データベースに慣れるために、「日本語諸方言コーパス (COJADS) 」の元データをデータベース化してみました。第2回は前回のモデルに沿って CSV を加工して SQLite DB 化するところまで。完全に自分用の作業メモで、説明もいろいろ足りていないと思いますが、ご容赦ください。
2020/08/17 ちょっと CREATE TABLE のコードを修正しました。
- 第1回: 日本語諸方言コーパスをDB化して遊ぶ (1) 構成を考える
- 第2回: 日本語諸方言コーパスをDB化して遊ぶ (2) SQLite3 で DB 化 ←今ここ
- 第3回: 日本語諸方言コーパスをDB化して遊ぶ (3) PHP Laravel で操作する
- 第4回: 日本語諸方言コーパスをDB化して遊ぶ (4) サービスの全体像を決める
- 第5回: 日本語諸方言コーパスをDB化して遊ぶ (5) データベースの移行とモデルの作成
- 第6回: 日本語諸方言コーパスをDB化して遊ぶ (6) 談話ごとの発話総覧を作る
- 第7回: 日本語諸方言コーパスをDB化して遊ぶ (7) 話者ごとの発話総覧を作る
- 第8回: 日本語諸方言コーパスをDB化して遊ぶ (8) ファイル形式変換機能をつける
- 第9回: 日本語諸方言コーパスをDB化して遊ぶ (9) Heroku でデプロイする
データベース化する
SQLite3 のインストール
DB として、今回はインストールも簡単・ローカル環境で気軽に遊べる SQLite をチョイス。コマンドラインツールと DB Browser for SQLite を両方準備しておきます。大量の CSV をインポートするには別に SQL ファイルをつくってコマンドラインで一気に処理したほうが楽だし、一度組んでおけばやり直しも簡単。一方、DB の具合を確かめたり、頭が働かないときは GUI ツールで DB を眺めるのもよいでしょう。
DB とテーブルの作成
まずデータベースを作成し、接続します。今回は cojads.sqlite3 という名前のデータベースにします。sqlite3.exe のあるフォルダをコマンドプロンプトで開き、以下のコマンド1行目を実行すると、データベースが新規作成され、自動で接続し、SQLite の対話モードに移行します。
sqlite3 cojads.sqlite3
sqlite>
次に、先ほどの ER 図のとおり、5つのエンティティに対応する5つのテーブルを作成します。実際のデータにはメタ情報に欠けがある場合も多い(例えば、通常「話者」の性別は男か女だが、たまたま口をはさんだ同席者など詳細不明な話者も存在する)ため、CHECK (性別 = "男" OR 性別 = "女") などの入力規則の設定は行ないません。以下のコマンドをコピペして SQLite に実行させます。
なお、テーブル名や属性名に日本語を用いるとどうしても後の工程で syntax error が出てしまったので、英字にしています。
CREATE TABLE prefecture(
prefectureNum INT,
prefectureName TEXT,
PRIMARY KEY (prefectureNum)
);
CREATE TABLE location(
prefectureNum INT,
locationId TEXT,
locationName TEXT,
PRIMARY KEY (prefectureNum, locationId),
FOREIGN KEY (prefectureNum) REFERENCES prefecture(prefectureNum)
);
CREATE TABLE speaker(
speakerId TEXT,
speakerSex TEXT,
speakerBirthyear TEXT,
PRIMARY KEY (speakerId)
);
CREATE TABLE discourse(
discourseId TEXT,
prefectureNum INT,
locationId TEXT,
fileId TEXT,
reference TEXT,
recordDate TEXT,
recordLocation TEXT,
recorder TEXT,
editor TEXT,
topic TEXT,
genre TEXT,
FOREIGN KEY (prefectureNum, locationId) REFERENCES location(prefectureNum, locationId),
PRIMARY KEY (discourseId)
);
CREATE TABLE utterance(
discourseId TEXT,
utteranceId INT,
speakerId TEXT,
xmin REAL,
xmax REAL,
dialectText TEXT,
standardText TEXT,
PRIMARY KEY (discourseId, utteranceId),
FOREIGN KEY (discourseId) REFERENCES discourse(discourseId),
FOREIGN KEY (speakerId) REFERENCES speaker(speakerId)
);
データのインポート
次に CSV を加工してテーブルに追加します。生データは談話ごとに CSV 化されており、すべての情報が1枚の CSV に詰まっているので、テーブルごとに必要な部分だけ抜き出して追加していく必要があります。生データの CSV の形式は完全に固定なので、マジックナンバーを多用してゴリゴリ進めていきましょう。
都道府県
まずは「都道府県」テーブルを作ります。これは JIS コード(JIS X 0401)まんまなので CSV とは関係なく作ってしまう。
INSERT INTO prefecture (prefectureNum, prefectureName)
