データベースに慣れるために、「日本語諸方言コーパス (COJADS) 」の元データをデータベース化してみました。第1回は公式で配られている冗長な CSV を第二正規化の済んだ形で再モデル化するところまで。完全に自分用の作業メモで、説明もいろいろ足りていないと思いますが、ご容赦ください。
2020/08/17 改訂しました。
- 第1回: 日本語諸方言コーパスをDB化して遊ぶ (1) 構成を考える ←今ここ
- 第2回: 日本語諸方言コーパスをDB化して遊ぶ (2) SQLite3 で DB 化
- 第3回: 日本語諸方言コーパスをDB化して遊ぶ (3) PHP Laravel で操作する
- 第4回: 日本語諸方言コーパスをDB化して遊ぶ (4) サービスの全体像を決める
- 第5回: 日本語諸方言コーパスをDB化して遊ぶ (5) データベースの移行とモデルの作成
- 第6回: 日本語諸方言コーパスをDB化して遊ぶ (6) 談話ごとの発話総覧を作る
- 第7回: 日本語諸方言コーパスをDB化して遊ぶ (7) 話者ごとの発話総覧を作る
- 第8回: 日本語諸方言コーパスをDB化して遊ぶ (8) ファイル形式変換機能をつける
- 第9回: 日本語諸方言コーパスをDB化して遊ぶ (9) Heroku でデプロイする
データの入手
COJADS は国立国語研究所で制作・管理されている全国諸方言の音声付き方言コーパスです。申請をすればコーパスアプリケーション「中納言」で様々な検索を利用することができますが、公式サイトで中納言版の元となるデータ(以降「生データ」)が配布されています。
生データは CSV 形式で配布されています。全データは一つのまとまった「談話」ごとにファイル分けされており、各「談話」は「話者」による「発話」を単位として構成されています。一つのファイルの中に「談話」の情報をすべて詰め込む関係で、データベースとしてはかなり冗長な構成となっています。どのようなエンティティと関係、および属性が存在するかを特定し、正規化を進め、データベースとして再構成していきます。
データの正規化
正規化の前に
公式サイトで配布されている生データ CSV は以下の 29 列からなっています。
xmin, xmax, 県, 地点, file番号, 地点ID, ID, 話者, 方言テキスト, 標準語テキスト, データ名, 収録年月日, 収録場所, 編集担当者, 話者生年, 話者年齢, 話者性別, 話題, 収録担当者, 談話ジャンル, 注1番号, 注1語形, 注1注釈, 注2番号, 注2語形, 注2注釈, 注3番号, 注3語形, 注3注釈
これは「談話ごとにデータを全結合した発話リスト」ですから、これとは別に「談話」テーブルを作成する必要があります。「談話ID」はファイル名そのもの(01_b_099 のようなもの)とします。ファイル名は後述するように意味コードを含んだ命名ですが、取り回しがよいので今回はこのまま使用します。
