はじめに
LLMアプリケーション開発において、「プロンプトエンジニアリング」は避けて通れない道です。特に画像生成(Image Generation)の領域では、「8k resolution」「cinematic lighting」といった呪文のようなキーワードを試行錯誤する作業に多くの時間を費やしていませんか?
今回は、スタンフォード大学発のLLMフレームワーク DSPy と、Googleのマルチモーダルモデル Gemini を組み合わせ、「画像生成プロンプトの最適化を完全自動化する」 アプローチを紹介します。
なぜ DSPy なのか?
DSPy (Declarative Self-improving Language Programs) は、LLMへの指示を「手書きのプロンプト」ではなく「プログラム(モジュールと最適化)」として記述するフレームワークです。
通常、DSPyはテキスト生成タスク(RAGや要約など)で使われますが、その強力なOptimizer(最適化機構) は、画像生成タスクにも応用可能です。
従来の課題
画像生成AIへの指示出しには、以下の課題がありました。
- 評価が主観的: 生成された画像が良いかどうかは、人間が見ないとわからない。
- 試行錯誤のコスト: プロンプトを微修正しては生成し直す、という泥臭い作業が必要。
今回のアプローチ:Visual Metric
DSPyの「Metric(評価関数)」の中に、画像を理解できるAI(VLM) を組み込みます。
- DSPyがプロンプトを書く
- 画像生成モデルが描く
- VLM(Gemini 1.5 Pro/Flash)がその画像を見て採点する
- 高得点だったプロンプトをDSPyが学習し、自己修正する
このループを回すことで、「VLMが合格点を出すような画像を生成できるプロンプト」 をDSPyが勝手に学習してくれます。
アーキテクチャ
システム全体のフローは以下のようになります。
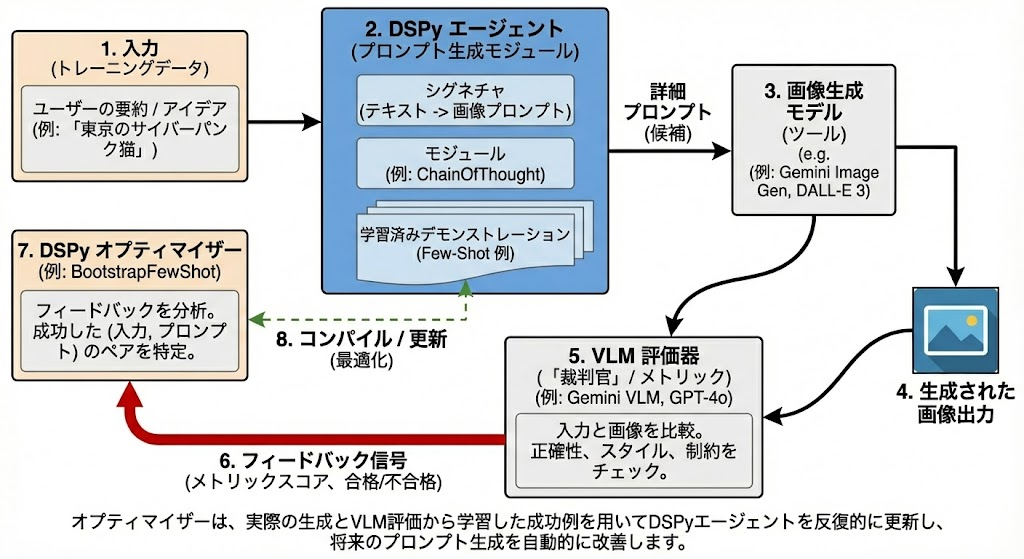
- Input: ユーザーの曖昧なアイデア(例:「売上が急増しているスライド」)
- DSPy Module: 詳細な画像生成プロンプトを作成
- Tool: 実際に画像を生成(Gemini Image Generation / DALL-E 3等)
- VLM Metric: 生成された画像と元のアイデアを比較し、内容が正しいか判定
- Optimizer: 成功したパターン(入力とプロンプトのペア)をFew-Shot事例としてモジュールに登録(コンパイル)
実装
実際に Python と Google Gemini API を使って実装してみましょう。
1. 前提条件
pip install dspy-ai google-generativeai pillow
2. ツール定義(画像生成とVLM評価)
まず、DSPyの外側で動作するツール関数を定義します。ここが「目」と「手」になります。
import dspy
import os
import io
import PIL.Image
import google.generativeai as genai
from dspy.teleprompt import BootstrapFewShot
# APIキーの設定
genai.configure(api_key=os.environ["GOOGLE_API_KEY"])
# モデル設定
IMAGE_GEN_MODEL = 'gemini-2.5-flash-image' # 画像生成用
VLM_MODEL = 'gemini-1.5-flash' # 評価用
DSPY_LM = "gemini/gemini-1.5-flash" # DSPyの思考用
# --- ツール1: 画像生成 ---
def generate_image_tool(prompt: str) -> PIL.Image.Image:
"""プロンプトを受け取り、実際に画像を生成して返す"""
try:
model = genai.ImageGenerationModel(IMAGE_GEN_MODEL)
response = model.generate_images(prompt=prompt, number_of_images=1, aspect_ratio="16:9")
image_bytes = response.images[0].image_bytes
return PIL.Image.open(io.BytesIO(image_bytes))
except Exception as e:
print(f" [Gen Error] {e}")
return PIL.Image.new('RGB', (100, 100), color='black') # 失敗時は黒画像
# --- ツール2: Visual Metric (VLMによる評価) ---
def vlm_evaluate_tool(original_text: str, image: PIL.Image.Image) -> bool:
"""
VLMを使って画像と元のテキストを比較し、
内容が正しく反映されていれば True を返す
"""
model = genai.GenerativeModel(VLM_MODEL)
prompt = f"""
あなたは厳しい品質管理AIです。
「元のテキスト(Original Text)」と「生成された画像(Generated Image)」を見比べてください。
Original Text: {original_text}
Task:
画像がテキストの内容を視覚的に正しく表しているか判定してください。
- テキストに含まれる具体的な数字(例: "120%")が画像内に描かれていますか?
