はじめに
突然ですが――
「オンライン授業は便利だけど、黒板は使いたいし、でもでもカメラマンを連れてくるのはめんどくさい」
と悩んだことがある先生や
「固定カメラから黒板を映したのでは板書が見にくい」
という不満を抱いたことがある学生はいませんか?
この記事では、リアルタイム物体検出アルゴリズムYOLOを使ったヒト自動追尾ドローンのレシピを紹介します。
ヒトの自動追尾に限らず、YOLOは非常に多くのクラスを検出できるので工夫次第で色々な場面に応用できます。
また、有名な話ですが、使用するドローンTello EDUの公式サンプルはPython2.7で書かれているため、ドローンのカメラ映像を受信するステップで数えきれないほどの犠牲者が出ています。
この記事では、Python3を使った「最もつまずきにくい環境構築」も併せてご紹介します。
記事の概要と実際の動作は以下の動画でも紹介しているので、よろしければご覧ください。
1. 概要
プログラムの一連の流れは以下の通りです。
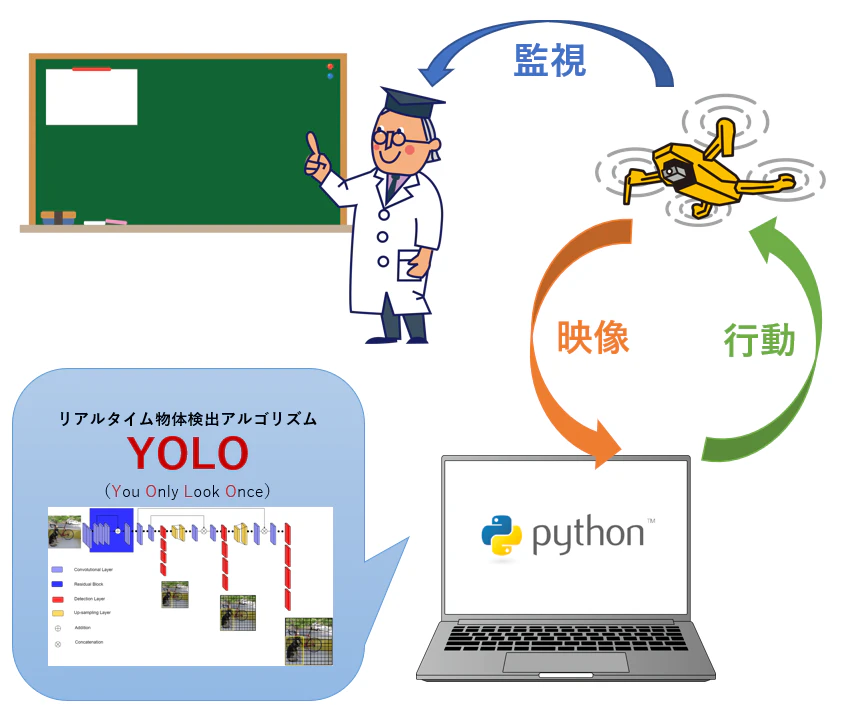
① ドローンとPCをWi-Fi接続する
② ドローンのカメラ映像を受信してPC側で表示
③ PC画面上の映像のスクリーンショットを保存
④ 【カスタマイズ可能】画像から物体検出アルゴリズムYOLOでヒトを検出
⑤ 映像フレームと④の相対位置から次のアクションを決定
⑥ ②~⑤を繰り返す
※ 映像をスクリーンショットで保存するステップを踏むことで、受信したストリーム映像をフレーム単位で取得するよりも、簡単にビルドができます
2. 環境構築
他の記事を読んでいただければ一目瞭然ですが、Telloの記事にしては非常に少ないです。
ライブラリインストール
numpy==1.22.1
opencv-python==4.5.5.62
Pillow==9.0.0
PyAutoGUI==0.9.53
pynput==1.7.6
tellopy==0.6.0
pip install -r requirements.txt
作業環境
- TELLO EDU(ドローン:DJIモバイルオンラインストアで17,050円)
- Python 3.10
- Windows11
- Tiny YOLOv3(tinyモデルは認識精度が若干劣るが、YOLOよりさらに高速に動作)
-
coco_classes.txt(ラベル一覧:coco.namesをコピペしてテキスト保存) -
yolov3-tiny.cfg(設定ファイル:tiny.cfgをコピー) -
yolov3-tiny.weights(学習済みウエイト:yolov3-tiny.weightsをダウンロード)
-
- ffmpeg(映像データの取り込み:こちらの記事を参考にインストールしてパスを通す)
- Mplayer(メディアプレーヤー:
こちらの記事を参考にインストールしてパスを通す)
2022/12/22更新:インストール方法は Mplayerのダウンロードが上手くいかない · Issue #1 · Kitsuya0828/TELLO-pursuit をご覧ください
3. ドローン操作Part
ドローンを手動でも制御できるように、pynput.keyboard.Listenerを使ってキーボード操作を継続的に検知します。
ドローンを動かすためには、Pythonパッケージtellopyを使います。
キーが押された時と離された時の処理は、こちらのコード(GitHub)を参考にしました。
def main():
drone = tellopy.Tello()
drone.connect()
drone.start_video()
drone.subscribe(drone.EVENT_FLIGHT_DATA, handler)
drone.subscribe(drone.EVENT_VIDEO_FRAME, handler)
def on_press(key):
"""キーが押された時に呼ばれるコールバック
"""
print(f'{key} pressed')
speed = 25
if key in [keyboard.Key.esc, keyboard.Key.space]:
return
if key == keyboard.Key.tab:
drone.takeoff()
print("Take off")
elif key == keyboard.Key.backspace:
drone.land()
print("Land")
elif key == keyboard.Key.up: # 上昇
drone.up(speed)
elif key == keyboard.Key.down: # 下降
drone.down(speed)
elif key == keyboard.Key.left: # 左旋回
drone.counter_clockwise(speed)
elif key == keyboard.Key.right: # 右旋回
drone.clockwise(speed)
elif key.char == 'w': # 前方
drone.forward(speed)
elif key.char == 's': # 後方
drone.backward(speed)
elif key.char == 'a': # 左
drone.left(speed)
elif key.char == 'd': # 右
drone.right(speed)
else:
return
return False # 検知終了
def on_release(key):
"""キーが離された時に呼ばれるコールバック
"""
print(f'{key} release')
