はじめに
前回の記事で、AerospikeのGraphデータベース機能をGremlin-Consoleで使うところまで試してみました。
この記事では、データのローディングと視覚化とを試してみます。
Appleシリコン搭載のMacを使用の場合、以下のaerospike-graph-serviceおよびgremlin-consoleについては、Rosetta 2をインストールし、--platform linux/amd64を追加して実行してください。
データのローディング
データのローディングには、スタンドアローン環境でロードするものと分散処理でロードするものとがあります。
どちらを使用するかは明確な基準はありませんが、データ量で使い分けます。
スタンドアローン環境の場合は、aerospike-graph-serviceのローカルファイルかS3環境からロードします。
分散処理の場合は、AWSかGCPのApache Sparcの機能と連携してロードします。
この記事ではスタンドアローン環境でのロードを試してみます。
スタンドアローン環境でのデータローディング
ローディングするデータはGremlin CSVのフォーマットを使用します。フォーマットについては、こちらに説明があります。(日本語での説明)
ロードするデータは、AWSが提供するこのサンプルデータを使用します。
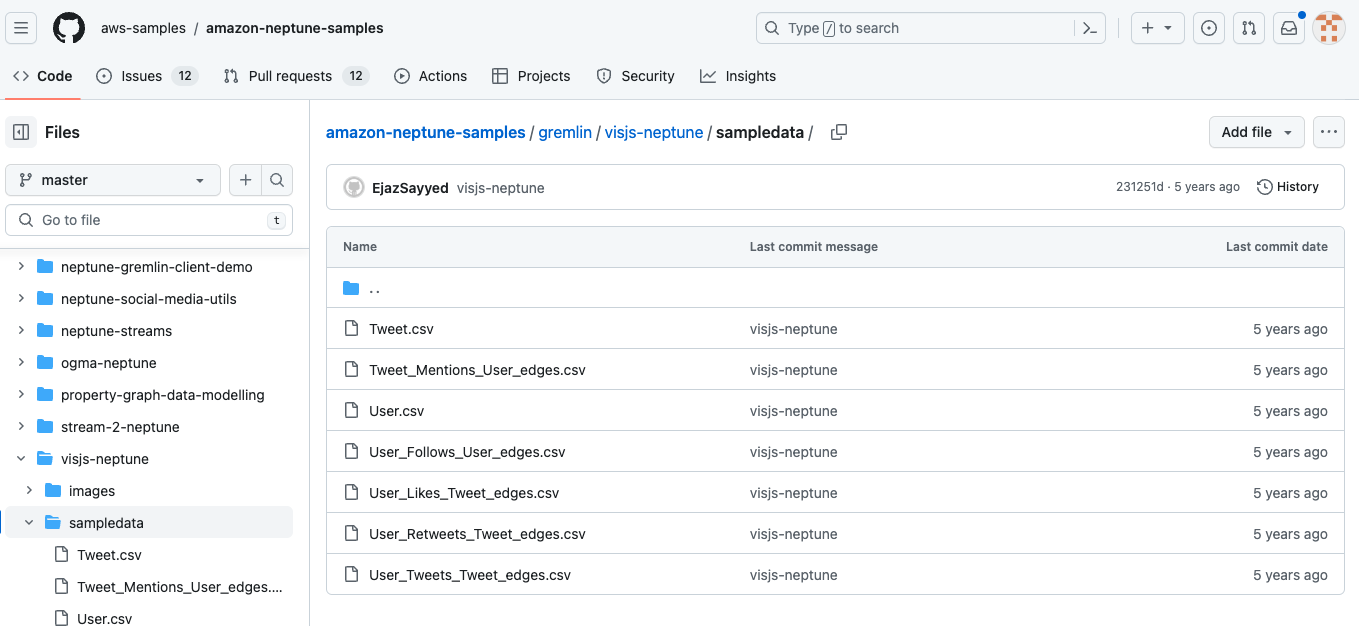
