はじめに
こんにちは!金融関連のデータマネジメントを通じてDXを推進しているコンサルタントです。
この度、「第4回金融データ活用チャレンジ」に挑戦しました。今回の目玉は、協賛企業であるDataiku社の**「Dataiku Cloud」**をフル活用して、生成AIによる事業経営提案書を作成することです。
PythonコードベースでのRAG(検索拡張生成)構築を学んだり、業務ではPalantirなどを利用していますが、実は私、Dataikuを触るのは今回が初めて。
Dataikuの「ノーコードとコードの融合」に大きな可能性を感じ、今回のコンペを通じてAIエージェント構築の「肌感」を掴むことを目標にしました。
本記事では、Dataiku Cloudを使ってどのように高度な提案書作成プロセスを構築したのか、その様子を公開します!
今回のミッション:建設業界10社への「刺さる」提案書作成
コンペの課題は、対象企業10社(すべて建設業)の財務データを分析し、生成AIを用いて「事業経営提案書」を作成することです。
しかし、単なる財務分析だけでは、本当の意味で価値のある提案はできません。
- 「地域によって建築業界に対する課題も、ニーズも異なるのでは?」
- 「業界全体のトレンドや競合動向をどう反映させるか?」
これらを解決するため、**「財務データ × 非財務情報(地域・技術・市場)」**を統合した、AIエージェントによる多角的な分析プロセスを構築しました。
構築したプロセスと全体像
Dataiku上で構築したフローの全体像は以下の通りです。
(Dataikuではデータのインプット・プロセス・アウトプットが左から右に流れるようなフロー図が自動的に作成されます。違和感ない状態が自然に作成できて感動!)
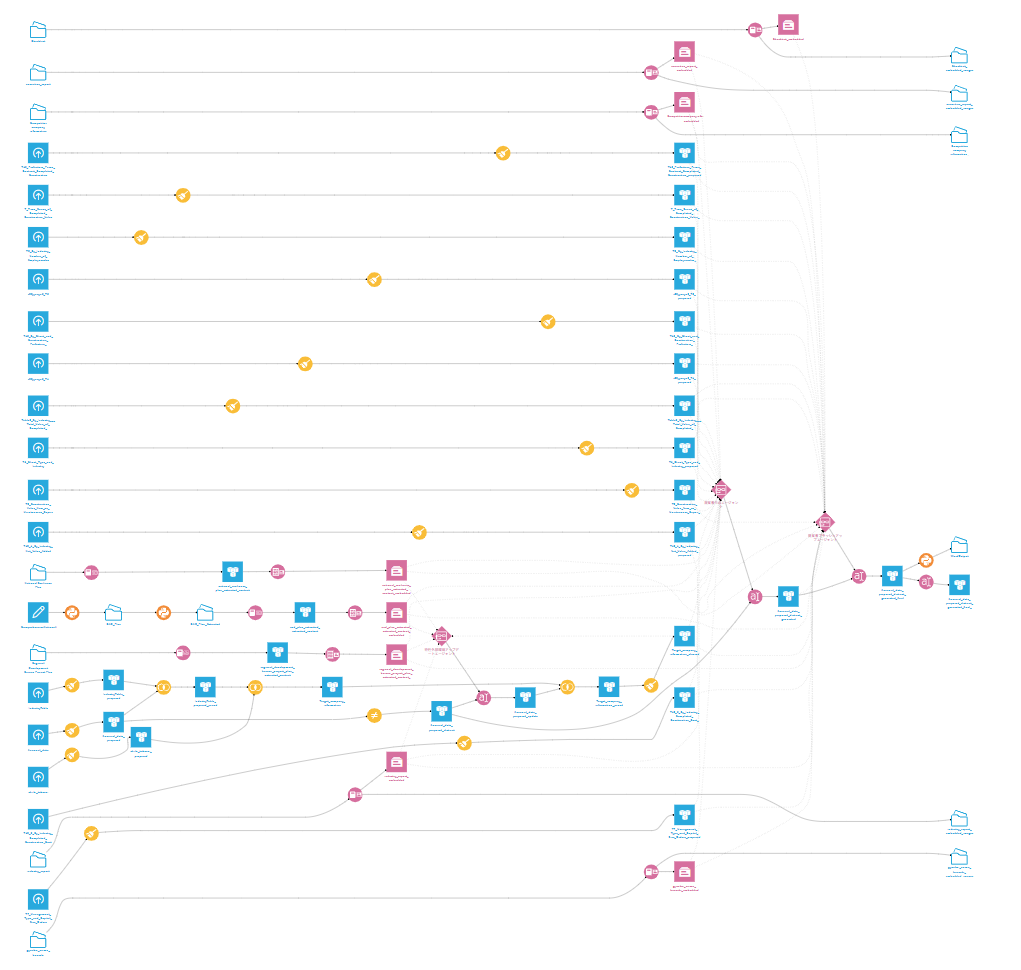
インプットデータの多様化
主催者から提供された財務データに加え、以下の非財務情報をGemini等の外部リサーチを組み合わせて独自に収集・統合しました。
| カテゴリ | 収集したデータ内容 |
|---|---|
| 自社分析 | 財務データ、建設工事施工統計(国交省) |
| 市場分析 | 建設業界リサーチ、建設業界の技術トレンド |
