
はじめに
本記事は any Advent Calendar #2 「マルチテナントSaaSにおけるエンジニアリング大全」 Day19 の記事です。 弊社anyのアドベントカレンダーをひとつ丸ごと占有して、ひとりアドベントカレンダーとして、筆者の「マルチテナントSaaSのエンジニアリング」への経験をすべてアウトプットしていくカレンダーです。
今回はマルチテナントSaaSにおけるプロダクトのObservabilityについて紹介します。Day 16のログ管理で紹介したような事例を含むテナント識別の工夫をすることが重要になります。具体例があるほうが理解しやすいため、Qastにおける事例を多めに紹介をしたいとおもいます💪
マルチテナントのObservabilityを取り巻く環境
何度も言及するようですが、マルチテナント特有の問題は、データやリソースの分離戦略に大きく依存します。ノイジーネイバー問題もリソースを共有するプールモデルであるからこそ発生することになります。
従来の外形データの取得を含むモニタリングによる手法から、マイクロサービス化の進行とともにトレーシングなどの重要性が増してきました。そしてObservabilityという言葉自体は、2025年末時点では、OpenTelemetryなどのテレメトリーデータのフレームワークなども登場して、成熟期を迎えた印象があります。
マルチテナントという観点では、データ分離のモデルの選定に応じたモニタリング、あらゆるログにテナントを識別させる手法、コスト面などの可視性を高めることが非常に重要になります。
Qastにおける事例
QastではObservabilityにかかわる要件を可能な限り、Datadogに寄せるようにしています。そのいくつかを紹介しましょう。下記はおおまかなサービス構成図になります。
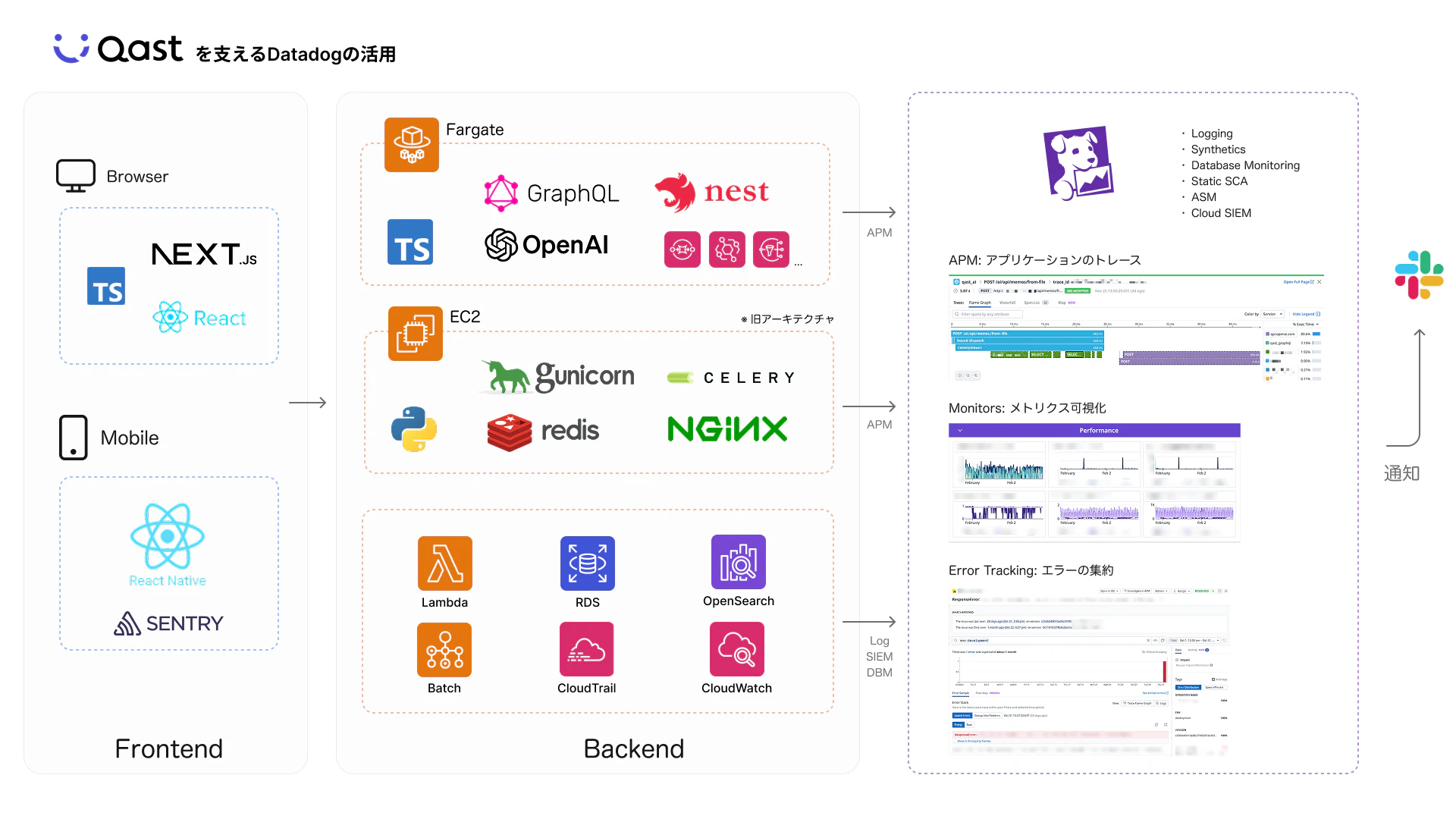
APMによるトレーシング
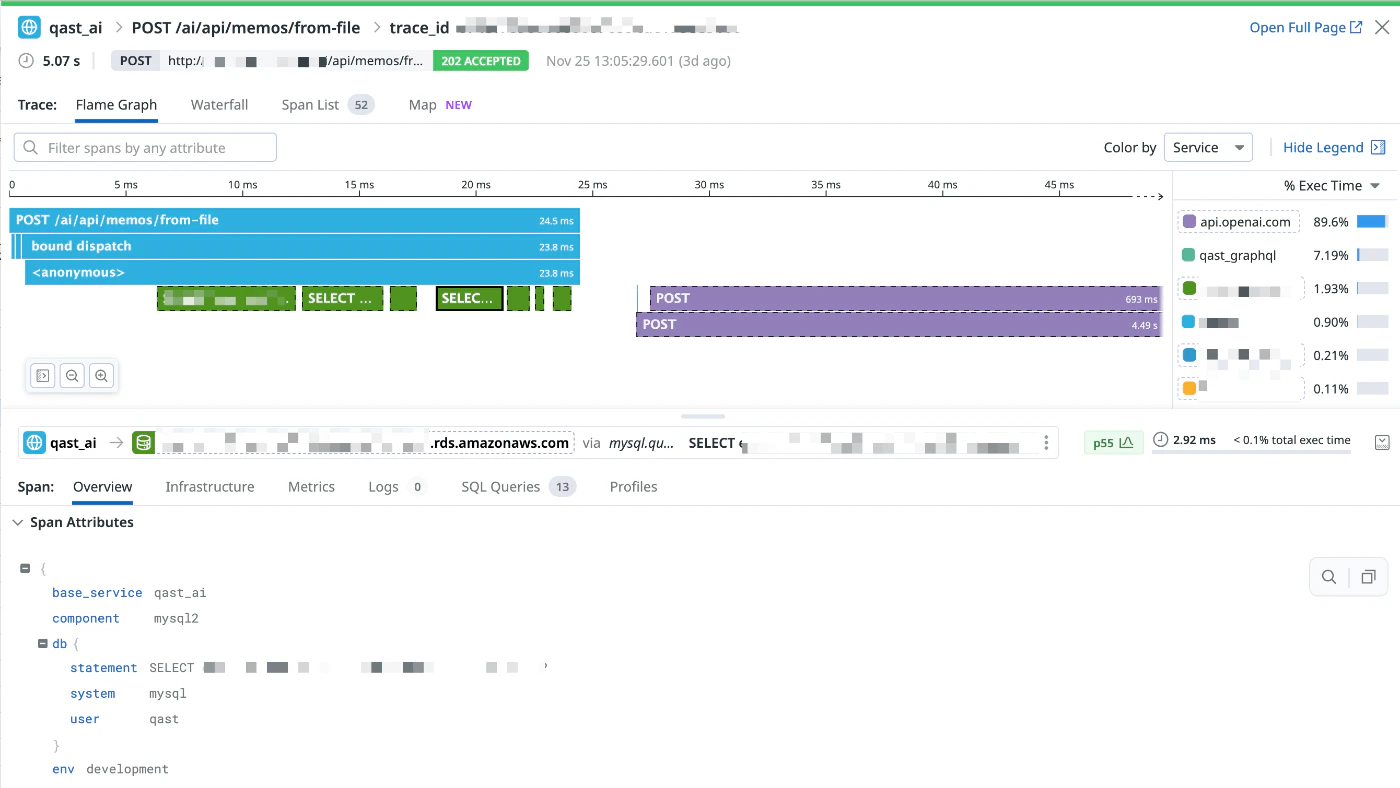
複数のマイクロサービスで構築されており、Datadog APM を利用したトレーシングの仕組みを導入しています。APMでは、HTTPリクエストからデータベースアクセス、外部API呼び出しまでを「Span」という単位で可視化しています。分散システムにおいても複数サービス間のトレースを接続することができ、サービス全体のパフォーマンスを把握できます。
