課題
データを分析してまとめたりするのは、Pythonでライブラリを利用するのが便利です。よく使うのは Numpy, Matplotlib, Pandas, Seaborn。
Jupyter Notebookでいろいろ分析を試行錯誤して、こんな処理をするといいというのが決まったらスクリプト化して毎日自動で走らせたくなります。
毎時間ごとにスクリプトを走らせたりするにはAWS Lambdaがお気軽。サーバのメンテなどやらずに済みます。しかも安い。
でもAWS LambdaのPythonでライブラリを使おうとすると、ディプロイパッケージを作ってあげないといけません。しかもNumpyなどコンパイルが必要なライブラリを使うなら、Amazon Linuxの環境などが必要になり面倒な感じです。
Cloud9 で気軽に開発環境を立ち上げる
AWS Cloud9 はEC2にサーバを立てたうえで、手元のPCのブラウザからアクセスして開発環境として利用できるものです。DockerでAmazon Linuxを動かすのもいいのかもしれませんが、クラウド上にセットアップしたほうがお手軽。しかもしばらく使っていないと勝手にEC2インスタンスを休止してくれるらしくてお財布に優しい。
AWS Cloud9 のメニューから新規環境を作ります。特に気をつけるところはないですが、今の所platformとして選べるのが Amazon Linuxか Ubuntu Server 18.04 LTS しかありません。Lambdaの環境は Amazon Linux2になってきているようですが、しょうがない。今回はAmazon Linuxを選びました。
Serverless application wizardでラムダ関数を用意する
基本的にはドキュメントに従ってセットアップします。
Cloud9が立ち上がったら、右端の"AWS Resources"タブをクリックしてLambdaメニューを表示する。"Create a new Lambda function"ボタンを押すと"Create serverless application"というウィザードが現れます。
今回は envtestという名前で作ることにします。Runtimeとして選べるPythonは残念ながらPython3.6だけでした。
ウィザードが終了したら、envtestというフォルダーができているはずです。
コードを書く前に、必要なライブラリをインストールしましょう。
envtest/venv/
にPythonのVirtual Environmentが用意されています。
Cloud9 IDEのコンソールから
source ./envtest/venv/bin/activate
と入力してアクティベートしてから、pipで必要なライブラリをどんどんインストールします。
AWS Lambdaには、ライブラリも含めたディプロイパッケージのサイズは250MBまでという制限があります。必要最低限なものだけインストールしましょう。
今回は
Numpy, Matplotlib, Pandas, Seaborn, Pillow, boto3
をインストールしましたが(ぎりぎり)大丈夫でした。
Lambda関数を書いていく
envtest/envtest/lambda_function.py
にLambda関数を書いていきます。
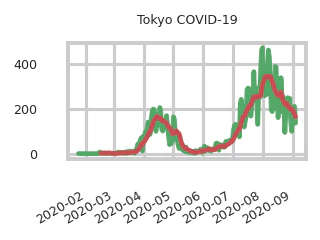
今回は東京都のコロナウィルス感染者数の傾向を掴むため、毎日公表される東京都の感染者数CSVを読み込み、日々の数値と7日間移動平均とをプロットしてS3にアップロードするスクリプトにしました。 AdafruitのPyportalで表示するように、320x240ピクセルのビットマップにしています。
2020-9-5現在こんな感じ。
import base64
import io
from datetime import datetime as dt
import boto3
import pandas as pd
import seaborn as sns
from matplotlib import pyplot as plt
sns.set(style="whitegrid")
from PIL import Image
# 新型コロナウイルス陽性患者発表詳細の取得
URL = 'https://stopcovid19.metro.tokyo.lg.jp/data/130001_tokyo_covid19_patients.csv'
s3_client = boto3.client('s3')
def lambda_handler(event, context):
df = pd.read_csv(URL)
df['date'] = df['公表_年月日'].apply(lambda a: dt.strptime(a, '%Y-%m-%d'))
df = pd.DataFrame(df['date'].value_counts(sort=False).sort_index())
df['ma7'] = df.iloc[:,0].rolling(window=7).mean()
#PyPortal is 320 x 240
ppi = 227
width = 320 / ppi
height = 240 / ppi
SMALL_SIZE = 4
MEDIUM_SIZE = 10
BIGGER_SIZE = 12
plt.rc('font', size=SMALL_SIZE) # controls default text sizes
plt.rc('axes', titlesize=SMALL_SIZE) # fontsize of the axes title
plt.rc('axes', labelsize=MEDIUM_SIZE) # fontsize of the x and y labels
plt.rc('xtick', labelsize=SMALL_SIZE) # fontsize of the tick labels
plt.rc('ytick', labelsize=SMALL_SIZE) # fontsize of the tick labels
plt.rc('legend', fontsize=SMALL_SIZE) # legend fontsize
plt.rc('figure', titlesize=BIGGER_SIZE) # fontsize of the figure title
fig, ax = plt.subplots(figsize=(width,height), dpi=ppi)
ax.plot(df['date'], color='g', label="Daily")
ax.plot(df['ma7'], 'r', label="ma7")
