本記事では、日本語テキストを対象に Word2Vec を用いて単語の意味空間(ベクトル表現)を学習し、サッカー戦術に関する国別文書から 「その国らしい特徴語」 を抽出します。さらに、抽出した単語をもとに PCAによる2次元可視化(概念MAP) を作成するまでの一連の流れをまとめます。
題材として、2026年ワールドカップのグループF(日本・オランダ・チュニジア)を想定し、各国のサッカー戦術を説明する短文データ(各10文)を用意しました。Janomeで形態素解析を行い、助詞・動詞など分析ノイズになりやすい要素や国名などのストップワードを除外して、戦術的な特徴を表しやすい語(主に名詞)に絞って扱います。
特徴語の抽出には、単なる頻出語ではなく 「国 vs その他(残り2国)」 の差を捉えるために、スムージング付きの ログオッズ(log odds) を用います。最後に、抽出した特徴語のWord2Vecベクトルを PCAで2次元に圧縮 し、国別に色分けした散布図として表示することで、戦術用語の「近さ(同じ文脈で使われる度合い)」を直感的に比較できるようにします。
この記事でわかること
- Janomeを使った日本語テキストの前処理(ストップワード・品詞フィルタ・簡易複合語)
- Word2Vec(Skip-gram)で単語ベクトルを学習する方法
- ログオッズで「国別に特徴的な単語」を自動抽出する方法
- Word2VecベクトルをPCAで2次元化し、概念MAPとして可視化する方法
- 可視化結果の読み方(近い語=似た文脈、国ごとの語彙の固まり方)
本記事の前提となる、Word2Vecの基本的な考え方を解説した記事です →
Word2Vecの仕組みと考え方
分析対象 文書の定義
import re
import numpy as np
from janome.tokenizer import Tokenizer
from gensim.models import Word2Vec
from collections import Counter
import matplotlib.pyplot as plt
import japanize_matplotlib
japanize_matplotlib.japanize()
soccer_documents = [
# 日本
"日本はゾーン守備とスライドを徹底し、連動性と規律でライン間の間延びを防ぐ。ハーフスペースを消し、外誘導から回収を狙う。",
"日本は連動プレスでパスコースを制限し、囲い込みで奪回する。奪った後はサイドチェンジで相手のスライドを逆手に取る。",
"日本はビルドアップで三角形を作り、3人目の受け手で前進する。ハーフスペースの受け手と逆サイドの幅取りを同時に行う。",
"日本は中盤の規律を保ち、ゾーンの間に侵入されない配置を優先する。セカンドボール回収で攻守の安定を作る。",
"日本は前線の連動でプレッシングトリガーを共有し、限定した方向へ誘導して奪回する。中央閉鎖と外回収が基本。",
"日本はサイドで数的優位を作り、ワンツーと3人目で崩す。クロスよりもカットバックを重視してゴール前を攻略する。",
"日本は最終ラインのラインコントロールで背後を管理し、ゾーンの間隔を一定に保つ。スライドとカバーで中央を固める。",
"日本は守備からの切り替えで即座に前進よりも保持を選び、再配置して攻撃を組み立てる。規律と連動を崩さない。",
"日本はハーフスペースの受け手を増やし、三角形のパスワークで前進する。外の幅と内側の受けを両立する。",
"日本は連動性で局面の数的不利を補い、規律でブロックを維持する。奪回後は素早いサイドチェンジで形勢を変える。",
# オランダ
"オランダはポジショナルプレーで5レーンを使い、ライン間の占有を最優先する。立ち位置で相手の守備を固定し、前進を作る。",
"オランダはローテーションで配置を崩し、ハーフスペースの受け手と外幅のウイングで相手のスライドを引き裂く。",
"オランダは偽9番で中盤を厚くし、第三者の動きで背後を取る。中央の数的優位からスルーパスを狙う。",
"オランダは即時奪回(カウンタープレス)でボールロスト直後に回収する。高い最終ラインと前向き守備が特徴。",
"オランダはビルドアップで3-2の基盤を作り、レーン固定と角度でパスコースを連続的に生成する。",
"オランダはライン間の受け手を常に確保し、相手のブロックに対して外→内の順で侵入する。5レーンの維持が鍵。",
"オランダは幅と深さを同時に確保し、ボールサイドに寄せた相手を逆手に取る。逆サイドの孤立を作り突破する。",
"オランダはポジショナルの原則で立ち位置を厳密に管理し、ローテーションは秩序ある交代で行う。配置の再現性が高い。",
"オランダは前線の圧力で相手のビルドアップを窒息させ、即時奪回で二次攻撃を連発する。押し込む時間が長い。",
"オランダはライン間の支配と即時奪回を両立し、5レーンの配置からテンポ変化で崩す。偽9番とハーフスペースが軸。",
# チュニジア
"チュニジアはローブロックで密集を作り、中央封鎖を徹底する。ブロック外では撤退優先で背後を渡さない。",
