本記事では、Snowflake 上で Iceberg テーブルを作成し、そのテーブルに DuckDB から過去断面参照を含むクエリをしてみます。また、Iceberg テーブルを構成するファイルの内容や動きも確認してみます。
1. はじめに
Snowflake がオープンテーブルフォーマット(OTF)の1つである Iceberg に対応しました。Iceberg テーブルは標準化されたフォーマットでユーザー管理のクラウドストレージに保存されるため、Snowflake 仮想ウェアハウスを使わず他のツールやプラットフォームからアクセスできるようになりました。
(逆方向に他のツール・プラットフォームで作成した Iceberg テーブルを Snowflake からアクセスすることもできるので、正確にはデータを容易に共有できるようになったというのが正しいですが)
「Snowflake 使わなくても OK~」みたいなノリは個人的にはちょっと懐疑的なのですが、まずは何事も試してみてからかなと思い、今回は Snowflake で Iceberg テーブルを作成し、それに対して DuckDB からクエリを実行してみたいと思います。
また、クラウドストレージ上に作成された Iceberg テーブルを構成するメタデータファイル、マニフェストファイル、マニフェストリストの内容を確認し、Iceberg テーブルにデータ追加や更新をした際にどう変化するかも確認してみたいと思います。
利用する環境は以下になります。
- Snowflake : Standard @ AWS オレゴンリージョン
- Iceberg テーブルデータ保存先 : Amazon S3 @ オレゴンリージョン
- DuckDB : v1.1.3
Iceberg テーブルを作成する際は Iceberg カタログとして何を使うかが一つの選択肢になりますが、今回は Snowflake を Iceberg カタログとして使います。
2. Snowflake における Iceberg テーブルの作成
Snowflake で Iceberg テーブルを作成するには、その保存先である外部ボリュームを事前に作成しておく必要があります。この記事ではその手順は割愛しますが、以下に従って実行すれば容易に作成できます。
外部ボリュームを作成した後に、Iceberg テーブルを作成します。今回は Snowflake サンプルデータベースに含まれる TPC-H の1年分データの集計結果を元に作成します。
create or replace iceberg table order_summary_03 (
orderdate date,
custkey integer,
partkey integer,
total_quantity integer
)
catalog = 'SNOWFLAKE'
external_volume = 's2d_extvol'
base_location = 'order_summary_03'
as
select
o.o_orderdate,
o.o_custkey,
l.l_partkey,
sum(l.l_quantity)
from
snowflake_sample_data.tpch_sf10.orders o
inner join
snowflake_sample_data.tpch_sf10.lineitem l
on (o.o_orderkey = l.l_orderkey)
where
o.o_orderdate between '1992-01-01' and '1992-12-31'
group by all
通常のテーブルは Snowflake が管理するストレージに作成されますが、Iceberg テーブルの場合は外部ボリュームで指定したクラウドストレージ上に以下のように保存されます。
data/29/snow_daZCs6QrCnY_QgJZk-uqHRg_0_2_004.parquet
data/32/snow_daZCs6QrCnY_QgJZk-uqHRg_0_2_002.parquet
data/4b/snow_daZCs6QrCnY_QgJZk-uqHRg_0_2_014.parquet
data/91/snow_daZCs6QrCnY_QgJZk-uqHRg_0_2_012.parquet
data/aa/snow_daZCs6QrCnY_QgJZk-uqHRg_0_2_008.parquet