VALUES (1, '北海道'), (2, '青森'), (3, '岩手'), (4, '宮城'), (5, '秋田'), (6, '山形'), (7, '福島'), (8, '茨城'), (9, '栃木'), (10, '群馬'), (11, '埼玉'), (12, '千葉'), (13, '東京都'), (14, '神奈川'), (15, '新潟'), (16, '富山'), (17, '石川'), (18, '福井'), (19, '山梨'), (20, '長野'), (21, '岐阜'), (22, '静岡'), (23, '愛知'), (24, '三重'), (25, '滋賀'), (26, '京都府'), (27, '大阪府'), (28, '兵庫'), (29, '奈良'), (30, '和歌山'), (31, '鳥取'), (32, '島根'), (33, '岡山'), (34, '広島'), (35, '山口'), (36, '徳島'), (37, '香川'), (38, '愛媛'), (39, '高知'), (40, '福岡'), (41, '佐賀'), (42, '長崎'), (43, '熊本'), (44, '大分'), (45, '宮崎'), (46, '鹿児島'), (47, '沖縄');
それ以外は CSV から抽出しましょう。うちの環境が Windows なのでバッチファイルを作ります。バッチファイルを書くのは初めてでしたが、変数解決のタイミングやGOTO文の壊れた仕様、文字コードの壁などに終始苦しめられ、なぜ Python で書かなかったのかと何度も何度も後悔しましたが、勉強と思って書きました。コード全体はやや長くなるので格納しておきます。
バッチファイルのコード全体
@ECHO off
SETLOCAL enabledelayedexpansion
CD %~dp0
REM 一時的にUTF-8で動作させる
CHCP 65001
REM 地点
TYPE location.csv > location.csv
FOR %%x IN (*.csv) DO (
SET filename=%%x
SET prefectureNum=!filename:~0,2!
SET locationId=!filename:~3,1!
CALL :GET_LOCATION_NAME !prefectureNum! !locationId! %%x
)
sqlite3 -separator , cojads.sqlite3 ".import location.csv location"
DEL location.csv
REM 話者
TYPE speaker.csv > speaker.csv
FOR %%x IN (*.csv) DO (
IF NOT "%%x" == "speaker.csv" (
FOR /F "skip=1 tokens=8 delims=," %%a IN (%%x) DO (
CALL :CHECK_EXISTENCE %%a
)
CALL :COLLECT_META %%x
)
FOR /L %%i IN (0,1,10) DO (
SET speaker_%%i=
)
)
sqlite3 -separator , cojads.sqlite3 ".import speaker.csv speaker"
DEL speaker.csv
REM 談話
TYPE discourse.csv > discourse.csv
FOR %%x IN (*.csv) DO (
IF NOT "%%x" == "discourse.csv" (
SET filepath=%%x
CALL :SUB %%x !filepath:~0,-4! !filepath:~5,-4!
)
)
sqlite3 -separator , cojads.sqlite3 ".import discourse.csv discourse"
DEL discourse.csv
REM 発話
TYPE utterance.csv > utterance.csv
FOR %%x IN (*.csv) DO (
IF NOT "%%x" == "utterance.csv" (
SET utteranceId=0
SET filepath=%%x
FOR /F "skip=1 tokens=1,2,8-10 delims=," %%a IN (%%x) DO (
SET discourseId=!filepath:~0,-4!
SET /a "utteranceId=utteranceId+1"
SET speakerId=!filepath:~0,-4!::%%c
SET dialectText=%%d
SET standardText=%%e
SET xmin=%%a
SET xmax=%%b
ECHO !discourseId!,!utteranceId!,!speakerId!,!dialectText!,!standardText!,!xmin!,!xmax! >> utterance.csv
)
)
)
sqlite3 -separator , cojads.sqlite3 ".import utterance.csv utterance"
DEL utterance.csv
REM あとで文字コードをSJISに戻すべし(sqliteコマンドなどがバグるので)
REM chcp 932
EXIT /b
REM 地点用サブルーチン
:GET_LOCATION_NAME
FOR /F "skip=1 tokens=4 delims=," %%a IN (%3) DO (
ECHO %1,%2,%%a >> location.csv
GOTO :end_gln
)
:end_gln
EXIT /b
REM 話者用サブルーチン1
:CHECK_EXISTENCE
SET i=0
SET flag=0
:loop_ce
SET item_ce=!speaker_%i%!
