1. はじめに
仕事の都合で DB/SQL の性能問題を調査する機会が少なくありませんが(決してメインの仕事ではないですが)、その中でよく出くわす問題の1つに「ぐるぐるSQL」(もしくは「ぐるぐる系」)といわれる、ループで大量の SQL 文を呼び出しているものがあります。
感覚ですが、私の周りでは OLTP 系システムの DB/SQL の性能問題の原因の割合は以下のように感じています。
- 30%:ぐるぐる SQL
- 20%:SQL 文の書き方が不適切
- 15%:索引がない or 不適切
- 15%:パーズが遅い
- 10%:データモデルがおかしい
- 10%:その他
(大昔は2番目 / 3番目がほとんどだったのですが、最近はなぜがぐるぐる SQL が多い…)
ぐるぐる SQL の実装では、ネットワーク通信や、アプリ側のクエリ生成 / 結果データ構築、DB 側のクエリ受信 / 結果送信といった、処理の本質的ではない部分のオーバーヘッドがボトルネックになりやすいです。そのため、ぐるぐる SQL による性能問題を改善するためには、DB 側の対応(索引作成など)や 局所的な SQL 文の修正だけでは難しく、アプリのコードに大きく手を加えないケースが多く、とても厄介です。
本記事では、ぐるぐる SQL がどの程度ひどい性能になるかということを実測で示したいと思います。この結果を見て、アプリ開発者の方がぐるぐる SQL をできるだけ避けようと思ってもらえれば幸いです。
記事の後半で、ぐるぐる SQL の改善案もいくつか示します。
今回のコードは以下にあります。
2. 題材の説明
今回は以下のような注文管理のデータモデルを使用します。
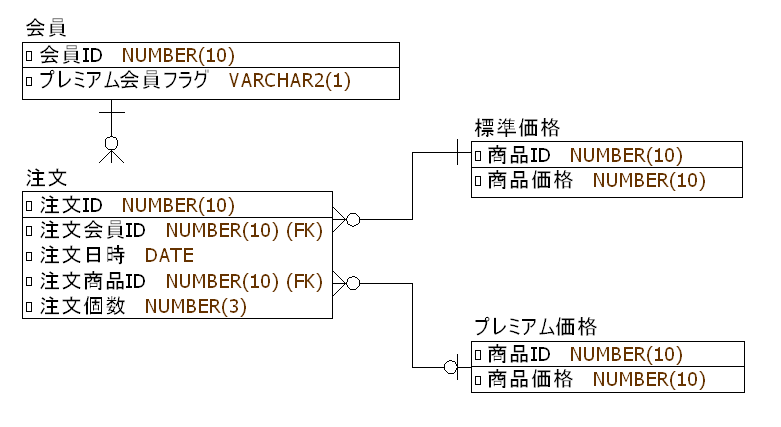
- 会員は通常会員とプレミアム会員の2種類がある。
- 会員は1回の注文あたり1種類の商品を複数個注文できる。
- 全ての商品には標準価格が設定されている。
- 商品の中にはプレミアム価格が設定されているものがある(すべての商品に設定されているわけではない)。
- プレミアム会員は、プレミアム価格が設定された商品をプレミアム価格で購入できる。プレミアム価格が設定されていない商品については、標準化価格での購入となる。
- 通常会員は、商品にプレミアム価格が設定されている/されていないに関わらず、標準価格での購入となる。
このようなケースで、ユーザーごとの購入金額を算出する処理を題材として考えてみたいと思います。
ポイントは、通常 / プレミアム会員ごとに参照すべきテーブルを切り替える必要があるため、集計処理を1本の SQL 文で書くには少し工夫が要ります。この辺りに慣れていないと、ぐるぐる SQL を実装してしまうケースが多いように思います。
3. 測定環境
- DB サーバー
- Amazon EC2 m5.xlarge (vCPU=4, メモリ=16GB)
- OS:CentOS 7
- RDBMS:Oracle Database 19c
- DB クライアント
- Amazon EC2 m5.xlarge (vCPU=4, メモリ=16GB)
- OS:Amazon Linux 2
- アプリ実装:Java 15 + MyBatis 3.5.6
DB サーバー / クライアントともに同じ VPC / サブネットに配置しています。
また、DB においては、会員 10 万件、注文 100 万件、プレミアム価格 10万件、標準価格 100万件のデータを準備しています。
また、今回の処理に必要な索引は作成済みです。
4. ぐるぐるSQL実装
顔をしかめたくなる実装ですが、今回は以下の流れで処理します。二重ループです。
- 全ての会員の情報を取得
- 会員ごとに以下の処理を実行(ループ)
3. 会員に紐付く全ての注文の情報を取得
4. 注文ごとに以下の処理を実施(ループ)
5. 会員がプレミアム会員であればプレミアム価格テーブルから注文の商品の価格を取得
6. 価格が取得できればそれを購入金額として集計し、次の注文に移る
7. 標準価格テーブルから注文の商品の価格を取得し、それを購入金額として集計
package loopSQL.logic;
import java.util.ArrayList;
import java.util.List;
import loopSQL.dto.Order;
import loopSQL.dto.SalesReportLine;
import loopSQL.mapper.SalesReportMapper;
import loopSQL.util.SessionBuilder;
public class SalesReport01 {
public List<SalesReportLine> getReportData() throws Exception {
// 集計結果を格納するリストを作成
var list = new ArrayList<SalesReportLine>();
// DB セッションと Mapper インスタンスの取得
var session = SessionBuilder.getInstance().getSession();
var mapper = session.getMapper(SalesReportMapper.class);
// 全会員の情報取得
var members = mapper.selectAllMembers();
// 会員ごとに購入金額を集計
for (var member : members) {
int totalAmount = 0;
// 会員の全注文を取得
var orders = mapper.selectOrders(member.getMemberId());
for (Order order : orders) {
// プレミアム会員かつプレミアム価格が設定されている場合、
// プレミアム価格で購入金額を計算する
if (member.getPremiumMemberFlag().equals("Y")) {