"チュニジアはミドルブロックからデュエルで止め、奪取後は縦への速攻を狙う。ロングボールとセカンド回収が重要。",
"チュニジアはサイドに追い込み、タッチラインを味方にして回収する。中央は人数で閉鎖し、危険地帯を消す。",
"チュニジアはターゲットへのロングボールで前進し、落としからセカンドボールを回収する。二次攻撃で押し上げる。",
"チュニジアは撤退の速さでブロックを整え、スペース管理を優先する。攻撃は少人数の速攻で完結させる。",
"チュニジアはセットプレーを重視し、CKやFKで得点機会を作る。流れの攻撃よりも再開局面の強度が高い。",
"チュニジアは密集守備で中央を消し、外側のクロスに対応する。空中戦とクリアで耐え、回収から速攻へ出る。",
"チュニジアは守備のブロック間隔を狭く保ち、ライン間を空けない。デュエルと身体能力で前進を止める。",
"チュニジアは攻撃の形がシンプルで、縦パスとドリブルで前進する。奪った瞬間の縦速度を最優先する。",
"チュニジアはローブロック+速攻で試合を制御する。密集、撤退、ロングボール、セカンド回収、セットプレーが柱。"
]
document_labels = (["日本"] * 10) + (["オランダ"] * 10) + (["チュニジア"] * 10)
countries = ["日本", "オランダ", "チュニジア"]
前処理
Word2Vecを学習するためには、文章をそのまま渡すのではなく、文書を「単語の並び(トークン列)」に変換する必要があります。そこでこのステップでは、以下の処理を実装します。
・Janomeを使って日本語文書を形態素解析
・助詞・動詞など分析ノイズになりやすい語を除外
・国名など必ず出る語(ストップワード)を除外
・戦術的に意味のある語(主に名詞)だけを抽出
さらに、「組織+性 → 組織性」「ポジショナル+プレー → ポジショナルプレー」のように、簡易的に複合語も復元します。
この結果として、Word2Vec学習用の単語列 all_sentences 国別単語リスト country_tokensを作成します。
import re
from janome.tokenizer import Tokenizer
# ストップワード(必ず出る語を除外)
# 国名や「サッカー」「戦術」などは特徴語になりにくいため除外する
japanese_stop_words = {
"日本", "オランダ", "チュニジア",
"サッカー", "戦術", "スタイル", "選手",
"ピッチ", "特徴", "ボール",
"これら", "もと", "もの", "ごと", "こと", "この"
}
# 除外する品詞(ノイズになりやすい語)
exclude_pos = {"動詞", "形容詞", "助詞", "助動詞", "記号", "補助記号", "空白"}
tokenizer = Tokenizer()
# 日本語単語抽出関数
# 文書を形態素解析し、意味のある語(主に名詞)だけを残す
def extract_japanese_words(text: str):
raw = []
# 文を形態素解析して単語単位に分割
for token in tokenizer.tokenize(text):
# 品詞(名詞・動詞など)
pos = token.part_of_speech.split(",")[0]
# 基本形(原形)
word = token.base_form.strip()
# --- 除外条件 ---
if not word or word == "*":
continue
if pos in exclude_pos:
continue
if word in japanese_stop_words:
continue
# 数字だけの語は除外
if re.fullmatch(r"[0-90-9]+", word):
continue
# 日本語・英字・数字以外の記号を除外
if re.fullmatch(r"[ぁ-んァ-ン一-龥a-zA-Z0-90-9ー・]+", word) is None:
continue
raw.append(word)
# 簡易複合語復元(最小限)
# 「組織 + 性」→「組織性」
# 「ポジショナル + プレー」→「ポジショナルプレー」
merged = []
i = 0
while i < len(raw):
w = raw[i]
# 組織性・連動性
if i + 1 < len(raw) and raw[i + 1] == "性" and w in ("組織", "連動"):
merged.append(w + "性")
i += 2
continue
# ポジショナルプレー
if i + 1 < len(raw) and raw[i + 1] == "プレー" and w == "ポジショナル":
merged.append("ポジショナルプレー")
i += 2
continue
merged.append(w)
i += 1
# 1文字語は除外して返す
return [w for w in merged if len(w) > 1 and w not in japanese_stop_words]
