はじめに
Google Document や NotebookLM からいいパワポを作成しても、「それを社内指定のデザインテンプレート(PowerPoint)に転記する作業」 に絶望したことはありませんか?
Markdownからスライドを生成するツール(Marp等)は便利ですが、「会社のロゴ位置」「フォント指定」「独自のあしらい」といった厳密な社内レギュレーションを守ろうとすると、CSSの調整だけで日が暮れてしまいます。
そこで今回は、「デザインはPowerPointの機能(スライドマスター)に任せ、Pythonは文字を流し込むことだけに集中する」 というアプローチで、社内準拠の資料作成を自動化するワークフローを構築しました。
実現するアーキテクチャ
この仕組みの肝は、Pythonでデザインをコードから描画するのではなく、**「既存の .pptx ファイルを金型(テンプレート)として利用する」**点です。
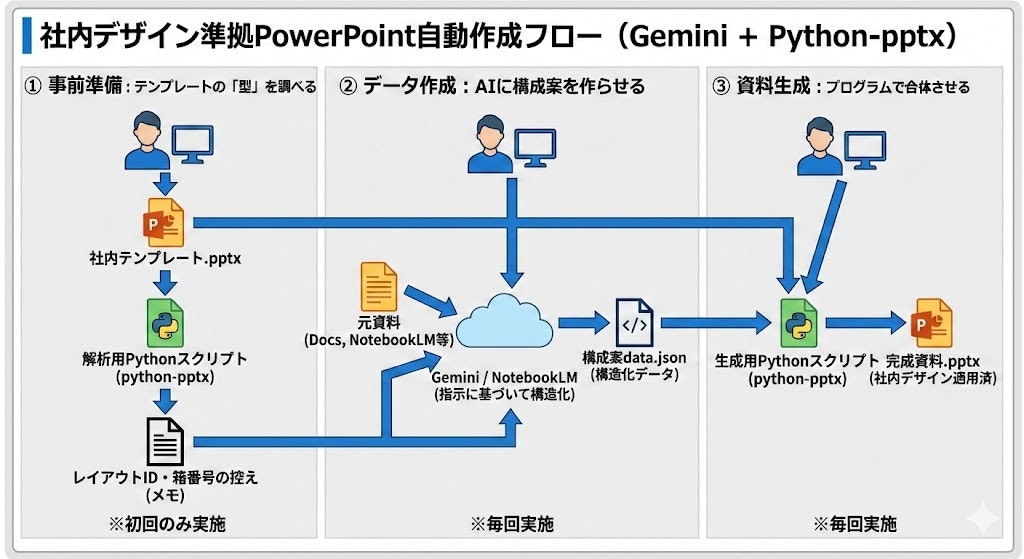
-
テンプレート解析: 社内
.pptxの「どこに文字が入るか(プレースホルダーID)」を特定する。 - データ構造化 (Gemini): 原稿を、テンプレートのIDに合わせた JSON データに変換する。
- スライド生成 (Python): テンプレートに JSON のデータを流し込んで保存する。
技術スタック
- Python 3.x
- python-pptx: PowerPoint操作ライブラリ
- Gemini (または NotebookLM): 非構造化テキストの構造化(JSON化)担当
Step 1. テンプレートの「見えないID」を解析する
python-pptx でテンプレートを扱う際、最大の障壁となるのが「このテキストボックスのIDは何番なのか?」が目視では分からない点です。
まずは、テンプレートを読み込み、全てのプレースホルダーに「自分のID」を書き込ませる解析スクリプトを実行します。
import sys
from pptx import Presentation
# 解析したい社内テンプレート
INPUT_FILE = "corporate_template.pptx"
OUTPUT_GUIDE = "layout_guide.pptx"
def analyze():
try:
prs = Presentation(INPUT_FILE)
except FileNotFoundError:
print("Error: テンプレートファイルが見つかりません")
return
guide_prs = Presentation(INPUT_FILE) # 解説用
print(f"--- Layout Analysis ---")
for i, layout in enumerate(prs.slide_layouts):
print(f"Layout ID: {i} ({layout.name})")
# 解説用スライドを追加
slide = guide_prs.slides.add_slide(guide_prs.slide_layouts[i])
if slide.shapes.title:
slide.shapes.title.text = f"Layout ID: {i}\n{layout.name}"
# 各プレースホルダーの中にIDを書き込む
for shape in layout.placeholders:
ph_idx = shape.placeholder_format.idx
print(f" - Placeholder ID: {ph_idx} ({shape.name})")
try:
# 実際のPPT上にIDを印字する
# (has_text_frameでテキスト入力可能か判定するのが無難)
if shape.has_text_frame:
slide.placeholders[ph_idx].text = f"【ID: {ph_idx}】\n{shape.name}"
except:
pass # 書き込めないタイプは無視
guide_prs.save(OUTPUT_GUIDE)
print(f"解析完了: {OUTPUT_GUIDE} を確認してください。")
if __name__ == "__main__":
analyze()
これによって生成された layout_guide.pptx を見ると、「表紙のタイトルは ID:0」「本文の箇条書きは ID:1」といった情報が一目瞭然になります。
Step 2. AIによる構造化データの作成
次に、Gemini(またはNotebookLM)に対して、原稿をこの「ID」に準拠したJSONに変換させます。
