はじめに
こんにちは。野村総合研究所の早川です。
本記事では AWS Lambda Durable Functionsの仕組みを解説し、Step Functionsとの使い分け、実際に使った場合に気をつけるべきことを紹介します。
従来、Lambdaといえば「ステートレスで使う」「マルチステップ処理は Step Functions に任せる」「状態管理は DynamoDB に外出しする」というのが設計のベストプラクティスとされてきました。
ところがre:Invent 2025にて、その前提を変える AWS Lambda Durable Functions が登場し、Lambda関数の中で状態管理や複数ステップにわたる長期実行ワークフローをコードとして書けるようになりました。
AWS Lambda Durable Functions とは
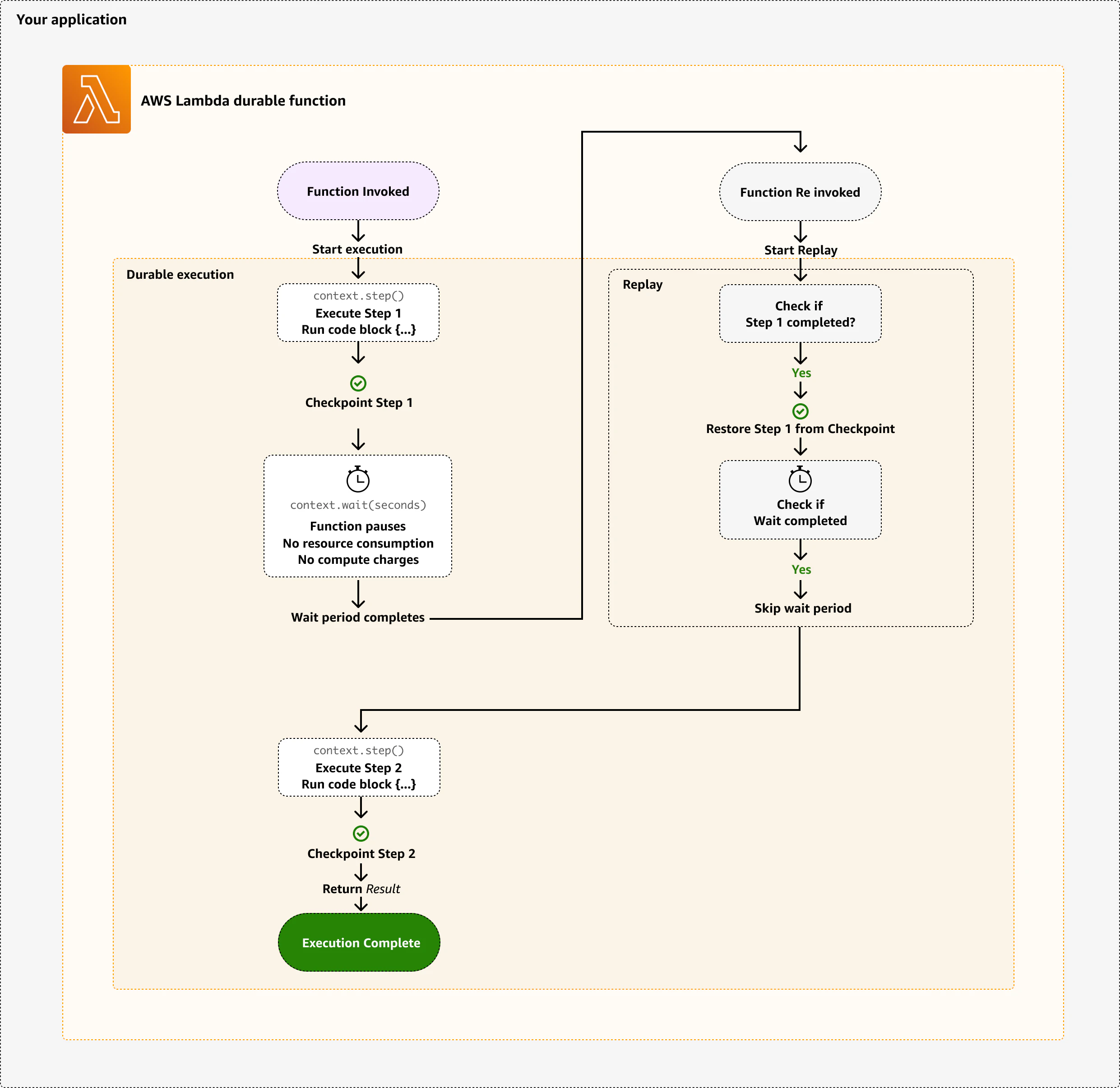
Lambda Durable Functions は、Lambda関数内でステートフルなワークフローを記述できる新しい機能です。
従来のLambdaとの最大の違いは「実行を途中で止めて、後から再開できる」点です。外部APIの応答待ち、人間の承認待ち、長時間バッチ処理などをLambdaの中でプログラム言語で定義できるようになりました。
これをどのように実現しているのかを理解するうえで、重要な仕組みがチェックポイントとリプレイです。
出典:https://docs.aws.amazon.com/lambda/latest/dg/durable-functions.html
動作の流れ
- 関数がStep・Wait・Callbackに到達すると、その結果をチェックポイントとして保存して一時停止します
- 次回起動時、関数コードは最初からリプレイされます
- チェックポイントに記録済みの処理はスキップされ、保存済みの結果が再利用されます
- 未完了のステップに到達したところから処理を再開します
このリプレイの仕組みがあるため、コードは必ず同じ入力に対して同じ結果を返すように実装しなければなりません(冪等性)。
リプレイ時に異なる値を返すコードがStep外にあると、チェックポイントに記録された値と矛盾が生じてエラーになります。
ファイルI/O、外部API呼び出し、乱数生成といった、冪等性を持たない処理はすべてStep内に収める必要があります。
4つの構成要素
Durable Functionsには「Step」「Wait」「Callback」「Parallel/Map」という4種類のコンポーネントがあります。これらを組み合わせることでワークフローを組み立てます。
Step
Stepはビジネスロジックの実行単位です。自動リトライと進捗追跡が組み込まれており、完了結果はチェックポイントに保存されます。
@durable_step デコレータで関数をステップとして実行可能にします。ステップ名はデフォルトでは関数名が使用されます。
from aws_durable_execution_sdk_python import (
DurableContext,
StepContext,
durable_execution,
durable_step,
)
@durable_step
def add_numbers(step_context: StepContext, a: int, b: int) -> int:
return a + b
@durable_execution
def handler(event: dict, context: DurableContext) -> int:
result = context.step(add_numbers(5, 3))
return result
Wait
Waitはリプレイ条件のイベントが来るまでコンピュート課金なしで待機します。タイムアウト設定も可能です。
以下は単純に5秒待機する例です。
from aws_durable_execution_sdk_python import DurableContext, durable_execution
from aws_durable_execution_sdk_python.config import Duration
@durable_execution
def handler(event: dict, context: DurableContext) -> str:
"""Simple durable function with a wait."""
# Wait for 5 seconds
context.wait(duration=Duration.from_seconds(5))
return "Wait completed"
Callback
Callbackは外部システムからのイベントを受け取るためのコンポーネントです。context.create_callback(name="wait-for-approval") でチェックポイントを作成すると同時に、callback_id が発行されます。Durable Function は、外部システムから対象のidで結果が送られてくるまで一時停止します。