if key == keyboard.Key.esc: # escが押された場合
return False # 検知を終了する
if key == keyboard.Key.space:
global auto
auto = not auto
sleep(1)
return False
if key == keyboard.Key.tab:
drone.takeoff()
print("Take off")
elif key == keyboard.Key.backspace:
drone.land()
print("Land")
elif key == keyboard.Key.up: # 上昇
drone.up(0)
elif key == keyboard.Key.down: # 下降
drone.down(0)
elif key == keyboard.Key.left: # 左旋回
drone.counter_clockwise(0)
elif key == keyboard.Key.right: # 右旋回
drone.clockwise(0)
elif key.char == 'w': # 前方
drone.forward(0)
elif key.char == 's': # 後方
drone.backward(0)
elif key.char == 'a': # 左
drone.left(0)
elif key.char == 'd': # 右
drone.right(0)
else:
return
return False # 検知終了
while True:
with keyboard.Listener(
on_press=on_press,
on_release=on_release) as listener:
listener.join()
drone.quit()
4. 物体検出Part
YOLOv3を利用するためには、Darknetの実装を利用する方法と、OpenCVでcv2.dnn_DetectionModelを利用する方法があります。どちらでも十分高速に動作するので、この記事では記述がシンプルな後者を採用します。
検出したヒトのバウンディングボックスの重心位置と画像の重心位置の差から左右の制御を行います。また、バウンディングボックスの大きさから前後の制御を行います。(この部分はアイデア次第で変更可能です)
前章でキーボード操作の検知は実装できているので、pyautogui.KeyDownからpyautogui.KeyUpまでのキー押下時間で移動距離を調節します。
def detect_object():
CONFIDENCE_THRESHOLD = 0.3
NMS_THRESHOLD = 0.4
class_names = []
with open("darknet_cfg/coco_classes.txt", "r") as f:
class_names = [cname.strip() for cname in f.readlines()]
COLORS = [np.random.randint(0, 256, [3]).astype(np.uint8).tolist() for _ in range(len(class_names))]
net = cv2.dnn.readNet("darknet_cfg/yolov3-tiny.weights", "darknet_cfg/yolov3-tiny.cfg")
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_OPENCV)
model = cv2.dnn_DetectionModel(net)
model.setInputParams(size=(416, 416), scale=1/255, swapRB=True) # 入力サイズ,スケールファクター,チャンネルの順番(True:RGB,False:BGR)
while(1):
take_screenshot(rect, './imgs/tello.png') # take_screenshot関数の呼び出し
img_folder_path = './imgs'
file_list = os.listdir(img_folder_path)
for img_file in file_list:
if (img_file.endswith(".png")):
frame = cv2.imread(img_folder_path + '/' + img_file)
class_ids, confidences, boxes = model.detect(frame, CONFIDENCE_THRESHOLD, NMS_THRESHOLD)
person = None # 人が検出されたかどうか(None:検出されていない,(x,y,w,h):人のバウンディングボックス)
start_drawing = time.time()
for (class_id, confidence, box) in zip(class_ids, confidences, boxes):
class_name = class_names[class_id]
color = COLORS[class_id]
label = f"{class_name} : {confidence}"
cv2.rectangle(frame, box, color, 2)
cv2.putText(frame, label, (box[0], box[1] - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2)