また「談話」テーブル作成と同時に、発話リストに「談話ID」を示すカラムを追加します。つまり現時点では以下のようになっているといえます。

第一正規化
第一正規化とは、テーブル中から 繰り返し属性 、すなわち一つの属性が複数の値を持つ状態を排除する操作を言います。
公式サイトから入手できる CSV(=発話テーブル)は、だいたい第一正規化が済んでいると言えそうですが、いくつか考慮すべき点があります。
まず注釈については、「注1」~「注3」のようにアドホックな複数カラムに分割されていることからわかる通り、ひとつの発話区間に0個以上3個以下の注釈が紐づいているわけで、実際には繰り返し属性と考えて差し支えないでしょう。今回は注釈をモデル化対象から外すことで対応します1。
また注を除いた21列のカラムについても、たとえば「編集担当者」「収録担当者」「話題」には複数の値が入ることがありえます。ここではこうした複数の値を、複数の属性値として独立してとらえるのではなく、複数の値が組としてひとつの属性値をなすと考えます2。
さらに「方言テキスト」「標準語テキスト」は全角スペースで区切られた1個以上複数の「文節」からなるので、文節を単位としてデータベース化する(つまり「発話単位」を「文節」へと分解する)のであれば、これは繰り返し属性とみなすことができ、さらなる分析が可能です。しかしそうなると、現状では発話の時間的区間(xmin~xmax)が文節に対応していませんから、文節の数に応じて等分するなどの措置をとる必要があり面倒です。今回は文節単位での分析は目的としていませんので、これも繰り返し属性とはとりません。
以上の留保をおくと、公式サイトの CSV は繰り返し属性をもたない第一正規形とみなすことができるでしょう。

第二正規化
第二正規化とは、主キーに 部分関数従属 する属性を別のテーブルに切り分ける操作のことです。
現在、発話テーブルは談話に関する情報が全結合してある状態ですから、多くの情報が部分関数従属しています。
たとえば「話者」「方言テキスト」「標準語テキスト」といった属性は「談話ID」と談話内での「ID」の2つの属性により同定されます。ざっくりいうと、これらの属性は「発話」テーブルの「本体」であり、最も多くの属性に従属するものです(つまり、このテーブルの主キーは「談話ID」と「ID」の複合キーであるということです)。
一方、「県名」「県番号」「データ名」といった属性は「談話ID」のみで同定でき、「ID」には従属していません。したがってこれらの属性は部分関数従属しているといえます。今回は新規テーブルに切り分けるのではなく、既存の「談話」テーブルにこれらの属性を移動させればよいでしょう。