結果は callback.result() で受け取ります。
from typing import Any
from aws_durable_execution_sdk_python import DurableContext, durable_execution
@durable_execution
def handler(event: Any, context: DurableContext) -> dict:
callback = context.create_callback(name="wait-for-approval")
# Send callback.callback_id to the external system that will resume this function.
send_approval_request(callback.callback_id, event["request_id"])
# Execution suspends here until the external system calls back.
result = callback.result()
return {"approved": True, "result": result}
Parallel / Map
Parallel/Mapはどちらも複数の処理を並列実行するコンポーネントです。実行する処理の種類が異なるか・同じかで使い分けます。
Parallel の使い方
Parallelは 「種類の違う複数の処理」を並列実行する場合に使います。並行実行する処理はコードで静的に定義します。以下の例では、「check_inventory」「check_payment」「check_shipping」という3種類の処理が同時に実行されます。
from aws_durable_execution_sdk_python import (
BatchResult,
DurableContext,
durable_execution,
)
def check_inventory(ctx: DurableContext) -> str:
return ctx.step(lambda _: "inventory ok", name="check-inventory")
def check_payment(ctx: DurableContext) -> str:
return ctx.step(lambda _: "payment ok", name="check-payment")
def check_shipping(ctx: DurableContext) -> str:
return ctx.step(lambda _: "shipping ok", name="check-shipping")
@durable_execution
def handler(event: dict, context: DurableContext) -> list[str]:
result: BatchResult[str] = context.parallel(
[check_inventory, check_payment, check_shipping],
name="check-services",
)
return result.to_dict()
Map の使い方
「同じ処理」を並列適用する場合に使います。処理の実行対象が動的に決まる場合に適しています。
このコード例では[1, 2, 3, 4, 5]の各数値にsquare関数を同時に実行し、それぞれの二乗(1, 4, 9, 16, 25)をまとめて返しています。
大量データを外部APIに送る際にレート制限を超えないよう、max_concurrency で同時処理数を制御することもできます。
from aws_durable_execution_sdk_python import (
BatchResult,
DurableContext,
durable_execution,
)
def square(ctx: DurableContext, item: int, index: int, items: list[int]) -> int:
return ctx.step(lambda _: item * item, name=f"square-{index}")
@durable_execution
def handler(event: dict, context: DurableContext) -> list[int]:
result: BatchResult[int] = context.map(
[1, 2, 3, 4, 5],
square,
name="square-numbers",
)
return result.to_dict()
Step Functionsとの比較・使い分け
Durable Functionsが登場したことで「Step Functions」との使い分けで悩む人が多いのではないでしょうか?