IF defined item_ce (
IF "%item_ce%" == "%1" (
SET /a "flag+=1"
)
SET /a "i+=1"
GOTO :loop_ce
)
IF %flag% equ 0 (
CALL :ADD_TO_LIST %1
)
EXIT /b
REM 話者用サブルーチン2
:ADD_TO_LIST
SET j=0
:loop_al
SET item_al=!speaker_%j%!
IF defined item_al (
SET /a "j+=1"
GOTO :loop_al
) ELSE (
SET speaker_%j%=%1
)
EXIT /b
REM 話者用サブルーチン3
:COLLECT_META
SET k=0
:loop_cm
SET item_cm=!speaker_%k%!
SET flag_cm=0
IF defined item_cm (
SET filename=%1
CALL :COLLECT_META_SUB !item_cm! !filename:~0,-4!
SET /a "k+=1"
GOTO :loop_cm
)
EXIT /b
REM 話者用サブルーチン4(3の補助ルーチン)
:COLLECT_META_SUB
FOR /F "skip=1 tokens=8,15,17 delims=," %%s IN (%2.csv) DO (
IF "%1" == "%%s" (
SET speakerId=%2::%1
SET speakerSex=%%u
SET speakerBirthyear=%%t
ECHO !speakerId!,!speakerSex!,!speakerBirthyear! >> speaker.csv
GOTO :end_cms
)
)
:end_cms
EXIT /b
REM 談話用サブルーチン
:SUB
FOR /F "skip=1 tokens=5-6,11-14,18-20 delims=," %%a IN (%1) DO (
SET discourseId=%2
SET prefectureNum=%%a
SET locationId=%%b
SET fileId=%3
SET reference=%%c
SET recordDate=%%d
SET recordLocation=%%e
SET recorder=%%h
SET editor=%%f
SET topic=%%g
SET genre=%%i
ECHO !discourseId!,!prefectureNum!,!locationId!,!fileId!,!reference!,!recordDate!,!recordLocation!,!recorder!,!editor!,!topic!,!genre! >> discourse.csv
GOTO end
)
:end
EXIT /b
文字コードについて
Windows のコマンドプロンプトは初期設定では SHIFT_JIS で動いていますが、SQLite は基本 UTF-8 を受け付けているので1、作業中だけ CHCP 65001 コマンドで UTF-8 に切り替えます(そのままだと他の作業に支障をきたすので、作業後に CHCP 932 で元に戻しておきます)。CSV も UTF-8 のものを使用します(公式サイトでは SHIFT_JIS 版と UTF-8 版が両方配布されています)。
データベースへのインポート
1レコードごとに sqlite3 を呼ぶと時間がかかるので、元の CSV から必要な列を抜き出して一時ファイルを作ってから一気に流し込みます。デフォルトではセパレータがパイプ | になっているので一時的にコンマ , に変更する必要があります。
sqlite3 -separator , databasepath ".import tempfile.csv tablename"
以下、それぞれのテーブルに関係する処理を抜粋して解説していきます。
地点
地点はわりと簡単で、ファイル名から「都道府県番号」と「地点ID」を抽出し、CSV の中の任意の1行から「地点」を抽出すれば終いです。FOR文につけているオプションですが、skip=1は見出し行無視, delims=,は区切り文字の指定、tokens=...は使用する項目の指定となっています。
なお、COJADS のデータは1地点に対して複数の談話が存在するため、この手法だと一時ファイル中に重複するレコードができてしまいますが、UNIQUE 制約がかけてあるので .import するときに自動で排除されます。
REM 一時ファイルを作成
TYPE location.csv > location.csv
REM ファイル名を加工して県番号と地点IDを取得
FOR %%x IN (*.csv) DO (
SET filename=%%x
SET prefectureNum=!filename:~0,2!
SET locationId=!filename:~3,1!
