はじめに
普段仕事でIoT関連のシステム構築をしているのですが、ある時サーバーレス・アーキテクチャに興味を持ったのがきっかけで、サーバーレスなクラウドサービスだけを使ったIoTデータ収集基盤を構築してみました。
せっかくなので、後々収集したデータを分析することを視野に、身近に存在するIoTデバイスであるiPhoneのセンサーデータを、サーバーレスで利用できるDWHのBigQueryに収集・蓄積する仕組みを考え、GCP上に実装しました。
- 参考:サーバーレス コンピューティングで提供されるGCPサービスまとめ
https://cloud.google.com/serverless/?hl=ja
<注意事項>
- 本稿は2019年1月時点の情報に基づいており、現在の情報と異なっている可能性があります。本稿の内容は執筆者独自の見解であり、所属企業における立場、戦略、意見を代表するものではありません。
目次
- システム構成
- 環境構築手順/環境利用手順
- データ可視化サンプル
- まとめ
- 補足1:サーバーレスなIoTデータ収集基盤の意義を考えてみる
- 補足2:各種構成要素の制約事項メモ
1. システム構成
全体像
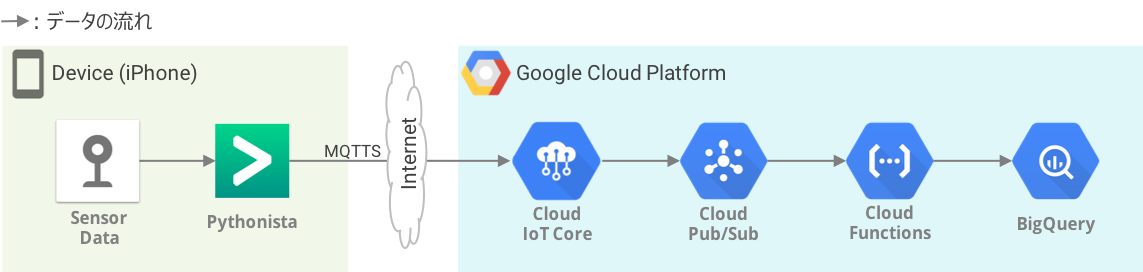
構成要素の説明
Sensor Data
iPhoneは無数のセンサーを備えており、Appleが提供するSDKを使い、iOSアプリ等からiPhoneのセンサーによって生成されるデータを取得することが可能です。
今回は、次に説明するPythonistaによってiPhoneで生成される位置情報データを取得し、それを定期的にサーバーに送信することとします。
Pythonista
-
Pythonistaは、Python開発環境を構築するための有料のiOSアプリで、インストールすることにより、iPhoneやiPad上でPythonコードの開発と実行ができるようになります。
-
Pythonistaの大きな特徴として、iOSと連携するためのPythonモジュールがプリインストールされていて、これを利用することでPythonスクリプトによって位置情報(location)や加速度情報(motion)などのセンサーデータ取得が可能である、という点があります。
- Pythonistaで利用可能なモジュール:
http://omz-software.com/pythonista/docs/ios/index.html
- Pythonistaで利用可能なモジュール:
今回は、このPythonistaを使ってiPhoneのセンサーデータ(位置情報)を取得し、MQTTSプロトコルによってGCPのゲートウェイに送信するPythonスクリプトを実行することとします。
Cloud IoT Core
GCP上のIoTゲートウェイとして利用できるサービスです。(2018年GA)
MQTTS/HTTPSの通信をサポートするとともに、認証(SSH鍵とトークンによる二段階認証)やデバイス管理を行う機能を備えています。認証された受信データをGCP上のCloud Pub/SubのトピックにPublishする機能があり、今回はこれを利用します。
-
Cloud IoT Coreはサーバーレス・プラットフォームで提供され、送受信されたデータ容量のみに基づいて課金されます。
Cloud Pub/Sub
GCP上のメッセージングキュー・サービスです。
トピックを作成し、Cloud IoT Coreのデータ保管先として設定することができます。
-
Cloud Pub/SubはCloud IoT Coreと同様、サーバーレス・プラットフォームで提供され、送受信されたデータ容量のみに基づいて課金されます。