# 国別トークンとWord2Vec学習用文リストを作成
# 国ごとに単語をまとめる辞書
country_tokens = {c: [] for c in countries}
# Word2Vec学習用(文ごとの単語列)
all_sentences = []
# 各文書を単語列に変換して保存
for doc, c in zip(soccer_documents, document_labels):
# 単語抽出
ws = extract_japanese_words(doc)
# Word2Vec用に文単位で追加
all_sentences.append(ws)
# 国別に単語を追加
country_tokens[c].extend(ws)
print("前処理完了")
print("文数:", len(all_sentences))
print("日本トークン数:", len(country_tokens["日本"]))
print("オランダトークン数:", len(country_tokens["オランダ"]))
print("チュニジアトークン数:", len(country_tokens["チュニジア"]))
前処理完了
文数: 30
日本トークン数: 106
オランダトークン数: 95
チュニジアトークン数: 94
# 前処理の結果表示
print("\n\n===== 国ごとのトークン総数 =====")
for c in countries:
print(f"{c}: {len(country_tokens[c])} tokens")
print("\n\n===== 国ごとの頻出語 Top15 =====")
for c in countries:
cnt = Counter(country_tokens[c])
print(f"\n--- {c} ---")
for w, n in cnt.most_common(15):
print(f"{w}: {n}")
===== 国ごとのトークン総数 =====
日本: 106 tokens
オランダ: 95 tokens
チュニジア: 94 tokens
===== 国ごとの頻出語 Top15 =====
--- 日本 ---
規律: 4
サイド: 4
ゾーン: 3
スライド: 3
ライン: 3
ハーフ: 3
スペース: 3
回収: 3
連動: 3
奪回: 3
受け手: 3
前進: 3
守備: 2
連動性: 2
誘導: 2
--- オランダ ---
相手: 5
レーン: 4
ライン: 4
配置: 3
即時: 3
奪回: 3
位置: 2
守備: 2
固定: 2
ローテーション: 2
ハーフ: 2
スペース: 2
受け手: 2
パス: 2
ビルドアップ: 2
--- チュニジア ---
回収: 5
ブロック: 4
速攻: 4
攻撃: 4
密集: 3
中央: 3
撤退: 3
優先: 3
ロング: 3
セカンド: 3
前進: 3
ローブ: 2
ロック: 2
デュエル: 2
人数: 2
Word2Vec学習(単語ベクトル化)
前処理で作成した all_sentences(単語列データ)を使ってWord2Vecモデルを学習します。
Word2Vecを学習すると
「連動」と「規律」
「ローブロック」と「撤退」
「ポジショナルプレー」と「5レーン」
のように、同じ文脈で使われる単語同士が近いベクトル空間に配置されるようになります。
つまりこのステップは、戦術用語を“意味の近さ”で表現できる単語ベクトルを作ることが目的です。
# Word2Vec 学習(単語ベクトル化)
from gensim.models import Word2Vec
# Word2Vecモデルの学習
model = Word2Vec(
sentences=all_sentences, # 学習対象(単語リストの集合)
vector_size=100, # ベクトル次元数(意味空間の広さ)
window=5, # 周囲何語を文脈として見るか
min_count=1, # 出現回数が1回以上の単語を学習対象にする
workers=4, # CPU並列数(高速化)
sg=1, # 1=Skip-gram(小規模データに強い)
negative=5, # ネガティブサンプリング数
alpha=0.025, # 学習率(初期値)
epochs=200 # 学習繰り返し回数(小規模なので多め)
)
# 学習された語彙(単語一覧)を取得
# model.wv.key_to_index に学習済み単語が格納されている
vocab = set(model.wv.key_to_index.keys())
# 学習結果の確認
print("Word2Vec学習完了")
print("語彙数(学習された単語数):", len(vocab))
Word2Vec学習完了
語彙数(学習された単語数): 150
国別特徴語抽出(ログオッズ)
次に、国ごとの単語出現を比較して「その国らしい語」をログオッズで抽出します。
Word2Vecで単語ベクトルを学習しただけでは、
「どの単語が日本らしいのか?」
「オランダ特有の戦術語は何か?」
といった 国別の特徴語 はまだ分かりません。そこでこのステップでは、「ある国でよく出るが、他国ではあまり出ない単語」を自動的に抽出します。