- ビジネススライドとして適切なレイアウトですか?
合格なら 'TRUE'、不合格なら 'FALSE' とだけ答えてください。
"""
try:
response = model.generate_content([prompt, image])
return "TRUE" in response.text.strip().upper()
except Exception as e:
return False
3. DSPy モジュールと Metric の定義
ここがDSPyの核心部分です。
# --- Signature: 入出力の定義 ---
class SummaryToImagePrompt(dspy.Signature):
"""要約テキストを入力として受け取り、画像生成AIのための詳細な英語プロンプトを作成する。"""
summary = dspy.InputField(desc="スライドの要約テキスト (日本語)")
image_gen_prompt = dspy.OutputField(desc="画像生成AIに入力するための詳細な英語プロンプト")
# --- Module: 処理の定義 ---
class SlidePromptGenerator(dspy.Module):
def __init__(self):
super().__init__()
# ChainOfThoughtを使うことで「どのような画風にすべきか」の思考プロセスを含める
self.prog = dspy.ChainOfThought(SummaryToImagePrompt)
def forward(self, summary):
return self.prog(summary=summary)
# --- Metric Wrapper: DSPy用の評価関数 ---
def visual_metric_fn(example, pred, trace=None):
"""
DSPyのOptimizerが呼び出す関数。
ここで「生成 -> VLM判定」の重い処理を行う。
"""
summary_input = example.summary
generated_prompt = pred.image_gen_prompt
print(f"\n[Metric] Testing Prompt: {generated_prompt[:30]}...")
# 1. 画像を作る
img = generate_image_tool(generated_prompt)
# 2. VLMに見せる
is_good = vlm_evaluate_tool(summary_input, img)
print(f" -> Result: {'✅ PASS' if is_good else '❌ FAIL'}")
return is_good
4. コンパイル(最適化)の実行
最後に、BootstrapFewShot を使ってモジュールを最適化します。
これが「プロンプトエンジニアリングの自動化」です。
def main():
# LMのセットアップ
lm = dspy.LM(DSPY_LM, api_key=os.environ["GOOGLE_API_KEY"])
dspy.settings.configure(lm=lm)
# 訓練データ(入力のみでOK。正解プロンプトはDSPyが見つける)
train_data = [
dspy.Example(summary="売上高: 10億円, 前年比: 120%達成, グラフ: 右肩上がり").with_inputs("summary"),
dspy.Example(summary="プロジェクトX: 進捗率 80%, 課題: 人員不足, 状態: 注意").with_inputs("summary"),
]
# 最適化前のモジュール
module = SlidePromptGenerator()
print("--- 最適化開始 ---")
# BootstrapFewShot:
# 教師データを使って推論し、MetricがTrueになった「成功事例」だけを
# Few-Shotとして自動的に収集・登録する
optimizer = BootstrapFewShot(metric=visual_metric_fn, max_bootstrapped_demos=2)
compiled_module = optimizer.compile(module, trainset=train_data)
print("--- 最適化完了 ---")
# テスト実行
test_input = "2025年目標: 新規事業の立ち上げ, 予算: 5000万円"
pred = compiled_module(summary=test_input)
print(f"最適化されたプロンプト:\n{pred.image_gen_prompt}")
# 最終確認
final_img = generate_image_tool(pred.image_gen_prompt)
final_img.show()
if __name__ == "__main__":
main()
何が起きているのか?
このコードを実行すると、以下のプロセスが自動で行われます。
- DSPyが
train_dataの入力に対してプロンプト案を生成します。 -
visual_metric_fnが実際に画像を生成させ、VLMに評価させます。 - VLMが「FAIL(不合格)」と言えば、DSPyはその試行を捨てます。
- VLMが「PASS(合格)」と言えば、DSPyは 「この入力に対して、こういうプロンプトを書いたら上手くいった」 という事例(Demonstration)を記憶します。
- 最終的な
compiled_moduleは、集めた成功事例を Few-Shot としてプロンプトに含んだ状態で推論するようになります。
結果として、人間が一切指示しなくても、「VLMが合格を出すような(=数字が正確で、レイアウトが綺麗な)画像を生成するプロンプトの書き方」 を学習したAIエージェントが完成します。
まとめ
DSPyの柔軟なインターフェースと、GeminiのようなVLMモデルを組み合わせることで、これまで人間の感覚に頼っていた「画像生成」の領域にも、エンジニアリング的な評価と改善のループを持ち込むことができます。
「プロンプトをどう書くか」ではなく「どう評価するか(Metric)」を設計するのが、これからのAIエンジニアの仕事になるかもしれません。