Cloud Functions
GCP上のサーバーレス・コンピューティングを提供するサービスです。競合サービスとしては、AWSのLambdaやIBM Cloud Functionsなどが存在します。
トリガーと処理を定義することで、何らかのイベントをトリガーにして処理を実行させることができます。
今回は、Cloud Pub/SubへのPublishをトリガーに、メッセージをSubscribeし、BigQueryに保管するETL処理を定義します。
-
Cloud Functionsはサーバーレス・プラットフォームで提供されており従量課金ですが、少し計算が複雑で、下記の要素に基づいて請求額が決まります。
- 処理の実行回数
- 処理の実行時間
- 処理実行時に利用されたリソース(CPUコア、メモリ容量)
- 送受信されたデータ容量
BigQuery
GCP上のDWHのカテゴリのデータストアです。VMインスタンスなどのコンピューティングリソースの設定が不要で、基本的に従量課金という仕組みとなっています。バックエンドで分散処理が行われ、大量データに対して高速な処理ができる点で、他クラウドのDWHサービスに対して優位性があるとされています。
-
BigQueryはサーバーレス・プラットフォームで提供され、基本的には従量課金ですが、保管データのストレージ容量に対する費用も発生します。下記の要素に基づいて請求額が決まります。
- 保管データのストレージ容量(アクティブストレージと長期保管で料金が変わる)
- ストリーミング挿入されたデータ容量
- クエリで処理したバイト数
iPhoneセンサーデータをBigQueryに保管するまでの流れ
PythonistaでPythonスクリプトを実行し、iPhone上のセンサーデータを取得します。
PythonistaのPythonスクリプトから、IoTゲートウェイであるCloud IoT Coreに対して、取得したデータを認証情報(デバイスID、SSH秘密鍵、認証トークン)とともに送信します。
Cloud IoT Coreは、受信した認証情報をもとに認証後、受信したデータをメッセージとしてCloud Pub/SubにPublishします。
Cloud Pub/SubへのPublishをイベント・トリガーにして、Cloud Functions上で事前定義した関数が起動されます。(トリガーはCloud Functionsにて定義します)
Cloud Functionsの関数で定義された処理によって、Cloud Pub/Subから受け取ったメッセージを整形し、BigQuery上に保管します。
2. 環境構築手順/環境利用手順
- 下記のGitHubリポジトリに、サンプルコードを含む、Terraformを利用した環境セットアップ手順/利用手順を記載しています。
- 「はじめに」に記載の注意事項をよく読み、手順を実施するようお願いします。 https://github.com/godajaiko21/iphone-data_to_bq/blob/master/README.md#%E7%92%B0%E5%A2%83%E6%A7%8B%E7%AF%89%E6%89%8B%E9%A0%86%E7%92%B0%E5%A2%83%E5%88%A9%E7%94%A8%E6%89%8B%E9%A0%86
3. データ可視化の例
「2. 環境構築手順/環境利用手順」までが実施後の状態で、BigQuery上に格納されたiPhoneセンサーデータを地図上に表示してみたいと思います。今回は位置情報を扱っているということもあるので、2018年9月に利用開始されたBigQueryで地理空間情報を利用するためのライブラリと、BigQuery Geo Vizというウェブツールを利用してみたいと思います。
