はじめに
皆さんは、教科書の要約がめんどくさいと思ったことはありませんか?
僕は、思ったことしかありません。
今回は、Python のキーワード抽出ライブラリを使って、
「要約で外してはいけないキーワードをどれだけ拾えるか」
を検証していきます。
あわよくば、毎週のように出る教科書の要約課題を (準)自動化 するのが目標です。
余談ですが、僕は最近 YouTuber を始めました。

【怠惰】教科書の要約がダルかったので自動でキーワード抽出してみた - YouTube
今回の内容をコミカル(?)に 5 分の動画にまとめたので、
記事をご覧になる前にご視聴いただけると幸いです。
0. 文章の準備
※ 詳しい手順は動画を参照してください
まずは、要約する文章(今回は計算機学の教科書)を準備します。
次に、要約したいページをスマホアプリでスキャンします。
(Adobe scanというアプリが綺麗に撮れてオススメです!)
それから、パソコンにアップロードしたPDFファイルを**文字起こし(OCR)**していきます。
色々なツールを試してみましたが、無料で最も精度が高かったのは、Google ドキュメントでした。
わずか 5 秒ほどで PDF の文書からテキストに変換されます。
後で使うので、txt ファイルとして保存しておいてください。
これで準備が整ったので、早速キーワード抽出をしていきましょう!
1. YAKE! によるキーワード抽出
YAKE! は Yet Another Keyword Extractor の略です。
【参考】GitHub - LIAAD/yake: Single-document unsupervised keyword extraction
読者をガッカリさせないように先に言っておくと、YAKE! では上手くキーワード抽出ができませんでした。お急ぎの方は 2. pke によるキーワード抽出をご覧ください。
1-1. Pythonでキーワードを抽出
YAKE! の処理の流れ
ソースコードは、
YAKE! によるキーワード抽出 | 株式会社AI Shift
という非常に分かりやすい記事を参考にさせていただきました。
import MeCab # pip install mecab
import re
from yake import KeywordExtractor # pip install yake
from yake.highlight import TextHighlighter
m = MeCab.Tagger("-Ochasen")
# 文章の前処理を行う関数
def sep_by_mecab(text):
return " ".join([t.split("\t")[0] for t in m.parse(text).split('\n')][:-2])
def text_pretrained(text):
array_text = []
for line in text.split('\n'):
if len(line)==0:
continue
sp_text = sep_by_mecab(line)
array_text.append(sp_text)
return "\n".join(array_text).replace("。", ".").replace("、", ",")
# 文字起こし済みのテキストファイルを読み込む
f = open('./textbook.txt', 'r', encoding='UTF-8')
text = f.read()
f.close()
# ライブラリに前処理したテキストを投げる
kw_extractor = KeywordExtractor(lan='ja', n=3, top=30) # 今回は 3-gram、上位 30 件のキーワードを表示
keywords = kw_extractor.extract_keywords(text=text_pretrained(text))
for keyword, score in keywords:
print(f'{keyword}: {score}')
1-2. HTMLでキーワードを強調する
キーワードの前後に HTML の <mark> タグを挿入して見やすくしました。
YAKE! にも、キーワードを探して前後に任意の文字列を挿入する TextHighlighter が用意されていたのですが、残念ながら英語にしか反応しませんでした…。
結局、正規表現モジュールの re を使って <mark> タグの挿入を行いました。
# 上の yake_test.py の続き
# ライブラリの蛍光ペン機能を使ってキーワードの前後に <mark> タグを挿入する
# 英語のキーワードにしか反応しなかった
# th = TextHighlighter(max_ngram_size= 3, highlight_pre = "<mark style='background-color:blue'>", highlight_post= "</mark>")
# print(th.highlight(text, keywords))
# 正規表現でキーワードの前後に <mark> タグを挿入して、HTML ファイルとして出力
f = open('./marked_textbook.html', 'w', encoding='UTF-8')
for keyword, score in keywords:
edited_keyword = re.sub(r"\s+", "", keyword) # キーワード中の空白を削除する
text = re.sub(edited_keyword, "<mark style='background-color:blue'>" + keyword + "</mark>", text)
f.write(text)
f.close()

「コンピュ」「できる」「という」「log」などといった謎のキーワードが上位に並んでしまい、うまくいきませんでした…。
(失敗の原因が分かる方、どなたか教えてください!)