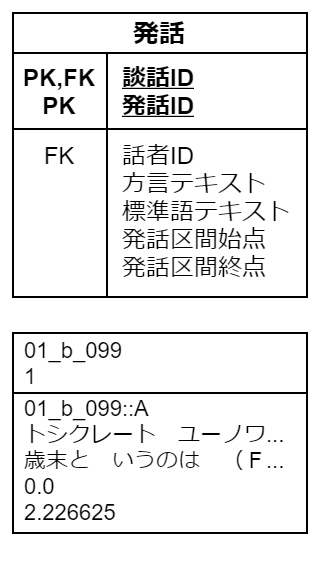
以上より第二正規化を行なうと、次のようになります(太字が主キー)。

第三正規化
第三正規化とは、推移的関数従属 を排除する操作のことです。第二正規化で主キーとそれ以外の属性との間に冗長性はなくなりましたが、この「それ以外の属性」のなかに、まだ冗長性が潜んでいるということで、さらなる簡素化を目指します。
第三正規化は、データ全体をどのようなエンティティに分割していくかイメージしながら行なうとやりやすいかと思います。
たとえば「談話テーブル」には 収録された地点 を表す情報がいくつか含まれていますが、「県(→県名)」と「file番号(→県番号)」は一対一で対応していますし、「地点(→地点名)」は「file番号(→県番号)」と「地点ID」に従属しています(属性名が分かりにくいので、矢印のように改名します)。
また「話者生年」「話者年齢」「話者性別」は 話者 が決まれば自動的に決まりますから、これも部分関数従属として切り出すことが可能です。ただし、話者自体は談話に従属する符号化が施されている(i.e. 談話ごとにA, B,... と符号化されている)ので、話者を同定するには「談話ID」と「話者」の2属性が必要です。
以上を念頭に置いて、テーブルを分割していきます。地点は以下のように「県」テーブルと「地点」テーブルに分割できます(後述)。
エンティティの切り分け
ここで一度、データをエンティティ・リレーションとして整理してみます。ひとまず「談話」「話者」「地点」「発話」の4つを措定して、その関係を考えてみます。1つの「地点」について、1つ以上の「談話」が対応します。1つの「談話」について、複数の「発話」が対応します3。1つの「話者」に対して1つ以上の「発話」が対応します。
「談話」と「話者」は多対多の関係として記述していますが、これは少し複雑です。前述の通り、COJADS では談話ごとに話者 A, 話者 B,... と独立に符号化されているので、「談話」に従属する定義づけもできます。ただ、談話間の話者の同一性がわからなくなっているだけで、実際には1人の話者が複数の「談話」に出現することがあるので、「談話」に依存しないエンティティとして考えたほうが健全だと思われます。

各テーブルの考察
先ほど述べた内容とやや重複しますが、以上の関係性を念頭において、各テーブルの属性を精査し、主キー・外部キーを考えていきます。
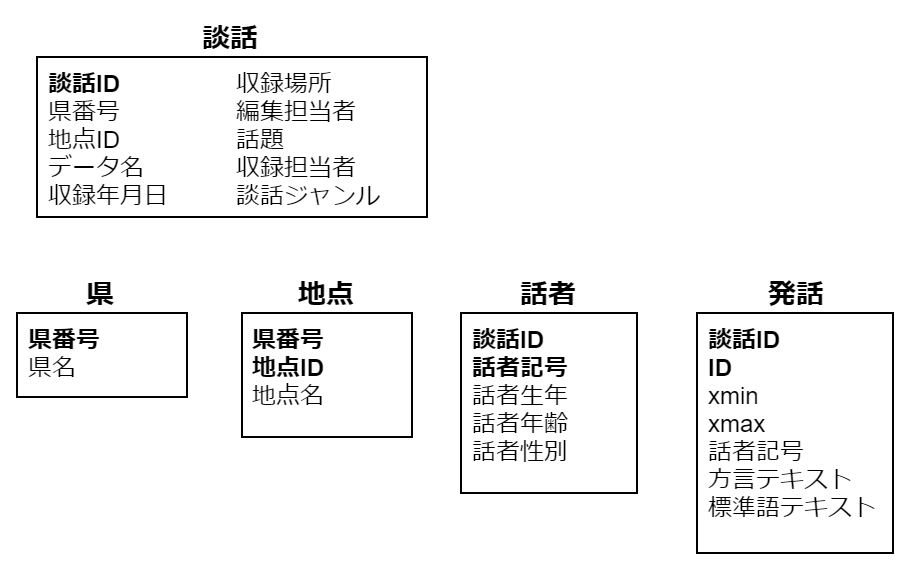
地点
地点に関する情報は「県名」「県番号(=file番号)」「地点名」「地点ID」の4つがありますが、「県名/県番号」は一対一の関係にあるため独立した小さなエンティティ「県」として分離できます。また「地点ID」は都道府県ごとに A, B,... と振られているため、「地点」エンティティは**「県番号」**と「地点ID」を複合主キーとして設定できます。
