はじめに
みなさん、ポケモンやってますか?私は10年振りくらいに買いましたサンタさんにもらいました。
ガチ勢目指して、年末年始は家に引きこもって厳選予定です。
AdventCalendarはポケモンネタで何かできないかなーと思っていたので、最近気になっている深層学習モデルの判断根拠を示す手法を、ポケモン御三家分類を例に試してみました。
※手法の説明やデータセットの準備も含めて記載していくので、結果だけ知りたい方は結果まで飛ばしてください
深層学習モデルの判断根拠を示す手法:TCAVとは
深層学習は様々な分野で社会実装が進み始めていますが、モデルが何を根拠に判断しているのかはブラックボックスになりがちです。
近年、モデルの「説明性」「解釈性」に関する研究が進められています。
そこで今回は、ICML2018に採択されたQuantitative Testing with Concept Activation Vectors (TCAV) という手法を試してみたいと思います。
論文概要
- ニューラルネットワークモデルの判断根拠を示す手法
- 従来のピクセルごとに重要度を算出するような手法ではなく、予測クラスの概念(色、性別、人種など)の重要度を示す
- 各画像に対する説明(≒ローカル)ではなく、各クラスに対する説明(≒グローバル)を生成するので、人間にわかりやすい説明性を持つ
- MLモデルの専門知識がなくても説明を理解することができる
- 解釈したい既存モデルに対して、再学習や変更の必要はない
Concept Activation Vectors (CAV)の概念
概念画像とランダムな反例の間で線形分類器をトレーニングし、決定境界に直交するベクトルを取得することにより、CAVを導出します。
(下の図見た方が早い)。
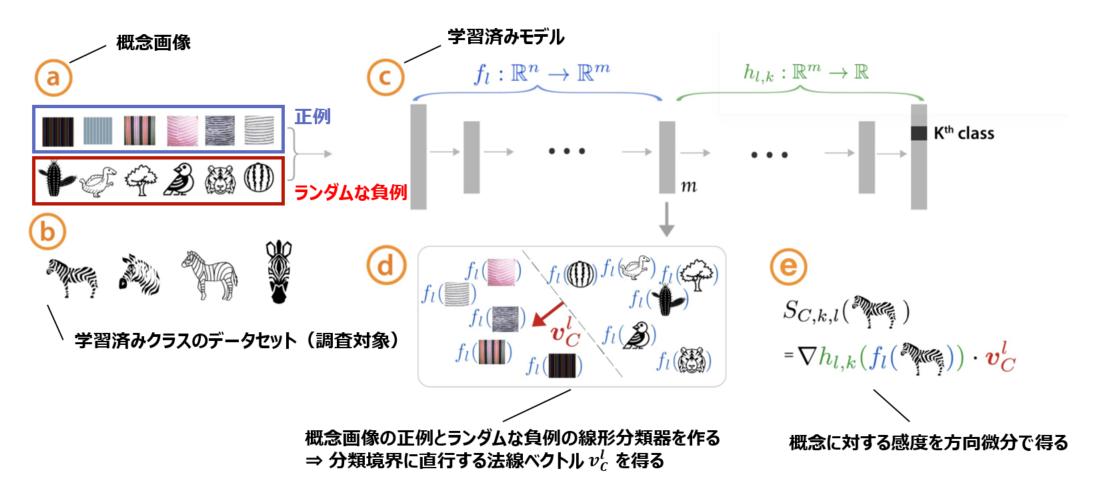
※より詳細な論文メモはこちらに置いてありますので、ご興味ある方はご覧ください
何がわかる?