# print(f'{class_name} : {box}')
if class_names[class_id] == 'person': # 検出された物体が人だった場合
x, y, h, w = box
if not person or person[2]*person[3] <= w*h: # バウンディングボックスの面積が大きければ更新
person = (x, y, w, h)
cv2.imshow('YOLOv3-tiny', frame)
os.remove(img_folder_path + '/' + img_file)
if person: # フレームから人が検出された場合
x, y, w, h = person # 人のバウンディングボックス
W, H = 976, 759 # 画像の横,縦の長さ
cx, cy = x+w/2, y+h/2 # バウンディングボックスの中心座標
dx = abs(cx-W/2) # バウンディングボックスの中心x座標と画像の中心x座標の差分
if cx < W/3: # 画像の左側に人がいる場合
# 左に進む
pg.keyDown('a')
sleep(0.2 + 0.1*(dx/W))
pg.keyUp('a')
elif cx > (W/3)*2: # 画像の右側に人がいる場合
# 右に進む
pg.keyDown('d')
sleep(0.2 + 0.1*(dx/W))
pg.keyUp('d')
if h*w < W*H/10:
pg.keyDown('w')
sleep(0.05)
pg.keyUp('w')
elif h*w > W*H/3:
pg.keyDown('s')
sleep(0.05)
pg.keyUp('w')
cv2.waitKey(1)
if img_file is None:
cv2.destroyAllWindows()
5. 全体ソースコード
これまでに紹介したドローン操作Partと物体検出Partがメインとなりますが、これらに受信したカメラ映像の表示やウィンドウ位置の調整などを加えた全体コードは以下の通りです。
全体コード
import time
import tellopy
import os
import cv2
import numpy as np
import pyautogui as pg
import win32gui
from pynput import keyboard
from PIL import ImageGrab
from time import sleep
from subprocess import Popen, PIPE
import threading
rect = None
auto = True
prev_flight_data = None
flight_data = None
video_player = None
def handler(event, sender, data, **args):
global prev_flight_data
global flight_data
global video_player
drone = sender
if event is drone.EVENT_FLIGHT_DATA:
if prev_flight_data != str(data):
print(data)
prev_flight_data = str(data)
flight_data = data
elif event is drone.EVENT_VIDEO_FRAME:
if video_player is None:
video_player = Popen(['mplayer', '-fps', '35', '-', 'libx264'], stdin=PIPE)
try:
video_player.stdin.write(data)
except IOError as e:
print("No video player")
print(e)
video_player = None
else:
print(f"event='{event.getname()}' data={data}")
def detect_object():
CONFIDENCE_THRESHOLD = 0.3
NMS_THRESHOLD = 0.4
class_names = []
with open("darknet_cfg/coco_classes.txt", "r") as f:
class_names = [cname.strip() for cname in f.readlines()]
COLORS = [np.random.randint(0, 256, [3]).astype(np.uint8).tolist() for _ in range(len(class_names))]
# print(COLORS)
# net = cv2.dnn.readNet("yolov3-tiny_face_best.weights", "yolov3-tiny_face.cfg")
net = cv2.dnn.readNet("darknet_cfg/yolov3-tiny.weights", "darknet_cfg/yolov3-tiny.cfg")
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_OPENCV)
model = cv2.dnn_DetectionModel(net)
model.setInputParams(size=(416, 416), scale=1/255, swapRB=True) # 入力サイズ,スケールファクター,チャンネルの順番(True:RGB,False:BGR)