Aerospike Graph Serviceのデータロードでは、EdgeとVerticのフォルダを分ける必要があるので、サンプルデータをダウンロード後、edgesとverticesのフォルダを作成し、Tweet.csvとUser.csvをverticesフォルダに、それ以外をedgesフォルダに移動し、apache-gremlin-serviceのDocker起動時にマウントして参照できるようにしてください。
例えば、前の記事のように以下のコマンドで起動している場合であれば、/home/graph/data/の下にsampledata/edgesとsampledata/verticesを作成し、csvファイルをそれぞれ保存してください。
sudo docker run -p 8182:8182 --name aerospike_gs \
-e aerospike.client.namespace="test" \
-e aerospike.client.host="$(sudo docker inspect -f '{{.NetworkSettings.IPAddress }}' aerospike_ee):3000" \
-v /home/graph/data/:/opt/graph/data/ \
aerospike/aerospike-graph-service
Gremlin-Consoleを使ってこのデータをロードします。
まず、Aerospike Graph ServiceのIPアドレスを調べます。
sudo docker inspect -f '{{.NetworkSettings.IPAddress }}' aerospike_gs
Gremlin-Consoleを実行します。
sudo docker run -it tinkerpop/gremlin-console
次に、Aerospike Graph Serviceに接続します。
g = traversal().withRemote(DriverRemoteConnection.using("[aerospike_gsのIPアドレス]", 8182, "g"));
以下でデータのロードを開始します。
g.with("evaluationTimeout", 24 * 60 * 60 * 1000).call("bulk-load").with("aerospike.graphloader.vertices", "/opt/graph/data/sampledata/vertices").with("aerospike.graphloader.edges", "/opt/graph/data/sampledata/edges")
成功すると以下のように表示されます。
==>Success
gremlin>
ここでは、ローカルなデータをローディングしましたが、AWSのS3からのローディングも可能です。
説明は、以下に記載されています。
https://docs.aerospike.com/graph/data-loading/standalone#bulk-loading-with-remote-files
大量データのローディング
分散処理でのローディングは、AWSかGCPの環境でApache Sparkを使用して実行できます。
詳しくは以下に記載されています。
https://docs.aerospike.com/graph/data-loading/distributed
視覚化ツール