「県番号」が「県」~「地点」~「談話」と3つのエンティティ間で関連を持つため、やや依存が強いですが、「県」エンティティは今後変更される可能性が限りなく低いため、少々依存度が高くなっても問題ないでしょう。もし今後国外の日本語話者についてもデータを追加することがあれば、「県」エンティティに「その他: 48」を追加することにしましょう。
以上より、次のような小さな2つのテーブルに分けることが出来ました(下部は属性値の例)。
話者
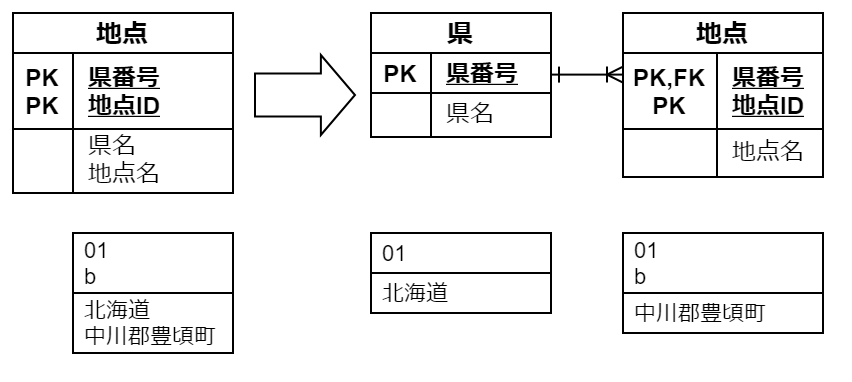
素朴に考えると、話者は各談話の中で A, B,... と符号化されているわけですから、01_b_099 のような「談話ID」と A, B,... のような「話者記号」を複合主キーとしてたてて、それに「話者生年」「話者年齢」「話者性別」という属性が従っているとみることになります。
しかし、上述のとおり、談話と話者は本来多対多の関係を持っているはずです。たとえば同一話者が異なる2つ以上の談話に参加することもあります。同一の話者(たとえば調査者)が異なる地点の談話に参加することもありえます。従って理想的には、話者は談話にも地点にも従属しない独立したエンティティとして措定され、談話を介さず直接発話と結びつくべきです。COJADS のデータの出典は「全国危機方言緊急調査」で、そこまでさかのぼれば談話を超えた話者の関係が明らかになりますが、公式サイトで公開されているデータ上はそのへんの情報を全く含んでおらず、談話ごとに A, B, . . . と振られて談話に従属しています。ですので、談話ID と話者記号の複合主キーとしてもいいのですが、ここでは理想に沿って(あるいは将来の拡張を見越して)、両者を 01_b_099::A のように結合した「話者ID」をたてておきます。元データにはない属性なので、広義の代理キーと言えるでしょうか。
また「話者年齢」は「話者生年」と「談話」の「収録年月日」から 算出可能 ですから取り除きます。言い換えると、話者の年齢は収録年月日によって変わるものですから、話者エンティティの属性として持たせるべきではないと考えられます。
以上の考察から、主キー「話者ID」に2つの属性「話者生年」「話者性別」が付属するシンプルなエンティティにまとまりました。
談話
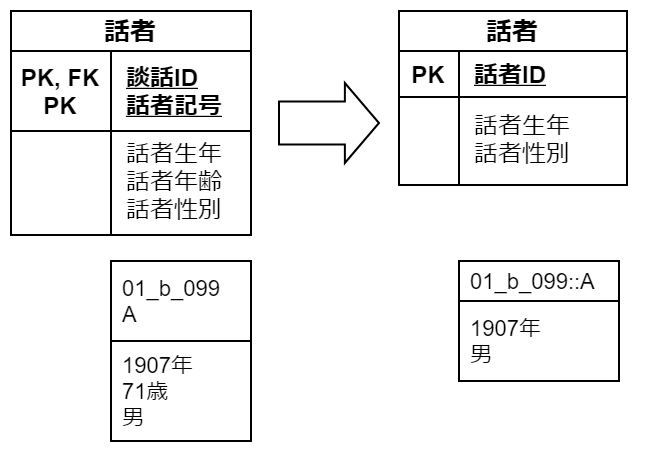
談話は音声ファイルと一対一で対応する談話のかたまりです。1つの「地点」に対して1つ以上の「談話」が所属しており、各談話は外部キーである「県番号」「地点ID」、そして独自の「ファイル記号」からなる複合主キーにより同定されます。生データのファイル名はこれらをアンダーバーでつなげた形をとっています(たとえば 01_b_099)。