※ログオッズ
単語 w が 国 𝑐に出やすい確率 𝑝𝑐(w) その他(残り2国)に出やすい確率 𝑝𝑜(w)を比較し、log 𝑝𝑐(𝑤)/𝑝𝑜(𝑤) が大きい単語ほど「その国らしさが強い」と判断します。
from collections import Counter
import numpy as np
# 国別特徴語を抽出する関数(ログオッズ)
# 各国の単語頻度を比較して、
# 「その国で特に出やすい語」をスコア化する
# score = log(p_c) - log(p_other)
# score > 0 なら「その国らしい語」
def auto_select_country_keywords(country_tokens, vocab, topn=10, alpha=0.5):
results = {}
# 全語彙を集める(Word2Vec学習済み語のみ対象)
all_words = set()
for c, toks in country_tokens.items():
all_words.update(toks)
# 学習済み語彙と共通する語だけ残す
V = list(all_words & vocab)
Vset = set(V)
# 全体頻度(3国合計)を計算
total_counter = Counter()
for c in country_tokens:
total_counter.update([w for w in country_tokens[c] if w in Vset])
# 各国ごとに「国 vs その他」で比較する
for c in country_tokens:
# 対象国の単語頻度
c_counter = Counter([w for w in country_tokens[c] if w in Vset])
# その他(残り2国)の頻度
other_counter = total_counter - c_counter
# 総単語数
c_total = sum(c_counter.values())
o_total = sum(other_counter.values())
scores = []
# 各単語のログオッズスコアを計算
for w in V:
cw = c_counter.get(w, 0) # 国cでの出現回数
ow = other_counter.get(w, 0) # その他での出現回数
# スムージング(ゼロ割防止)
p_c = (cw + alpha) / (c_total + alpha * len(V))
p_o = (ow + alpha) / (o_total + alpha * len(V))
# ログオッズスコア
score = float(np.log(p_c) - np.log(p_o))
scores.append((w, score))
# スコアが高い順に並べて上位語を抽出
scores.sort(key=lambda x: x[1], reverse=True)
# 「国らしさがある語」だけ採用(score > 0)
picked = [x for x in scores if x[1] > 0]
# 上位topn語を保存
results[c] = picked[:topn]
return results
# 国別特徴語を抽出して表示
country_keywords = auto_select_country_keywords(
country_tokens,
vocab,
topn=10, # 各国の特徴語を10個表示
alpha=0.5 # スムージング係数
)
print("【国別キーワード(ログオッズ上位)】")
for c in countries:
print(f"\n■ {c}")
for w, s in country_keywords[c]:
print(f" {w}: {s:.3f}")
【国別キーワード(ログオッズ上位)】
■ 日本
規律: 2.575
連動: 2.323
ゾーン: 2.323
三角形: 1.987
誘導: 1.987
連動性: 1.987
チェンジ: 1.987
受け: 1.476
攻守: 1.476
基本: 1.476
■ オランダ
レーン: 2.678
即時: 2.427
確保: 2.090
ローテーション: 2.090
位置: 2.090
固定: 2.090
相手: 1.780
スルー: 1.580
連発: 1.580
直後: 1.580
■ チュニジア
速攻: 2.688
密集: 2.436
ロング: 2.436
撤退: 2.436
ロック: 2.100
人数: 2.100
ローブ: 2.100
デュエル: 2.100
プレー: 2.100
セット: 2.100
概念MAP可視化(PCA→2次元散布図)
抽出した特徴語をWord2Vec空間に配置しPCAで2次元に落として概念MAPを描きます。
抽出した 国別特徴語 は、スコア(ログオッズ)で「国らしさ」は分かります。
ただ、それだけだとそれらの語同士が「意味的に近いのか?」
どの国の語が似た概念領域にあるのか?