-
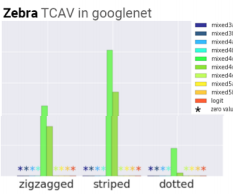
モデルが学習している**「概念」を人間が解釈可能**な形で定量化できる
例:「シマウマ」分類において「ドット柄」より「ストライプ柄」を学習している
また、任意の層での学習を見ることもできるので、浅い層/深い層でどの程度粗い/細かい特徴を捉えているかも見ることができます。
-
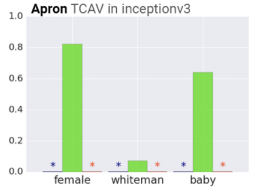
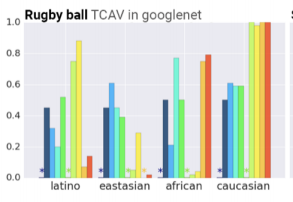
データセットのバイアスがわかる
例:「エプロン」クラスにおいて、「女性」の概念が関連している、「ラグビーボール」クラスにおいて、「白人」の概念が関連している
-
画像ソーターとして使える(概念画像との類似性に基づいて並び替えができる)
まず適当な分類器を作る
今回はTCAVを動かしてみるのが目標なので、簡単なタスクにしました。
ポケモン御三家分類器を作ります。
データセットの準備
①クローリング
icrawlerを使って下記の画像を収集しました。
コード貼っておきます。
import os
from icrawler.builtin import GoogleImageCrawler
save_dir = '../datasets/hibany'
os.makedirs(save_dir, exist_ok=True)
query = 'ヒバニー'
max_num = 200
google_crawler = GoogleImageCrawler(storage={'root_dir': save_dir})
google_crawler.crawl(keyword=query, max_num=max_num)
②前処理
最低限の処理だけです。
- ①クローリングで取得した画像を手動で正方形にクロップ
- 256×256にリサイズ
- train/val/testに分割
御三家画像サンプル
こんな感じで画像が集まりました。
(ちなみに私はヒバニー即決でした。炎タイプ大好き)
| ヒバニー | メッソン | サルノリ |
|---|---|---|
 |
 |
 |
| 156枚 | 147枚 | 182枚 |
以下のような御三家以外のポケモンや、キャラクターの画像、デフォルメされすぎているイラストなども紛れていたので目検で除外しています。
キバナサンカッコイイ



分類器作成
シンプルなCNNです。

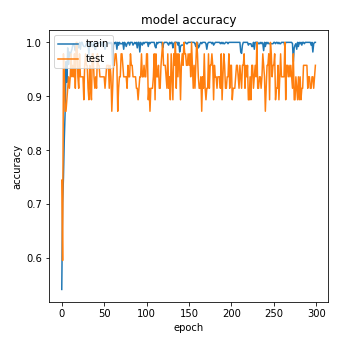
テストデータの画像が少ない(15枚程度)のでテストデータのAccuracyはバタついていますが、TCAVの検証には十分であろう精度の分類モデルができました。
CAVの計算に**.pbファイル**が必要になるので、.pbでモデルを保存します。
次に、モデルが何を学習しているのか見るための準備をします。
TCAVの実行準備
下記ステップに沿って準備していきます。
(今回使ったコードはこちらに置いてあります。あとでちゃんとREADME書きます。。。)
Step1:概念画像(正例と負例)の準備
正例画像に用意したのは下記の画像です。
色を見て御三家を分類するのでは、という仮説のもと数色準備しました。
(10~20枚でも動きはしますが、50~200枚くらいあった方がよいとのことです)
正例画像サンプル
| 白 | 赤 | 青 | 黄 | 緑 | 黒 |
|---|---|---|---|---|---|
 |
 |
 |
 |
 |
 |
| 22枚 | 20枚 | 15枚 | 18枚 | 21枚 | 17枚 |
こういう複数カラーが混ざりすぎているものは除外しています

負例画像サンプル
上記のどの正例にも該当しないものが望ましいです。(今回の場合、どの色にも該当しないというのは難しいですが。。)
今回はCaltech256からランダムに画像を取ってきました。
ここまでに集めた画像たちのディレクトリ構成は下記のようになります。
概念画像のセットは全てサブディレクトリにする必要があります。
├── datasets
│ ├── for_tcav # TCAV用のデータセット