| 地域特性 | 国土強靭化計画、地方整備局の事業概要、社会資本総合整備計画 |
| 競合分析 | 都道府県別の同業種の競合情報 |
Dataikuでは多様な方法でデータをインプットできます。
今回は、あらかじめデータ格納フォルダを作成して、フォルダにデータファイルをアップロードする方法、アップロード時にデータセット化して扱うインプット方法を2通り実装しています。
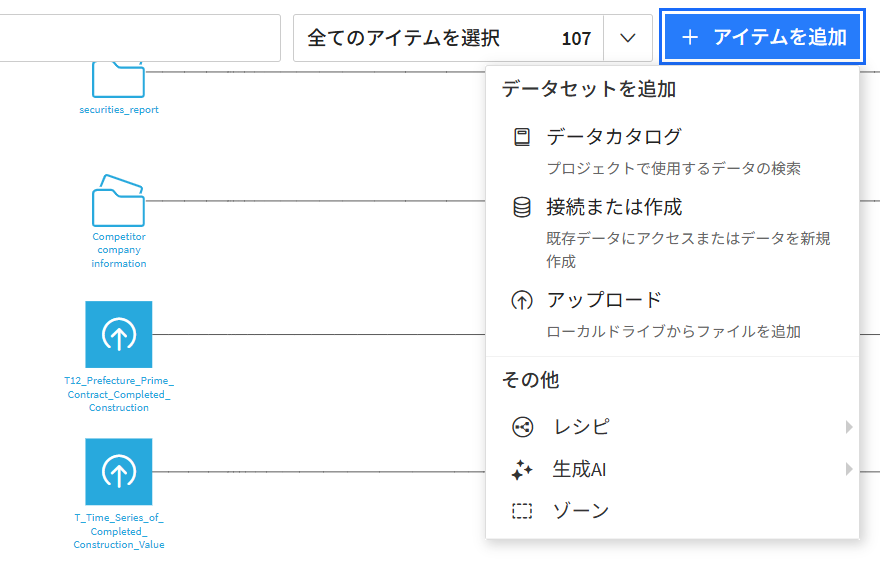
【1.データ格納フォルダ】
<+ アイテムを追加>から接続または作成でフォルダを作成

【2.データセット化】
<+ アイテムを追加>からアップロードを作成
徹底解説:Dataiku Cloudによる実装ステップ
今回の提案書作成は、単にプロンプトを投げるのではなく、以下の5つのステップで構築しました。
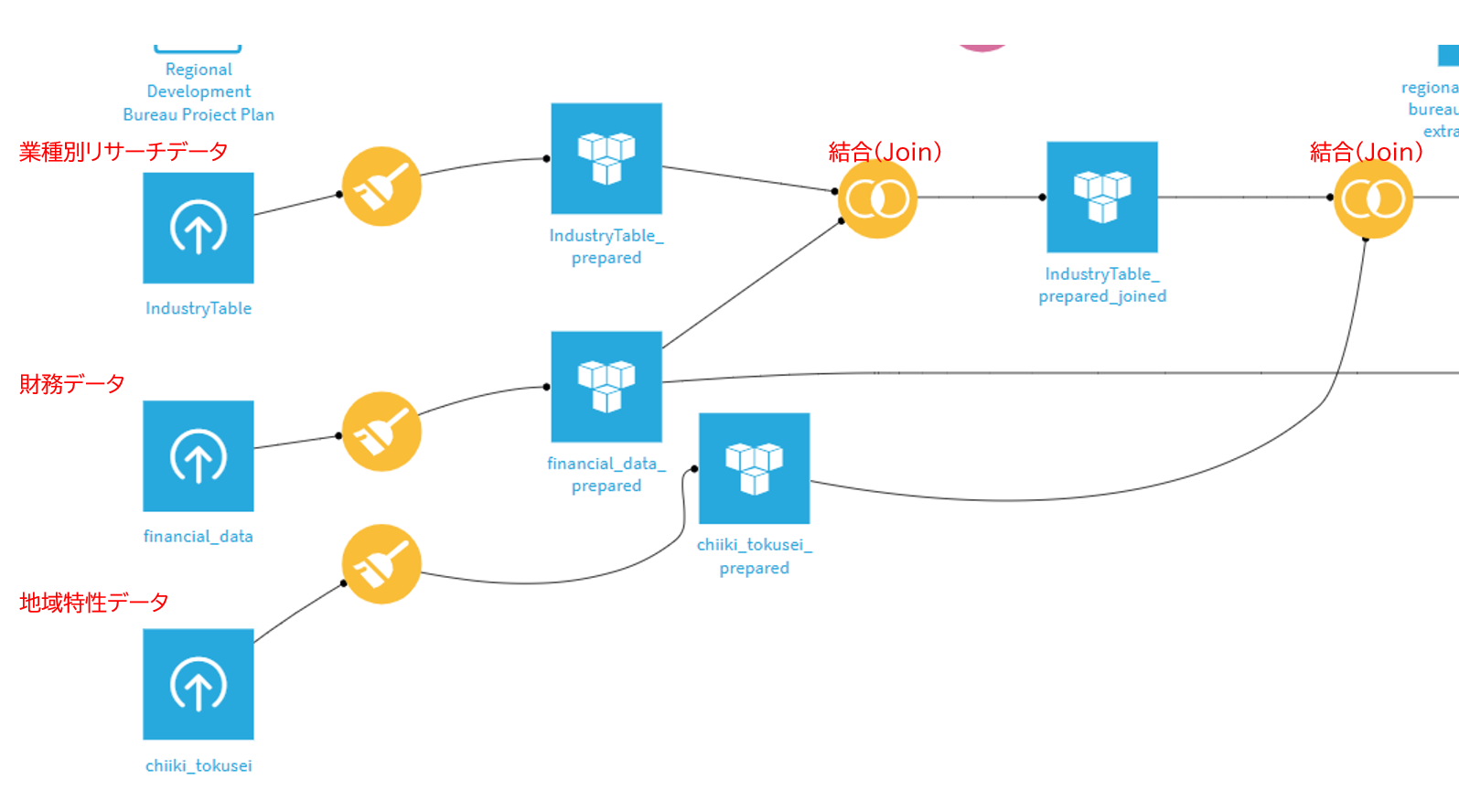
STEP 1:インプットデータの「トリートメント」
まず、提供された財務データに「血肉」を通わせるため、外部情報を統合しました。
- データのアップロード: 主催者提供の財務データと、Geminiでリサーチした「業界動向」「競合情報」をDataikuのDatasetとしてインポート。
-
データの結合(Join):
財務データ+業種別リサーチデータをJoinレシピで結合。これにより、企業ごとの財務状況と業界特有の課題を紐付けました。
STEP 2:Pythonレシピによる地域データの自動収集
「地域特性」を深掘りするため、各自治体のPDF資料が必要でしたが、手動収集は困難です。ここでDataikuのPythonレシピを活用しました。
-
実装内容:
- 都道府県ごとのURLリストをDatasetとして作成。
- Pythonレシピ内で
requestsやBeautifulSoupを用い、指定したURLからPDFリンクを辿って「社会資本総合整備計画」を取得するコードを実装。 - 取得したデータをそのままDataiku上のフォルダ(Managed Folder)へ保存。
【URLを保持するデータセット】
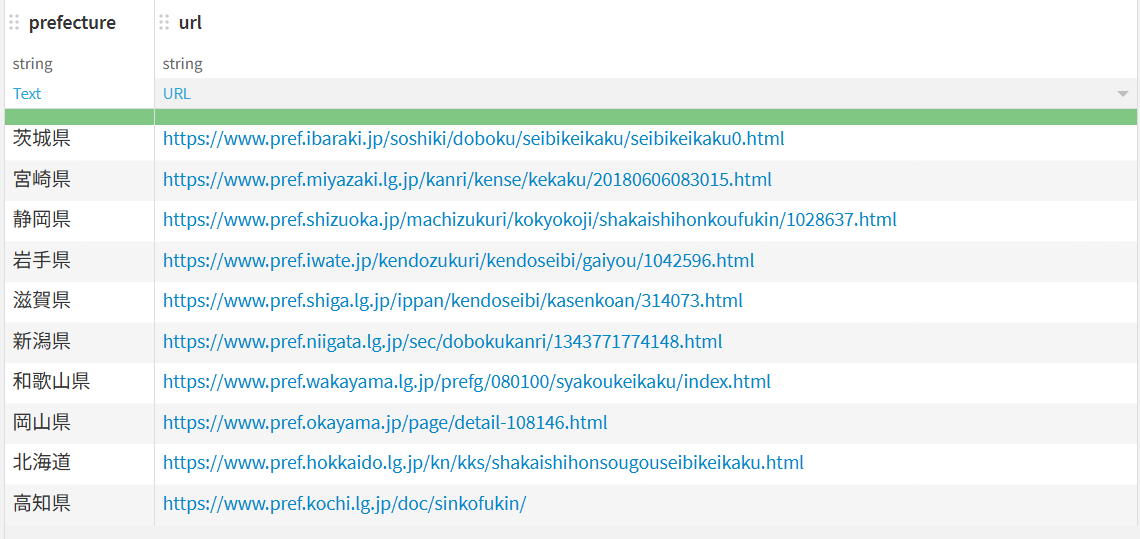
【URLをもとにPDF探索】