2. pke によるキーワード抽出
pke は python keyphrase extraction の略です。
2-1. Pythonでキーワードを抽出
グラフベースのキーフレーズ抽出手法のアルゴリズムから、ライブラリ実行のソースコードまで解説されている
はじめての自然言語処理 pke によるキーフレーズ抽出 | オブジェクトの広場
という記事がとても分かりやすかったので、詳しく知りたい人は参考にしてください。
私は記事の通りに、ローカル環境に必要なライブラリをインストールしようとして失敗したので、Google Colaboratory で実行しました。
誰でも閲覧できるように公開しておいたので、ローカル環境へのインストールに失敗した人や今すぐ試したい人はぜひご利用ください。
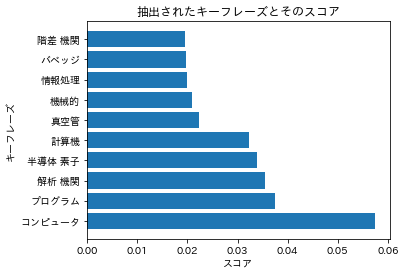
スコアが高ければ高いほど、重要度が高いことを示しています。
YAKE! を使った時よりも、重要そうなキーワードが抽出されました。
2-2. HTMLでキーワードに蛍光ペンを引く
【1-2】では、青色の <mark> タグを使ってキーワードを強調しましたが、いかにもベタ塗りという感じがして、見ていて気持ちが良いものではありません。蛍光ペンで引いたようにキーワードを目立たせるために、HTML の style 属性を使って直接 CSS を書き込みました。
また、どの部分が重要なのか一目で判別できるように、算出されたスコアに基づいて重要度別に色分けをしました。
import re
# 要約したいテキストファイルを読み込む
f = open('./textbook.txt', 'r', encoding='UTF-8')
text = f.read()
f.close()
##### ここに Google Colaboratory の実行結果を貼り付ける(ローカル環境の場合はリストに保存されているので不要) #####
keywords = [('コンピュータ', 0.05748433574453739),
('プログラム', 0.037497428085298705),
('解析 機関', 0.03545382390469013),
('半導体 素子', 0.033901752577436585),
('計算機', 0.03226897132380664),
('真空管', 0.022318020359036798),
('機械的', 0.02100199951461384),
('情報処理', 0.01986907044620832),
('バベッジ', 0.01971479670629982),
('階差 機関', 0.019580305856911506)] # 見やすさの都合上で少し表示を減らしました(30 → 10)
##### ここに Google Colaboratory の実行結果を貼り付ける(ローカル環境の場合はリストに保存されているので不要) #####
f = open('./marked_textbook.html', 'w', encoding='UTF-8')
