Googleが2018年10月に発表し、大いに話題となった自然言語処理モデルBERT。このBERTのモデルから単語ベクトルが抽出できるようなので、色々と調べてみようと思います。
BERTの単語ベクトルの特徴
単語ベクトルといえばWord2Vecですが、Word2Vecの単語ベクトルは、異なる意味の単語でも字面が同じならば全て同じ値になってしまうという欠点があります。
例えば下のような文があった場合、この文の最初の「HP(ヒューレット・パッカード)」と2つ目の「HP(ホームページ)」は別の意味を持つ単語ですが、ベクトルとしては同じになります。
HP社は、2019年11月18日に新製品をHPで発表した。
ところが、BERTの場合は、2つの「HP」のベクトルは異なる値になります。それだけではなく、下の例のような同じ意味の3つの「HP」も、すべて異なるベクトルになります。
HP社は、HP社と、HP社の競合会社であるXX社とが、業務提携すると発表した。
すなわち、BERTの場合には、全ての単語が出現ごとに文脈に依存して異なるベクトル表現を持ち、同じベクトルの値を持つ単語は一つもありません。
調べたいこと
BERTの単語ベクトルは全て異なる値を持ちますが、さすがに字面が同じで意味も同じ単語の場合は、似た(距離の近い)ベクトルになっているんじゃないかと思います。さらには、「HP」と「ヒューレット・パッカード」のように、字面は違っても意味の同じ単語どうしも、似たベクトルになっている気がします。
「思う」「気がする」のは勝手な期待なので、今回は「本当にそうなのか?」を調べてみたいと思います。
本題
環境
- MacOS 10.15.1
- Python 3.6.5
- Tensorflow 1.14.0
- その他必要なものをpipでインストール
単語ベクトルの抽出
BERTの学習済モデルの準備
Googleが公開しているTensorflow版BERTのコードを使えば、BERTの学習、単語ベクトルの抽出ができますが、BERTの学習には非常に時間がかかってしまうため、今回はyoheikikutaさんが公開しているBERTの学習済モデルを使って実験を行います。このモデルは、日本語版Wikipediaを学習データとしており、トークナイズにはSentencePieceを使っています。
BERTの学習済モデルを適当なディレクトリ(以降、このディレクトリを<BERT_DIR>と記述します)に保存し、その中に下記の学習済モデル用のBERTの設定ファイルも保存します。
{
"attention_probs_dropout_prob": 0.1,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"max_position_embeddings": 512,
"num_attention_heads": 12,
"num_hidden_layers": 12,
"type_vocab_size": 2,
"vocab_size": 32000
}
データの準備
Wikipediaから、「GAFA」、「Google」、「Amazon.com」、「Facebook」、「アップル (企業)」、「アマゾン熱帯雨林」の先頭パラグラフを取得して、1行1センテンスとなるファイルsentence_gafa.txtを作成し、適当なディレクトリ(以降、このディレクトリを<INPUT_DIR>と記述します)に保存します(下記のテキスト先頭の[1]、[2]、…は、今回の記事用に追記した行番号で、実際のデータには含まれていません)。
[1]GAFA(ガーファ)またはGAFAMなどと往時には呼ばれ、最近はむしろビッグテックまたはビッグテク(Big Tech)と呼ばれているのは、米国の多国籍企業でコンピューターやソフトウェアを駆使してサイバースペースを2010年代に支配するに至った企業のことで、具体的にはグーグル・アマゾン・フェイスブック・アップル(およびマイクロソフト)の4/5つの主要IT企業である。
[2]最近、ヨーロッパから始まって、米国でも、独占禁止法を適用する声が上がり始めている。
[3]Google LLC(グーグル)は、インターネット関連のサービスと製品に特化した世界規模のアメリカの多国籍テクノロジー企業である。
[4]検索エンジン、オンライン広告、クラウドコンピューティング、ソフトウェア、ハードウェア関連の事業がある。
[5]アメリカ合衆国の主要なIT企業で、GAFA、FAANGの一つ。
[6]Amazon.com, Inc.(アマゾン・ドット・コム)は、アメリカ合衆国・ワシントン州シアトルに本拠を構えるECサイト、Webサービス会社である。
[7]アレクサ・インターネット、A9.com、Internet Movie Database(IMDb)などを保有している。
[8]アメリカ合衆国の主要なIT企業で、GAFA、またFAANGのひとつである。