import dataiku
import requests
from bs4 import BeautifulSoup
import os
import time
# 1. Dataikuの入出力設定
input_dataset = dataiku.Dataset("ComprehensiveNationalInfrastructureDevelopmentPlan") # 入力データセット名
output_folder = dataiku.Folder("AeU4giDu") # 出力フォルダID
df = input_dataset.get_dataframe()
# 2. PDFをダウンロードする関数
def download_pdf(url, folder):
try:
response = requests.get(url, timeout=10)
soup = BeautifulSoup(response.text, 'html.parser')
# ページ内のすべてのリンク(<a>タグ)をループ
for link in soup.find_all('a'):
href = link.get('href')
if href and href.endswith('.pdf'):
# 相対パスを絶対パスに変換
pdf_url = requests.compat.urljoin(url, href)
pdf_name = os.path.basename(pdf_url)
# PDFの内容を取得
pdf_response = requests.get(pdf_url)
# DataikuのManaged Folderに保存
with folder.get_writer(pdf_name) as w:
w.write(pdf_response.content)
print(f"成功: {pdf_name} を保存しました。")
# サーバー負荷軽減のため少し待機
time.sleep(1)
except Exception as e:
print(f"エラー発生 ({url}): {e}")
# 3. メイン処理:各URLに対して実行
for index, row in df.iterrows():
target_url = row['url']
