はじめに
データウェアハウス(DWH)では、ユーザーによる分析クエリの高速化や複雑さ低減のために、明細データからKPIを事前に集計したデータマートを作成することが多く行われます。
以下に簡単な例を示します。ここでは、売上1件1件の明細データを持つ「売上明細」テーブルのデータから、日別×商品別の分析を容易にするために「日別売上サマリー」テーブルというデータマートを作成しています。
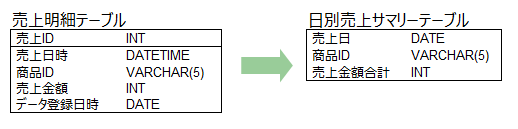
これを行う場合、売上明細テーブルにおいては日々データが増えていくため、増えた分の差分データをデータマート(ここでは「日別売上サマリー」テーブル)にどう反映していくかが課題になります。
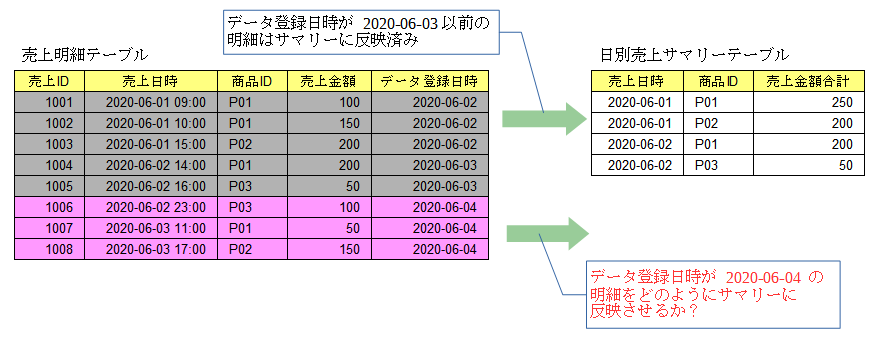
(ちなみに、このサンプルデータでは 売上ID=1006 は 2020/06/02 のデータなのですが、他の 2020/06/02 のデータより1日遅れて登録されています。こういうのをLate Arriving Dataといい、ETLを設計実装する際に考慮が必要になってきます。)
差分データをデータマートに反映させる戦略は大きく以下の2パターンに分かれます。
- UPSERT (INSERT + UPDATE)
- CTAS (CREATE TABLE AS SELECTによる洗い替え)
大規模DWHでは一般的に2番目のCTASの戦略が採用されるケースが多いですが、(1日分のデータ量ではなく)「売上明細」テーブル、「日別売上サマリー」テーブルのデータ保持期間が長くなるほど処理時間が掛かる傾向があります。その欠点を補うために
- パーティション単位でのCTAS
- CTAS + パーティション切り替え
という方法があります。本記事では、この4パターンの戦略を説明していきたいと思います。
ちなみに、本記事で例示するSQL文はSQL Server 2019 on Linuxで動作確認しています。
その1:UPSERT
「売上明細テーブル」の差分データを「日別売上サマリー」テーブルに、「あればUPDATE、なければINSERT」というアプローチで反映させる方法です。差分データを1件ずつループで処理するのは論外として、最近のDBMSでは「あればUPDATE、なければINSERT」を1つのSQL文で実行するためのMERGE文が用意されていることが多いです。
MERGE INTO [日別売上サマリー] AS t
USING (
SELECT
convert(DATE, [売上日時]) AS [売上日],
[商品ID],
sum([売上金額]) AS [売上金額合計]
FROM
[売上明細]
WHERE
[データ登録日時] = '2020/06/04'
GROUP BY
convert(DATE, [売上日時]),
[商品ID]
) AS f
ON (t.[売上日] = f.[売上日] AND t.[商品ID] = f.[商品ID])
WHEN MATCHED THEN
UPDATE SET t.[売上金額合計] = t.[売上金額合計] + f.[売上金額合計]
WHEN NOT MATCHED THEN
INSERT VALUES (f.[売上日], f.[商品ID], f.[売上金額合計]);
[データ登録日時] = '2020/06/04'の部分はインデックス or パーティション or Zone Mapが効いて該当データしか読み込まないと想像してください(SQL ServerにはZone Mapはないと思うけど)。
- メリット
- 比較的シンプルに実装できる。
- 差分データが少ない場合は比較的高速に処理できる。
- デメリット
- データ有無チェックやUPDATEの部分が(特に後者が)ランダムアクセスになりやすく、差分データが大量の場合は遅くなりやすい。
- 処理に掛かる時間が読みづらい。
その2:CTAS
CTASはCREATE TABLE .. AS SELECTの略で、DWHの領域では対象データを一度削除して全件洗い替えるという意味で使われます。実際にはTRUNCATE & INSERT .. SELECT ..で実装されることが多いです(IASという人もいますが、これも含めてCTASということの方が多いと思います)。
