はじめに
前回の記事で、BERTで抽出した単語ベクトルを使って同義語、同音異義語の判別ができるかどうかということを試してみました。
具体的には、下記のテキスト123をBERTに入力し、企業名のアマゾン(Amazon)と地名のアマゾン(Amazon)の単語ベクトル(768次元)を抽出しました。可視化するために2次元に次元削減し、その分布を調べました。
[1]GAFA(ガーファ)またはGAFAMなどと往時には呼ばれ、最近はむしろビッグテックまたはビッグテク(Big Tech)と呼ばれているのは、米国の多国籍企業でコンピューターやソフトウェアを駆使してサイバースペースを2010年代に支配するに至った企業のことで、具体的にはグーグル・アマゾン・フェイスブック・アップル(およびマイクロソフト)の4/5つの主要IT企業である。
・・・
[6]Amazon.com, Inc.(アマゾン・ドット・コム)は、アメリカ合衆国・ワシントン州シアトルに本拠を構えるECサイト、Webサービス会社である。
・・・
[9]2019年現在、Amazon.comがアメリカ国外でサイトを運営している国はイギリス、フランス、ドイツ、カナダ、日本、中国、イタリア、スペイン、ブラジル、インド、メキシコ、オーストラリア、オランダ、トルコ、アラブ首長国連邦の15か国である。
・・・
[17]アマゾン熱帯雨林(アマゾンねったいうりん、英: Amazon Rainforest、西: Selva Amazónica、葡: Floresta Amazônica)とは、南アメリカ大陸アマゾン川流域に大きく広がる、世界最大面積を誇る熱帯雨林である。
・・・
下の図がその結果です(単語の後の番号は、その単語が含まれる文の行番号です。同一文内に複数回出現する単語の場合は、17-1、17-2、…のように出現順序も付与しています)。