Graphデータベースを利用される場合、システム内だけではなく、視覚化して分析したい場合も多いかと思います。
Aerospikeでは、G.V()での視覚化が可能になっています。
以下に説明が記載されています。
https://docs.aerospike.com/graph/data-loading/distributed
ここでは、簡単に試してみます。
このツールは有償ツールですが、60日間のトライアルが可能ですので、ぜひ試してみてください。
価格については以下に記載されています。
https://gdotv.com/buy/
ツールのイメージを知りたい場合は、以下から説明や動画をご覧ください。
https://docs.gdotv.com/#janusgraph
利用する場合は、以下からダウンロードし、インストールしてください。
https://gdotv.com/
インストールし起動すると、このような画面が表示されます。
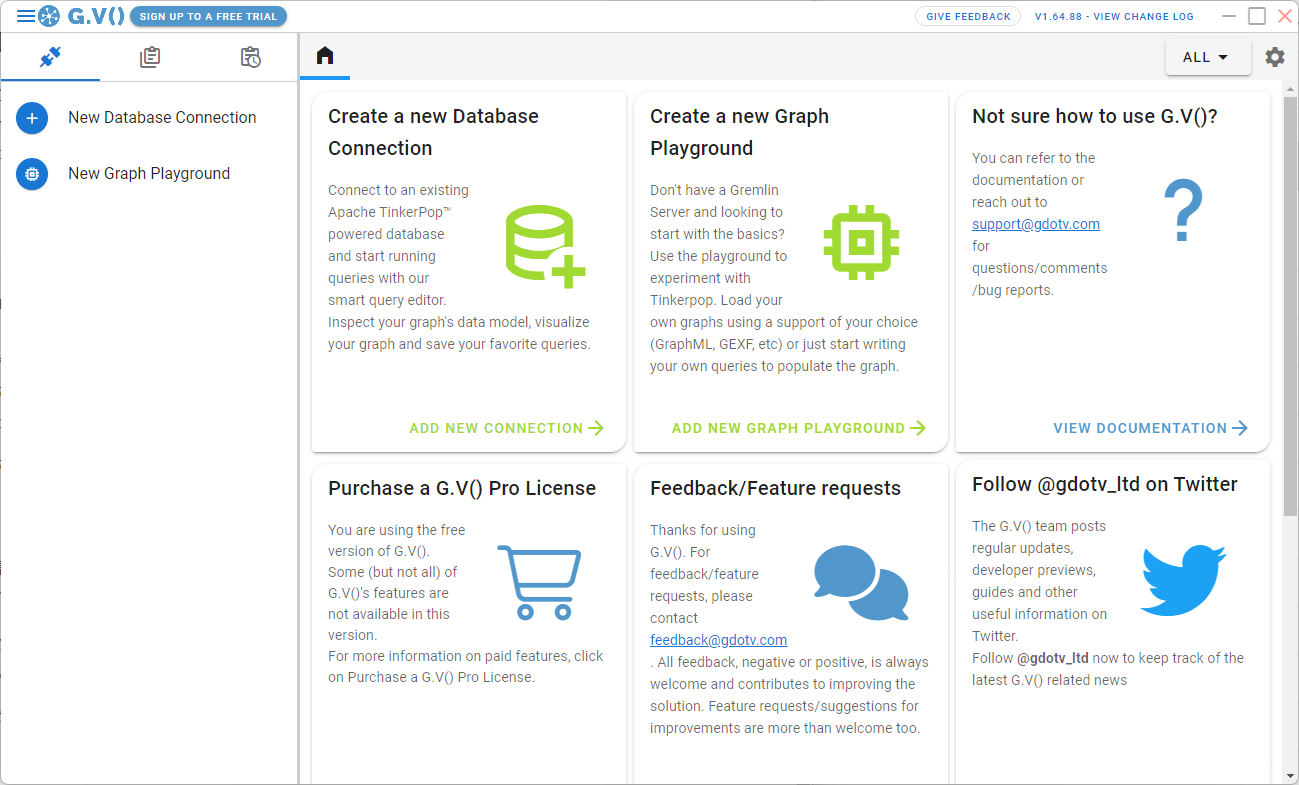
左の、「New Database Connection」をクリックすると以下の画面が表示されます。
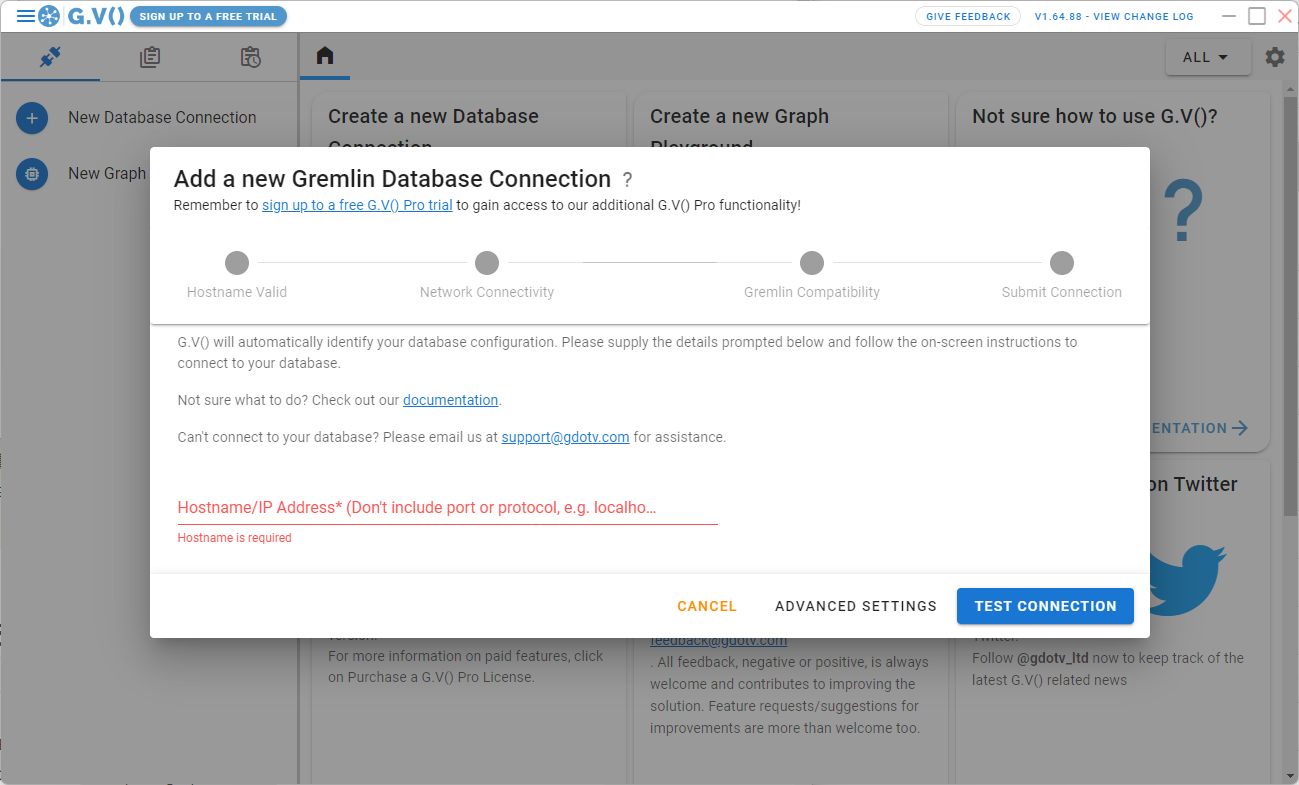
ここで、Aerospike Graph Serviceのホスト名またはIPアドレスを入力し、「TEST CONNECTION」をクリックします。
ネットワークやGremlinのインタフェースのチェックが行われ、以下の画面が表示されます。
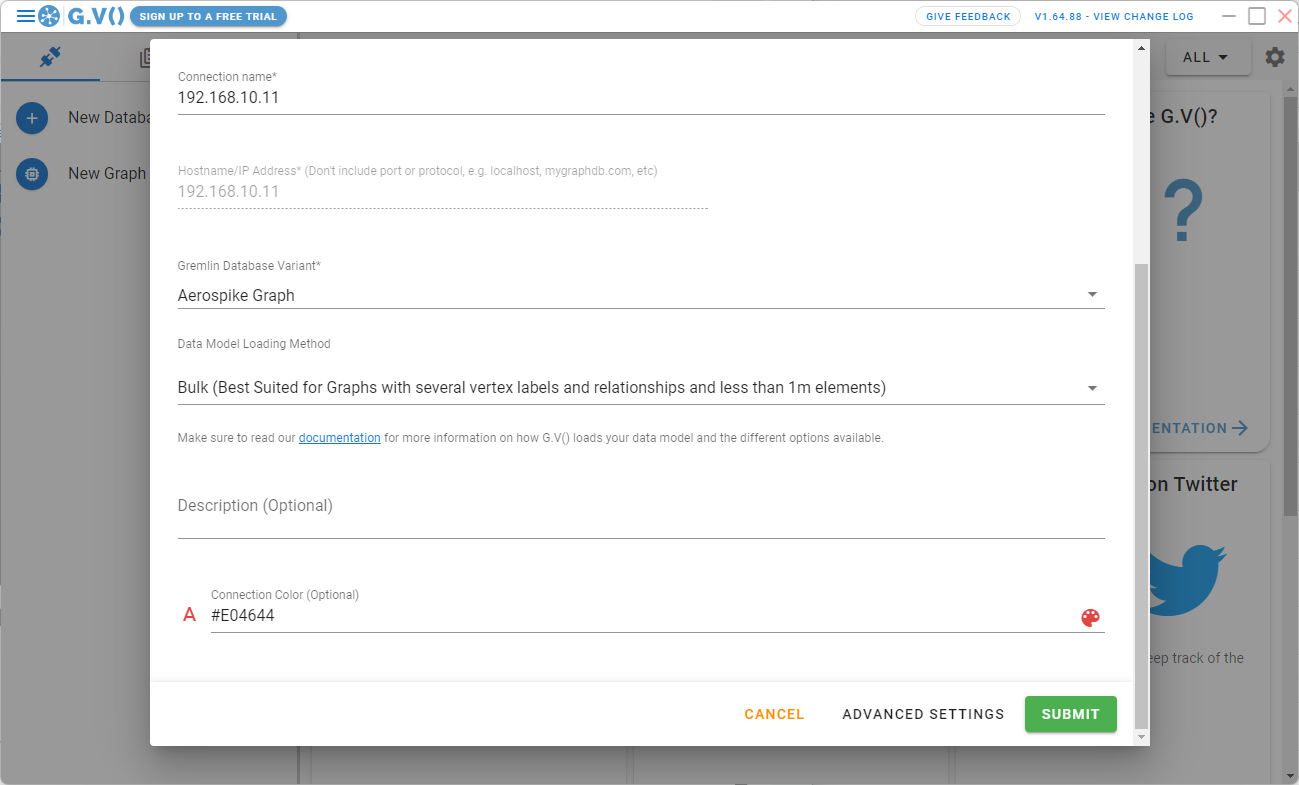