TRUNCATE TABLE [日別売上サマリー]
GO
INSERT INTO [日別売上サマリー]
SELECT
convert(DATE, [売上日時]) AS [売上日],
[商品ID],
sum([売上金額]) AS [売上金額合計]
FROM
[売上明細]
GROUP BY
convert(DATE, [売上日時]),
[商品ID]
GO
- メリット
- とてもシンプルに実装できる。
- フルスキャン&一括データロードなのでハードの性能が活かしやすい。
- DBMSの並列処理や高速ロード(OracleDBでいうダイレクトパスロード+NOLOGGING、SQL Serverでいう高速インサート+最小ログ記録)などの機能が活かしやすい。
- 処理にどれだけ時間が掛かるかがとても読みやすい。
- データ集計にミスなどがありデータマートを再集計する場合でも同じ処理で実現できる。
- デメリット
- 過去データも含めて再集計、データマートへのロードが発生するため、データ保持期間が長いと処理時間が延びる。
その3:パーティション単位のCTAS
CTASのデメリットを軽減するための方法になります。これをするためには[日別売上サマリー]テーブルをパーティション化しておく必要があります(DWHであれば普通パーティション化しますが)。
以下はパーティションテーブルの作成手順です。
CREATE PARTITION FUNCTION [PF_日別売上サマリー] (DATE)
AS RANGE LEFT FOR VALUES ('2020/06/01', '2020/06/02', '2020/06/03')
GO
CREATE PARTITION SCHEME [PS_日別売上サマリー]
AS PARTITION [PF_日別売上サマリー]
ALL TO ([PRIMARY])
GO
CREATE TABLE [日別売上サマリー] (
[売上日] DATE,
[商品ID] VARCHAR(5),
[売上金額合計] INT
) ON [PS_日別売上サマリー]([売上日])
GO
処理を開始する前に[日別売上サマリー]テーブルのどのパーティションに更新が必要かを確認するために、[売上明細]テーブル上の差分データをSELECTします。「はじめに」の章で記載したサンプルデータに対して以下のクエリーを実行すると '2020/06/02' と '2020/06/03' が返ってくるため、[日別売上サマリー]テーブルの2番目(=2020/06/02)と3番目(=2020/06/03)のパーティションに更新が必要なことが分かります。
SELECT
convert(DATE, [売上日時]) AS [売上日]
FROM
[売上明細]
WHERE
[データ登録日時] = '2020/06/04'
GROUP BY
convert(DATE, [売上日時])
(ちなみに、[売上日]のユニーク値を取得するためにDISTINCTではなくGROUP BYを使っているのは性能向上の良くあるテクニックです。SQL Serverで効くかは知りませんが、OracleやRedshiftでは効きます。)
[日別売上サマリー]テーブルの2番目のパーティションのデータ(=2020/06/02のデータ)を更新するために、2番目のパーティションのデータをTRUNCATE⇒INSERT SELECTによるデータ再作成を行います。
TRUNCATE TABLE [日別売上サマリー] WITH (PARTITIONS (2))
GO
INSERT INTO [日別売上サマリー]
SELECT
convert(DATE, [売上日時]) AS [売上日],
[商品ID],
sum([売上金額]) AS [売上金額合計]
FROM
[売上明細]
WHERE
'2020/06/02 00:00' <= [売上日時]
AND [売上日時] < '2020/06/03 00:00'
GROUP BY
convert(DATE, [売上日時]),
[商品ID]
GO
同様に3番目のパーティションに対してもTRUNCATE⇒INSERT SELECTをすれば完成です。
- メリット
- CTAS戦略[売上明細]テーブル、[日別売上サマリー]テーブルともに、差分データが関係する売上日のデータしか処理しないため、処理時間がデータ保持期間に依存しない。