var price = mapper.selectPremiumPrice(order.getOrderItemId());
if (price != null) {
totalAmount +=
order.getOrderQuantity() * price.getItemPrice();
continue;
}
}
// 先の条件が満たされない場合、標準価格で購入金額を計算する
var price = mapper.selectStandardPrice(order.getOrderItemId());
totalAmount += order.getOrderQuantity() * price.getItemPrice();
}
list.add(new SalesReportLine(member.getMemberId(), totalAmount));
}
return list;
}
// 以下略
}
SQL文を記載した Mapper XML ファイルは以下の通りです。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="loopSQL.mapper.SalesReportMapper">
<select id="selectAllMembers" resultType="loopSQL.dto.Member">
SELECT -- selectAllMembers
member_id,
premium_member_flag
FROM
members
ORDER BY
member_id
</select>
<select id="selectOrders" resultType="loopSQL.dto.Order">
SELECT -- selectOrders
order_id,
order_member_id,
order_date,
order_item_id,
order_quantity
FROM
orders
WHERE
order_member_id = #{memberId}
ORDER BY
order_id
</select>
<select id="selectPremiumPrice" resultType="loopSQL.dto.Price">
SELECT -- selectPremiumPrice
item_id,
item_price
FROM
premium_prices
WHERE
item_id = #{itemId}
</select>
<select id="selectStandardPrice" resultType="loopSQL.dto.Price">
SELECT -- selectStandardPrice
item_id,
item_price
FROM
standard_prices
WHERE
item_id = #{itemId}
</select>
<!-- 以下略 -->
</mapper>
この実装で会員 10 万件の購入金額を集計する処理は 172.4 秒かかります。件数の割にはとても遅いですね。
ちなみに、各 SQL 文の DB 側実行に掛かっている時間は 15.3 秒しかありません(この情報は V$SQL から取得しています)。
| SQLクエリ | 実行回数 | 合計経過時間(秒) |
|---|---|---|
| members 全件取得 | 1 | 0.1 |
| orders の取得 | 100,000 | 2.8 |
| premium_prices の取得 | 330,021 | 3.7 |
| standard_prices の取得 | 614,053 | 8.7 |
この手のケースで、「アプリ側には手を入れたくないので DB 側で何とかなりませんか」と性能改善依頼を受けることもありますが、DB 側で時間が掛かっていない以上、DB 側だけでは何ともなりませんね。
5. 改善案
5-1. 理想的な方法(SQL文1本で完結)
今回の処理は、外部結合と CASE 文を活用すると、1本の SQL 文で実現できます。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="loopSQL.mapper.SalesReportMapper">
<!-- 略 -->
<select id="selectReportData" resultType="loopSQL.dto.SalesReportLine">
SELECT -- selectReportData
m.member_id member_id,
sum(CASE
WHEN m.premium_member_flag = 'Y' AND pp.item_id IS NOT NULL
THEN o.order_quantity * pp.item_price
ELSE o.order_quantity * sp.item_price
END
) total_amount
FROM
members m
INNER JOIN
orders o ON (m.member_id = o.order_member_id)
LEFT OUTER JOIN
premium_prices pp ON (o.order_item_id = pp.item_id)
INNER JOIN
standard_prices sp ON (o.order_item_id = sp.item_id)
GROUP BY
m.member_id
ORDER BY
m.member_id
</select>
<!-- 以下略 -->
</mapper>
この SQL 文を組み込んだ Java プログラムは 3.1 秒で処理を完了します。ぐるぐる SQL 実装の 55.6 倍高速になります(DB 内部での SQL 実行はパラレルクエリにはなっていません)。
上のような実装以外にも、プレミアム会員と通常会員を別の SQL 文で処理をして、結果を UNION ALL で連結するなどの方法もあると思います。