global rect
while(1):
if not rect:
continue
# print(f'rect={rect}') # 画像の横,縦の長さをチェックする
take_screenshot(rect, './imgs/tello.png')
img_folder_path = './imgs'
file_list = os.listdir(img_folder_path)
for img_file in file_list:
if (img_file.endswith(".png")):
frame = cv2.imread(img_folder_path + '/' + img_file)
class_ids, confidences, boxes = model.detect(frame, CONFIDENCE_THRESHOLD, NMS_THRESHOLD)
person = None # 人が検出されたかどうか(None:検出されていない,(x,y,w,h):人のバウンディングボックス)
start_drawing = time.time()
for (class_id, confidence, box) in zip(class_ids, confidences, boxes):
class_name = class_names[class_id]
color = COLORS[class_id]
label = f"{class_name} : {confidence}"
cv2.rectangle(frame, box, color, 2)
cv2.putText(frame, label, (box[0], box[1] - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2)
# print(f'{class_name} : {box}')
if class_names[class_id] == 'person': # 検出された物体が人だった場合
x, y, h, w = box
if not person or person[2]*person[3] <= w*h: # バウンディングボックスの面積が大きければ更新
person = (x, y, w, h)
cv2.imshow('YOLOv3-tiny', frame)
os.remove(img_folder_path + '/' + img_file)
global auto
if not auto:
break
if person: # フレームから人が検出された場合
x, y, w, h = person # 人のバウンディングボックス
W, H = 976, 759 # 画像の横,縦の長さ
cx, cy = x+w/2, y+h/2 # バウンディングボックスの中心座標
dx = abs(cx-W/2) # バウンディングボックスの中心x座標と画像の中心x座標の差分
if cx < W/3: # 画像の左側に人がいる場合
# 左に進む
pg.keyDown('a')
sleep(0.2 + 0.1*(dx/W))
pg.keyUp('a')
elif cx > (W/3)*2: # 画像の右側に人がいる場合
# 右に進む
pg.keyDown('d')
sleep(0.2 + 0.1*(dx/W))
pg.keyUp('d')
if h*w < W*H/10:
pg.keyDown('w')
sleep(0.05)
pg.keyUp('w')
elif h*w > W*H/3:
pg.keyDown('s')
sleep(0.05)
pg.keyUp('w')
cv2.waitKey(1)
if img_file is None:
cv2.destroyAllWindows()
def take_screenshot(rect, image_path):
"""指定範囲rectのスクリーンショットを取得・保存する
"""
screenshot = ImageGrab.grab()
cropped_screenshot = screenshot.crop(rect)
cropped_screenshot.save(image_path)
def set_screen_position():
"""Mplayerのスクリーンの位置を左上に自動調節する
"""
global rect
while True:
try:
mplayer_app = win32gui.FindWindow(None, 'MPlayer - The Movie Player')
sleep(1)
win32gui.SetForegroundWindow(mplayer_app)
hwnd = win32gui.GetForegroundWindow()
l, t, r, b = win32gui.GetWindowRect(hwnd)
win32gui.MoveWindow(hwnd, 0, 0, r-l, b-t, True)
l, t, r, b = win32gui.GetWindowRect(hwnd)
rect = (l, t, r, b) # スクリーンショット範囲を示すグローバル変数rectの更新
print('Setting screen position done')
break
except:
continue
def main():
drone = tellopy.Tello()
drone.connect()
drone.start_video()
drone.subscribe(drone.EVENT_FLIGHT_DATA, handler)