print(f"解析中: {target_url}")
download_pdf(target_url, output_folder)
技術的な工夫: PDFが膨大だったため、特定のキーワードを含む計画のみに絞り込むフィルタリング機能もコードに追加しました。
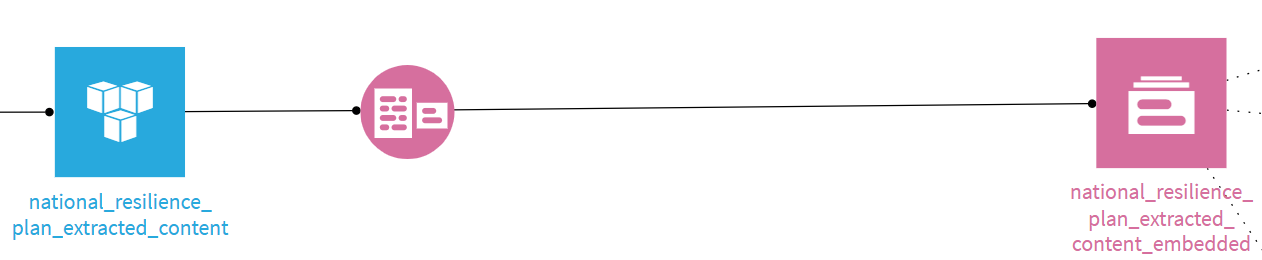
STEP 3:Knowledge Bank(RAG)の構築
収集した大量の非財務データをAIが賢く参照できるよう、DataikuのKnowledge Bank機能を活用しました。
- ベクトル化: 収集したPDFやテキストデータをDataiku上でEmbedding。
- Agent Tool化: これをエージェントが「道具」として使えるよう、Agent Toolとして定義しました。
【例|国土強靭化計画のベクトル化】
私はPDFファイルから文字を抽出してからベクトル化することとしました。
1.PDFファイルから文字抽出

2.抽出された結果をベクトル化
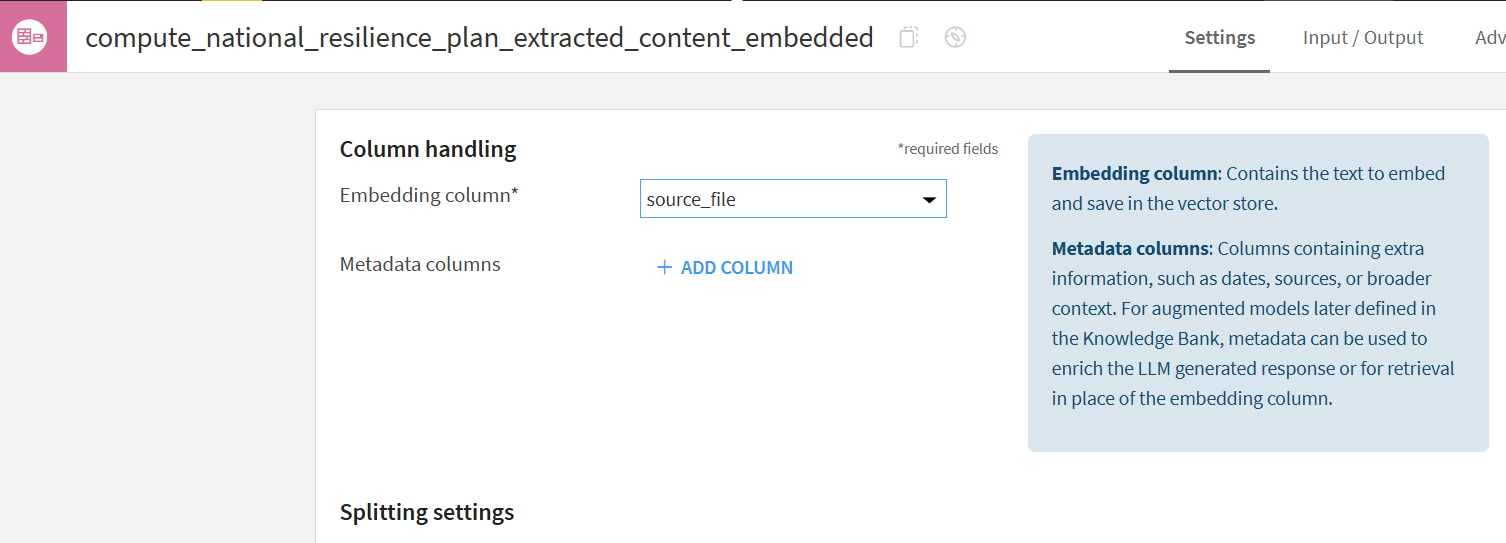
★★★ブログを作成中に衝撃的なことに気が付きました★★★
ベクトル化(Embedding)をするときに、どの列を対象にEmbeddingするのかを指定する「Embedding column」という選択肢があり、私は誤ってコンテンツ内容である"extracted contents"ではなくファイル名である"source file"を選んでいました!!(恥ずかしいし、悔しいーーー、もっと早く気が付いていれば、もっとよくなったでしょうに・・・あまり国土強靭化計画の内容が反映されないわけだ(泣))
STEP 4:3段構えの「マルチエージェント」フロー
ここが本実装の心臓部です。1つのAIに全てを任せず、**「作成・評価・修正」**のプロセスをDataiku上で構築しました。
-
① 提案書作成エージェント:
財務・市場・地域の全てのToolを参照し、Gemini Proで作成した「必勝フォーマット」に従ってmd形式のドラフトを出力。
-
② 評価エージェント:
完成したドラフトを「専門家の目」でチェック。不足しているデータや、論理の飛躍を指摘させます。