企業名のアマゾン(アマゾン[1]、アマゾン[6]、Amazon[6]、Amazon[9])と地名のアマゾン(アマゾン[17-1]、アマゾン[17-2]、アマゾン[17-3]、Amazon[17])の2つのグループに分かれることを期待していましたが、期待外れな結果でした。
この原因は、BERTの単語ベクトルには、意味だけではなく、単語の字面、前後の単語、品詞、・・・など様々な要素が含まれていることにあるのだろうと前回は考察しました。
おそらくそうなんだろうけど、少し気になることがあるので、今回はもう少し探ってみたいと思います。
各層の単語ベクトル
前回の記事で使用したのは、12個の中間層を持つBERTのモデルでした。各階層がそれぞれ単語ベクトルを持っていますが、この記事を参考にして、出力に近い4つの層のベクトルの平均で単語ベクトルを作りました。
本当にこれでよかったのか?もっと良いベクトルの作り方があったかも?
そこで、今回は各層の単語ベクトルの分布を調べてみることにしました(単語ベクトルの抽出方法は、前回の記事をご覧下さい)。もしかしたら、どこかの層で単語の意味が表現されているかもしれません。
下の12個の図がその結果です。上から1層目、2層目、…、12層目となっています。
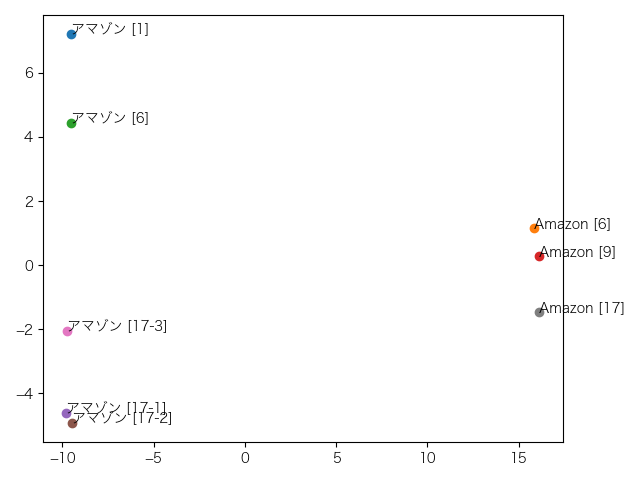
これは1層目。縦軸の-1を境に企業名と地名が分かれていますが、アマゾンとAmazonとがもっとまとまって欲しいところです。
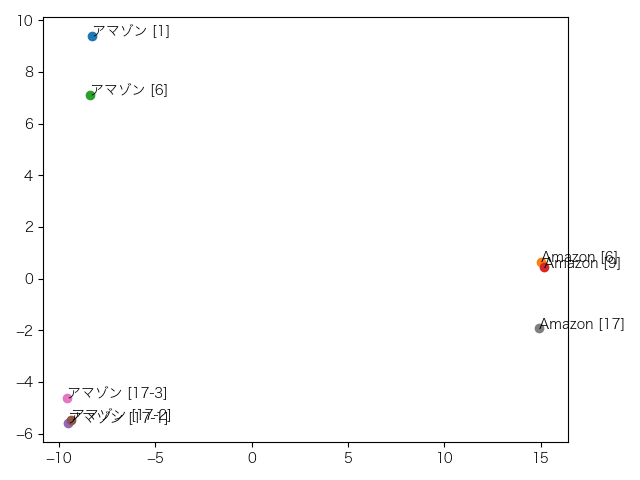
これは2層目。1層目と似たような傾向ですが、地名のアマゾン、企業名のAmazonそれぞれがきれいにクラスターになってます。
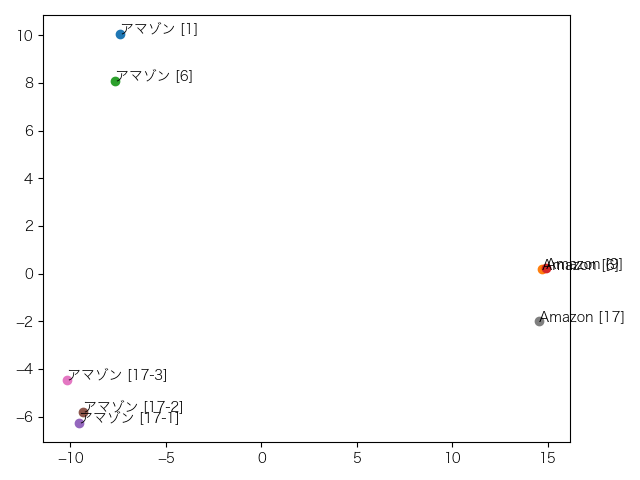
これは3層目。特に変化はありません。
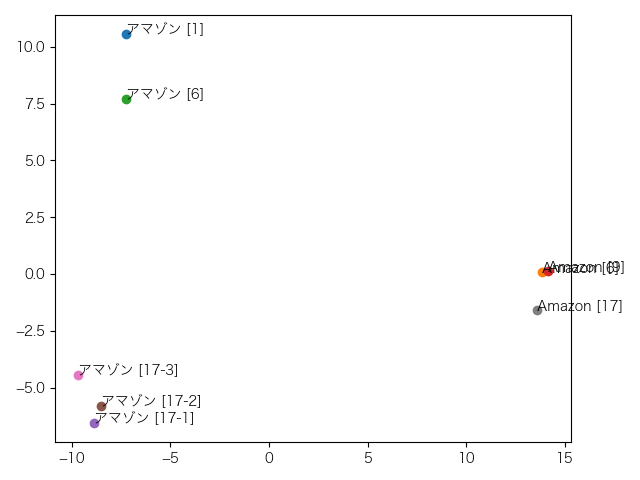
これは4層目。特に変化はありません。
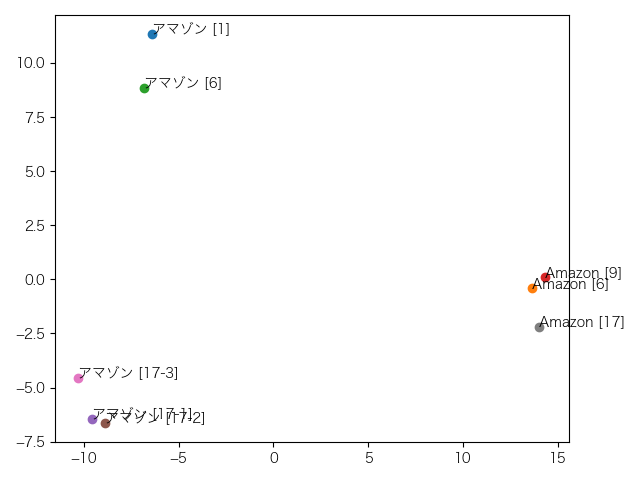
これは5層目。特に変化はありません。
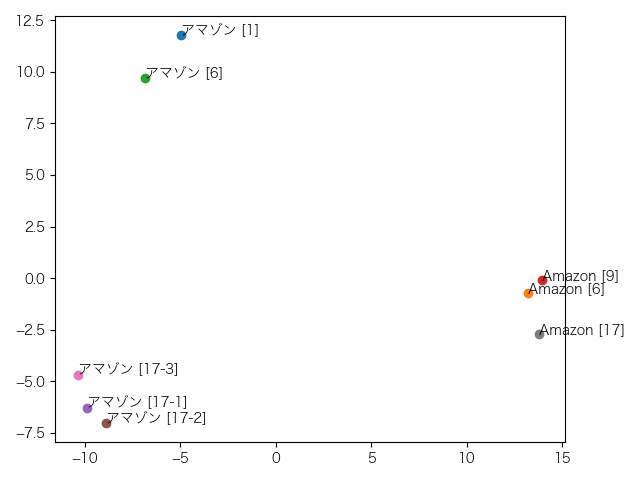
これは6層目。特に変化はありません。
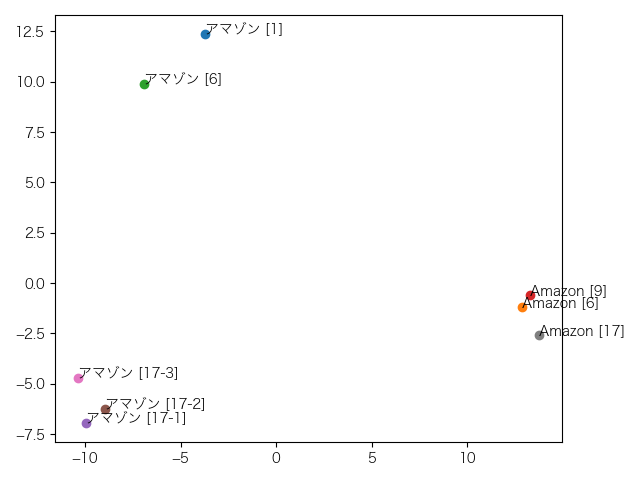
これは7層目。特に変化はありません。
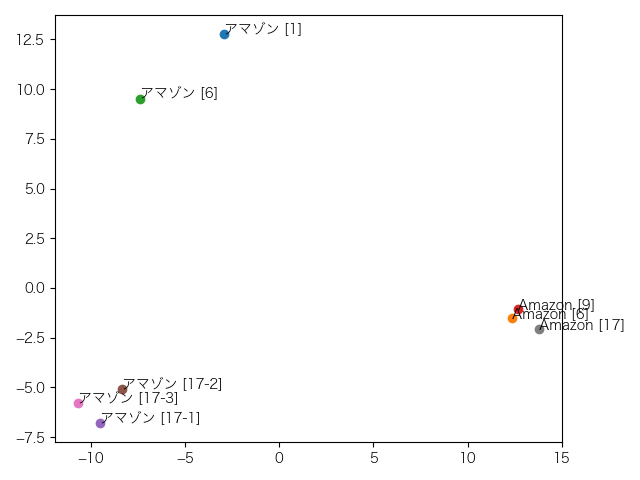