drone.subscribe(drone.EVENT_VIDEO_FRAME, handler)
def on_press(key):
"""キーが押された時に呼ばれるコールバック
"""
print(f'{key} pressed')
speed = 25
if key in [keyboard.Key.esc, keyboard.Key.space]:
return
if key == keyboard.Key.tab:
drone.takeoff()
print("Take off")
elif key == keyboard.Key.backspace:
drone.land()
print("Land")
elif key == keyboard.Key.up: # 上昇
drone.up(speed)
elif key == keyboard.Key.down: # 下降
drone.down(speed)
elif key == keyboard.Key.left: # 左旋回
drone.counter_clockwise(speed)
elif key == keyboard.Key.right: # 右旋回
drone.clockwise(speed)
elif key.char == 'w': # 前方
drone.forward(speed)
elif key.char == 's': # 後方
drone.backward(speed)
elif key.char == 'a': # 左
drone.left(speed)
elif key.char == 'd': # 右
drone.right(speed)
else:
return
return False # 検知終了
def on_release(key):
"""キーが離された時に呼ばれるコールバック
"""
print(f'{key} release')
if key == keyboard.Key.esc: # escが押された場合
return False # 検知を終了する
if key == keyboard.Key.space:
global auto
auto = not auto
sleep(1)
return False
if key == keyboard.Key.tab:
drone.takeoff()
print("Take off")
elif key == keyboard.Key.backspace:
drone.land()
print("Land")
elif key == keyboard.Key.up: # 上昇
drone.up(0)
elif key == keyboard.Key.down: # 下降
drone.down(0)
elif key == keyboard.Key.left: # 左旋回
drone.counter_clockwise(0)
elif key == keyboard.Key.right: # 右旋回
drone.clockwise(0)
elif key.char == 'w': # 前方
drone.forward(0)
elif key.char == 's': # 後方
drone.backward(0)
elif key.char == 'a': # 左
drone.left(0)
elif key.char == 'd': # 右
drone.right(0)
else:
return
return False # 検知終了
while True:
with keyboard.Listener(
on_press=on_press,
on_release=on_release) as listener:
listener.join()
drone.quit()
if __name__ == '__main__':
t1 = threading.Thread(target=main)
t2 = threading.Thread(target=detect_object)
t3 = threading.Thread(target=set_screen_position)
t1.start()
t2.start()
t3.start()
t1.join()
t2.join()
t3.join()
threading.Threadを使ってマルチスレッド処理を行っていますが、並行処理でありPythonの仕様上それほど速くならないそうです。気になる方は以下の記事を参考にしてください。
Pythonの並列処理・並行処理をしっかり調べてみた - Qiita
ディレクトリ構造は以下の通りです。
C:.
│ main.py
│ requirements.txt
│
├─darknet_cfg
│ coco_classes.txt
│ yolov3-tiny.cfg
│ yolov3-tiny.weights
│
└─imgs
tello.png
GitHubにもアップロードしているので、ぜひご覧ください。
おわりに
1.7万円のトイドローンとリアルタイム物体検出アルゴリズムYOLOを使って、ヒトを自動追尾しながら映像を受信するプログラムを作ることができました(YouTubeにアップロードした動画も見てくれると嬉しいです)。
ヒトに限らず様々なクラスを検出したり、全く異なるアルゴリズムでドローンの次の行動を決定したりできるので、様々な場面に応用できると思います。
お気に入りの機能を付けてドローンプログラミングをお楽しみください!
[P.S.]
学生の私にとって1.7万円のドローンの購入は苦渋の決断でしたが、できることの可能性が広がったという意味では良い買い物だったと思います。