data/b5/snow_daZCs6QrCnY_QgJZk-uqHRg_0_2_016.parquet
data/ce/snow_daZCs6QrCnY_QgJZk-uqHRg_0_2_006.parquet
data/d2/snow_daZCs6QrCnY_QgJZk-uqHRg_0_2_010.parquet
metadata/snap-1737733020242000000-0c044641-7cfb-4912-8dc6-b82674527067.avro
metadata/1737733020242000000-_KjvHSbW7uN3sqLTP8uHvw.avro
metadata/00001-43b9bfdb-de7c-47c2-9048-7faad60b44f9.metadata.json
Iceberg テーブル作成直後に以下のクエリを実行します。(後で同じ意味のクエリを DuckDB から実行します)
select
min(orderdate),
max(orderdate),
count(*),
sum(total_quantity)
from
order_summary_03
結果

次に以下の INSERT を実行して半年分のデータを追加します。
insert into order_summary_03
select
o.o_orderdate,
o.o_custkey,
l.l_partkey,
sum(l.l_quantity)
from
snowflake_sample_data.tpch_sf10.orders o
inner join
snowflake_sample_data.tpch_sf10.lineitem l
on (o.o_orderkey = l.l_orderkey)
where
o.o_orderdate between '1993-01-01' and '1993-06-30'
group by all
先ほどと同じクエリを実行すると、以下の結果になります。(件数や合計値が増加しています)

また、次の UPDATE 文でデータを更新してみます。
update order_summary_03 t
set
t.total_quantity = t.total_quantity + f.total_quantity
from
(
select
o.o_orderdate orderdate,
o.o_custkey custkey,
l.l_partkey partkey,
sum(l.l_quantity) total_quantity
from
snowflake_sample_data.tpch_sf10.orders o
inner join
snowflake_sample_data.tpch_sf10.lineitem l
on (o.o_orderkey = l.l_orderkey)
where
o.o_orderdate between '1993-01-01' and '1993-06-30'
group by all
) f
where
t.orderdate = f.orderdate
and t.custkey = f.custkey
and t.partkey = f.partkey
先ほどと同じクエリを実行すると、以下の結果になります。(件数は変わりませんが、合計値は増えています)

3. DuckDB からの Iceberg テーブルへのクエリ実行
DuckDB には Iceberg テーブルを読み込むための拡張機能が提供されています。まずそれをインストールします。併せて、Iceberg テーブルが配置されている Amazon S3 にアクセスするための httpfs 拡張機能もインストールします。
install httpfs;
install iceberg;
load httpfs;
load iceberg;
次に Amazon S3 に接続するための設定を行います。
SET s3_region='us-west-2';
SET s3_endpoint='s3.us-west-2.amazonaws.com';
SET s3_access_key_id='<アクセスキー>';
SET s3_secret_access_key='<シークレットアクセスキー>';
これで Iceberg テーブルにクエリを実行する準備が整いました。