for i, ks in enumerate(keywords):
keyword, score = ks
if 3*i < len(keywords): # 上位 1/3 は赤色のマーカー
color = "#ffcccc"
elif 3*i < 2*len(keywords): # 中位 1/3 は橙色のマーカー
color = "#ffcc99"
else: # 下位 1/3 は黄色のマーカー
color = "#ffffcc"
edited_keyword = re.sub(r"\s+", "", keyword)
text = re.sub(edited_keyword, f"<mark style='background:linear-gradient(transparent 50%, {color} 0%)'>" + edited_keyword + "</mark>", text)
# ページにタイトルをつける
f.write("""
<html>
<head>
<title>要約大好きクラブ</title>
<head>
<body>
<h1 style="padding: 1rem 2rem; color: #fff; border-radius: 10px; background-image: -webkit-gradient(linear, left top, right top, from(#f83600), to(#f9d423));background-image: -webkit-linear-gradient(left, #f83600 0%, #f9d423 100%);background-image: linear-gradient(to right, #f83600 0%, #f9d423 100%);">要約大好きクラブ</h1>
""")
f.write(text)
f.write("""
</body>
</html>
""")
f.close()

赤色が密集している部分は重要そうだと予想がつきます。橙色や黄色の部分はほとんどが具体例になっているので正しい判断をしているようです。数式の部分はしっかりと除外されています。
3. キーワード収集率の算出
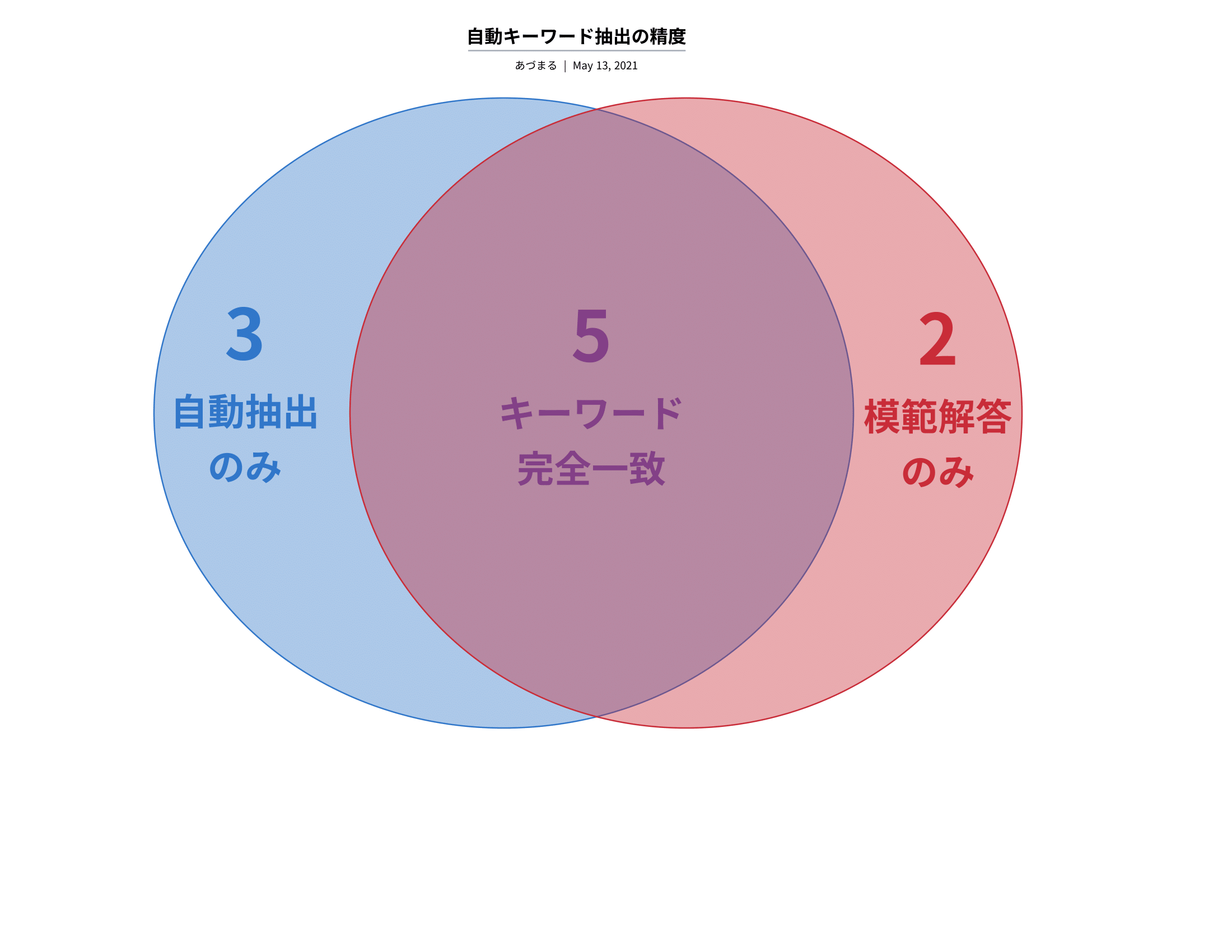
先生の模範解答の要約と比較したところ、上のベン図のような結果になりました。
(「模範解答のみ」の 2 つのキーワードのうち片方は、この教科書で独自に定義された言葉でした…)
なお、抽出されたキーワードとしては、スコア 0.25 以上のものをカウントしました。
この文章に限っての結果ですが、超重要キーワードのカバー率は71%でした。
おわりに
キーワードの分布を色別に可視化することで、要約すべき部分が一目で分かるようになりました。
あとは、重要なキーワードが密集している部分を切り抜いて、指定文字数に合うように加工すれば、教科書の要約課題は終了です。
完全自動とまではいきませんでしたが、【はじめに】で目標としていた (準)自動化 にはギリギリ到達できたと思います。