[9]2019年現在、Amazon.comがアメリカ国外でサイトを運営している国はイギリス、フランス、ドイツ、カナダ、日本、中国、イタリア、スペイン、ブラジル、インド、メキシコ、オーストラリア、オランダ、トルコ、アラブ首長国連邦の15か国である。
[10]Facebook(フェイスブック、FB)は、アメリカ合衆国カリフォルニア州メンローパークに本社を置くFacebook, Inc.が運営する世界最大のソーシャル・ネットワーキング・サービス(SNS)である。
[11]Facebook, Inc.はアメリカ合衆国の主要なIT企業であり、GAFA、FAANGの一つで、FacebookのほかInstagramやMessenger、WhatsAppを提供している。
[12]Facebookという名前は、アメリカ合衆国の一部の大学が学生間の交流を促すために入学した年に提供している本の通称である「Face book(英語版)」に由来している。
[13]アップル(英: Apple Inc.)は、アメリカ合衆国カリフォルニア州に本社を置く、インターネット関連製品、デジタル家庭電化製品および同製品に関連するソフトウェア製品を開発、販売する多国籍企業である。
[14]2007年1月9日に、アップルコンピュータ(Apple Computer, Inc.)から改称した。アメリカ合衆国の主要なIT企業である。
[15]マイクロソフト(英: Microsoft Corporation)は、アメリカ合衆国ワシントン州に本社を置く、ソフトウェアを開発、販売する会社である。
[16]1975年にビル・ゲイツとポール・アレンによって創業された。
[17]アマゾン熱帯雨林(アマゾンねったいうりん、英: Amazon Rainforest、西: Selva Amazónica、葡: Floresta Amazônica)とは、南アメリカ大陸アマゾン川流域に大きく広がる、世界最大面積を誇る熱帯雨林である。
[18]2019年の大火事で10%の面積を焼失したとされる。
[19]森林破壊が原因と見られる、木が大量に枯死する等の現象が多発しており、焼き畑と合わせて二酸化炭素大量放出の原因になっており問題になっている。
引用元:「GAFA」「Google」「Amazon.com」「Facebook」「アップル (企業)」「アマゾン熱帯雨林」『フリー百科事典 ウィキペディア日本語版』。2019年11月18日 (日) 6:00 UTC、URL: https://ja.wikipedia.org
ベクトル抽出プログラムの準備
Googleが公開しているTensorflow版BERTのextract_features.pyを使えば、BERTのモデルからベクトルが抽出できますが、このプログラムはトークナイザーにWordPieceを使っているため、そのままでは今回使用するモデルに対しては使えません(今回使用する学習済モデルはSentencePieceでトークナイズされているため)。
学習済モデルを公開しているyoheikikutaさんが、extract_features.pyをSentencePieceで使えるように修正したものを公開しているので、こちらを使うことにします(src/extract_features.py)。
ベクトル抽出の実行
以下のコマンドを実行して、単語ベクトルを抽出します(<OUTPUT_DIR>は出力先のディレクトリ)。
python extract_features.py --input_file=<INPUT_DIR>/sentences_gafa.txt --model_file=<BERT_DIR>/wiki-ja.model --vocab_file=<BERT_DIR>/wiki-ja.vocab --bert_config_file=<BERT_DIR>/bert_config.json --init_checkpoint=<BERT_DIR>/model.ckpt-1400000 --output_file=<OUTPUT_DIR>/features_gafa.txt --do_lower_case=false --layers=0,1,2,3,4,5,6,7,8,9,10,11
出力されたファイルは以下のようなJSONっぽい形式になっています。
{
"linex_index": 0, // 入力ファイルの行番号(センテンスの番号)
"features": [
{
"token": "[CLS]", // センテンスを構成するトークン([CLS]はBERTでの行頭を表す特別なトークン)
"layers": [
{"index": 0, "values": [0.48546, ...]}, // 中間層0の出力
{"index": 1, "values": [0.587065, ...]}, // 中間層1の出力
...
{"index": 11, "values": [0.48324, ...]} // 中間層11の出力
]
},
{
"token": "▁",
...
},
{
"token": "GAFA",
...
},
...
]
}
{
"linex_index": 1,
...
}
...