Iceberg テーブルは以下のようにメタデータファイルをトップとする構造になっています(図は Snowflake Quickstartsの Getting Started with Iceberg Tablesから抜粋)。DuckDB はこのメタデータファイル、もしくはそれが配置されているパスを指定して Iceberg テーブルを参照します。

今回の環境では、CREATE TABLE, INSERT, UPDATE を実行した結果、以下の3つのメタデータファイル(JSON形式)が作成されています。
-rw-r--r--. 1 mabe mabe 1836 1月 25 00:37 metadata/00001-43b9bfdb-de7c-47c2-9048-7faad60b44f9.metadata.json
-rw-r--r--. 1 mabe mabe 2529 1月 25 00:38 metadata/00002-8aaef21d-58a6-4d3a-937d-6558c26b719d.metadata.json
-rw-r--r--. 1 mabe mabe 3223 1月 25 00:45 metadata/00003-0c5a1785-ac40-480a-aab3-0f57932c9bd4.metadata.json
このうちの最新のメタデータファイルを指定して以下のクエリを実行してみます。
select
min(orderdate),
max(orderdate),
count(*),
sum(total_quantity)
from
iceberg_scan('s3://mabe-s2d-s3-iceberg/order_summary_03/metadata/00003-0c5a1785-ac40-480a-aab3-0f57932c9bd4.metadata.json');
結果は以下になり、2. で最後に実行したクエリの結果と一致しています。
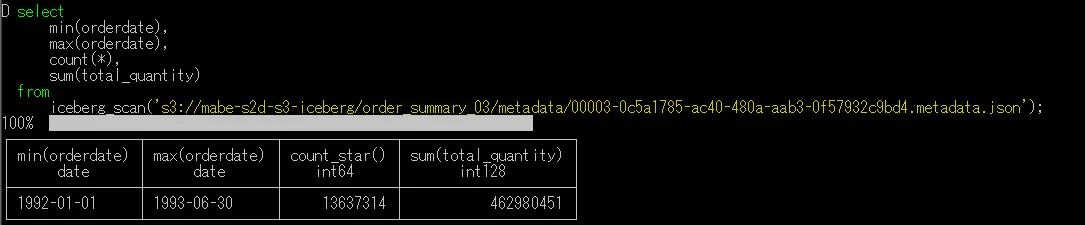
また、他のメタデータファイルを指定してクエリを実行すると結果は以下のようになり、テーブル作成直後、データ追加直後の過去断面データに対してクエリを実行できていることが分かります。


Iceberg の一般的な利用方法としては、使用すべきメタデータファイルがどれかを Iceberg カタログに問い合わせて取得するのですが、DuckDB は Iceberg カタログに未対応です。
4. Iceberg テーブルを構成するファイル
ここからは Iceberg テーブルを作成、データ追加、更新した際に、Iceberg テーブルを構成するファイルがどうなっているかを確認していきます。
まず、Iceberg テーブルを作成した直後は以下のファイルが作成されています。(一度 Linux 環境にダウンロードして ls で表示した結果を並び替えています)
-rw-r--r--. 1 mabe mabe 1836 1月 25 00:37 metadata/00001-43b9bfdb-de7c-47c2-9048-7faad60b44f9.metadata.json
-rw-r--r--. 1 mabe mabe 4215 1月 25 00:37 metadata/snap-1737733020242000000-0c044641-7cfb-4912-8dc6-b82674527067.avro
-rw-r--r--. 1 mabe mabe 7059 1月 25 00:37 metadata/1737733020242000000-_KjvHSbW7uN3sqLTP8uHvw.avro
-rw-r--r--. 1 mabe mabe 8698880 1月 25 00:37 data/29/snow_daZCs6QrCnY_QgJZk-uqHRg_0_2_004.parquet
-rw-r--r--. 1 mabe mabe 8702976 1月 25 00:37 data/32/snow_daZCs6QrCnY_QgJZk-uqHRg_0_2_002.parquet
-rw-r--r--. 1 mabe mabe 8702976 1月 25 00:37 data/4b/snow_daZCs6QrCnY_QgJZk-uqHRg_0_2_014.parquet
-rw-r--r--. 1 mabe mabe 8717824 1月 25 00:37 data/91/snow_daZCs6QrCnY_QgJZk-uqHRg_0_2_012.parquet