先に述べたように、1つの「談話」に対して複数の「発話」が従属しているため、複合主キーをそのまま用いるより代理キー(サロゲートキー)を用意したほうがよさそうです。ここでは生データのファイル名をそのまま「談話ID」として利用することにします(これはいわゆる「意味コードを含んでいる」状態で、一般的には避けるべきかもしれません)。
なお「収録場所」は「〇〇寺」「××公会堂会議室」など非常に特定的な情報であるため、「地点」エンティティではなく「談話」エンティティの属性として扱ってよいと考えます。また、実はひとつの「談話」の中に複数の話題が含まれる(=談話の途中で話題が変わる)場合があるのですが、これは今回考えないものとします。
発話
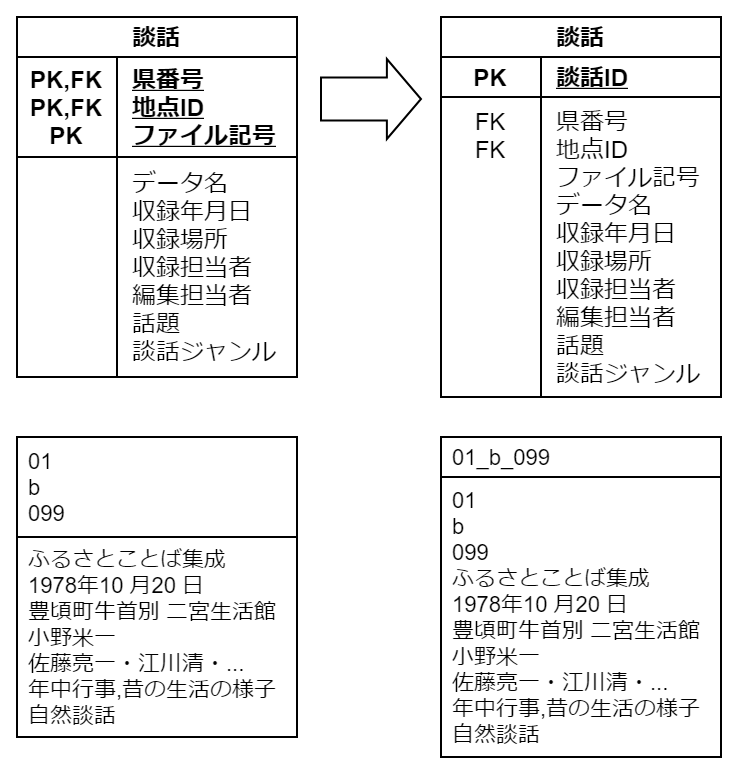
「発話」は適当な長さの言語片4であり、話者、対応する音声ファイル上での発話区間の時間情報(xmin=発話区間始点, xmax=発話区間終点)、方言テキスト、標準語テキストからなります(方言テキストと標準語テキストは1つ以上の文節からなります)。
これまでの議論から、主キーを定めるのに悩む必要はありません。主キーは複合キーであり、所属する談話 ID と、談話内で独自にふられた発話 ID によって同定されます。発話 ID は xmin 昇順に 1, 2, . . . とふられていますが、xmin が全く同じ発話も多く存在するため、xmin を発話 ID がわりに使用することはできません。
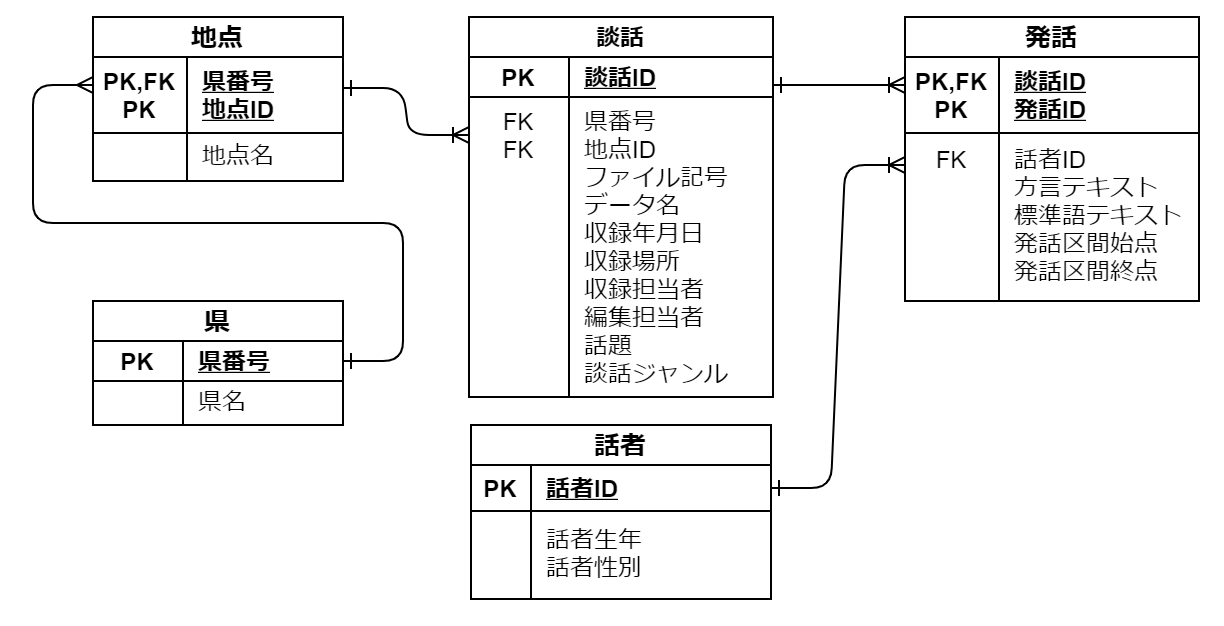
ER 図に起こす
以上の議論から詳細な ER 図を起こすと以下のようになります。
次回予告
実際に SQLite3 でデータベース化します。
-
注釈をモデルから外す大きな理由のひとつは、実は注釈が談話IDの末尾が099のファイル(=『ふるさとことば集成』をデータソースとするファイル)にしか含まれておらず、それ以外のファイルでは完全に空白であることです。 ↩
-
別の言い方をすれば、「編集担当者」テーブルとか「収録担当者」テーブルのようなものを立てる価値はないと考えます。「話題」についても、有限個の既定の話題からえらんで談話を収録しているならともかく、COJADS データの「話題」は談話内容に応じて後付けしているものですので、やはり「話題」テーブルをたてる価値は見出せません。 ↩
-
ひょっとすると「談話」と「発話」が一対一に対応する事例もあるかもしれません(「場面設定」ジャンルなど)。 ↩
-
文の切れ目、あるいは 0.2 秒程度の休止が入ったタイミングで切られています。 ↩