データ分離戦略としても、基本的にはサブドメインでテナントごとに分かれているため、その値を利用することでテナント識別が可能になっています。
Error TrackingとSlack通知
Qastで発生したエラー通知は、Datadog Error Trackingを用いて、Slackのチャンネルへの通知されます。そこでチーム名(テナント名)を含めるようにして、テナントを識別できます。

個々のエラーすべてにすぐに反応できるわけではないのですが、顧客からの問い合わせとの紐付きを緩やかに発見できることがあります。テナント情報を含めることで、特定の顧客環境で発生している問題をすばやく判断することもできます🏄♂️
Loggingによるログ管理
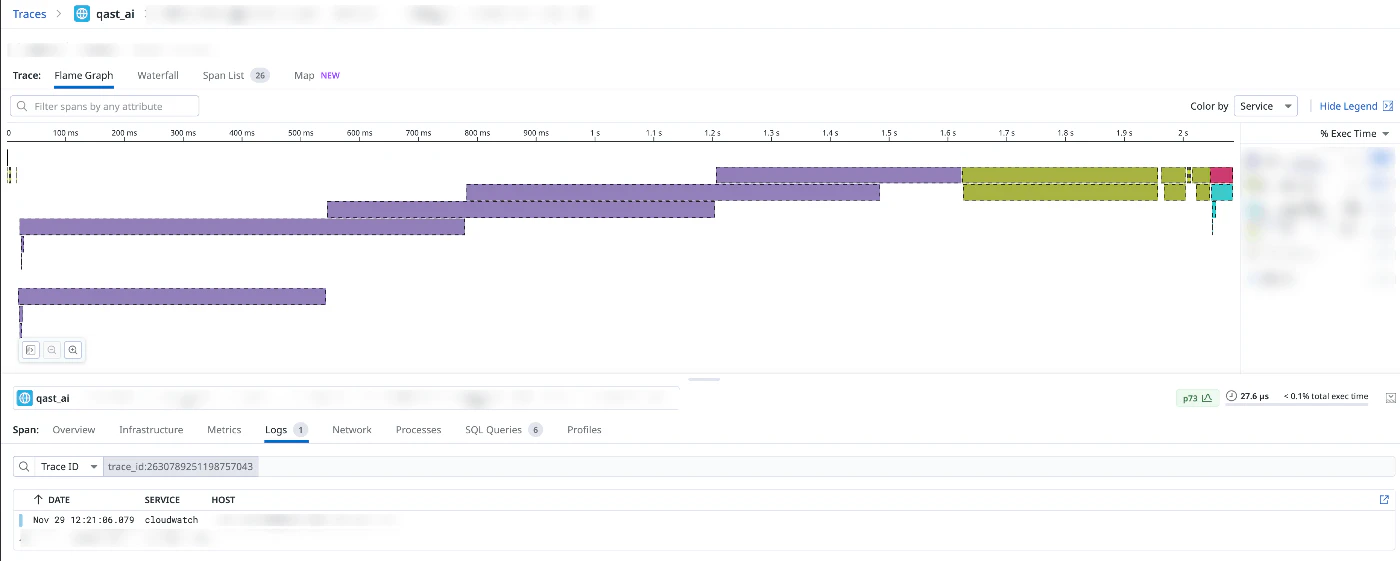
QastではCloudWatch LogsからDatadogへログを転送しています。また構造化ログへの自動パース機能(Log Pipeline)を利用することで、Gunicorn、nginxなどの非構造化ログにも対応しています。
