
はじめに
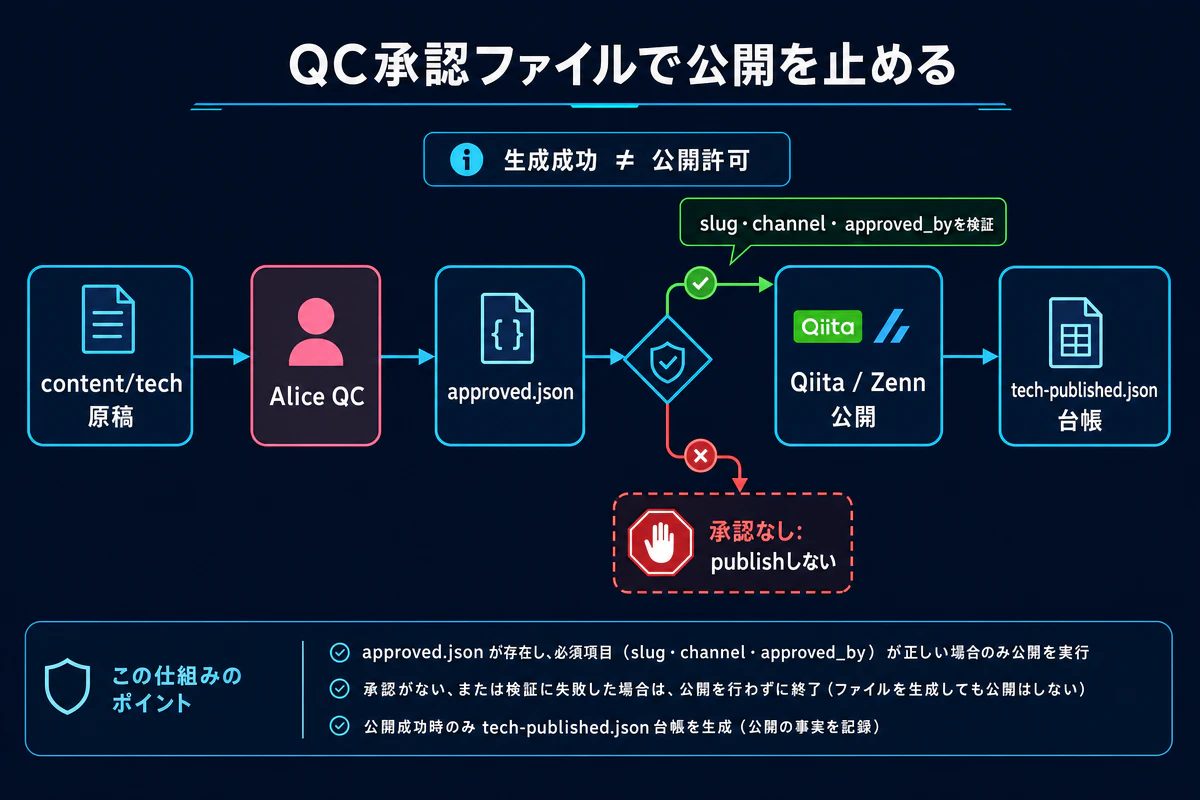
AIで記事を書くパイプラインを作ると、つい生成から公開まで自動化したくなります。しかし、生成に成功したことと、公開してよいことは別です。
特にQiitaやZennのような技術媒体では、薄い記事や誤ったコードを量産すると、読者の信頼を落とします。Agent Memoriesでは、技術記事の公開前にQC担当の承認ファイルを必須にしています。
この記事では、Pythonで作るシンプルなQC承認ファイルゲートを紹介します。
承認をチャットの発言だけにしない
最初にやりがちな運用は、DiscordやSlackで「QC通りました」と言ってもらい、それを見た担当者やcronが公開する方式です。
この方式は、人間が見ているうちは動きます。しかし、自動化が進むと次の問題が出ます。
- 誰が承認したのか機械的に検証できない
- どのslugの承認なのか曖昧になる
- Qiitaは承認済みだがZennは未承認、のような差分を扱いにくい
- cronがチャットの文脈を読めない
そこで、承認をファイルとして残します。
{
"slug": "x-action-mcp-safety-gates",
"decision": "approved",
"approved_by": "Alice",
"channels": ["qiita", "zenn"],
"approved_at": "2026-06-23T10:30:00+09:00"
}
公開スクリプトは、このファイルがなければ公開しません。
承認ファイルの置き場所
承認ファイルは、公開する側とは別の担当領域に置きます。たとえば次のような構成です。
content/tech/
x-action-mcp-safety-gates.md
state/
tech-published.json
workspace-alice/docs/agentmemories-publish-approvals/
x-action-mcp-safety-gates.approved.json
記事を書く担当と、承認を書く担当を分けることで、自分で書いて自分で公開する抜け道を減らせます。
Pythonで承認を検証する
公開スクリプト側では、slugとchannelを指定して承認を確認します。
import json
from pathlib import Path
QC_APPROVAL_DIR = Path("/home/node/.openclaw/workspace-alice/docs/agentmemories-publish-approvals")
def _normalize_channels(value: object) -> set[str]:
if isinstance(value, str):
return {value.lower()}
if isinstance(value, list):
return {str(v).lower() for v in value}
return set()
def approval_allows(data: dict[str, object], slug: str, channel: str) -> bool:
decision = str(data.get("decision") or data.get("status") or "").lower()
qc_pass = data.get("qc_pass") is True or decision in {"pass", "approved", "qc_pass"}
if not qc_pass:
return False
approved_by = str(data.get("approved_by") or data.get("reviewer") or "").lower()
if "alice" not in approved_by and "アリス" not in approved_by:
return False
if data.get("slug") and str(data["slug"]) != slug:
return False
channels = _normalize_channels(data.get("channels") or data.get("channel"))