REM サブルーチン内で地点名を取得して一時ファイルに蓄積
CALL :GET_LOCATION_NAME !prefectureNum! !locationId! %%x
)
REM データベースに挿入し、しかるのち一時ファイルを削除
sqlite3 -separator , cojads.sqlite3 ".import location.csv location"
DEL location.csv
EXIT /b
REM 地点用サブルーチン(%1: 県番号, %2: 地点ID, %3: ファイルパス)
REM 2行目の「地点」列を取得して一時ファイルに書き込む
:GET_LOCATION_NAME
FOR /F "skip=1 delims=, tokens=4 " %%a IN (%3) DO (
ECHO %1,%2,%%a >> location.csv
GOTO :end_gln
)
:end_gln
EXIT /b
話者
話者テーブルを作るには、各ファイルから(1)話者リストを作成し、(2)話者ごとにメタ情報を収集し、(3)データベースに追加する、という3段階を経なければいけませんが、バッチでは配列が扱えないため、重複なし話者リストの作成からして困難です。またループを途中で抜けるために GOTO 文を利用したいのですが2、ネストされた FOR 内部から GOTO を行なうと変数が大変なことになるので、その部分をサブルーチン化して階層を浅くしています3。
バッチには関数が存在しないので、サブルーチンを作成して CALL で飛びます。ただし、サブルーチンに引数を持ち込むことはできますが、文字列などを返すことはできないので、サブルーチンの中で一時ファイルへの書き込みを済ませるようにしています。
- BATのfor文におけるGOTO文のトラップ | 雑記 ※BLOGじゃないから恥ずかしくないもん!
- バッチファイルでサブルーチンを使用する | 知識ゼロからのwindowsバッチファイル超入門
- バッチファイルで配列とforeachを使う方法 | Qiita
REM 一時ファイルを作成
TYPE speaker.csv > speaker.csv
FOR %%x IN (*.csv) DO (
IF NOT "%%x" == "speaker.csv" (
REM 話者リストを作成する(最大 10 名)
REM 行ごとに話者を取得して、サブルーチン内で話者リストになければ追加
FOR /F "skip=1 delims=, tokens=8" %%a IN (%%x) DO (
CALL :CHECK_EXISTENCE %%a
)
REM 話者ごとにメタ情報を拾って一時ファイルに入れる
CALL :COLLECT_META %%x
)
REM ひとつのファイルの処理が終わったら話者リストをクリア
FOR /L %%i IN (0,1,10) DO (
SET speaker_%%i=
)
)
REM データベースに挿入し一時ファイルを削除
sqlite3 -separator , cojads.sqlite3 ".import speaker.csv speaker"
DEL speaker.csv
EXIT /b
REM 話者用サブルーチン
REM リスト内にないなら追加、あるなら何もしない(%1: 話者候補)
REM 疑似配列として speaker_0, speaker_1,.. . を用いている
:CHECK_EXISTENCE
SET i=0
SET flag=0
:loop_ce
SET item_ce=!speaker_%i%!
IF defined item_ce (
IF "%item_ce%" == "%1" (
SET /a "flag+=1"
)
SET /a "i+=1"
GOTO :loop_ce
)
REM flag が 0 なら未登録と判断して追加用サブルーチンに
IF %flag% equ 0 (
CALL :ADD_TO_LIST %1
)
EXIT /b
REM リスト末尾に追加(%1: 新規話者)
:ADD_TO_LIST
SET j=0
:loop_al
SET item_al=!speaker_%j%!
IF defined item_al (
SET /a "j+=1"
GOTO :loop_al
) ELSE (
SET speaker_%j%=%1
)
EXIT /b
REM メタ情報を収集する(%1: ファイルパス)
:COLLECT_META
SET k=0
:loop_cm
SET item_cm=!speaker_%k%!
SET flag_cm=0
IF defined item_cm (
SET filename=%1
CALL :COLLECT_META_SUB !item_cm! !filename:~0,-4!
SET /a "k+=1"
GOTO :loop_cm
)
EXIT /b
REM COLLECT_META のサブルーチン(%1: 話者, %2: ファイル名)
REM 話者が %1 と同一になる行を発見してメタ情報を一時ファイルに書き込み、即離脱
:COLLECT_META_SUB
FOR /F "skip=1 delims=, tokens=8,15,17" %%s IN (%2.csv) DO (
IF "%1" == "%%s" (
SET speakerId=%2::%1
SET speakerSex=%%u
SET speakerBirthyear=%%t
REM 氏名と補足情報は空欄のままとする
ECHO !speakerId!,!speakerSex!,!speakerBirthyear! >> speaker.csv
GOTO :end_cms
)
)
:end_cms
EXIT /b
談話
談話IDとしてはひとまず「都道府県番号」と「地点ID」と「ファイル記号」をアンダーバーで接続したものを使用します。ID のなかに意味コードが含まれているので本来よくありませんが、インポート作業を簡単にするためこの形式を使用します。
メタ情報は見出し行を除いた第2行から最終行まですべて同じ情報ですので、とりあえず2行目を使用します。
REM 一時ファイルを作成
TYPE discourse.csv > discourse.csv
REM 各CSVから必要な情報を抜き出す
REM 談話IDやファイル記号はサブルーチンに入れる前に成形しておく
FOR %%x IN (*.csv) DO (
IF NOT "%%x" == "discourse.csv" (
SET filepath=%%x
CALL :discourse_SUB %%x !filepath:~0,-4! !filepath:~5,-4!