が分かりません。
そこでこのステップでは、
・特徴語の Word2Vecベクトル(100次元) を取り出す
・PCAで 2次元に圧縮(見える形にする)
・国別に色分けして散布図(概念MAP)を描く
という流れで、「戦術用語の意味空間」を可視化します。
import numpy as np
import matplotlib.pyplot as plt
# PCAでベクトルを2次元に落とす関数
# Word2Vecのベクトルは高次元(例:100次元)なので、そのままでは散布図にできない
# PCA(主成分分析)で情報量が大きい方向を2軸に圧縮し、2次元で「近い/遠い」を見える化する
def pca2d(X):
X = np.asarray(X, dtype=float)
# 平均0にセンタリング(PCAの基本手順)
Xc = X - X.mean(axis=0, keepdims=True)
# 共分散行列
cov = np.cov(Xc, rowvar=False)
# 固有値・固有ベクトル(PCAの核)
eigvals, eigvecs = np.linalg.eigh(cov)
# 固有値が大きい順(主成分の重要度順)に並べる
order = np.argsort(eigvals)[::-1]
# 上位2成分の固有ベクトル(2次元への変換行列)
W = eigvecs[:, order[:2]]
# 2次元へ射影
return Xc @ W
# 概念MAPに載せる点を作る
# points: (国, 単語, スコア, ベクトル) のタプルで保持
# ※同じ単語が別国に出ても「国別の点」としてプロットしたいので(国, 単語)単位で保持する
points = []
for c in countries:
for w, s in country_keywords[c]:
if w in model.wv: # 学習済み語のみ
points.append((c, w, s, model.wv[w]))
if len(points) < 3:
raise ValueError("可視化に十分な語彙がありません(抽出語が少なすぎます)。")
# ベクトルをまとめてPCAで2次元化
vecs = np.vstack([v for _, _, _, v in points]) # (N, 100)
xy = pca2d(vecs) # (N, 2)
# 散布図として可視化
colors = {"日本": "tab:red", "オランダ": "tab:blue", "チュニジア": "tab:green"}
plt.figure(figsize=(12, 8))
# プロット(点+ラベル)
for (c, w, s, _), (x, y) in zip(points, xy):
# 点(●)を描画
plt.scatter(
x, y,
s=60, # 点サイズ
alpha=0.75, # 透明度
c=colors[c], # 国ごとに色分け
label=c
)
# ラベル(単語)を点の近くに表示
plt.annotate(
w,
(x, y),
xytext=(4, 4), # 文字の位置を少しずらす
textcoords="offset points",
fontsize=8 # ラベルを少し小さく
)
# 凡例の重複を削除(scatterで毎回labelを付けるため)
handles, labels = plt.gca().get_legend_handles_labels()
seen = set()
new_handles, new_labels = [], []
for h, lab in zip(handles, labels):
if lab not in seen:
new_handles.append(h)
new_labels.append(lab)
seen.add(lab)