- デメリット
- 若干実装が面倒くさい。
- 上記の例だとすでに集計済みの 2020/06/02 の売上明細データも再集計が必要。
- SQL Serverだと、INSERT先が空テーブルではないため、高速インサートは無効になることがある(上のケースではそもそも高速インサートはしようとしていないですが)。
その4:CTAS + パーティション切り替え
その3のパーティション単位CTASのデメリットの内、2番目と3番目に対応するためには、パーティション切り替えの機能を利用します。
まず、2番目のパーティションの更新後のデータを投入するための一時的なテーブル「日別売上サマリー_Temp」を「日別売上サマリー]テーブルと同じ構成で作成します(DBMSが提供している一時テーブルではありません)。
CREATE TABLE [日別売上サマリー_Temp] (
[売上日] DATE,
[商品ID] VARCHAR(5),
[売上金額合計] INT
) ON [PS_日別売上サマリー]([売上日])
その後、2番目のパーティション用のデータを作成した一時的なテーブルに投入します。その3のパーティション単位のCTASと異なるのは、、[売上明細]テーブルからは差分データのみを読み込んでいることです。代わりに[日別売上サマリー]テーブルの '2020/06/02' 分の集計済みデータを読んでいますが、こちらは集計済みのため件数が少なく、より高速に処理ができます。
INSERT INTO [日別売上サマリー_Temp]
SELECT
a.[売上日],
a.[商品ID],
sum(a.[売上金額合計])
FROM
(
SELECT
[売上日],
[商品ID],
[売上金額合計]
FROM
[日別売上サマリー]
WHERE
[売上日] = '2020/06/02'
UNION ALL
SELECT
convert(DATE, [売上日時]) AS [売上日],
[商品ID],
sum([売上金額]) AS [売上金額合計]
FROM
[売上明細]
WHERE
[データ登録日時] = '2020/06/04'
AND '2020/06/02 00:00' <= [売上日時]
AND [売上日時] < '2020/06/03 00:00'
GROUP BY
convert(DATE, [売上日時]),
[商品ID]
) a
GROUP BY
a.[売上日],
a.[商品ID]
その後、「日別売上サマリー」テーブルと「日別売上サマリー_Temp」テーブルの2番目のパーティションを入れ替えます。SQL Serverは入れ替え対象のパーティションは空である必要があるので事前にTRUNCATEしてからパーティション入れ替えを実行します。(この制約がなぜあるのかはよくわかりません。OracleDBだと空でなくとも問題なく切り替えできるのですが…)
TRUNCATE TABLE [日別売上サマリー] WITH (PARTITIONS (2))
GO
ALTER TABLE [日別売上サマリー_Temp]
SWITCH PARTITION 2 TO [日別売上サマリー] PARTITION 2
GO
あとは '2020/06/03' のデータも同様に作成すれば完了です。
- メリット
- [売上詳細]テーブルは差分データのみを読むため、処理が高速。
- デメリット
- 実装がかなり面倒くさい。
さいごに
DWHのデータマート更新における以下の4パターンの戦略を例示しました。
- UPSERT
- CTASによる全件洗い替え
- パーティション単位でのCTAS
- CTAS + パーティション切り替えの組み合わせ
基本、下に行くほど高速になります。ただ、4.の方法は結構実装が手間なので、よほどデータ量が多くなければ3.の方法でマート更新処理がバッチウィンドウに収まることを祈ることが多いかなと思います。
ちなみに、Amazon RedshiftやIBM PureData System for Analytics(旧Netezza)などパーティション機能を持たないDBMSだと1.と2.しか選択肢がないので注意が必要です。(ハードパワーに物を言わせて解決できるケースも多いのでNGというわけではありませんが)