-rw-r--r--. 1 mabe mabe 8713728 1月 25 00:37 data/aa/snow_daZCs6QrCnY_QgJZk-uqHRg_0_2_008.parquet
-rw-r--r--. 1 mabe mabe 8706560 1月 25 00:37 data/b5/snow_daZCs6QrCnY_QgJZk-uqHRg_0_2_016.parquet
-rw-r--r--. 1 mabe mabe 8718336 1月 25 00:37 data/ce/snow_daZCs6QrCnY_QgJZk-uqHRg_0_2_006.parquet
-rw-r--r--. 1 mabe mabe 8706560 1月 25 00:37 data/d2/snow_daZCs6QrCnY_QgJZk-uqHRg_0_2_010.parquet
先ほど触れた通り、メタデータファイル metadata/00001-43b9bfdb-de7c-47c2-9048-7faad60b44f9.metadata.json がトップになるので、このファイルの中身を確認します。
{
"format-version" : 2,
"table-uuid" : "cb9aea37-1fe8-4b8f-8989-63761ad48ebf",
"location" : "s3://mabe-s2d-s3-iceberg/order_summary_03/",
"last-sequence-number" : 1,
"last-updated-ms" : 1737733020242,
"last-column-id" : 4,
"current-schema-id" : 0,
"schemas" : [ {
"type" : "struct",
"schema-id" : 0,
"fields" : [ {
"id" : 1,
"name" : "ORDERDATE",
"required" : false,
"type" : "date"
}, {
"id" : 2,
"name" : "CUSTKEY",
"required" : false,
"type" : "int"
}, {
"id" : 3,
"name" : "PARTKEY",
"required" : false,
"type" : "int"
}, {
"id" : 4,
"name" : "TOTAL_QUANTITY",
"required" : false,
"type" : "int"
} ]
} ],
"default-spec-id" : 0,
"partition-specs" : [ {
"spec-id" : 0,
"fields" : [ ]
} ],
"last-partition-id" : 999,
"default-sort-order-id" : 0,
"sort-orders" : [ {
"order-id" : 0,
"fields" : [ ]
} ],
"properties" : {
"format-version" : "2"
},
"current-snapshot-id" : 2332567356637016889,
"snapshots" : [ {
"sequence-number" : 1,
"snapshot-id" : 2332567356637016889,
"timestamp-ms" : 1737733020242,
"manifest-list" : "s3://mabe-s2d-s3-iceberg/order_summary_03/metadata/snap-1737733020242000000-0c044641-7cfb-4912-8dc6-b82674527067.avro",
"schema-id" : 0,
"summary" : {
"operation" : "append",
"manifests-kept" : "0",
"added-files-size" : "69667840",
"total-records" : "9117071",
"manifests-created" : "1",
"total-data-files" : "8",
"manifests-replaced" : "0",
"added-data-files" : "8",
"added-records" : "9117071",
"total-files-size" : "69667840"
}
} ],
"snapshot-log" : [ {
