はじめに
結構ビビっている
*「ディープラーニングでモーガン・フリーマンとココナッツチョコレートを識別してみる」*が一昨日炎上していて、見事にQiitaからも消されていたので、めちゃめちゃビビってます。
同じ画像分析でも方向性が大分違うということや、目的と動機などをきちんと留意してもらえると助かります。
誰かにとって不利になるようなものでしたら消します。(ってか最初に言っておくとそんな精度よくないから、そういうことにはならないと思うが。)
動機と目的
AKB48の爆発的なブレイクから最近では乃木坂46,欅坂46などなどたくさんのアイドルグループが誕生しており、*「アイドル戦国時代」*とまで言われるようになりました。
一方、世の中にはアイドルグループに属していないがかなり可愛い人が結構多く存在します。
なんなら君アイドルより可愛くね?って子が結構いるかと思います。
そんなこんなんで、もうアイドル界も単純に顔が可愛いから応援されるみたいなフェーズじゃないんだろうなあとも思ったりしています。
(歌唱力とか、バライティ力とか、ファンサービスとか等々)
そこで、
「え、じゃあもうなんかそんなに顔による違いってないんじゃね??」
「それとも、自分みたいな素人にはわからなうような差が実はあるの?」
「だったら、TensorFlow先生に聞いてみるか」
と思い、実際にやってみました。
(ちなみに私は生駒里奈さん推しでした。卒業してしまったが。。)
詳しい内容は、Githubにあげますが、どの写真を作ったのかなど色々炎上のタネになりそうなところは見えないようにしていますのでご了承を。
学習フロー
画像の準備
まず、「46グループ系」「AKB48系」「一般人」の3つのグループに属す人の顔写真を集めラベル付けします。
それぞれ150枚くらい集めました。(あとで、角度を変えるなどして水増しをします。)
「46グループ系」
主にに乃木坂46と欅坂46のオフィシャルページから顔写真を持ってきました。
ただし、背景色や服装などのばらつきをもたらすためそれ以外からも持ってきます。
「AKB48系」
主にに乃木坂46と欅坂46のオフィシャルページから顔写真を持ってきました。
こちらも上と同様、背景色や服装などのばらつきをもたらすためそれ以外からも持ってきます。
ただ、46グループより過去の選抜メンバーなど活動期間が長い分色々なメンバーのデータが取りやすかったです。
「一般人」
どこのアイドルグループにも属していない日本人女性をランダムに公開されているものから持ってきました。
リサイズとか、水増しとかしてデータセット作成!
それぞれの画像は形も大きさも違うため、一旦全て統一します。
今回はサクッと学習できるよう**「75 x 75 pixel」**で統一しました。
データ量を増やすために、写真の角度を変えるなどして水増しもします。
import numpy as np
from PIL import Image
import os, glob, random
# 変数の初期化
photo_size = 75 #画像サイズ
X = []#画像データを格納するリスト
y = []#ラベルデータを格納するリスト
def glob_images2(path, label, max_photo, rotate):
files = glob.glob(path + "/*.png")#ファイルの一覧を得る
random.shuffle(files)
used_file={}
#各ファイルを処理
i = 0
for f in files:
if i >= max_photo: break
if f in used_file: continue# 同じファイルを使わない
used_file[f] = True
i += 1
#画像ファイルを読む
img = Image.open(f)
img = img.convert('RGB')#色空間をRGBに合わせる
#同一サイズにリサイズ
img = img.resize((photo_size, photo_size))
X.append(image_to_data(img))
y.append(label)
if not rotate: continue
#角度を少しずつ変えた画像を追加
for angle in range(-20, 21, 5):
#角度を変更
if angle != 0:
img_angle = img.rotate(angle)
X.append(image_to_data(img_angle))
y.append(label)
#反転
img_r = img_angle.transpose(Image.FLIP_LEFT_RIGHT)
X.append(image_to_data(img_r))
y.append(label)
def image_to_data(img):#画像データを正規化
data = np.asarray(img)
data = data / 256
data = data.reshape(photo_size, photo_size, 3)
return data
# 最大枚数max_photoのデータセットを作る
def make_dataset2(max_photo, outfile, rotate):
global X
global y
X = []
y = []
#各画像のフォルダーを読む
glob_images2("./new_AKB", 0, max_photo, rotate)
glob_images2("./new_46", 1, max_photo, rotate)
glob_images2("./new_people", 2, max_photo, rotate)
X = np.array(X, dtype=np.float32)
np.savez(outfile, X=X, y=y)
print("saved:" + outfile)
# データセットを作成する
make_dataset2(300, "photo-train.npz", rotate=True)
make_dataset2(100, "photo-test.npz", rotate=False)
学習の実行
いよいよ作ったデータセットを作って学習させていきます。
from sklearn.model_selection import train_test_split
from keras.models import Sequential
from keras.layers import Activation, Dropout, Dense
from keras.utils import np_utils
import numpy as np
# 変数の宣言
classes = 3 #いくつに分類するか
data_size = 75 * 75 * 3 #縦75 x 横75 x 3原色
# データを学習、モデルを評価
def main():
#読み込み
