はじめに
株式会社ピーアールオー(あったらいいな!を作ります) Advent Calendar 2022の3日目になります。
前日は 私の「Wingetで簡単!開発PCセットアップ(Windows)」でした。
MLをやってみたいけど
MLを気軽に試してみたいけど、最大の障壁となるのはやはり高価なGPUが必要という点かと思います。PCゲームをやる方ならまだしも、そうでない人間には数万~数十万もするdGPU/eGPUを用意することは簡単ではありません。特にこの分野ではcudaコアを有するNVIDIAのGPUが一強という感じですが、まともに使えそうなボードをそろえようとするとやはり十万程度の出費が必要になります(この辺は諸説あるでしょうが・・・)。
もちろん、CPUのみで挑むというやり方もありますが、あまりに時間がかかるのはやはり敬遠しがちになります。また、クラウドGPUみたいなものもあるので、そういうものを使えば初期費用を抑えて実行することはできるのでしょうけど、それはそれで壁があるんですよね。。。
できれば私のようなライト勢は、手持ちの機材でサクッと動かして概要だけ理解したいというのが正直なところです。
対して、最近はCPU統合型GPU(iGPU)の性能も向上してきていると聞きます。特にIntel Iris xeやAMD Ryzenに搭載されたRadeonといった最新のiGPUは最安ランクのGPU(1060とか)と同等の性能を持っているなどの情報を見るようになってきました。
こうした情報を見るにつけ、iGPUで機械学習を実行することはできないのかな・・・と思っていて改めて調べたんですが、いろいろと選択肢が出てきているようだったので、試してみようというのが本稿の内容です。
非Nvidia GPUでMLできるライブラリ
ほかにもあるのでしょうが、ちょっと調べた感じだと以下が見つかりました。
| ライブラリ | 特徴 |
|---|---|
| PlaidML | AMD Radeon系のGPUをターゲットにしたライブラリ?MacやLinuxでも動作する。 |
| DirectML | Microsft謹製。Windows10、11で動作する。 |
今回はWindows11上での情報が多かったDirectMLを使ってみようと思います。
DirectMLはcudaの代わりにDirectX12を使うことで、非NvidiaのGPUでもMLを可能にしているそうです。したがって動作性能は多少劣ったとしても、導入すればTensorflowなどもある程度動かせるようになるはずです。
使ってみる
directMLの導入
環境がとっ散らかりそうだったので、初めに仮想環境を用意しておきます。
python -m venv dlc
.\dlc\Scripts\Activate.ps1
