沢山のディレクトリにある沢山のファイルの一覧を取得する時のお話
あるところに400ディレクトリの中に計52万ファイルがありました。一個一個見ていくのは残りの人生が何年あっても足りません。どうしたものかと悩んだおじいさんはNode.jsなんだからasyncの並行処理が良いねと言いました。でも、おばあさんはworker_threadで並列処理の方が絶対早いよと言うのです。
そこで、おじいさんとおばあさんは、どっちが速いのか競争することにしました。
勝負は10回勝負。並列数(nParallel)と並行数(nConcurrences)を1から51まで変化させた時の全てのディレクトリにある全てのファイルのパスをメインスレッドにメッセージとして返すのに要する時間を計測します。48コアのCPU環境で対象ファイルはネット越しにマウントしているディレクトリにあります。並行数と並列数は1~51までとし、ディレクトリを単位として仕事を分割します。また並行数と並列数の組み合わせのうち、ディレクトリ数(400)を超えるものは無視します。
実装
import { Worker, workerData, parentPort, isMainThread } from 'worker_threads'
import { fileURLToPath } from 'url';
import fs from 'fs';
import path from 'path';
import async from 'async';
const nParallels = [1, 6, 11, 16, 21, 26, 31, 36, 41, 46, 51];
const nConcurrences = [1, 6, 11, 16, 21, 26, 31, 36, 41, 46, 51];
const nDirectory = 400;
const nLoop = 10;
//このディレクトリ以下に400のディレクトリがあり計52万のファイルが存在しています
const targetDir = '/target/directory/';
if (isMainThread) {
for (const nParallel of nParallels) {
for (const nConcurrence of nConcurrences) {
if (nParallel * nConcurrence > nDirectory) { continue; }
console.time(nParallel + ' para/ ' + nConcurrence + ' conc');
for (let c = 0; c < nLoop; c++) {
const dirents = await fs.promises.readdir(targetDir, { withFileTypes: true });
let directories = await async.reduce(dirents, [], async (memo, dirent) => {
if ((dirent.isDirectory())) {
memo.push(path.join(targetDir, dirent.name));
}
return memo;
});
//console.log("total", directories.length, "directories");
let directoryChunks = await async.reduce(directories, [[]], async (memo, directory) => {
if (memo[memo.length - 1].length >= nConcurrence) {
memo.push([]);
}
memo[memo.length - 1].push(directory);
return memo;
});
let nFile = 0;
await async.eachOfLimit(directoryChunks, nParallel, async (directoryChunk) => {
return new Promise((resolve, reject) => {
const worker = new Worker(fileURLToPath(import.meta.url), { workerData: { 'directoryChunk': directoryChunk } });
worker.on('message', (message) => {
nFile += message.length;
});
worker.on('exit', () => {
resolve();
});
});
});
//console.log("total", nFile, "files");
}
console.timeEnd(nParallel + ' para/ ' + nConcurrence + ' conc');
}
}
} else {
await parentPort.postMessage(
await async.reduce(workerData.directoryChunk, [], async (memo, directory) => {
const files = await async.map(
await async.filter(
await fs.promises.readdir(directory, { withFileTypes: true }),
async (dirent) => {
return dirent.isFile;
}
),
async (dirent) => {
return path.join(directory, dirent.name);
}
)
return memo.concat(files);
})
);
}
実装解説
実装としては、まずメインスレッドで対象ディレクトリのサブディレクトリを持ってきます。
const dirents = await fs.promises.readdir(targetDir, { withFileTypes: true });
let directories = await async.reduce(dirents, [], async (memo, dirent) => {
if ((dirent.isDirectory())) {
memo.push(path.join(targetDir, dirent.name));
}
return memo;
});
このサブディレクトリリストを並列実行数毎のチャンクにします。
let directoryChunks = await async.reduce(directories, [[]], async (memo, directory) => {
if (memo[memo.length - 1].length >= nConcurrence) {
memo.push([]);
}
memo[memo.length - 1].push(directory);
return memo;
});
このチャンク毎にasync.eachLimitを使って、Workerを起動します。asyncLimitは配列を非同期処理してくれるのですが、並行実行数(limit)を設定できる便利な関数です。ここではnParallelを設定してます。この関数は並行実行されますが、この中でWorkerを起動することで、nParallelに設定された数のスレッドが立ち上がり、並列実行されます。
await async.eachOfLimit(directoryChunks, nParallel, async (directoryChunk) => {省略...
