化しようがしまいが、結局ある程度の論文には目を通すことになるのですが、今年の傾向を把握するために、計算&可視化プログラムを使って(主観だけでなく)定量的な確証を得よう、ということです。
やりたいこと
- ある年のあるカンファレンスの注目キーワードを可視化する
ポイントは「他の年やカンファレンスと比較して相対的にピックアップされているキーワードを抽出したい」という点です。
そのために、WordCloudで可視化するときのスコアに、単なる頻度ではなく、TFIDFを計算して採用しました。
※ ここでのD(ドキュメント)の単位は開催年別のカンファレンスに相当し、たとえば、ACL2019がドキュメント1つ、NLP2018が1つ、・・・EMNLP2019が1つ、・・・のように扱いました。
手法
といっても、やっていることはレガシーな自然言語処理で、かつ記事上に公開するようなコードではないため、要点を箇条書きで記述するにとどめます。
プログラム詳細を知りたい方はGithubを参照してください。 https://github.com/kazuaki-i/acl_statistics
やっていることは以下の4ステップです。
- ACLアンソロジーのメインカンファレンスのタイトルをスクレイピングする
- IFIDFを計算するために、タイトル中に含まれる単語の出現頻度をカウントする
- (2)でカウントした頻度を使用して、TFIDFを計算する
- 計算したTFIDFをスコアとして、WordCloudで可視化する
気をつけた点としては、
- スクレイピングの時に、各学会のメインカンファレンスのタイトルのみを抽出するための条件の設定(ACLアンソロジーのページがスクレイピングに優しくなかった)
- 単語の頻度をカウントするときにステミングする(単語を原型に戻す処理。今回はsnowballstemmerを利用した)
日本語と異なる点として、英語では単語がスペースで区切られているため、Mecabとかでやる形態素解析の処理は必要ありませんが、過去形や複数形などで変化している単語を原型に戻す「ステミング」の処理が必要です(日本語ではMecabとかが形態素解析のついでにやってくれます)。
このステミングや単語分割はもっと頑張ることができると思いますが、今回は妥協して簡単な処理のみにとどめました。
結果
ACL2019を可視化してみました。

Bertの影響だと思いますが、self-・・・という語が目につきます。
また、医療系のワークショップが開かれていた影響か、健康関連の単語もそこそこの大きさで存在します。
なお、2015年の結果は次のとおりです。
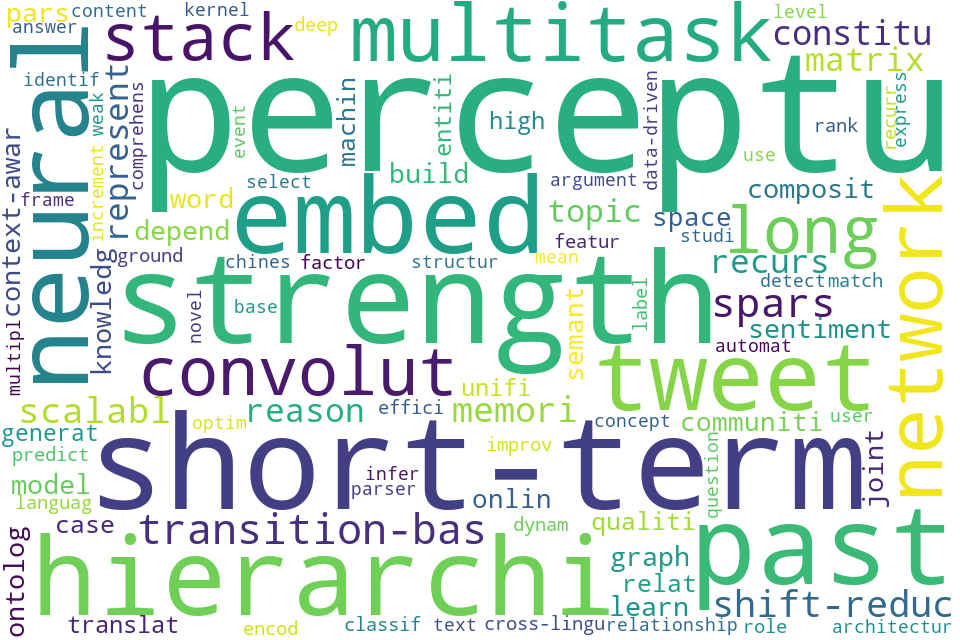
LSTMが流行りだしたころですね。はっきりとshort-termなどのそれっぽい言葉が目に付きます
ちなみにACL2019の公式?のWordCloudはこんな感じ。

まあ、NLP業界で当たり前に使われる語ばかりで、少なくとも2019年の特色を捉えているとは言えないでしょう(そもそもそういう目的で作ったWordCloudではないと思いますが)。
まとめ
- この記事では、ACLアンソロジーで公開されている論文のカンファレンス・年別の特徴を定量的に把握するために、タイトルに含まれている語をTFIDFでスコアリングしてWordCloudで可視化しました。
- 大した処理はしていませんが、なにかの役に立てば幸いです。