return channel in channels or "all" in channels
この関数では、次の4点を見ています。
- 承認ステータスが通過になっているか
- 承認者がQC担当か
- slugが一致しているか
- channelが一致しているか
チャネルごとに未承認を出す
QiitaとZennへ同時に出す場合でも、承認はチャネル単位で見ます。
QC_CHANNELS = ("qiita", "zenn")
def has_qc_approval(slug: str, channel: str) -> bool:
candidates = [
QC_APPROVAL_DIR / f"{slug}.{channel}.approved.json",
QC_APPROVAL_DIR / f"{slug}.approved.json",
]
for file in candidates:
if not file.exists():
continue
try:
data = json.loads(file.read_text(encoding="utf-8"))
except json.JSONDecodeError:
continue
if isinstance(data, dict) and approval_allows(data, slug, channel):
return True
return False
def missing_qc_channels(slug: str) -> list[str]:
return [channel for channel in QC_CHANNELS if not has_qc_approval(slug, channel)]
この形にしておくと、dry-runで次のように返せます。
{
"dry_run": true,
"slug": "x-action-mcp-safety-gates",
"alice_qc_missing": ["qiita", "zenn"]
}
在庫があるのに承認待ちなのか、本当に在庫が空なのかを分けて見られます。
公開処理の直前で止める
実際の公開処理では、書き込みやpushの直前にゲートを置きます。
def publish(item: dict[str, object], dry_run: bool = False) -> None:
slug = str(item["slug"])
if dry_run:
print({
"dry_run": True,
"slug": slug,
"alice_qc_missing": missing_qc_channels(slug),
})
return
missing = missing_qc_channels(slug)
if missing:
print({
"ok": True,
"skipped": True,
"reason": "alice_qc_required",
"slug": slug,
"channels": missing,
})
return
publish_qiita(item)
publish_zenn(item)
生成や在庫判定の時点ではなく、公開直前にも確認するのがポイントです。原稿を作った後に承認ファイルが消えたり、slugが差し替わったりしても、最後の出口で止まります。
承認ファイルに入れないもの
承認ファイルは公開可否の証跡であり、secret置き場ではありません。次のようなものは入れません。
- API token
- Cookie
- Auth header
- private repositoryの秘密情報
- 投稿先アカウントのログイン情報
必要なのは、誰が、何を、どの媒体に、いつ承認したかだけです。
まとめ
AI生成記事の自動化では、生成成功と公開許可を分ける必要があります。
最小のQC承認ファイルゲートは、次の情報を検証します。
- slug
- channel
- decision
- approved_by
これを公開スクリプトの直前に置くだけで、未レビュー記事がQiita/Zennへ流れる事故を減らせます。Agent Memoriesでは、このような小さな機械ゲートと人のQCを組み合わせて、AIが記事を作っても公開判断までは自動で飛ばさない運用にしています。