{
"linex_index": 20,
}
今回使ったBERTのモデルは、12個の中間層、各中間層は768個のニューロンで構成されています。
上記出力の「layers」の各要素が中間層に該当し、「layers.values」が各中間層の768個のニューロンの出力に該当します。
各トークンに対して、768次元のベクトルが12個あり、これらがそのトークンのベクトル表現とみなすことができます。
これら12個のベクトルのうち、
- 12個のベクトルを連結した768×12次元のベクトル
- 12個のベクトルの平均
- 出力層に最も近い11番目のベクトル
など、そのトークンを表すベクトルを作る方法は色々ありますが、この記事によると、BiLSTMによる固有表現抽出タスクでは、出力に近い4つの層のベクトルを連結したベクトルを入力として使ったときに最も成績が良かったそうです。
連結をしてしまうと計算量が増えるため、今回は出力に近い4つの層のベクトルの平均をそのトークンのベクトルとすることにします。
ちなみに、入力データの1番目のセンテンスをSentencePieceでトークナイズをすると、以下のようになります(「|」がトークンの区切り)。
[CLS]|▁|GAFA|(|ガー|ファ|)|または|GAFAM|などと|往|時には|呼ばれ|、|最近|は|むしろ|ビッグ|テック|または|ビッグ|テ|ク|(|B|ig|▁|T|e|ch|)|と呼ばれている|の|は|、|米国の|多|国籍|企業|で|コンピューター|や|ソフトウェア|を駆使して|サイバー|スペース|を|2010|年代に|支配|する|に至った|企業の|ことで|、|具体的に|は|グー|グル|・|アマゾン|・|フェイス|ブック|・|アップル|(|および|マイクロソフト|)|の|4|/|5|つの|主要|IT|企業である|。|[SEP]
これをみて分かるように、トークン≠単語です。例えば「グーグル」という単語は、「グー」、「グル」という2個のトークンで構成されています。
BERTのモデルから取得できるのは単語のベクトルではなくトークンのベクトルです。今回は、複数のトークンで構成されている単語に対しては、この単語を構成する全てのトークンのベクトルを平均したものをその単語のベクトルとします(正しい方法かどうかはわかりませんが)。
例えば、「グー」のトークンベクトルが[1.0, 2.0, 3.0]、「グル」のトークンベクトルが[4.0, 5.0, 6.0]だった場合、「グーグル」の単語ベクトルは[(1.0+4.0)/2, (2.0+5.0)/2, (3.0+6.0)/2] = [2.5, 3.5, 4.5]となります。
ベクトルの可視化
ベクトルの数字の並びを眺めていてもなんだかよくわからないので、可視化をしてみました。
なぜか、どのベクトルも603次元目の値が他に比べて極めて小さいマイナスの値になっていて、可視化をしたときに特徴がつかみづらくなるため、0で補正をしました。