-
③ ブラッシュアップエージェント:
評価結果をもとに、再度各Toolを参照して内容を補強。最終的な提案書を完成させます。
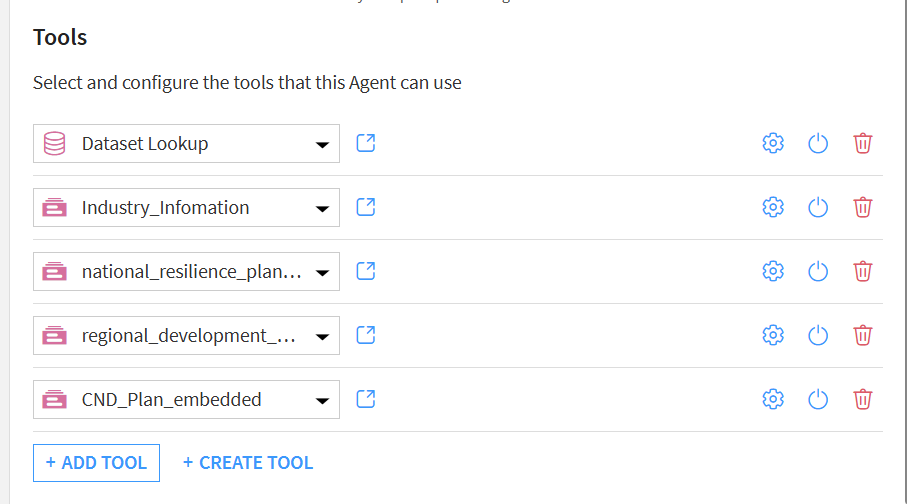
★★★
エージェントにはAgent toolsに登録した道具を指定できます。
先にRAG化したデータやデータセットをAgents & GenAI modelsの画面から指定します。
STEP 5:最終アウトプットの変換(Dataiku & Google Colab)
コンペの規定はWord形式(.docx)でしたが、Dataiku環境内でのライブラリ制約を考慮し、以下のハイブリッド方式を採用しました。
- Dataiku: 最終的なブラッシュアップ済みテキスト(Markdown)を出力。
- Google Colab: Dataikuから書き出したmdファイルを一括でWordに変換するPythonコードを実行。
【mdファイルを一括でWordに変換するPython】
# 1. 必要なライブラリとPandoc本体のインストール
!apt-get install pandoc -y
!pip install pypandoc
# 2. Googleドライブのマウント ※GoogleドライブのDataフォルダにmdファイルを用意
from google.colab import drive
drive.mount('/content/drive')
import os
import pypandoc
from datetime import datetime
# --- 設定エリア ---
INPUT_DIR = '/content/drive/MyDrive/Data'
BASE_OUTPUT_DIR = '/content/drive/MyDrive/output'
# 1. 実行時の日時を取得 (例: 202310251430)
timestamp = datetime.now().strftime('%Y%m%d%H%M')
# 2. 日時付きの出力フォルダパスを作成
target_output_dir = os.path.join(BASE_OUTPUT_DIR, timestamp)