ここでのポイントは、プロンプトに**「デザインのカタログ(メニュー表)」を含めること**です。これにより、テンプレート特有のデザイン(2列比較など)をAIに正しく選択させることができます。
Geminiへのプロンプト例:
以下の原稿を、PowerPoint生成用のJSON形式に変換してください。
【デザイン・レイアウト選択ルール】
内容は以下のLayout IDを適切に使い分けてください。
- **Layout ID: 0 (表紙)**: 最初の1枚のみ使用。
- **Layout ID: 1 (通常)**: 一般的なテキスト用。
- **Layout ID: 4 (2列比較)**: 「メリット・デメリット」や「A案・B案」の比較時に使用。
- 左側(ID:1)に項目、右側(ID:2)に詳細を入れること。
【出力JSONフォーマット】
[
{
"layout_id": 0,
"placeholders": { "0": "タイトル", "1": "サブタイトル" }
},
...
]
Step 3. Pythonによる流し込み(生成)
最後に、JSONデータをテンプレートに流し込みます。
import json
from pptx import Presentation
TEMPLATE_FILE = "corporate_template.pptx"
DATA_FILE = "content.json"
OUTPUT_FILE = "result.pptx"
def generate():
prs = Presentation(TEMPLATE_FILE)
try:
slides_data = json.load(open(DATA_FILE, 'r', encoding='utf-8'))
except FileNotFoundError:
print("Error: JSONファイルが見つかりません")
return
for page in slides_data:
# 指定されたレイアウトを取得
layout_id = page["layout_id"]
# 存在チェック
if layout_id >= len(prs.slide_layouts):
continue
slide = prs.slides.add_slide(prs.slide_layouts[layout_id])
# 各プレースホルダーにテキストを注入
for ph_id_str, text in page["placeholders"].items():
try:
ph_id = int(ph_id_str)
slide.placeholders[ph_id].text = text
except KeyError:
print(f"Warning: ID {ph_id} not found in layout {layout_id}")
except ValueError:
pass
prs.save(OUTPUT_FILE)
print(f"生成完了! {OUTPUT_FILE} が作成されました。")
if __name__ == "__main__":
generate()
この手法のメリット・デメリット
実際に運用してみて感じた特徴をまとめます。
メリット
-
デザイン再現性が100%
- プログラムで座標指定して描画するのではなく、正規の
.pptxテンプレートを使うため、フォント、ロゴ位置、背景装飾などが完全に社内規定通りになります。
- プログラムで座標指定して描画するのではなく、正規の
-
デザインとデータの分離
- 「デザインを変えたい」場合はテンプレート(スライドマスター)を編集するだけ。「内容を変えたい」場合はJSONを変えるだけ。Pythonコードを修正する必要がありません。
-
特殊レイアウトへの対応力
- 「3列比較」「画像メイン」などの複雑なレイアウトも、事前にテンプレート側に枠を作っておけば、AIへの指示(ID指定)だけで呼び出せます。
デメリット・課題
-
初回セットアップの手間
- テンプレートのLayout IDやPlaceholder IDを調査し、プロンプト用の「メニュー表」を作る初期コストがかかります。
-
「枠」の制約
- 基本的には「用意された枠(プレースホルダー)に文字を入れる」ことしかできません。「動的に図形を矢印で繋ぐ」「グラフを生成する」といった高度な描画には不向きです(そこだけ手作業で行う運用が現実的です)。
まとめ
「社内デザイン遵守」という要件において、Pythonですべてを描画しようとするのは茨の道です。
「PowerPointの強力なテンプレート機能」と「LLMの構造化能力」を組み合わせ、Pythonを単なる接着剤として使うこのアプローチこそが、実務における最適解ではないでしょうか。
NotebookLMで作った要約を、ものの数秒で社内フォーマットのスライドに変換できた瞬間は、かなりの快感です。ぜひ試してみてください。