この記事では、.NETアプリケーションの難読化ツールを自作する手順を、初心者にも分かりやすく解説します。C#コードが実行ファイルになるまでの流れを概観し、なぜ難読化が中間言語(IL)に対して行われるのかを説明します。その上で、識別子の難読化や文字列の暗号化、制御フローの難読化といった技術を自作ツールで実装する方法を、詳細なC#コード例を交えて紹介します。最後に、自作難読化ツールの課題を述べ、市販の難読化ツールを使う利点について結論づけます。
1. C#コードから実行ファイルが生成される流れ
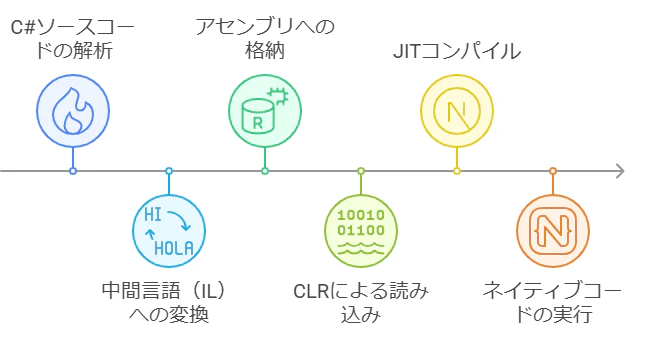
まず、C#などの高水準言語で書かれたソースコードは、コンパイラによって中間言語(CILまたはMSIL)に翻訳されます。Visual C#コンパイラなどがソースを解析し、CPU非依存の命令セットであるILを生成します 。生成されたILコードは、メタデータ(型やメンバ情報)とともにアセンブリ(.exeや.dllの実行ファイル形式)に格納されます 。IL付きのアセンブリはプラットフォームに依存せず、.NET共通の形式となっています。
アプリケーションを実行する際には、.NETのランタイムであるCLR(共通言語ランタイム)がアセンブリのILコードを読み込み、JIT(Just-In-Time)コンパイラによって必要に応じてILをネイティブの機械語に変換します 。JITコンパイルは実行時に逐次行われ、頻繁に使われるコードはネイティブに変換・最適化され、実行速度が向上します。最終的に、JITで生成されたネイティブコードがCPU上で実行され、プログラムが動作します。
2. 自作.NET難読化ツールの実装
それでは、簡単な.NET難読化ツールを自作してみましょう。ここではMono.Cecilと呼ばれるライブラリを用いて、アセンブリのILを書き換える方法を紹介します。Mono.Cecilを使うと、既存のDLLやEXEを読み込み、その中の型やメソッド、命令列を操作できます。以下では、難読化の代表的な手法である「識別子の難読化」「文字列の暗号化」「制御フローの難読化」を順に実装し、最後にコマンドライン引数で任意のDLL/EXEに適用できるコンソールツールの形にまとめます。
識別子の難読化(Obfuscation)
識別子の難読化とは、クラス名やメソッド名、フィールド名などプログラム中の名前を無意味な文字列に置換することです。逆コンパイルされた際に元の意味が推測されにくくなるため、まず手軽に思いつく防御策です。例えば、Player, CalculateScoreといった名前は動作を連想させますが、難読化によってA_1, a, bのようなランダムな名前に変えられれば可読性が大きく低下します。
Mono.Cecilで識別子を変更するには、アセンブリ内の型やメンバを走査してNameプロパティを書き換えます。以下に、全てのクラスとそのメソッドを単純な固定名にリネームするコード例を示します(実際はランダム生成や重複チェックが必要ですが、概念実証として簡略化しています)。
using Mono.Cecil;
AssemblyDefinition asm = AssemblyDefinition.ReadAssembly("入力アセンブリ.dll");
foreach (TypeDefinition type in asm.MainModule.Types)
{
if (type.Name == "<Module>") continue; // グローバルモジュールはスキップ
type.Name = "Class" + Guid.NewGuid().ToString("N"); // クラス名をGUIDに変更
foreach (MethodDefinition method in type.Methods)
{
method.Name = "Method" + method.MetadataToken.ToInt32(); // メソッド名を適当な名前に変更
}
}
asm.Write("出力アセンブリ.dll");
上記では、Mono.Cecilでアセンブリを読み込み、各型とメソッドのNameを上書きしています。例えば、メソッド名にはメタデータトークン値を使ってユニークな名称を与えています(本来は衝突を避ける工夫が必要です)。難読化後のアセンブリをリフレクター(.NET Reflector)やIL逆コンパイラで見ると、クラス名やメソッド名が軒並み意味不明なものに置き換わっているはずです。
補足: ローカル変数名については、C#のリリースビルドではメタデータ上に残らないため通常は難読化不要です(デバッグ情報を含むPDBにのみ保持されます)。主に変更対象となるのは、型名・メソッド名・フィールド名・プロパティ名などのメタデータ上の識別子です。
文字列の暗号化(String Encryption)
文字列の暗号化は、コード中にハードコーディングされた文字列リテラルを難読化する技術です。ILコード上では、文字列はldstr命令で埋め込まれており、アセンブリ内に平文で保存されています。難読化において文字列を暗号化することで、実行ファイル上から平文の重要文字列を消し去り、解析を困難にする効果があります
自作ツールでは、以下の手順で文字列リテラルの暗号化を実装できます。
- アセンブリ内の全てのIL命令を走査し、
OpCodes.Ldstr(文字列ロード命令)を探す。 - 見つけた文字列リテラル(
instruction.Operandが文字列)を、暗号化関数を使って別の文字列に変換する。 - 該当の
ldstr命令オペランドを暗号化後の文字列に置き換える。 - 実行時に元の文字列に復号するためのデコード関数をアセンブリ内に埋め込み、
ldstr命令の直後にその関数呼び出し命令を挿入する。