Workerは割り当てられたチャンク(中には並行実行数分のディレクトリパスを保持)を、並行実行で走査し、各ディレクトリのファイル一覧を得てメインスレッドにメッセージとして通知します。asyncfilterで
await async.reduce(workerData.directoryChunk, [], async (memo, directory) => {
const dirents = await fs.promises.readdir(directory, { withFileTypes: true });
const files = await async.map(
await async.filter(省略...
結果(10回の処理時間の平均)
という訳で、実験結果。
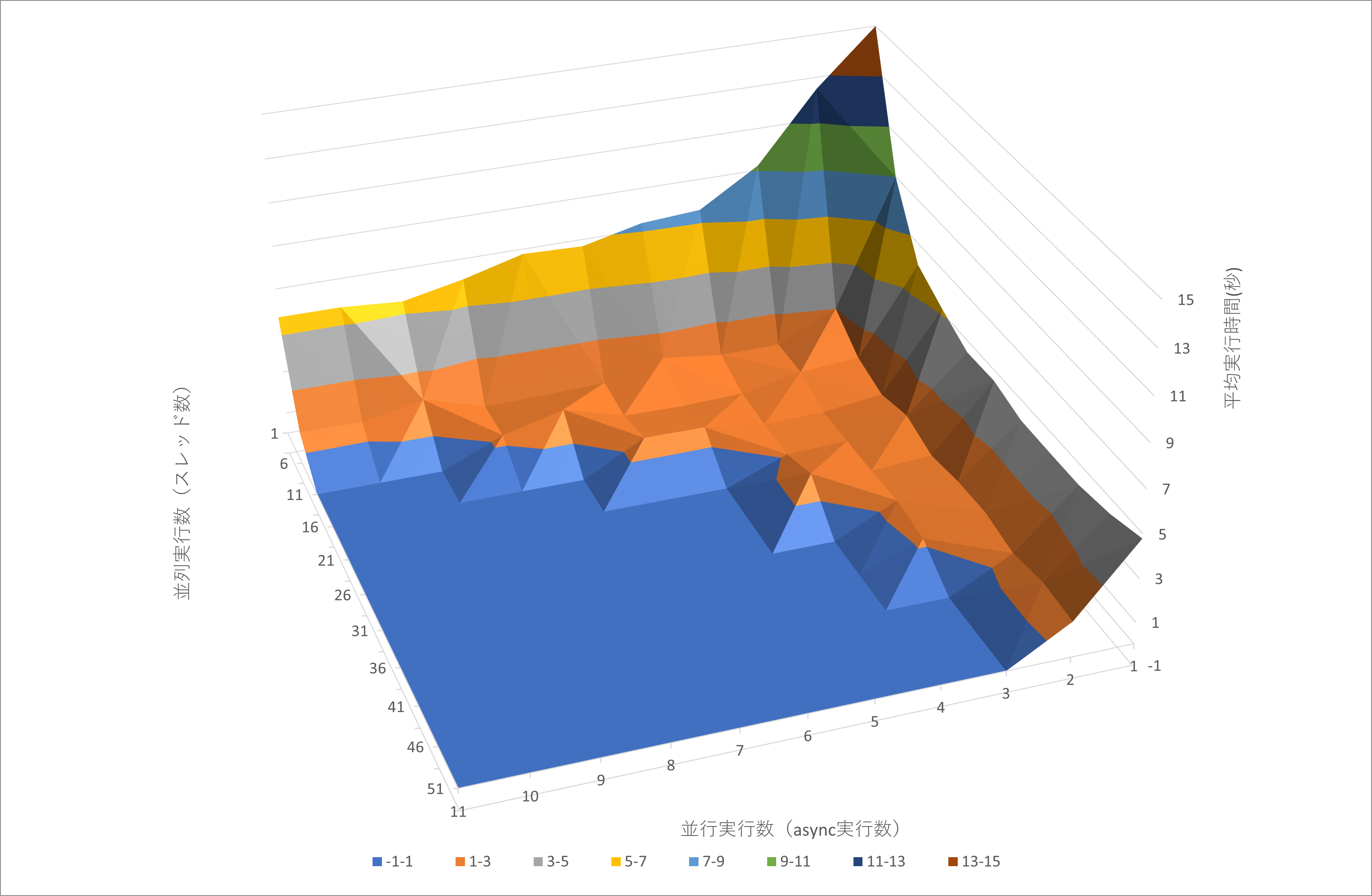
縦横軸がそれぞれ並列実行数、並行実行数です。高さ方向に平均処理時間をプロットしていますが、並列数1×並行数1のところが飛びぬけて遅い(約45秒)ので、縦軸最大値は15秒として、全体的な傾向が見えやすいようにしてます。
この図からわかる事は、並列実行数だけ、並行実行数だけを増やしても、絶対的な速さは得られない事がわかります。一方で、どっちが効くかというと、このタスクでは、あまり差異はなさそうです。
以下、あまり意味はないですが、早い順に並べてみました。スレッド数11の並行実行数21が最速です。CPUのコア数が48ですから、そこまで達していない事を見ると、どこか(IO?)がサチってますね。
| 順位 | スレッド数 | 並行実行数 | 平均処理時間 (秒) |
|---|---|---|---|
| 1 | 11 | 21 | 1.0829 |
| 2 | 16 | 16 | 1.0939 |
| 3 | 21 | 16 | 1.1118 |
| 4 | 11 | 26 | 1.1245 |
| 5 | 11 | 16 | 1.1663 |
| 6 | 36 | 11 | 1.1678 |
| 7 | 16 | 11 | 1.1767 |
| 8 | 6 | 36 | 1.1891 |
| 9 | 6 | 31 | 1.2187 |
| 10 | 21 | 11 | 1.2265 |
| 11 | 11 | 36 | 1.2314 |
| 12 | 26 | 11 | 1.2712 |
| 13 | 6 | 26 | 1.32 |
| 14 | 31 | 11 | 1.3881 |
| 15 | 26 | 6 | 1.4649 |