全ての次元を可視化
入力データの1行目の「グーグル」(グーグル[1])、3行目の「グーグル」(グーグル[3])、「Google」(Google[3])のベクトルを取得し、グレースケールのマトリクス(ベクトルは768次元なので、24×32)で可視化しました([]内の数字は入力データの行番号です)。
目を細めてみると、「グーグル[1]」と「グーグル[3]」は似ているような気がしますが、多分気のせいです。当然、それらしい特徴はつかめません。
しかし、ここでは同じ「グーグル」という単語でも、異なったベクトル表現になっているということが重要です。
2次元で可視化
ベクトルの全ての次元を眺めてみてもよくわからないので、768次元のベクトルを、主成分分析で2次元に次元削減してみました([]内の数字は入力データの行番号です)。
まずは、「GAFA」、「ガーファ」、「Google」、「グーグル」、「Amazon」、「アマゾン」、「Facebook」、「フェイスブック」、「Apple」、「アップル」のベクトルがどのように配置されているかを調べました。
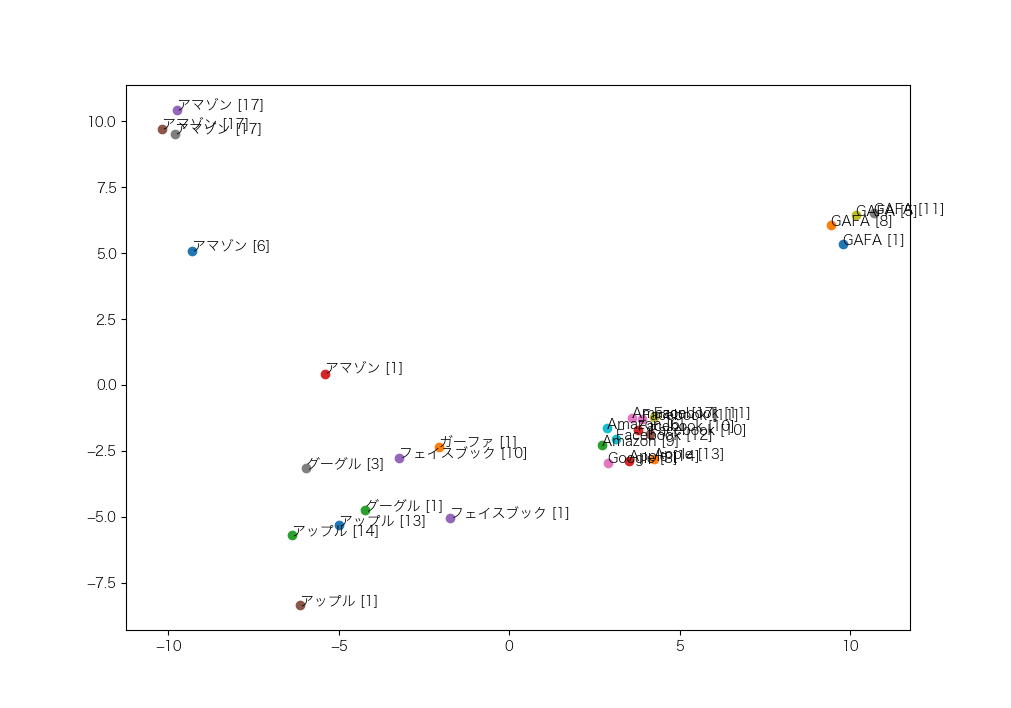
次のような特徴が読み取れます。
- 地名の「アマゾン」(アマゾン[17])は、企業名の「アマゾン」(アマゾン[1]、アマゾン[6])とは区別されている
- アルファベットの単語に注目すると、企業名の「Google」、「Amazon」、「Facebook」、「Apple」は企業名ではない「GAFA」とは区別されている
次に、ごちゃっとしている「GAFA」以外のアルファベットだけで次元削減を行い、ベクトルの配置を調べました。
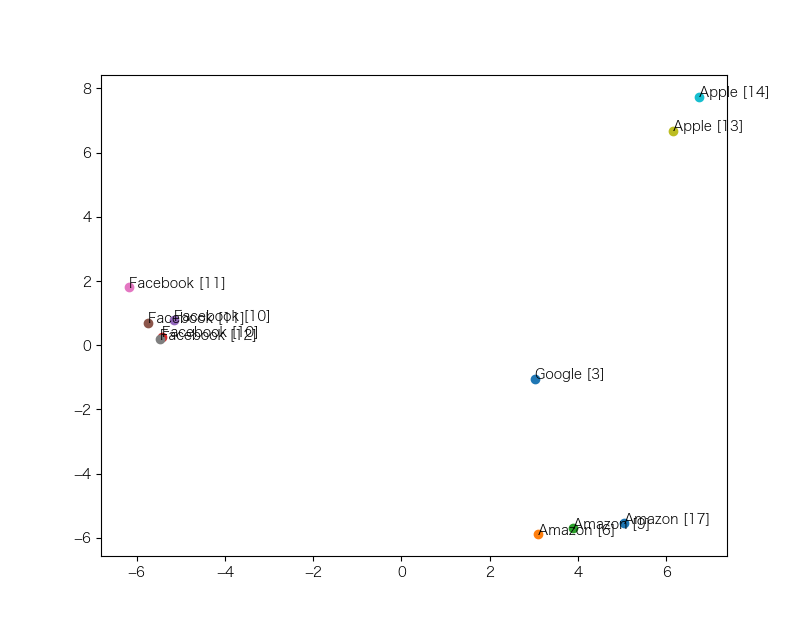
おっ、いい感じに分かれているじゃないですか。と思いきや、右下のAmazonゾーンに、地名の「Amazon」(Amazon[17])が入り込んでしまっています。
では、「Amazon」、「アマゾン」だけで次元削減をしたらどうなるか?企業名のグループ、地名のグループに分かれてくれたらうれしいですね。
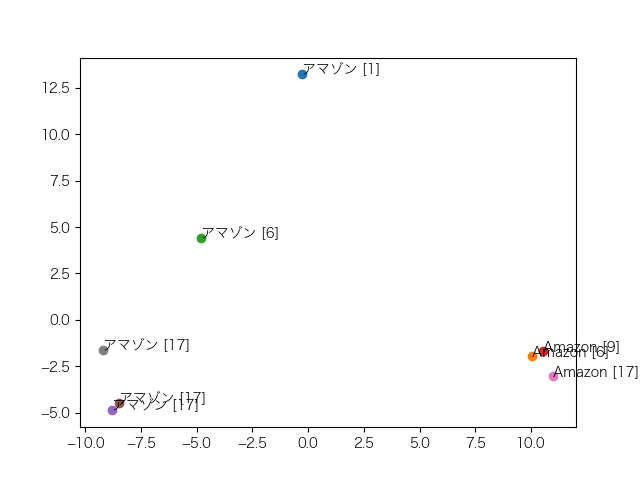
ダメです。新たな特徴も見つかりませんでした。
もう少し詳しく色々とみてみたいところですが、今回はここまでとさせていただきます。
まとめ
今回の実験はデータ数が少なく、定性的な結果でしかないですが、BERTのベクトルそのものでは、単語の意味を区別することは難しそうな感じがします。
BERTのベクトルには、おそらく単語の字面、前後の単語、品詞、意味、・・・など様々な要素が含まれているため、意味的な特徴を得たい場合には、ベクトルの中から意味を表現している成分を抽出する必要があるのかもしれません。
今後は、こういったことを深掘りしていきたいと考えています。