例えば、Mono.Cecilで文字列命令を検出してオペランドを書き換えるコードは次のようになります(暗号化アルゴリズムの詳細は省略します)。
foreach (MethodDefinition method in asm.MainModule.Types.SelectMany(t => t.Methods))
{
if (!method.HasBody) continue;
var processor = method.Body.GetILProcessor();
for (int i = 0; i < method.Body.Instructions.Count; i++)
{
Instruction ins = method.Body.Instructions[i];
if (ins.OpCode == OpCodes.Ldstr)
{
string original = (string)ins.Operand;
string encrypted = EncryptString(original); // 独自の暗号化関数で文字列をエンコード
ins.Operand = encrypted;
// 復号メソッド呼び出し命令を挿入
Instruction callDec = processor.Create(OpCodes.Call, decryptMethodRef);
processor.InsertAfter(ins, callDec);
i++; // 挿入した分インデックスを進める
}
}
}
上記では、各メソッド内の命令列を調べてOpCodes.Ldstrを見つけています。EncryptStringは例えばBase64エンコードや簡単なXOR演算などで文字列を変換する独自関数です。そして、暗号化文字列をオペランドに設定し直した後、その直後に復号用メソッド(decryptMethodRefが指すメソッド)を呼び出す命令を挿入しています。こうすることで、実行時には埋め込まれた暗号化文字列が読み込まれ、直後の復号関数呼び出しにより元の平文に戻されてからプログラムで使用されます。
復号関数(Decrypt関数)は難読化ツール側から対象アセンブリに新たに注入するか、既存の空のメソッドに実装を埋め込む形で用意します。例えば以下のようなシンプルなXORによる復号関数を追加できます。
public static string DecryptString(string enc)
{
char key = 'K';
var chars = enc.ToCharArray();
for (int i = 0; i < chars.Length; i++)
chars[i] = (char)(chars[i] ^ key);
return new string(chars);
}
暗号化時には同じ鍵'K'でXORしておき、実行時にそれを元に戻すイメージです(実用上はもう少し複雑な処理や動的キーを用いるべきです)。難読化後のアセンブリをIL逆コンパイルすると、文字列リテラルは意味のない暗号化データに置き換わっており、直接には内容を読み取れません。また、復号関数も一見無関係な計算のように見えるため、全体としてコードの理解が難しくなります。
制御フローの難読化(Control Flow Obfuscation)
制御フローの難読化は、プログラムの分岐やループ構造を意図的に複雑化し、元の論理構造を判別しにくくする手法です。通常、逆コンパイラはIL命令列からifやforなどの高水準な制御構造を推測します。そこで難読化では、意味のない条件分岐やジャンプ命令を挿入したり、基本ブロックの順序を入れ替えたりして、逆コンパイラの解析アルゴリズムを混乱させます。難読化後のコードは論理的には元と等価ですが、通常の手法では綺麗にデコンパイルできない「スパゲティコード」になっています。
自作ツールで制御フロー難読化を行うには高度なIL操作が必要ですが、簡単な例として「常に偽となるダミー条件」を挿入してみます。以下は、メソッド冒頭に無意味な条件分岐ブロックを追加するMono.Cecilコード例です。
var processor = method.Body.GetILProcessor();
var firstInstr = method.Body.Instructions[0];
var skipLabel = processor.Create(OpCodes.Nop);
// 常に真になる条件を構築 (1はtrueなので必ずbrtrue_sが実行され、ダミー部をスキップ)
processor.InsertBefore(firstInstr, processor.Create(OpCodes.Ldc_I4_1));
processor.InsertBefore(firstInstr, processor.Create(OpCodes.Brtrue_S, skipLabel));
// ダミーの命令ブロック(実行されない)
processor.InsertBefore(firstInstr, processor.Create(OpCodes.Ldstr, "dummy"));
processor.InsertBefore(firstInstr, processor.Create(OpCodes.Pop));
// ラベル挿入
processor.InsertBefore(firstInstr, skipLabel);
上記コードは、メソッドの最初にLdc_I4_1(スタックに1を載せる)とBrtrue_S skipLabel(スタックトップがtrueならskipLabelに飛ぶ)を挿入しています。常にスタックに1(真)を積むため、この分岐は必ず発生し、その下に挿入した"dummy"という文字列を読み込んで捨てる命令(意味の無いダミー命令)は一度も実行されません。結果的に、この部分は実行上は無視されますが、IL上は不可解な条件分岐として残り続けます。逆コンパイラはこの不自然なパターンに対応できず、正しく高水準な構造に変換できなくなります。))実際、Dotfuscatorで制御フロー難読化されたコードをReflectorで見ると、関数内部のコードがデコンパイル不能となり「// この項目は難読化されているため変換できません」というコメントだけが表示されます 。