| 16 | 6 | 46 | 1.4758 |
| 17 | 16 | 21 | 1.4839 |
| 18 | 41 | 6 | 1.4896 |
| 19 | 6 | 51 | 1.5072 |
| 20 | 16 | 26 | 1.5093 |
| 21 | 16 | 6 | 1.5127 |
| 22 | 51 | 6 | 1.6431 |
| 23 | 6 | 16 | 1.6807 |
| 24 | 26 | 16 | 1.6892 |
| 25 | 6 | 11 | 1.6996 |
| 26 | 11 | 11 | 1.7192 |
| 27 | 31 | 6 | 1.734 |
| 28 | 46 | 6 | 1.7847 |
| 29 | 36 | 6 | 1.8176 |
| 30 | 11 | 6 | 1.9193 |
| 31 | 21 | 6 | 1.9321 |
| 32 | 11 | 31 | 1.9454 |
| 33 | 6 | 21 | 2.0346 |
| 34 | 6 | 41 | 2.0399 |
| 35 | 6 | 6 | 3.0052 |
| 36 | 36 | 1 | 4.0687 |
| 37 | 41 | 1 | 4.0759 |
| 38 | 31 | 1 | 4.0844 |
| 39 | 46 | 1 | 4.3219 |
| 40 | 21 | 1 | 4.4535 |
| 41 | 26 | 1 | 4.5095 |
| 42 | 51 | 1 | 4.7892 |
| 43 | 16 | 1 | 5.1709 |
| 44 | 1 | 41 | 5.4326 |
| 45 | 1 | 46 | 5.6377 |
| 46 | 1 | 51 | 5.6491 |
| 47 | 11 | 1 | 5.9967 |
| 48 | 1 | 36 | 6.0155 |
| 49 | 1 | 26 | 6.674 |
| 50 | 1 | 31 | 6.7652 |
| 51 | 1 | 21 | 7.3284 |
| 52 | 1 | 16 | 7.5211 |
| 53 | 6 | 1 | 8.9749 |
| 54 | 1 | 11 | 9.2236 |
| 55 | 1 | 6 | 12.4572 |
| 56 | 1 | 1 | 44.0639 |
結論
結局のところ並列実行も並行実行も大切だという事がわかって、おじいさんとおばあさんは末永く仲良く暮らしましたトサ。
めでたしめでたし。