トレースとログの相互参照が可能で、ログだけでは見えてこない情報を可視化できる点が大きなメリットです。マルチテナントSaaSにおいては、ログにテナント情報を含めることで、テナント単位での問題の切り分けが容易になります。
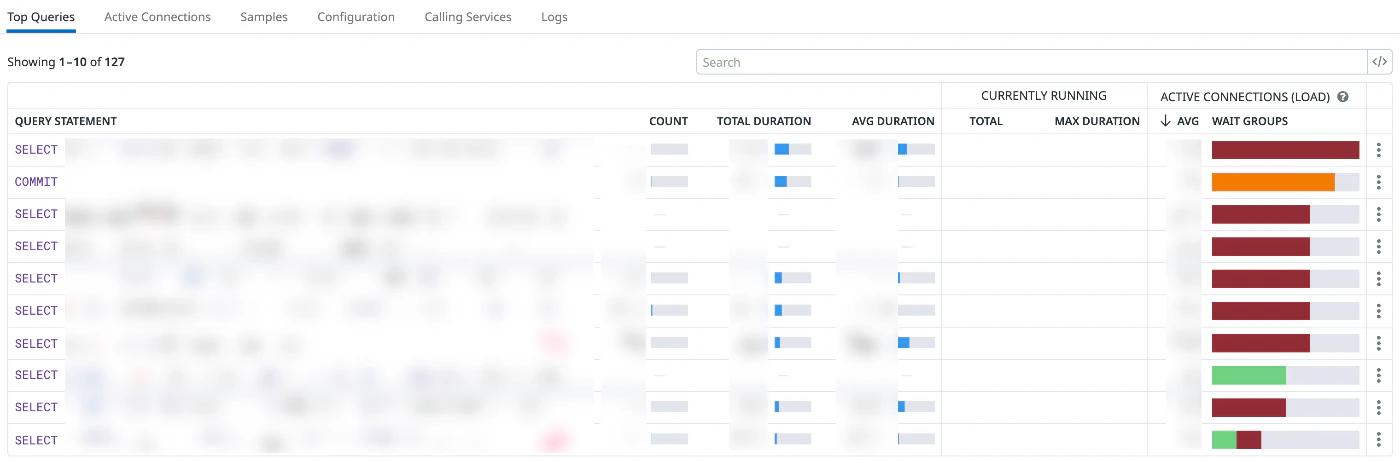
データベースのモニタリング
RDS上のデータベース監視のために、Datadog Database Monitoringを活用しています。CPU使用率、コネクション数、クエリ実行時間などのメトリクスを取得し、データベースのパフォーマンスを可視化しています。
実装例として、異常なクエリを検出してCPU使用率を削減したり、インスタンスタイプのダウンサイジングを実現したりするなど、具体的な成果を上げています。マルチテナントSaaSにおいては、特定のテナントによる過度なデータベース負荷を検出する際にも有効です。
さいごに
今回はQastの事例を中心に、マルチテナントにおけるObservabilityの一部の実例を紹介しました。正解のある領域ではないため、継続的な改善と試行錯誤が大切になります💪