開発者のスキルセットなども考慮が必要ですが、以下のような使い分けが考えられます。1
Lambda Durable Functionsを選ぶとき:
- アプリケーション開発に慣れていて、ワークフローのロジックをコードで管理したい場合
- ユニットテストをアプリケーションのコードとして書きたい場合
- AIエージェントのチェーン呼び出しなど、LLM連携が中心の場合
Step Functionsを選ぶとき:
- DynamoDB・ECS・SQSなど複数のAWSサービスをつなぐ必要がある場合
- アプリケーション開発の経験が少ない方、非エンジニアも含めたチームで実行フローを可視化して管理したい場合
- 並列実行・エラーハンドリング・タイムアウトをDSLで宣言的に管理したい場合
| 観点 | Lambda Durable Functions | Step Functions |
|---|---|---|
| 言語 | Python / TypeScript / JavaScript / Java | Amazon States Language(JSON)またはビジュアルデザイナー |
| スコープ | Lambda関数内部のロジックとして記述 | AWSサービス横断のオーケストレーションを記述 |
| テスト | pytestやJestで通常のユニットテストが書ける | ローカルテストに制約あり |
| 向いている処理 | 分散トランザクション、AIワークフロー、人間承認フロー | 複数AWSサービスをまたぐワークフロー |
制約と注意点
最後に、Durable Functionsを使う前に知っておくべき制約をまとめます。
1. Step外の処理は重複実行される
リプレイのたびにStep外のコードは毎回実行されるので、重複実行されたくない通知送信などはStep内に書いておく必要があります。
ログ出力・メトリクス送信・外部API呼び出しはStep内に入れておき、Stepの外に書くのは副作用がない読み取り処理に限ります。
2. ステップ名を変えたり、順序を変える場合はデプロイタイミングに注意
SDKはリプレイ時に「チェックポイントログのステップ名・順序」と「実行中のコードのステップ名・順序」を照合します。
実行途中のワークフローが存在する状態でステップ名を変更・削除・並び替えしてデプロイすると、照合に失敗し、ワークフローがエラー終了します。
3. LLMのレスポンスをそのままStepの戻り値にすると256KB上限を超えるため効率が悪くなる
runInChildContext や parallel / map などの複合操作では、戻り値が256KBを超えるとチェックポイントに保存されず、replay時に処理が再実行されます。2
LLMの呼び出し結果(長文レポートや大量のJSON)をそのまま戻り値にするとこの上限を超えやすくなります。
そのため、LLMレスポンスのような大きなデータはS3などに保存し、Stepの戻り値にはそのキーのみを返すのがベストプラクティスです。
その他、ドキュメントに記載されている制約についても確認してきましょう。
- 既存関数への追加は不可: 現時点では、Durable Functionsは新規Lambda関数にのみ設定できます。既存関数の設定変更で有効化することはできません。3
- イベントソースマッピングの時間制限: Amazon SQSなどからDurable Functionsを呼び出す場合、ワークフロー全体の実行時間(Wait期間含む)が15分以内に制限されます。4
- チェックポイントのオーバーヘッド: Stepの数が増えるほどリプレイ時の再実行コストが増大します。小さすぎるステップ処理や、全体でのステップ数が多くなる場合には分割を検討します。5
まとめ
Lambda Durable Functionsによって、「ステートレスで使う」「長期処理はStep Functionsに任せる」というLambdaの設計制約が変わりました。特に、アプリケーションのコード開発のような感覚でフローを書けたり、ユニットテストができるという体験は、AWSに慣れていないエンジニアも扱いやすくなるのではないかと感じました。特にAIエージェントのような非同期ステップが多いワークフローは、Lambdaを使った実装がしやすくなったと思います。
一方で、リプレイの仕組みを理解していないと、想定していない処理の重複といったはまりどころに直面しますので、Lambda Durable Functions の特徴を理解してうまく活用していきましょう。