data = np.load("./photo-train.npz")
X = data["X"] #画像データ
y = data["y"] #ラベル
#テストデータの読み込み
data = np.load("./photo-test.npz")
X_test = data["X"]
y_test = data["y"]
#高次元行列を2次元へ
X = np.reshape(X, (-1, data_size))
#訓練とテストデータ
X_test = np.reshape(X_test, (-1, data_size))
print()
#モデル訓練して評価
model = train(X, y)
model_eval(model, X_test, y_test)
# モデルを構築しデータを学習する
def train(X, y):
model = Sequential()
model.add(Dense(units=64, input_dim=(data_size)))
model.add(Activation('relu'))
model.add(Dense(units=classes))
model.add(Activation('softmax'))
model.compile(loss='sparse_categorical_crossentropy', optimizer='sgd', metrics=['accuracy'])
model.fit(X, y, epochs=30)
model.save_weights("girl.hdf5")
return model
# モデル評価
def model_eval(model, X_test, y_test):
score = model.evaluate(X_test, y_test)
#print("loss:", score[0]*100, "%")
print("accuracy:", score[1]*100, "%")#全体正解率(予測に対してどれくらい当たってたか)
if __name__=="__main__":
main()
結果
学習させていないテスト画像を予測させた結果です。

テスト学習のaccuracyは88%でした。
トレーニングデータのaccuracyも80%くらいでした。
どうせ40%くらいの精度だろうなあと思っていたのでかなり満足です。
遊んでみる
「どうせ顔じゃなくて背景の色とか、服装みたいなところで選んでるんじゃないの?」
「そんな精度高いわけないじゃん」
と言う怖い人の声が聞こえてきます。
自分もそう思うので、ちょっとテストをやってみます。
from keras.models import Sequential
from keras.layers import Activation, Dense
from PIL import Image
import numpy as np, sys
classes = 3
photo_size = 75
data_size = photo_size * photo_size * 3
labels = ["48系統", "46系統", "普通の人"]
def build_model():
model = Sequential()
model.add(Dense(units=64, input_dim=(data_size)))
model.add(Activation('relu'))
model.add(Dense(units=classes))
model.add(Activation('softmax'))
model.compile(
loss='sparse_categorical_crossentropy',
optimizer='sgd',
metrics=['accuracy'])
model.load_weights('girl.hdf5')
return model
def check(model, fname):
img = Image.open(fname)
img = img.convert('RGB')
img = img.resize((photo_size, photo_size))
data = np.asarray(img).reshape((-1, data_size)) / 256
res =model.predict([data])[0]
y = res.argmax()
per = int(res[y] * 100)
print("{0} ({1} %)".format(labels[y], per))
if len(sys.argv) <= 1:
print("check.py ファイル名")
quit()
model = build_model()
check(model, sys.argv[1])
乃木坂46のメンバーがどう予測されるかチェック
まずは、乃木坂46のメンバーの顔写真をどう予測するかチェックしてみます。
画像は未学習のもので、背景色や服装はできるだけ学習に使ったものと違うようなものを用意します。
(ちなみに使った画像は、「与田祐希」さんです。)
結果は以下の通りです。
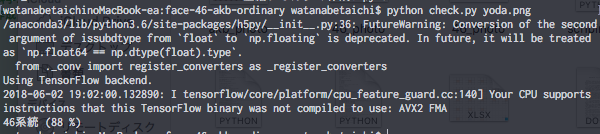
おおおお。
見事に予測されてますね。
AKB48のメンバーがどう予測されるかチェック
こちらもAKB48メンバーのうち未学習のものを用意しました。
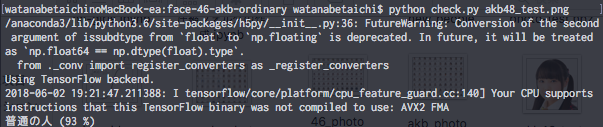
うーん。。
分類に失敗しています。
一般人がどう予測されるかチェック
こちらも、アイドルではない女の人の未学習の画像を予測させます。
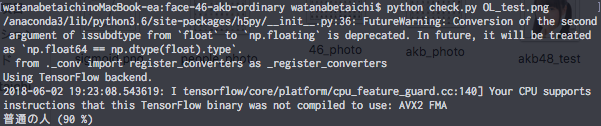
こちらはうまく予測できていますね。
違う人も誤って一般人に振り分けてしまう傾向がありそうですね。
終わりに(改善の余地)
前述した通り、一体「一般人」というくくりの中でも、どのレベルの人を学習させるかで結果が変わるので、そこらへんの定義が曖昧だったのが今回精度が低かった原因かなと思います。
(確かに、そこそこ可愛い人を使った実感あり。ただ、じゃあ一般人の平均的な顔ってどんな顔だよって感じだしなあ。。)
あとはやはり、本当に顔面だけを分析しているかは怪しいので、もっとGoogleのApiなどを使って分析できないかなあと考えております。
アイドルグループの区別だけでなく、
他にも色々なものに対して使えるモデルになっているので遊んでみようかと思います。
(今度はもうちょっと社会性のあるものを扱いたい)
Twitterでは、面白そうなエンジニア系の情報発信や活動をしているので、よければフォローしてもらえると嬉しいです。
DMくだされば個人的に、協力したり相談に乗ったりもしますのでいつでも気軽に連絡ください。
それでは!
参考
日経ソフトウエア 2017年11月号
AKB48オフィシャルサイト
乃木坂46オフィシャルサイト
欅坂46オフィシャルサイト