今回は処理要件がシンプルなので SQL 文1本で実現するのは難しくありません。ただし、実際の業務システムとなると条件分岐などが複雑になり、1本で完結することが困難なケースも多いです。
そこで次の節ではもう少し汎用的な改善策を講じてみたいと思います。
5-2. 次善策:データをキャッシュして SQL 文実行回数を減らす
多重ループの処理においては、一番内側のループ内処理が実行回数が一番多いため、大きくプログラムの構造を変えずに改善しようとすると、そこを修正することが近道になります。
以下は、二重ループの中で繰り返し実行されている SQL 文(プレミアム価格/標準価格テーブルへの SELECT)を取り除いた実装になります。ループの内部で毎回アクセスするのではなく、事前に2つのテーブルのデータを全件取得しキャッシュすることで、二重ループの内部では SQL 文を実行することを回避しています。
package loopSQL.logic;
import java.util.ArrayList;
import java.util.List;
import loopSQL.dto.Member;
import loopSQL.dto.Order;
import loopSQL.dto.SalesReportLine;
import loopSQL.mapper.SalesReportMapper;
import loopSQL.util.SessionBuilder;
public class SalesReport03 {
public List<SalesReportLine> getReportData() throws Exception {
var list = new ArrayList<SalesReportLine>();
var session = SessionBuilder.getInstance().getSession();
var mapper = session.getMapper(SalesReportMapper.class);
// 事前にプレミアム価格 / 標準価格テーブルのデータを全件取得しておく
var premiumPrices = mapper.selectAllPremiumPrices();
var standardPrices = mapper.selectAllStandardPrices();
var members = mapper.selectAllMembers();
for (Member member : members) {
int totalAmount = 0;
var orders = mapper.selectOrders(member.getMemberId());
for (Order order : orders) {
if (member.getPremiumMemberFlag().equals("Y")) {
// 注文ごとにプレミアム価格テーブルを参照するのではなく、
// 事前にキャッシュしたデータから取得する。
var price = premiumPrices.get(order.getOrderItemId());
if (price != null) {
totalAmount += order.getOrderQuantity() * price.getItemPrice();
continue;
}
}
// 注文ごとに標準価格テーブルを参照するのではなく、
// 事前にキャッシュしたデータから取得する。
var price = standardPrices.get(order.getOrderItemId());
totalAmount += order.getOrderQuantity() * price.getItemPrice();
}
list.add(new SalesReportLine(member.getMemberId(), totalAmount));
}
return list;
}
// 以下略
}
この実装だと、44.2 秒で処理が完了します。先の改善策よりは改善度合いが劣りますが、修正箇所が局所的なので、汎用的に適用しやすいテクニックです。注文テーブルに関してはまだ会員数の数だけ SQL 文で参照していますが、ここもキャッシュするとより高速になるかと思います。
ただ、この改善策は全データをアプリ側に持ってこないといけないため、データ件数とアプリ側のメモリの余裕を考慮しながら採用するか否かを判断することになると思います。
6. さいごに
今回は、DB の性能問題で良くある「ぐるぐる SQL」について、どの程度遅いのかというのを実測してみました。繰り返し大量の SQL 文を発行することのデメリットは明確ですね。
| 処理方式 | 処理時間(秒) |
|---|---|
| ぐるぐる SQL | 172.4 |
| SQL 文1本 | 3.1 |
| データキャッシュ | 44.2 |
「ループを使うな」とは言いませんが、その弊害は DB アクセスを行うアプリ開発者の方にはしっかりと認識していただければと思います。
実際には、複雑なロジックを伴う処理をぐるぐる SQL ではなく1本の SQL 文で実現するのは難しいケースもあり、実現できたとしても読みづらいコードになるなどの弊害があるケースもあります。ループで SQL 文を繰り返し実行するとは言っても、数十回(もしくは 100 回以上)程度の繰り返し実行ではそれほど大きな性能問題にはならないケースも多いので、性能 / 実現しやすさ / コードの読みやすさのバランスをとって処理ロジックを選択してもらえればと思います。
また、細かい処理をループで大量に繰り返し実行することで処理オーバーヘッドが性能問題を引き起こすケースはぐるぐる SQL だけではありません。
- マイクロサービスとかいって、REST API 呼び出しをループで大量に実行しようとする
- リアルタイム処理とかいって、ストリーム系サービスで1件ずつデータを処理しようとする
など、繰り返し処理をしてオーバーヘッドに足をすくわれるというケースは至る所にあるので、気を付けたいものですね。
(最後の数行は愚痴です。)