必要なパッケージをインストール
pip install diffusers==0.3.0
pip install transformers
pip install onnxruntime
私の環境ではtransformersのインストール時にエラーが発生しました。
error: can't find Rust compiler
Rustの開発環境が必要らしいので、Wingetで導入。
winget install Rustlang.Rust.MSVC
次はこのエラー
error: Microsoft Visual C++ 14.0 or greater is required. Get it with "Microsoft C++ Build Tools": https://visualstudio.microsoft.com/visual-cpp-build-tools/
2022のほうでいいのかな・・・。
C:\Windows\System32>winget search buildtools
名前 ID バージョン ソース
----------------------------------------------------------------------------------------
Visual Studio Build Tools 2022 Microsoft.VisualStudio.2022.BuildTools 17.4.2 winget
Visual Studio Build Tools 2019 Microsoft.VisualStudio.2019.BuildTools 16.11.21 winget
インストール
winget install Microsoft.VisualStudio.2022.BuildTools
が、エラーは変わらず。
調べてみると、どうもGUIインストーラーにて構成の変更が必要な模様。
仕方ないのでエラーテキストにあったDLページからインストーラーをDLし、実行。
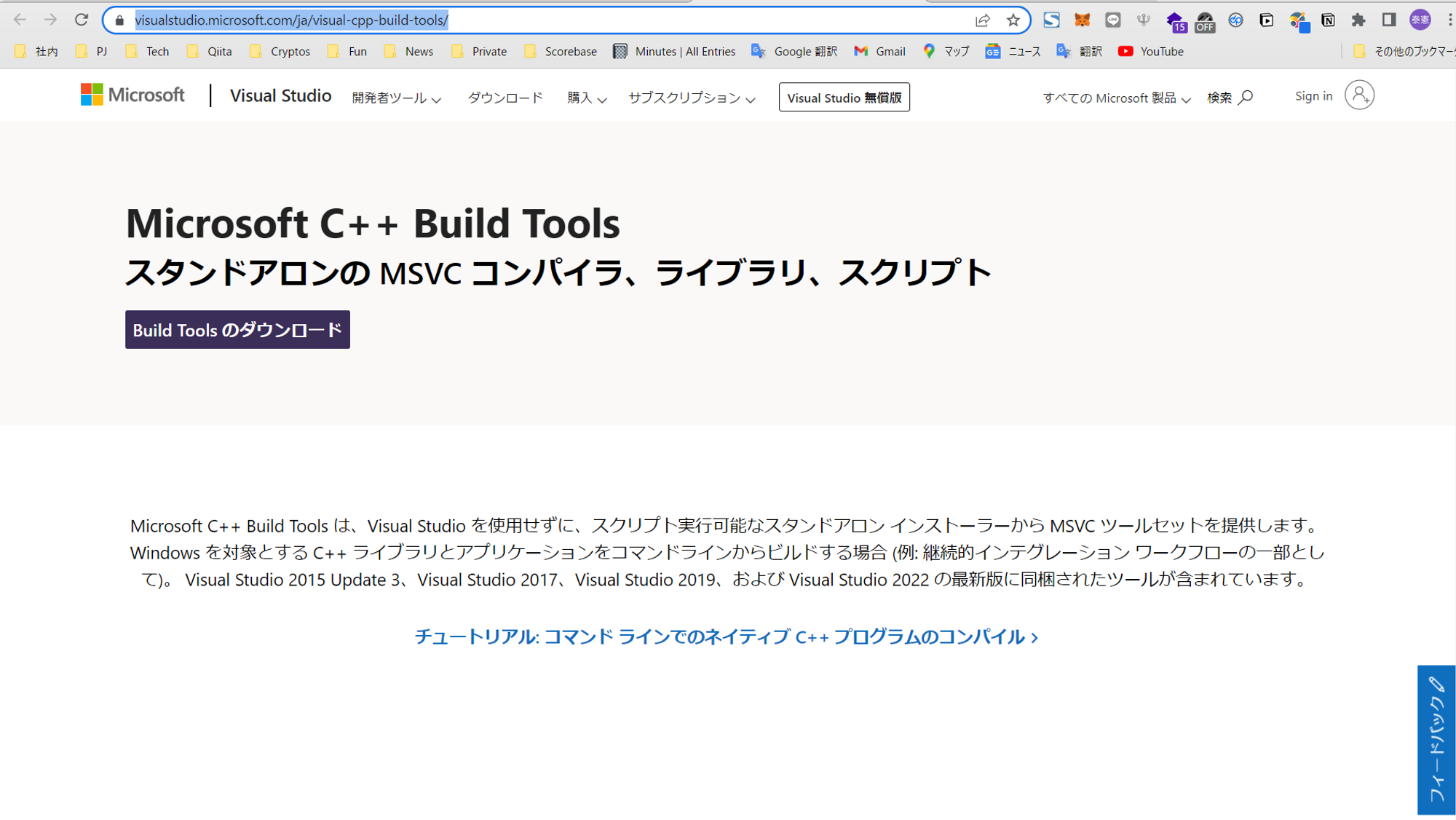
Visual Studio Build Toolsから「変更」を選択
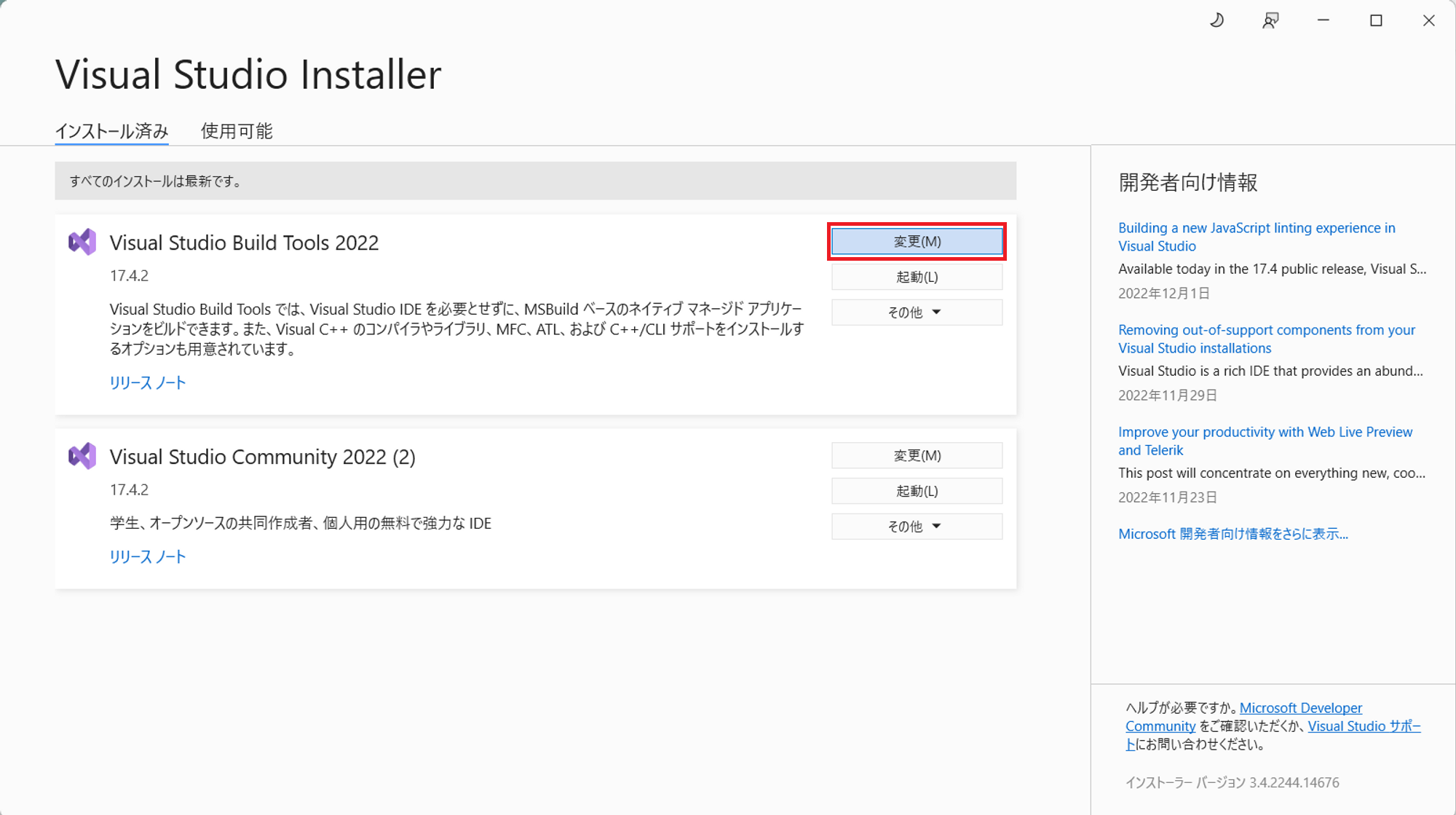
C++によるデスクトップ開発を有効にする
さらにこのエラーが発生。numpyがインストールできない。
note: This error originates from a subprocess, and is likely not a problem with pip.
ERROR: Failed building wheel for numpy
Failed to build numpy