plt.legend(new_handles, new_labels, title="国")
plt.title("戦術用語の概念MAP(Word2Vec + PCA)", fontsize=14)
plt.xlabel("PC1(主成分1)")
plt.ylabel("PC2(主成分2)")
plt.grid(True, alpha=0.2)
plt.tight_layout()
plt.show()
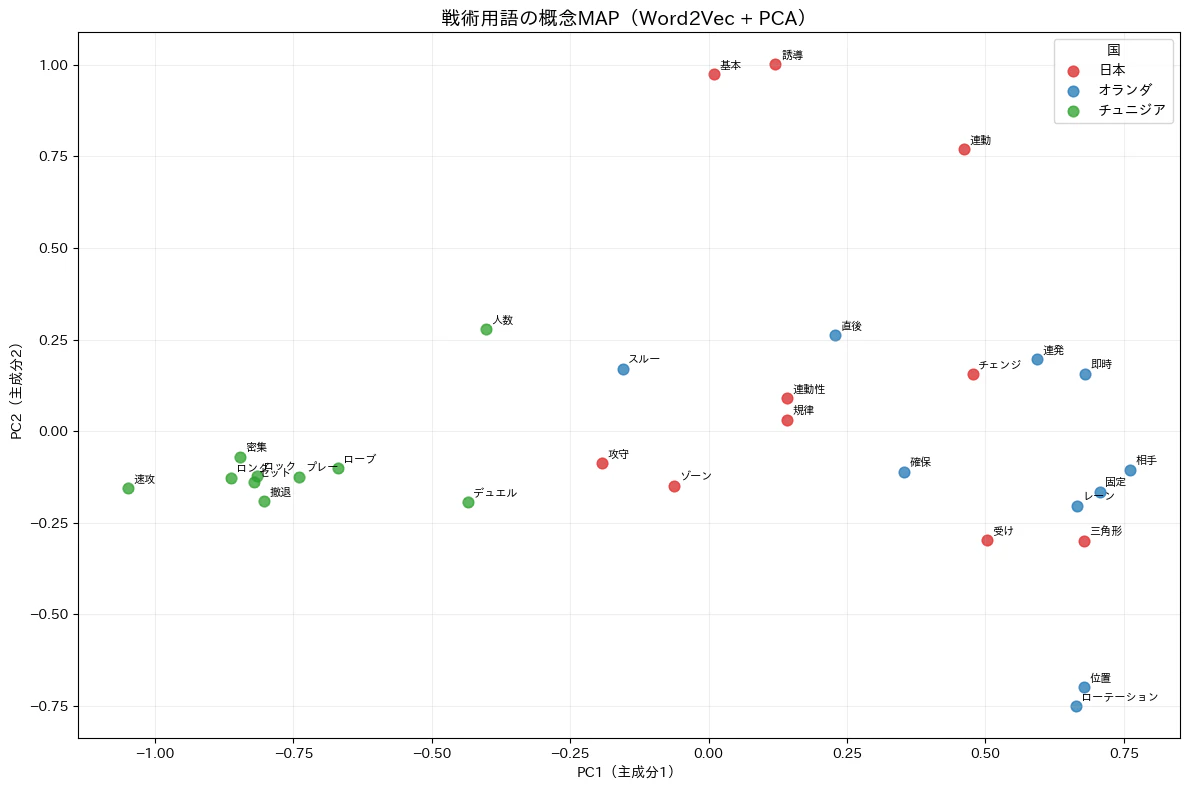
結果の解釈
日本の語彙を見ると、連動、連動性、規律、ゾーン、誘導、基本などがまとまって配置されています。
日本は「ゾーン守備、スライド、組織的な連動、規律ある守備ブロック」といった「集団戦術」を重視する傾向が強いことが反映されています。
オランダ側には「ローテーション、位置、即時、間接、確保」などが集中しています。
これは典型的なポジショナルプレー、立ち位置による優位性、パス構造の設計、即時奪回(ゲーゲンプレス)を示す語彙であり、オランダの「配置と構造」の思想が見えます。
チュニジアの語彙は左側に集まり、「速攻、ロングボール、競り合い、デュエル、撤退、密集」などが近い位置にあります。
これは守備ブロックを敷く、ボール奪取後に速攻、対人強度(デュエル)、ロングで前進という「現実的・縦に速い」スタイルを表しています。
MAP上で見ると、日本(赤)とオランダ(青)は右側で一部近い
→ 組織性・ビルドアップの概念が共有されている
チュニジア(緑)は左側で独立
→ 対照的な縦志向・守備的スタイル
という構造になっています。
中央にある単語は「共通戦術語彙」と解釈できます。
例えば中央付近にある「攻守、ゾーン、スルー」などは、国を問わず登場するため「共通概念」として中心に配置されます。
まとめ(改善・発展アイデア)
前処理の精度を上げる(複合語の扱い)
今回の結果を見ると、例えば
ロー + ブロック のように ローブロックが分割されていました
改善案
「ロー + ブロック → ローブロック」
「セカンド + 回収 → セカンド回収」
「ライン + 間 → ライン間」
など、分析対象に合わせて複合語ルールを追加する
Word2Vecの妥当性チェック(近傍語を見る)
学習できているかは 類似語の確認が一番わかりやすいです
例
model.wv.most_similar("規律")
model.wv.most_similar("ローテーション")
model.wv.most_similar("速攻")
概念MAPをPCA以外で可視化する(t-SNE / UMAP)
PCAは「全体の分散」を保つのが得意ですが、局所構造(近傍のまとまり)は崩れることがあります
発展案
t-SNE:近い語のクラスタがより見えやすい
UMAP:高速で構造も保持しやすい(最近の定番)
特徴語抽出を別手法と比較する(再現性・説明性)
今回はログオッズでしたが、他にも「特徴語抽出」の手法を試す
・TF-IDF(文書内の重要度、説明しやすい)
・χ²(カイ二乗)(分類タスクで強い)
・PMI / LLR(共起の強さを見たいとき)
データ量を増やして安定させる(重要)
Word2Vecは データが少ないとベクトルが不安定になりやすいです
発展案
国ごとに戦術記事・試合分析記事を増やす
文書数を「各国10→100」に増やす
文長を揃えて、国ごとの単語数バランスを取る
Word2Vecは「単語の意味の近さ」を学習できるため、TF-IDFのような頻度ベースとは違い、文脈を含んだ戦術用語の関係性を捉えられる点が魅力です。
今回のように、特徴語抽出(ログオッズ)と可視化(概念MAP)を組み合わせることで、国別の戦術スタイルを“単語の地図”として俯瞰することが可能になります。
複合語の強化や可視化手法の変更(t-SNE/UMAP)を加えて、概念MAPの解像度を上げてみてください。