"snapshot-id" : 2332567356637016889,
"timestamp-ms" : 1737733020242
} ]
重要な点としては以下でしょうか。
-
schemasでテーブルスキーマの情報が定義されている -
snapshotsでスナップショット(断面)の情報を持つ(今回は1つですが)-
timestamp-mssでスナップショットの作成日時が分かる -
manifest-listで次に参照すべきマニフェストリストが指定されている
-
次に指定されているマニフェストリストの中身を確認してみます。これは AVRO ファイルであるため、以下の Python プログラムで確認します(こちらから持ってきています)。
import avro.io
import avro.datafile
import pprint
import json
import sys
with open(sys.argv[1], 'rb') as f:
reader = avro.datafile.DataFileReader(f, avro.io.DatumReader())
for data in reader:
pprint.pprint(data)
結果を以下に一部抜粋します。
{'added_files_count': 8,
'added_rows_count': 9117071,
'added_snapshot_id': 2332567356637016889,
'content': 0,
'deleted_files_count': 0,
'deleted_rows_count': 0,
'existing_files_count': 0,
'existing_rows_count': 0,
'manifest_length': 7059,
'manifest_path': 's3://mabe-s2d-s3-iceberg/order_summary_03/metadata/1737733020242000000-_KjvHSbW7uN3sqLTP8uHvw.avro',
'min_sequence_number': 1,
'partition_spec_id': 0,
'partitions': [],
'sequence_number': 1}
追加されたファイル数や行数、マニフェストファイルなどの情報が確認できます。
さらにマニフェストファイルの中身を確認します。
{'data_file': {'column_sizes': None,
'content': 0,
'equality_ids': None,
'file_format': 'PARQUET',
'file_path': 's3://mabe-s2d-s3-iceberg/order_summary_03/data/29/snow_daZCs6QrCnY_QgJZk-uqHRg_0_2_004.parquet',
'file_size_in_bytes': 8698880,
'key_metadata': None,
'lower_bounds': [{'key': 1, 'value': b'c\x1f\x00\x00'},
{'key': 2, 'value': b'\x02\x00\x00\x00'},
{'key': 3, 'value': b'\x02\x00\x00\x00'},
{'key': 4, 'value': b'\x01\x00\x00\x00'}],
'nan_value_counts': None,
'null_value_counts': [{'key': 1, 'value': 0},
{'key': 2, 'value': 0},
{'key': 3, 'value': 0},
{'key': 4, 'value': 0}],
'partition': {},
'record_count': 1138571,
'sort_order_id': 0,
'split_offsets': None,
'upper_bounds': [{'key': 1, 'value': b'\xd0 \x00\x00'},
{'key': 2, 'value': b'_\xe3\x16\x00'},
{'key': 3, 'value': b'\x80\x84\x1e\x00'},
{'key': 4, 'value': b'2\x00\x00\x00'}],