これは8層目。Amazonに企業名、地名の区別が見えなくなりました。
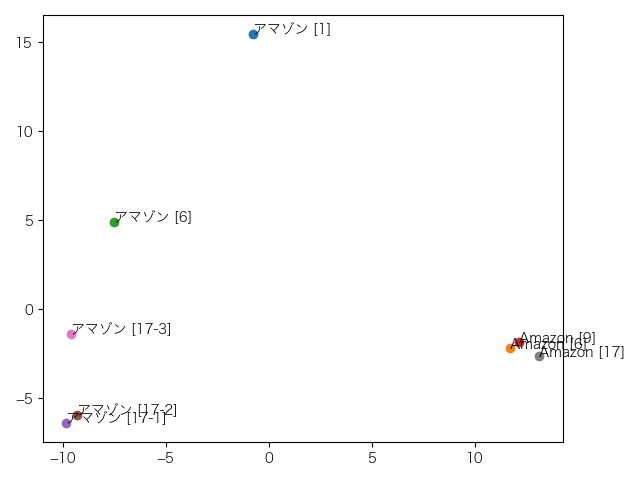
これは9層目。アマゾン[6]がアマゾン[17-3]を誘い出しに来ました。
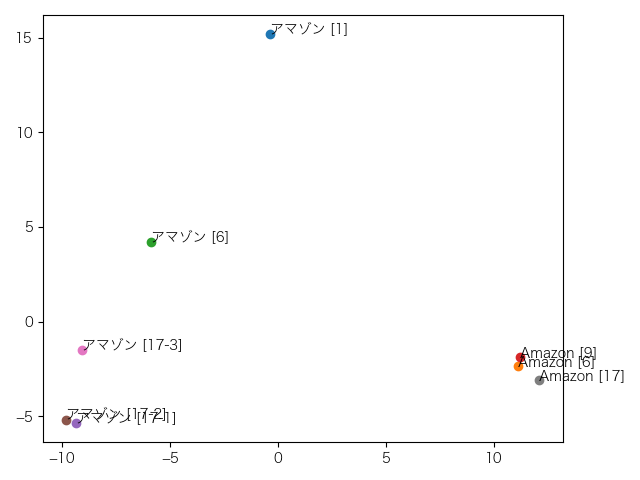
これは10層目。
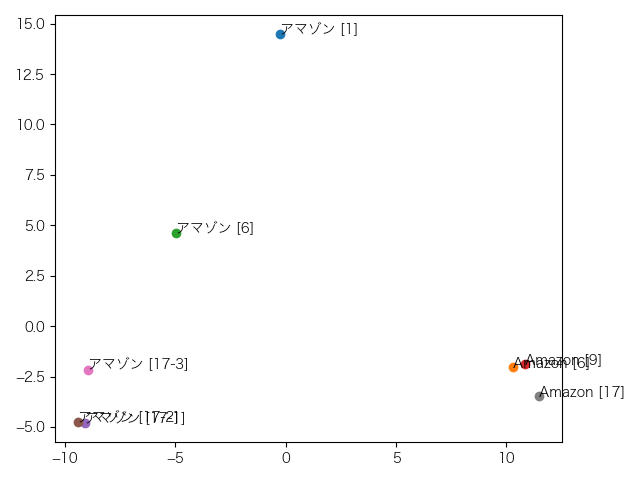
これは11層目。
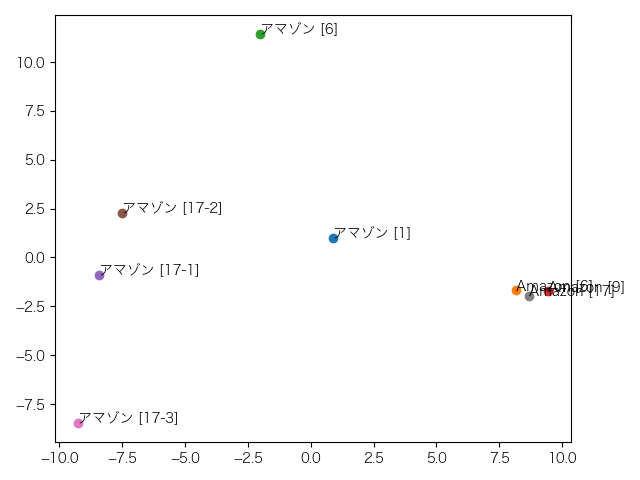
これは12層目。もう何だかわかりません(笑)。
類似度の計算
ここまでは、単語ベクトルの分布を可視化するために、768次元の単語ベクトルを2次元に次元削減しましたが、だいぶ情報が失われてしまっているのでは?という疑問があります。
そこで、768次元の単語ベクトルのままで、各単語のベクトル間の類似度を計算してみます。類似度の計算方法はいろいろありますが、今回は、コサイン類似度、ユークリッド距離を使用します。
下に結果を示します。数字をそのまま眺めても特徴がわかりづらいので、グレースケールのマトリックスで表示します。類似度が高いほど黒に近く、低いほど白に近くなるように表現してあります。

