仮想環境でちょっとしたデータベース作業を行う際に、久しぶりにphpMyAdminを使いました。
久しぶり過ぎて、何か所か行き詰ってしまったところがあったので、既出のものばかりかもしれないけど、備忘録として投稿。
行き詰まったところ
60,000行を超えるレコード数を持った約20MBほどのCSVファイルをインポートさせると、読み込みの途中でエラーになってしまう。
SELECT DISTINCTで重複レコードをまとめるSQLを発行したにも関わらず、ダブって表示されてしまう。(大文字小文字を区別していない)
検証環境
まずは、サーバーのスペックなど。仮想ホストにはVMware ESXiを利用しています。
| 項目 | 内容 | 確認用のコマンド |
|---|---|---|
| OS | CentOS Linux release 7.9.2009 (Core) | cat /etc/redhat-release |
| Web Server | Apache/2.4.6 (CentOS) | httpd -v |
| PHP | PHP 5.4.16 (cli) (built: Apr 1 2020 04:07:17) | php -v |
| DB server | mariadb-server-5.5.68-1.el7.x86_64 | rpm -qa | grep -i mariadb |
| phpMyAdmin | phpMyAdmin-4.4.15.10-4.el7.noarch | rpm -qa | grep -i phpmyadmin |
設定ファイルを修正する
さまざまなphpの設定をするphp.iniを修正。インポートファイルのサイズ制限もここで変更。
デフォルト値
/etc/php.ini
upload_max_filesize = 2M
post_max_size = 8M
今後のことも考えて、大幅にアップさせることにしました。
変更後
/etc/php.ini
upload_max_filesize = 32M
post_max_size = 128M
Webサーバーを再起動させ反映させる。
# systemctl restart httpd
注意点
upload_max_filesizeだけ変更しても上限8,192KBになってしまう。
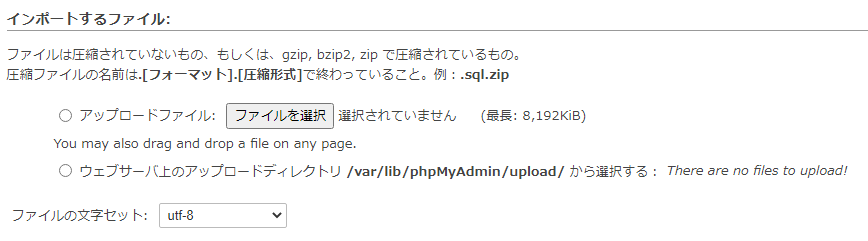
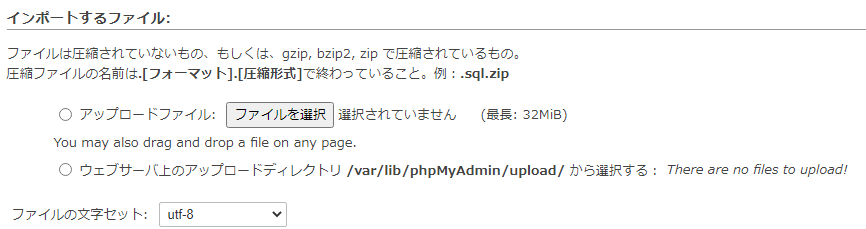
post_max_sizeも変更する。
すると32MiBに変わる。
大文字小文字の区別
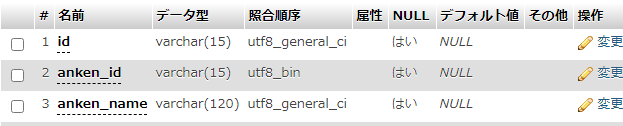
調べたらところ、バイナリにすることで解決するようだ。
該当カラムの照合順序を「utf8_bin(UNICODEバイナリ)」に指定することで解決。
※デフォルトで作ると「utf8_general_ci(UNICODE・大文字小文字を区別しない)」で作られるみたい。