'value_counts': [{'key': 1, 'value': 1138571},
{'key': 2, 'value': 1138571},
{'key': 3, 'value': 1138571},
{'key': 4, 'value': 1138571}]},
'file_sequence_number': None,
'sequence_number': 1,
'snapshot_id': 2332567356637016889,
'status': 1}
{'data_file': {'column_sizes': None,
'content': 0,
'equality_ids': None,
'file_format': 'PARQUET',
'file_path': 's3://mabe-s2d-s3-iceberg/order_summary_03/data/32/snow_daZCs6QrCnY_QgJZk-uqHRg_0_2_002.parquet',
'file_size_in_bytes': 8702976,
'key_metadata': None,
'lower_bounds': [{'key': 1, 'value': b'c\x1f\x00\x00'},
{'key': 2, 'value': b'\x02\x00\x00\x00'},
{'key': 3, 'value': b'\x04\x00\x00\x00'},
{'key': 4, 'value': b'\x01\x00\x00\x00'}],
'nan_value_counts': None,
'null_value_counts': [{'key': 1, 'value': 0},
{'key': 2, 'value': 0},
{'key': 3, 'value': 0},
{'key': 4, 'value': 0}],
'partition': {},
'record_count': 1138727,
'sort_order_id': 0,
'split_offsets': None,
'upper_bounds': [{'key': 1, 'value': b'\xd0 \x00\x00'},
{'key': 2, 'value': b'_\xe3\x16\x00'},
{'key': 3, 'value': b'\x7f\x84\x1e\x00'},
{'key': 4, 'value': b'>\x00\x00\x00'}],
'value_counts': [{'key': 1, 'value': 1138727},
{'key': 2, 'value': 1138727},
{'key': 3, 'value': 1138727},
{'key': 4, 'value': 1138727}]},
'file_sequence_number': None,
'sequence_number': 1,
'snapshot_id': 2332567356637016889,
'status': 1}
...
長いので省略しますが、
- データを保持する Parquet ファイルのパス(複数)
- それぞれの Parquet ファイルの行数や各カラムの NULL の数、上限値/下限値の情報
が含まれていることが分かります。
Snowflake のマイクロパーティションは行数や各カラムの NULL の数、上限値/下限値をメタデータとして持っており、パーティションプルーニングなどの性能向上に活用いています。同様の情報がマニフェストリストにあることが分かります。実は Parquet ファイル自体にもこれらの情報は含まれるのですが、マニフェストファイルにこの情報があることで Parquet ファイルを個別に読まなくともプルーニングできるのではないかと思います。
ここまでのファイルの関連を整理すると、以下のようになります。

次に、半年分のデータを追加した場合は以下のようになりました(オレンジ色が追加されたファイル)。
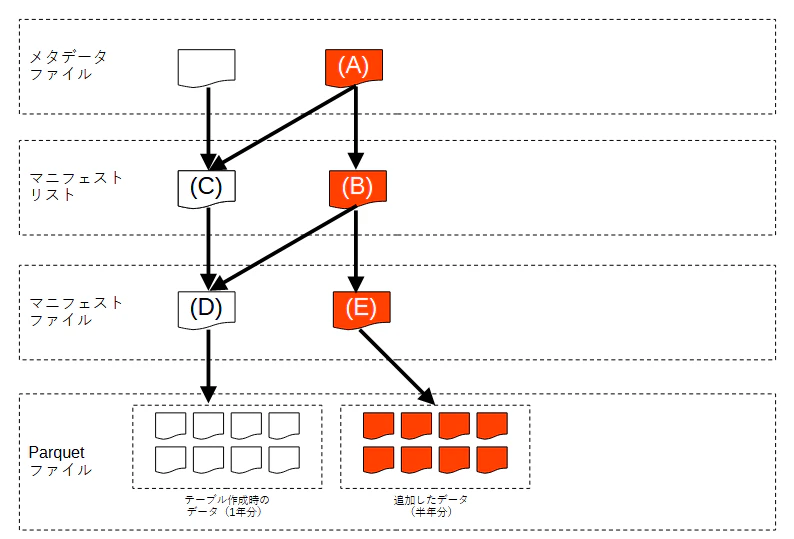
まず、新たにメタデータファイル (A) とマニフェストリスト (B) が1つずつ作成されています。新しいメタデータファイル (A) は新しいマニフェストリスト (B) に加え、以前のマニフェストリスト (C) へのリンクも保持しています。これにより、過去断面のデータを辿れるようにしているのではないかと思います。