Connection Name、Description、Connection Colorを必要であれば変更し、「SUBMIT」をクリックします。
接続が作成され、ライセンスの登録画面が表示されます。
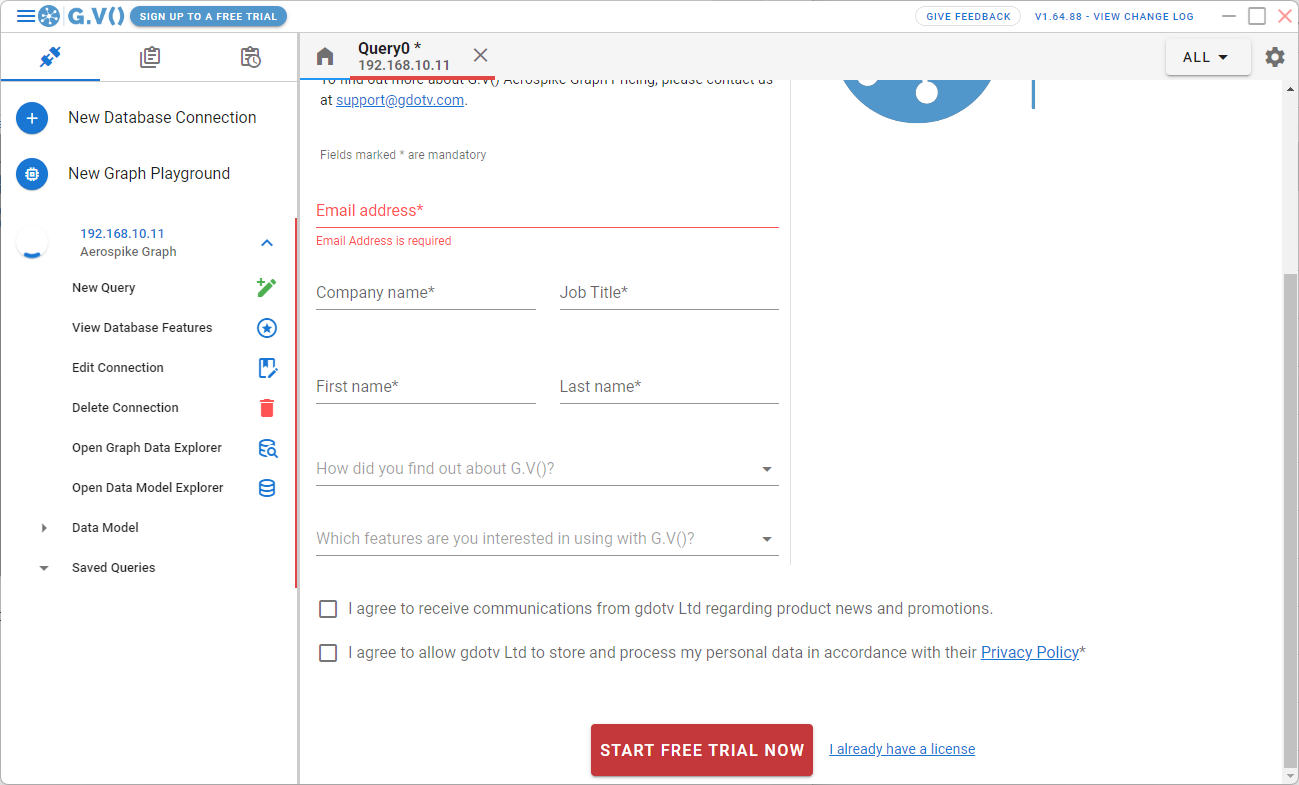
必要な情報を入力し、「START FREE TRIAL NOW」をクリックすると、Validation Codeの入力画面が表示されます。
設定したメールアドレスにValidation Codegaが送信されますので入力し、「SUBMIT VALIDATION CODE」をクリックしてください。これで、G.V()が使用できるようになります。
様々な機能がありますが、「Open Graph Data Explorer」をクリックすると、以下のようにGraphデータが視覚化されます。

これは、上記のロードしたデータです。さすがにデータが多いので、非力なPCだと相当時間がかかりますし、開けない場合もあります。
ちょっと厳しいようであれば、前回のサンプルデータで試してください。
まとめ
あくまでテスト環境なので、性能的には厳しいものがありますが、確認作業であれば十分かと思いますので、ぜひ、試してみてください。
以下に、さらに詳しい情報がありますので、御覧ください。
https://docs.aerospike.com/graph
前回の記事:Aerospikeを使ってみる:Graph データベース機能を試す
https://qiita.com/aerospike_nakadai/items/992eedcf2bb9e485e101