制御フロー難読化の高度な実装では、複数の基本ブロックをswitch文に見立てたジャンプテーブルで繋ぎ直す「フラット化」手法や、意味のないループを入れて解析を困難にする手法などもあります。自作する場合、IL命令のジャンプ先や例外ハンドラの範囲を正しく更新する必要があり、非常に複雑です。今回は簡単な例示にとどめますが、制御フロー難読化は難読化ツールの中でも特に実装難易度が高い部分となります。
コマンドライン引数でDLL/EXEを難読化する
以上の機能を組み込んだ難読化処理を、コンソールアプリケーションとして仕上げれば、自作難読化ツールの完成です。コマンドライン引数から入力ファイル(難読化したいDLLやEXE)を受け取り、上記の識別子難読化・文字列暗号化・制御フロー難読化の処理を順次適用し、結果を別のファイルに出力するようにします。
例えば、Program.csのMainメソッドで引数を処理するコードは次のようになります。
static void Main(string[] args)
{
if (args.Length < 1)
{
Console.WriteLine("Usage: Obfuscator.exe <target.dll>");
return;
}
string inputPath = args[0];
string outputPath = Path.GetFileNameWithoutExtension(inputPath) + "_obf.dll";
var asm = AssemblyDefinition.ReadAssembly(inputPath);
RenameIdentifiers(asm); // 識別子難読化
EncryptStrings(asm); // 文字列暗号化
ObfuscateControlFlow(asm); // 制御フロー難読化
asm.Write(outputPath);
Console.WriteLine($"Obfuscated assembly saved to: {outputPath}");
}
引数が不足している場合は使い方を表示し、1つ目の引数で指定されたDLLを読み込んで難読化を実施、_obf.dllというファイル名で書き出しています。実際の処理では、先ほど示した各難読化処理(RenameIdentifiers, EncryptStrings, ObfuscateControlFlow)をそれぞれ実装済みと仮定しています。こうすることで、コマンドラインからObfuscator.exe MyApp.dllのように実行すればMyApp_obf.dllが生成される、というツールになります。
3. 自作難読化ツールの問題点
自作した難読化ツールは動作すれば達成感がありますが、実用面ではいくつかの問題点があります。
-
実装に手間と高度な知識がかかる: ILを直接解析・書き換えする処理は複雑で、バイトコードやCLRの挙動について深い理解が必要です。特殊なケース(例えばジェネリクスや非同期メソッドの状態マシンなど)に対応するにはさらに多くの時間とコードを書かなければなりません。商用レベルの難読化エンジンを個人で再現するのは容易ではありません。
-
実行時エラーのリスク: 不完全な難読化は、アプリケーションの動作に影響を及ぼす可能性があります。例えば、リフレクションで名前を指定してメソッド呼び出しをしている場合、識別子のリネームで参照が解決できなくなります。また、IL命令の整合性が崩れると実行時に
VerificationExceptionや予期せぬ例外を引き起こす恐れがあります。自作ツールではこれらの検証やテストを入念に行う必要があります。 -
パフォーマンスの低下: 制御フローをわざと複雑にしたり、文字列を都度復号化する処理を挟んだりするため、難読化後のコードは多少なりとも実行速度やメモリ効率が悪化します 。特に文字列暗号化は、実行時に復号処理を行うため起動時間の遅延につながることがあります。商用ツールではパフォーマンスへの影響を抑える工夫がありますが、自作では最適化まで手が回らないかもしれません。
-
メンテナンスが大変: .NETの仕様変更やC#言語拡張があるたびに、難読化ツール側も対応を迫られます。例えば、新しいC#構文に対応するILパターンへの追随や、UnityやXamarinのような特殊な.NETランタイム環境への対応など、継続的なアップデートが必要です。個人でメンテナンスし続けるのは負担が大きいでしょう。
4. 結論:やはり市販ツールを使うのが現実的
ここまで、自作の.NET難読化ツールの仕組みと実装方法を見てきました。学習目的で自分で難読化処理を書いてみることは、ILやCLRの理解を深める上で非常に有益です。しかし、実際のソフトウェア製品を難読化してリリースする場合、自作ツールを使うのは現実的ではないと言えます。前述したように高度な難読化を正確に実装・維持するのは難しく、得られる防御効果とのバランスも疑問が残ります。
商用の難読化ツールを利用するのが実務では一般的であり、安全です。これらのツールはVisual Studioと統合され簡単に設定できるものも多く、豊富なオプションで必要十分な難読化を自動で行ってくれます。何より実績がある分、安定性や信頼性が高く、最新のC#機能やプラットフォームにも随時対応がアップデートされています。学習のために自作すること自体は意義がありますが、得られた知見は市販ツールの適切な活用に役立て、「餅は餅屋」に任せるのが最終的には得策でしょう。