また、一番下の Parquet ファイルに注目すると、新しいファイルが追加されています。これは追加した半年分のデータに相当します(ファイル数がテーブル作成時の1年分のデータと変わっていないですが、1ファイルあたりのサイズは 1/2 になっています)。
以前からあった1年分の Parquet ファイル(左の8個)と追加された半年分の Parquet ファイル(右の8個)をそれぞれまとめるマニフェストファイル (D) と (E) の両方をマニフェストリスト (B) が参照することで、全データを辿れるようになっているように想像できます。
最後に、データを更新した場合は以下のようになりました(オレンジ色が追加されたファイル)。
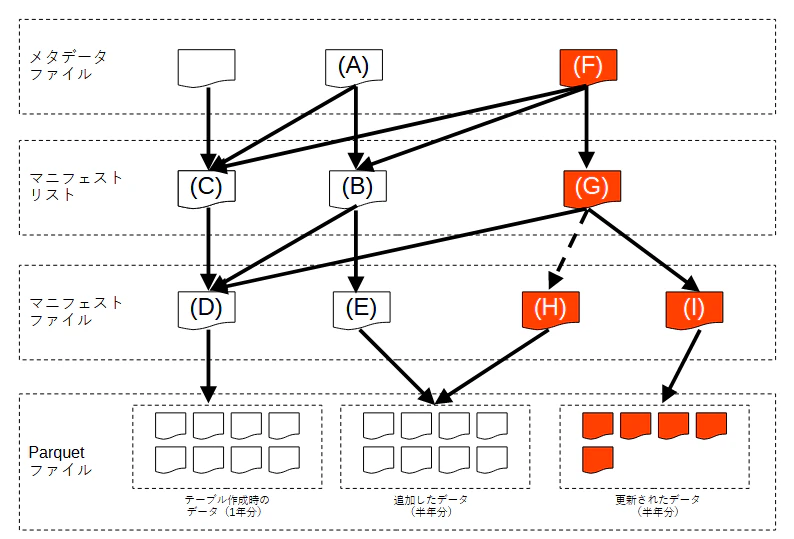
メタデータファイル (F) とマニフェストリスト (G) が1つずつ追加されるのは今までと変わらないですが、そこからの関連が異なります。
- マニフェストファイルは (H) と (I) の2つ作成されます
- (H) は更新前のデータの Parquet ファイルを指しています
- (I) は更新後のデータの Parquet ファイルを指しています(ファイル数が減っていますが、4MB×2 + 8MB×3となっておりデータサイの合計は同じです)
- マニフェストファイル (G) 上では、(H) について
'deleted_files_count': 8との記載があり、実際に有効なのは (D) と (I) のマニフェストファイルのみのようです
ここまでで、Iceberg テーブルの構成ファイルの動作が少しイメージできるようになった気がします(厳密には Iceberg の仕様を読まないといけないですが)。
ただ、最新のメタデータファイルは過去のマニフェストファイルへのリンクも持っているので、最新のメタデータファイルだけあれば過去断面のクエリは実行可能なような気もしますが、どうなんでしょうか?(DuckDB には特にどのマニフェストファイルを選ぶのかに影響しそうなオブションはなさそう)
おまけに、Iceberg テーブルのタイムトラベル期間が経過した後にどうなるかも確認します。今回の Iceberg テーブルのタイムトラベル期間は1日(Standard のデフォルト)に設定しているのですが、1日後には以下のようになりました。
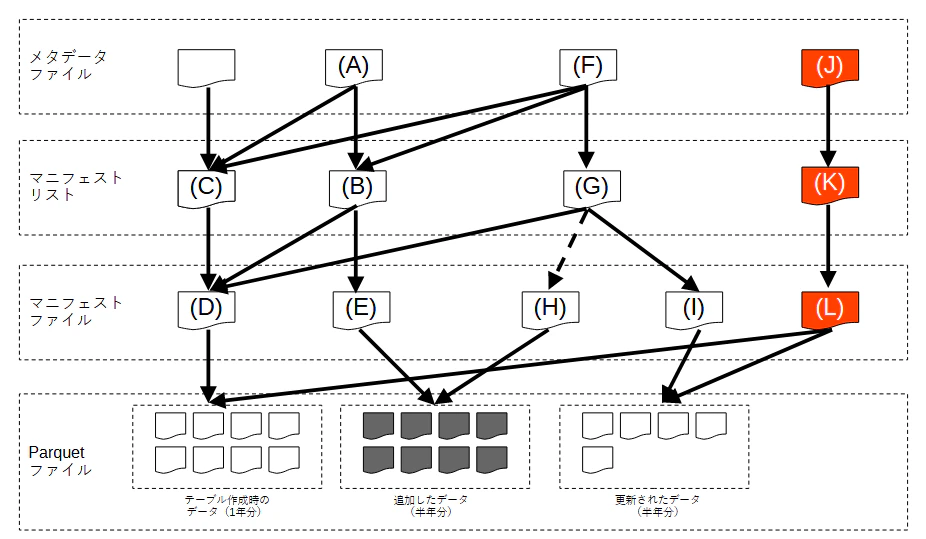
メタデータファイル (J) とマニフェストリスト (K) が1つずつ追加されるのは今までと同様ですが、違うポイントとして、
- メタデータリスト (J) はタイムトラベル期間を過ぎたマニフェストリスト (C), (B), (G) は参照しなくなった
- 最初に作成された Parquet ファイルと更新後の Parquet ファイルはまとめてメタデータファイル (L) が参照している(直前ではメタデータリスト (G) で分かれていた)
- タイムトラベル期間を過ぎたデータ(グレーの Parquet ファイル)は削除された(これらを参照しているマニフェストファイル (E) と (H) は残っている)
ということで、期間を過ぎたデータには問い合わせできなくなっていることが分かります。
4. まとめ
今回は
- Snowflake で Iceberg テーブルを作成し DuckDB からクエリを行う
- Iceberg テーブルの構成ファイルの動作を確認する
ということをしてみました。
面白いなと思ったのは、以下の3点です。
- メタデータファイルにスキーマ情報があり、DuckDB で定義が不要(Parquet 直アクセスの場合は必要)
- Snowflake マイクロパーティションのイミュータブルな仕組みと似ていること
- マニフェストリストに行数や最大値/最小値が含まれており、性能向上に有用そう
- 過去断面へのクエリ(タイムトラベル)も可能
また、DuckDB で過去断面のデータを参照する際は、この記事でやったように過去のメタデータファイルを指定するのではなく、最新のメタデータファイルから適切なマニフェストファイルを辿ってくれることが本来うれしいのですが、いずれできるようになるんでしょうか?
あと、今回触れませんでしたが、アクセス権管理や監査をどうするのか、クロスリージョン/クロスクラウドのケース(要は地域をまたいだデータ共有)をどうするのかなどは、私が関わったプロジェクトに Iceberg を導入する際には必要になるので、今後考えてみたいと思います。