# 3. 出力フォルダが存在しない場合は作成
if not os.path.exists(target_output_dir):
os.makedirs(target_output_dir)
print(f"作成された出力フォルダ: {target_output_dir}")
# --- 実行エリア ---
files = [f for f in os.listdir(INPUT_DIR) if f.endswith('.md')]
if not files:
print("変換対象の .md ファイルが見つかりませんでした。")
else:
print(f"合計 {len(files)} 件のファイルを処理します。\n")
for filename in files:
input_path = os.path.join(INPUT_DIR, filename)
output_filename = os.path.splitext(filename)[0] + '.docx'
output_path = os.path.join(target_output_dir, output_filename)
print(f"変換中: {filename} -> {output_filename} ...", end="")
try:
pypandoc.convert_file(input_path, 'docx', outputfile=output_path)
print(" 完了!")
except Exception as e:
print(f" 失敗: {e}")
print(f"\nすべての処理が終了しました。")
print(f"保存先: {target_output_dir}")
開発を支えた「プロンプトエンジニアリング」の工夫
DataikuのLLM Meshを最大限活かすため、プロンプトには以下の工夫を凝らしました。
- 役割(Role)の明確化: 「あなたは大手銀行のベテラン経営コンサルタントです。長年、建設・土木業界の事業経営に携わっており、業界特性・業界課題・地域特性を踏まえた事業提案が得意です。」といったペルソナを設定。
- 思考の連鎖(CoT): 財務分析 → 外部環境分析 → 課題抽出 → 具体的施策、というステップを踏めるようなフォーマットを指示。