#ax.text(0, 1, "212", fontsize=4)
ax.set_title("Tokyo COVID-19")
#fig.legend()
fig.autofmt_xdate()
plt.tight_layout()
pic_IObytes = io.BytesIO()
plt.savefig(pic_IObytes, format='png')
pic_IObytes.seek(0)
im = Image.open(pic_IObytes)
pic_IObytes_bmp = io.BytesIO()
im.save(pic_IObytes_bmp, format='bmp')
pic_IObytes_bmp.seek(0)
#pic_hash = base64.b64encode(pic_IObytes_bmp.read())
s3_client.upload_fileobj(pic_IObytes_bmp, "pyportal", "covid19_tokyo.bmp", ExtraArgs={'ACL': 'public-read'})
return ''
コード補足
df = pd.read_csv(URL)
この1行だけでURLからCSVをダウンロードして、Pandas.DataFrameにしてくれます。すばらしい。
df['date'] = df['公表_年月日'].apply(lambda a: dt.strptime(a, '%Y-%m-%d'))
df = pd.DataFrame(df['date'].value_counts(sort=False).sort_index())
df['ma7'] = df.iloc[:,0].rolling(window=7).mean()
後で扱いやすいように、文字列として日付が入っている列から、DateTimeオブジェクトの列をつくり、それをインデックスとしたDataFrameとして定義し直す。
また7日間移動平均を計算して新しい列を作る。
fig, ax = plt.subplots(figsize=(width,height), dpi=ppi)
ax.plot(df['date'], color='g', label="Daily")
ax.plot(df['ma7'], 'r', label="ma7")
matplotlibでグラフ描画。最終的に320x240pixelにしたいので、dpiを適当に設定してwidth, heightを設定。
pic_IObytes = io.BytesIO()
plt.savefig(pic_IObytes, format='png')
pic_IObytes.seek(0)
グラフをPNG形式でメモリ上に保管。Pyportalがビットマップ形式しか読めないので、ビットマップで保存したかった。でも利用しているmatplotlibのバックエンドがBMP形式での保存に対応していなかった。
im = Image.open(pic_IObytes)
pic_IObytes_bmp = io.BytesIO()
im.save(pic_IObytes_bmp, format='bmp')
pic_IObytes_bmp.seek(0)
しょうがないので一旦PNG形式として保存したのをPillowで開いてBMP形式として保存し直す。
s3_client.upload_fileobj(pic_IObytes_bmp, "pyportal", "covid19_tokyo.bmp", ExtraArgs={'ACL': 'public-read'})
S3にアップロードして公開する。
Cloud9ではLambda関数のデバッグがラク
通常Lambda関数はデバッグするのが面倒です。標準関数だけを使うような単純なものはAWS Lambda管理画面上のIDEが使えてまだマシですが、今回のように外部ライブラリをたくさん使うとそれもできない。
ところがCloud9のIDEでは簡単にデバッグできます。ブレイクポイントを設定してデバッガも利用可能。ありがたや。
ボタン1つでディプロイ
"Run local"でデバッグして、うまく行ったらディプロイします。
Cloud9 IDEのLambdaメニューから、"Deploy the selected Lambda function"ボタンを押すだけ。
勝手に環境をzipしてAWS Lambdaにアップしてくれます。
今回は最後にS3にアップロードするので、AWS Lambda管理画面から今回の関数のロールにAmazonS3FullAccessのポリシーを設定する必要があります。
うまくいったらEventBridge (CloudWatch Events)をトリガーとして設定して、rate(1 day)とかにすれば完成。
おまけ Cloud9で Jupyter Notebookを立ち上げる
Cloud9のIDEも悪くないのですが、Jupyter Notebookでいろいろやってみたいときもあります。
そこでClould9のサーバ上でJupyter Notebookを立ち上げ、手元のPCやスマホのブラウザからJupyter Notebookで開発できるようにします。
EBS容量を大きくしておく
Jupyter Notebookでいろいろ実験してみる環境を整えるので、おそらくEBS volumeの容量が足りなくなります。ドキュメントに従って大きくしておきましょう。私は20GiBにしておきました。
Resize an Amazon EBS volume used by an environment
minicondaで好きにする
Cloud9 IDEのコンソールから、minicondaをセットアップして好きなPythonの環境をセットアップしていきます。
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh
あとは condaで好きに環境を作ればいい。
Jupyter Notebook立ち上げ
jupyter notebook --ip=0.0.0.0
立ち上げるときには、外部からアクセスできるようにIPに0.0.0.0を指定します。
セキュリティーはガバガバなので、せめてパスワードは設定しましょう。
AWS Cloud9 管理画面のEC2 Instanceの項目の"Go To Instance"をクリックすると、利用しているEC2の管理画面が出ます。
"パブリック DNS (IPv4)"にあるURLをクリップボードにコピーし、最後に”:8888”とポート番号指定をつけてブラウザでアクセスるとJupyter Notebookにアクセスできます。
こんな感じ。
http://ec2-xx-xxx-xx-xx.ap-northeast-1.compute.amazonaws.com:8888/