3.1. BigQuery Geo Vizへのアクセス
下記URLから、BigQuery Geo Vizにアクセスします。
https://bigquerygeoviz.appspot.com/
3.1.1. BigQueryから位置情報データを取得するクエリ文の入力
「Select data」フィールドで「Authorize」実施後、プロジェクトを指定し、下記のようなクエリ文をフォームに入力します。
SELECT ST_GeogPoint(longitude, latitude) AS p FROM
`{{PROJECT_ID}}.{{BQ_DATASET_ID}}.{{BQ_TABLE_ID}}`
{{PROJECT_ID}}、{{BQ_DATASET_ID}}、{{BQ_TABLE_ID}}には環境構築時に設定したIDを指定します。その後、「Run」を実行して「See Rusults」をクリックします。
3.1.2. クエリ結果に含まれる位置情報データ列の指定
次の「Define Columns」フィールドで「Geometry column」に「p」を選択し、「Add styles」を選択します。
3.1.3. マーカー等のスタイル選択
「Style」フィールドで見やすいようにスタイルを選択します。
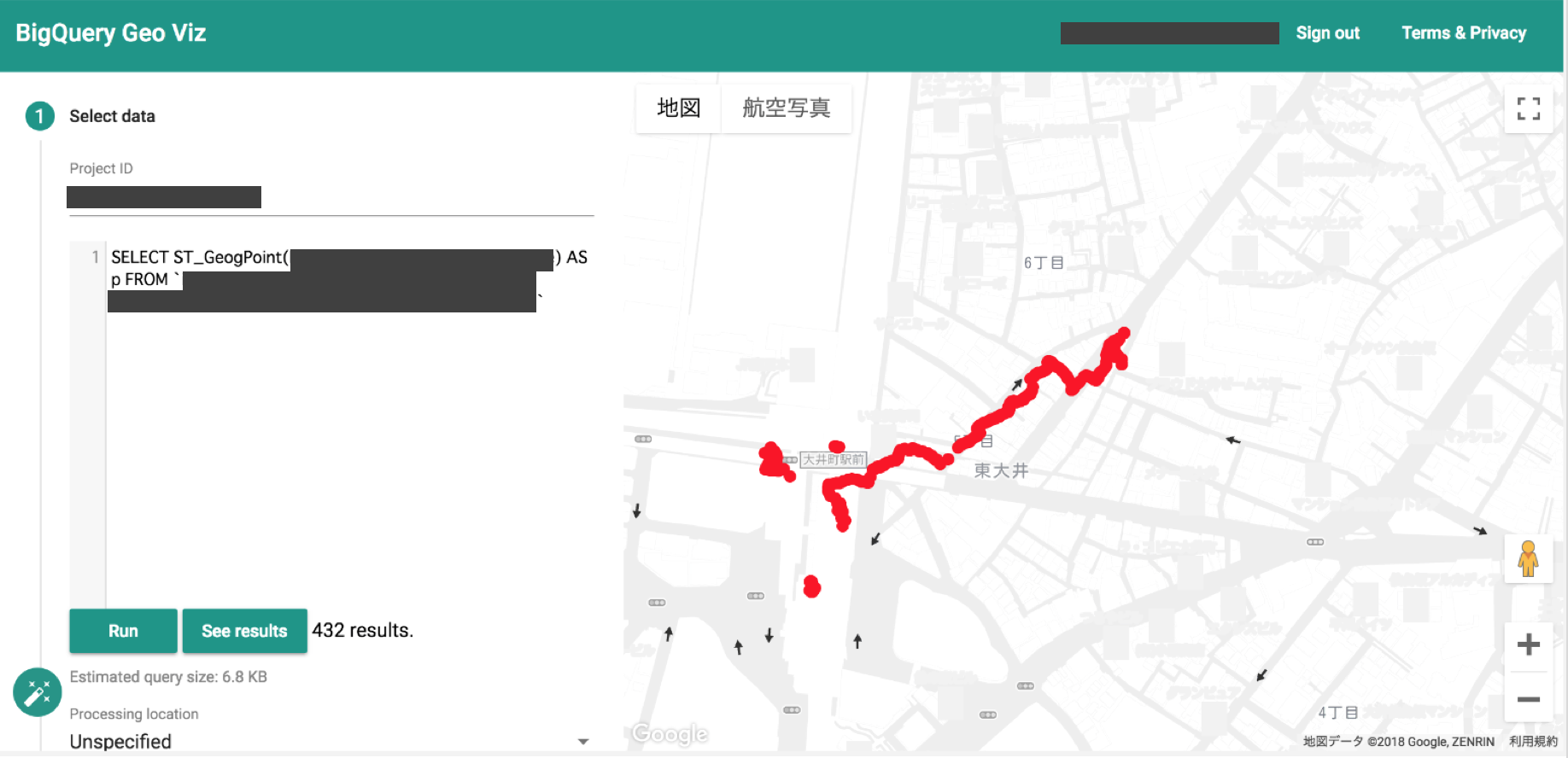
表示画面例
iPhoneから連携されたデータが赤でプロットされて表示されていることが確認できました。
4. まとめ
今回は、iPhoneのセンサーデータ(位置情報)をBigQueryに投入する環境を構築しました。
GCPのサーバーレスなサービスだけを使っての環境構築を試みましたが、やろうとしていたことは一通り実現できたかな、と思っています。
次回はデータの可視化だけでなく、分析にも手を広げていきたいと思います。
もしご参考になる部分がありましたら、ぜひ、いいねやコメントでのリアクションをいただければうれしい限ります。
なお、今回構築したサーバーレスなIoTデータ収集基盤の意義や、各種構成要素を使ってみて分かった制約事項は、下記の補足にまとめていますので、興味あれば参照ください。
補足1:サーバーレスなIoTデータ収集基盤の意義を考えてみる
今回目指したのは、サーバーレスの長所を生かしたIoTデータ収集基盤の構築です。サーバーレスのどのようなところを長所と考え、それを考慮するとどんな活用シーンがあるか、について考えた内容を記載しています。
サーバーレスの長所
サーバーレスなクラウド・サービス(サーバーレス・コンピューティングの形態で利用可能なクラウド・サービス)には以下のような長所があります。
(短所も含めたサーバーレス・コンピューティングの詳細説明は下記(参考)に記載の記事をご覧ください)
未使用時のコスト最適化:
事前に定義した処理(Function)について、処理実行時に実際に使用されたリソース量に対し従量的に課金される。したがって、処理を実行していない時間帯のコストを最小化できる。(注1)処理の拡張性:
事前に定義した処理が実行される際は、1つ1つの処理の実行単位で自動的に必要なリソースが割り当てられる。リソースの総量はクラウドベンダーが管理しユーザーは意識不要であるため、処理を並列実行させる場合の拡張性の見積もりや準備が不要である。(注2)運用の簡素化:
処理はプログラミング言語で書かれたコードによって定義されるが、そのコードの実行環境(例:JavaであればJVM)以下のレイヤーはクラウドベンダーによって運用・保守される。したがって、ユーザー側はコードの開発と運用・保守に集中することができ、運用・保守工数の削減が可能である。
注1: クラウド上にアップロードされたデータの保管費用なども発生するため、未利用時のコストがゼロになる訳ではない。
注2: クラウドベンダーごとに処理の呼び出し頻度の制限が存在する。(例えば、100秒あたり 1,000,000呼び出し、など)
(参考)サーバーレス・コンピューティングについての説明記事
https://www.nic.ad.jp/ja/materials/iw/2017/proceedings/s07/s7-nakayama.pdf
https://qiita.com/y-some/items/e9b78468428d1c481fac
サーバーレスなIoTデータ収集基盤の活用シーン
例えば、デバイスとのデータ通信がない時間帯が、不定期かつ頻繁に存在するようなケースでは、データ収集基盤をサーバーレス・アーキテクチャとすることにより恩恵が受けられると思われます。
データ収集基盤がIaaSやPaaSで構成されている場合、デバイスからのデータ通信が全くない時間帯が存在したとしても、それが不定期である場合には、万が一の接続があった場合に備えてコンピューティング・リソースを常時起動させておく必要があります。そのため、その分のコンピューティング・リソースの維持コストが発生します。未使用の時間帯が多ければ多いほどそのコストは増えていきます。
一方、サーバーレス・アーキテクチャの場合は、コンピューティング・リソースは常時起動していても、データ通信が行われたタイミングでしかコストが発生しない課金形態のため、未利用時を考慮した運用(縮退運用等)は不要です。
無料利用枠が存在するため、小規模なデータ収集基盤を作りたい場合もおすすめです。もし、PoC後に規模を拡張する必要が出たとしても、設定変更不要で使い続けられます。
補足2:各種構成要素の制約事項メモ
- Pythonista
- 任意のPythonのバージョンは利用できない
- Pythonのバックグラウンド実行もできるが、フォアグラウンドでないと有効なデータが生成されないモジュールもある(例:Motionモジュール)
- Cloud IoT Core
- まだasia-northeast1をサポートしていない(asia-east1はサポート)
- SSH鍵とJWTで生成した認証トークンによる二段階認証が必須である
- つまりデバイスから直接Cloud IoTにデータ送信する場合、デバイス上でJWTを利用できることが前提となる(難しい場合はEdgeを経由させる必要があるかもしれない)
- Cloud Pub/Sub
- QoSはAt-least-once
- Dead Letter Queueに対する処理を定義できない
- 処理されずに放置されたメッセージは最大7日間までExponential Backoff方式でメッセージが再送される
- Cloud Functions
- 言語のサポートが限られる(Nodejs、Python、GO)
- Cloud FunctionsのPub/Subトリガーを定義できるが、Pub/Subトリガーで取得したメッセージに対するAckがサポートされていない(独自にPubSubモジュールを使って処理する必要がありそう)
- 請求額の計算が複雑なため、使ってみないと分からない部分が多い
- BigQuery
- Cloud Functionsと同様、請求額の計算が複雑なため、使ってみないと分からない部分が多い