)
)
REM データベースに挿入し、一時ファイルを削除
sqlite3 -separator , cojads.sqlite3 ".import discourse.csv discourse"
DEL discourse.csv
EXIT /b
REM 談話用サブルーチン(%1: ファイルパス, $2: 談話ID, $3: ファイル記号)
REM 2行目だけ使えばいいので、1行目をスキップして2行目終了時にGOTOで抜ける
:discourse_SUB
FOR /F "skip=1 delims=, tokens=5-6,11-14,18-20" %%a IN (%1) DO (
SET discourseId=%2
SET prefectureNum=%%a
SET locationId=%%b
SET fileId=%3
SET reference=%%c
SET recordDate=%%d
SET recordLocation=%%e
SET recorder=%%h
SET editor=%%f
SET topic=%%g
SET genre=%%i
ECHO !discourseId!,!prefectureNum!,!locationId!,!fileId!,!reference!,!recordDate!,!recordLocation!,!recorder!,!editor!,!topic!,!genre! >> discourse.csv
GOTO :end_ds
)
:end_ds
EXIT /b
発話
最後にデータの中核である「発話」テーブルを作っていきます。複雑なループを組んだり、複雑な配列操作をする必要がなく、サブルーチンなしでさらっと書けます。「談話ID」はファイル ID そのもの、話者IDは談話ID+話者記号(元データ [7])、「xmin」は元データ [0] 、「xmax」は元データ [1]、「方言テキスト」は元データ [8]、「標準語テキスト」は元データ [9] です。
REM 一時ファイルの作成
TYPE utterance.csv > utterance.csv
FOR %%x IN (*.csv) DO (
IF NOT "%%x" == "utterance.csv" (
REM 発話IDはインクリメントする
SET utteranceId=0
SET filepath=%%x
REM 見出し行はスキップして、行ごとに処理
FOR /F "skip=1 delims=, tokens=1,2,8-10" %%a IN (%%x) DO (
REM 拡張子を消してファイル名を取得
SET discourseId=!filepath:~0,-4!
SET /a "utteranceId=utteranceId+1"
SET speakerId=!filepath:~0,-4!::%%c
SET dialectText=%%d
SET standardText=%%e
SET xmin=%%a
SET xmax=%%b
REM 一時ファイルに挿入
ECHO !discourseId!,!utteranceId!,!speakerId!,!dialectText!,!standardText!,!xmin!,!xmax! >> utterance.csv
)
)
)
REM データベースに挿入して一時ファイルを削除