これは1層目。字面の同じペアでの類似度が高くなっています。ちなみに完全に意味で別れた場合には下の図の様になりますが、これとは程遠い結果です。


これは2層目。

これは3層目。

これは4層目。

これは5層目。

これは6層目。

これは7層目。

これは8層目。
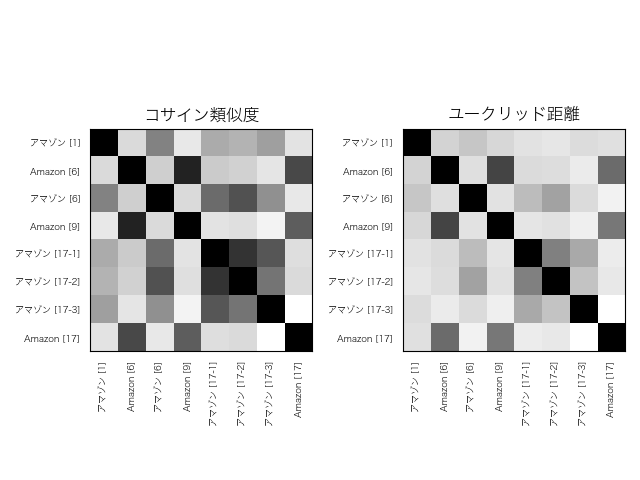
これは9層目。

これは10層目。
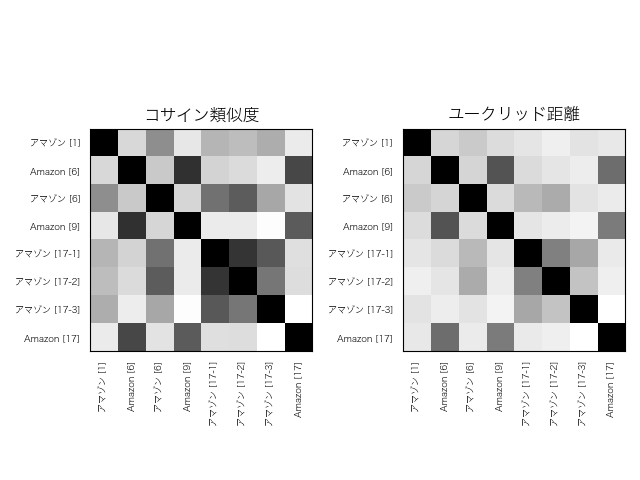
これは11層目。
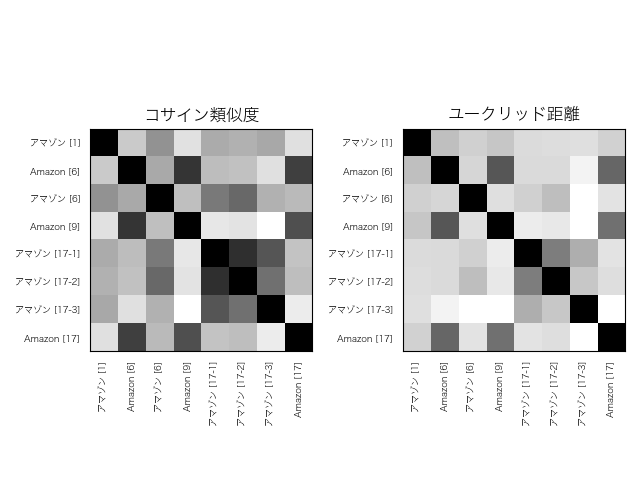
これは12層目。
結果を見ると、出力に近い層になるほど、字面の情報が弱くなっていることがわかります。BERTに入力するベクトルは、字面の情報だけを持ったOne-hotベクトルなので、入力に近いほど字面の情報が濃く表れるのは当然といえば当然です。
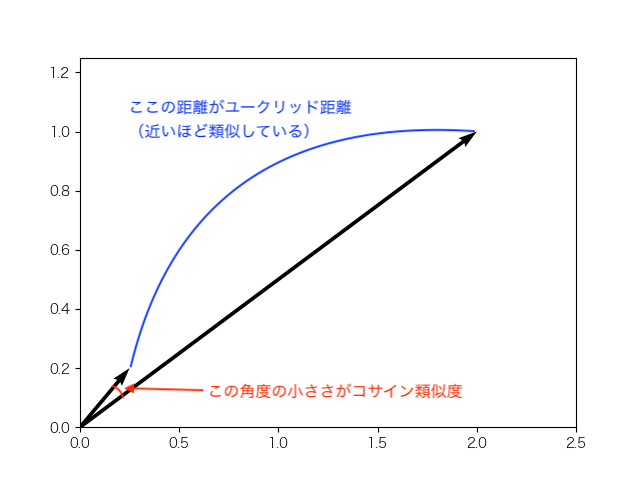
また、コサイン類似度よりもユークリッド距離の方が字面の情報が弱いこともわかります。これは下の図で説明ができます。
2つの単語ベクトルが、この様になっている場合には、コサイン類似度での類似度は大きくなり、ユークリッド距離での類似度は小さくなるからです。
まとめ
今回は、各層の単語ベクトルの分布を見てみましたが、入力に近い層で縦軸に意味の境界線がありそうな感じでした。前回考察した通り、768次元のベクトルのどこかの次元、もしくは次元の組み合わせで意味が表現されている可能性を予想させるような結果です。
また、単語ベクトル間の類似度を計算した結果から、類似度には単語の字面が強く反映されていることがわかりました。意味を取り扱う場合には、単語ベクトルそのまま使わないほうが良さそうです。
前回と同じ結論ですが、やはり意味を表す軸を探す難行が必要そうです。
-
先頭の[1]、[2]、…は、今回の記事用に追記した行番号で、実際のデータには含まれていません ↩
-
今回の記事に関係のない行は省略してあります ↩
-
引用元:「GAFA」「Google」「Amazon.com」「Facebook」「アップル (企業)」「アマゾン熱帯雨林」『フリー百科事典 ウィキペディア日本語版』。2019年11月18日 (日) 6:00 UTC、URL: https://ja.wikipedia.org ↩