│ │ ├── black
│ │ ├── blue
│ │ ├── green
│ │ ├── hibany
│ │ ├── messon
│ │ ├── random500_0
│ │ ├── random500_1
│ │ ├── random500_2
│ │ ├── random500_3
│ │ ├── random500_4
│ │ ├── random500_5
│ │ ├── red
│ │ ├── sarunori
│ │ ├── white
│ │ └── yellow
│ └── splited # 画像分類モデル作成用データセット
│ ├── test
│ │ ├── hibany
│ │ ├── messon
│ │ └── sarunori
│ ├── train
│ │ ├── hibany
│ │ ├── messon
│ │ └── sarunori
│ └── validation
│ ├── hibany
│ ├── messon
│ └── sarunori
Step2:モデルラッパーを実装する
まずクローンしてきます。
git clone git@github.com:tensorflow/tcav.git
ここでは、モデルの情報をTCAVに伝えるためのラッパーを作ります。
このクラスを tcav/model.py に追記します。
class SimepleCNNWrapper_public(PublicImageModelWrapper):
def __init__(self, sess, model_saved_path, labels_path):
self.image_value_range = (0, 1)
image_shape_v3 = [256, 256, 3]
endpoints_v3 = dict(
input='conv2d_1_input:0',
logit='activation_6/Softmax:0',
prediction='activation_6/Softmax:0',
pre_avgpool='max_pooling2d_3/MaxPool:0',
logit_weight='activation_6/Softmax:0',
logit_bias='dense_1/bias:0',
)
self.sess = sess
super(SimepleCNNWrapper_public, self).__init__(sess,
model_saved_path,
labels_path,
image_shape_v3,
endpoints_v3,
scope='import')
self.model_name = 'SimepleCNNWrapper_public'
これで準備が完了します。早速結果を見てみます。
結果
各クラスで重要視している概念(今回は色)を見てみます。
*印がついていない概念が重要視しているものです。
| ヒバニークラス | メッソンクラス | サルノリクラス |
|---|---|---|
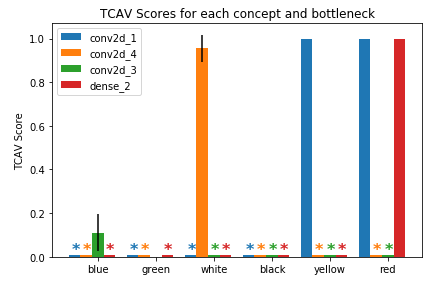 赤・黄色・白 赤・黄色・白 |
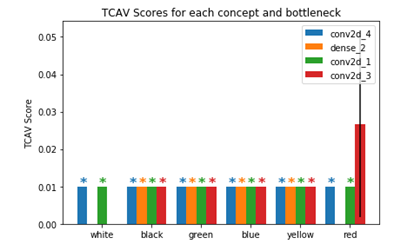 赤 (!?) 赤 (!?) |
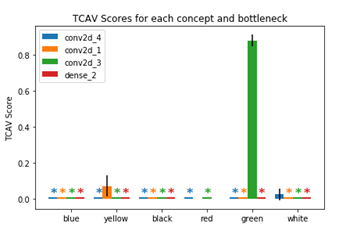 緑 緑 |
|
|
|
ヒバニーとサルノリはそれっぽい結果かなと思います。
メッソンに関しては謎なので要考察です。
実験中に、試行回数や概念画像・ターゲット画像の枚数を変えると結構結果が変わるので、もう少し考察が必要かなと思っています。
概念画像の選び方によっても変わりそうなので、色々試し甲斐がありそうです。
まとめ
ニューラルネットワークモデルの判断根拠を示す手法を試してみました。
人間が解釈しやすく、**"直観的にそれっぽい"**結果が得られました。
今回は御三家分類ということで概念画像として色を選びましたが、概念画像を準備するのが大変ですね。。
諸々準備は必要ですが、モデルを学習しなおす必要はないし、一連の流れを一回試して慣れちゃえば楽に使えると思います。
是非試してみてください!