sqlite3 -separator , cojads.sqlite3 ".import utterance.csv utterance"
DEL utterance.csv
EXIT /b
バッチを実行
上で作ったバッチファイルを、CSV および sqlite3 と同じフォルダにおいて実行します。@ECHO off と設定しているので、特に何の表示も出ないはずですが、UNIQUE 制約に引っかかるとか、CSV の不具合で列数が異なるとか、何らかの原因でインサートに失敗するとコマンドプロンプト上に表示されます(文字コードを変更するとウィンドウの表示内容が更新されて、エラーメッセージが消えてしまうので、文字コードを SJIS に戻す CHCP 932 はコメントアウトしています)。
今回は末尾が 099 のファイル(『ふるさとことば集成』所収のデータ群)のみをデータベース化しました4。発話は約5万行、全体で約8MB程度のデータサイズになりました。DB Browser for SQLite で接続して閲覧してみましょう。
だいたいちゃんとインポートできていますね。5万行程度であれば、DB Browser for SQLite で非常に快適に閲覧できます。
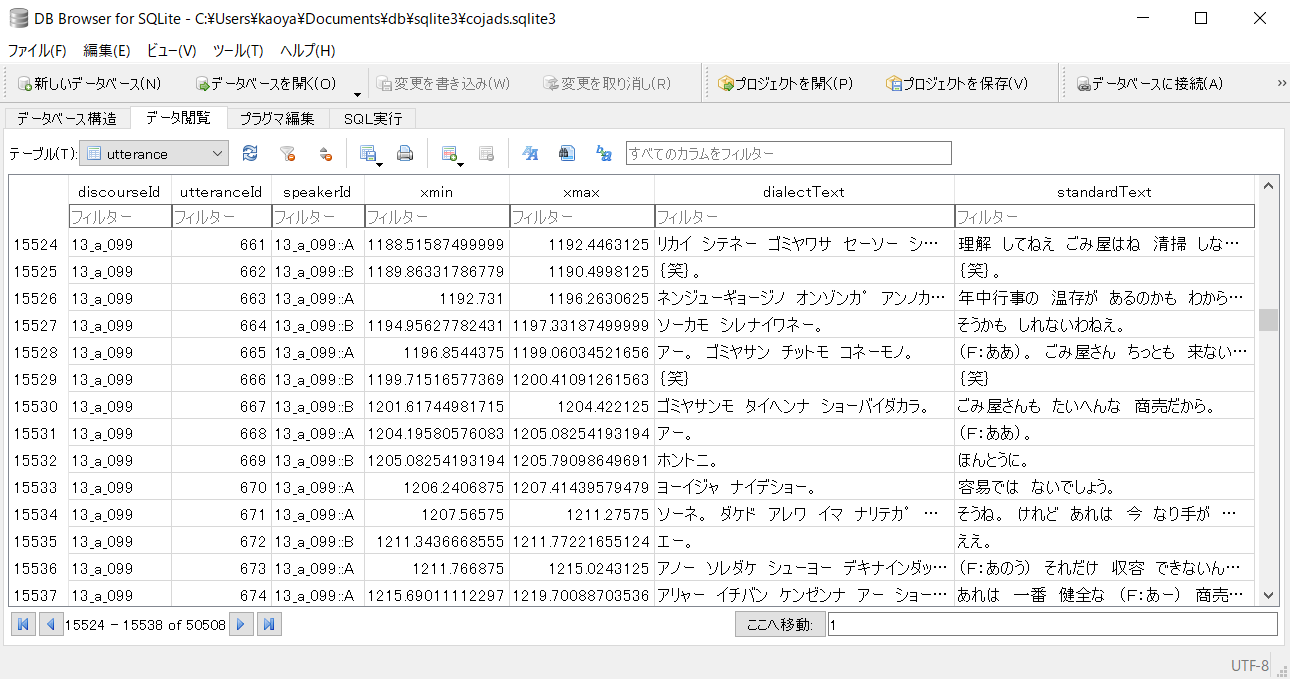
ひとつ気がかりな点としては、この手法では実は外部キー制約がきちんと働いていないであろう点です。ただ今回ここには目をつぶることにします。
補足
この手法では末尾が 099 のファイルだけうまく変換できます。それ以外のファイルは「編集担当者」などメタデータ中に空欄になっている箇所があるため、,, のように CSV 上でコロンが連続しています。Windows バッチファイルには、先ほど利用したように delimiter を指定して文字列を分割する機能がありますが、このように delimiter が連続している場合はその部分が無視されるようで、099 とそれ以外のファイルで挿入する場所がずれてしまいます。何それ?
これはマジックナンバーを用いて処理を進めていた弊害ですね(伏線回収)。素直に Python や JavaScript で書いて、見出し行を利用して辞書や連想配列に変換して、そこから挿入処理を行なっていればこんなことには……。ただ、一時的な対処法としては、処理にかける前に CSV の ,, をすべて , , に置換しておけば正しく処理できます。私は面倒くさいので Python で変換しました。
次回予告
PHP Laravel でデータベースを操作してみます。
-
DB Browser for SQLite などの GUI ツールは文字コードを指定しての CSV 読み込みに対応していますが、コマンドラインツールはたぶん対応していないのではないかと思います。 ↩
-
バッチに
continueやbreakのような便利なものはありません。 ↩ -
2行目のみ処理する方法としては、ループ内にインクリメントする変数を用意して、その変数が2以下のときしかループ内を実行しないようにIFブロックを組む手法も考えましたが、変数代入のタイミングが変でやっぱりよく組めませんでした。 ↩
-
実際には現在サイトで公開されている CSV そのままではなく、手作業で様々なノイズを取り除いたものを使用しています。 ↩