工夫したこと・チャレンジしたこと
-
「型」と「チェックリスト」の導入:
普段の業務経験から、AIの出力品質を安定させるには「フォーマット」が不可欠だと確信していました。Geminiを使い倒して最適な提案書フォーマットと評価チェックリストを事前に作成し、それをDataikuのエージェントに組み込むことで、プロの視点に近いアウトプットを目指しました。
-
3C分析のフレームワーク適用:
「市場・競合・自社」の視点でインプットデータを整理。Dataiku上でこれらのデータをクレンジングし、エージェントが扱いやすい「Agent Tool(Dataset)」として整備しました。
Dataikuを使ってみた感想
初めてDataiku Cloudを使用しましたが、**「ビジュアルでプロセスが見える化される」**ことの安心感は絶大でした。
普段使っているPalantirはデータ統合やBIに強みがありますが、生成AIとの親和性や、エージェントをノーコードでサクサク組める軽快さはDataikuに軍配が上がると感じます。特に、作成したデータセットをそのままAgentのKnowledgeとして紐付けられるシームレスさは感動的でした。
振り返りと次回の展望
今回のチャレンジを通じて、AIエージェントは単に「作って終わり」ではなく、**「いかに良質なインプット(データトリートメント)を行い、いかに多角的なレビュー(評価プロセス)を組み込むか」**が重要であることを再認識しました。
次回チャレンジしたいこと:
- DataikuでのWebアプリ実装: 人間が途中でレビューを挟めるインターフェースを作り、より実務に近いツールに昇華させたい。
- オーケストレーターの設計: 今回は連鎖的な構成でしたが、全体を制御するオーケストレーターを配置し、より複雑なタスク分解に挑みたい。
コンペを通じて、生成AIが「仕事の相棒」から「頼れるチームメンバー」に進化していく過程を実感できました。Dataikuという強力な武器を手に入れたので、これからの業務・スキルアップにも積極的に取り入れていきたいと思います!
最後までお読みいただきありがとうございました。
本記事が、これからDataikuで生成AI活用を始める方の参考になれば幸いです。