ERROR: Could not build wheels for numpy, which is required to install pyproject.toml-based projects
numpyは3.10までしか対応してないとのこと。ていうか、DirectMLは3.5~3.7までしか対応してなかった・・・。
気を取り直して3.7で仮想環境を再作成する。
py -3.7 -m venv dlc
再度必要なパッケージを導入してようやく準備完了。
実行してみる
動作確認
公式に倣い、tensorflow-directmlパッケージを導入して動作を確認してみます。
pip install tensorflow-directml
pythonコンソールに入り、以下でテストを実行
(dlc) PS C:\Users\owner> python
Python 3.7.9 (tags/v3.7.9:13c94747c7, Aug 17 2020, 18:58:18) [MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> from tensorflow.python.client import device_lib
C:\Users\owner\dlc\lib\site-packages\scipy\__init__.py:149: UserWarning: A NumPy version >=1.16.5 and <1.23.0 is required for this version of SciPy (detected version 1.16.4
UserWarning)
>>> device_lib.list_local_devices()
2022-12-03 18:40:39.273065: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2
2022-12-03 18:40:39.317989: I tensorflow/stream_executor/platform/default/dso_loader.cc:97] Successfully opened dynamic library C:\Users\owner\dlc\lib\site-packages\tensorflow_core\python/directml.d6f03b303ac3c4f2eeb8ca631688c9757b361310.dll
2022-12-03 18:40:39.319069: I tensorflow/stream_executor/platform/default/dso_loader.cc:97] Successfully opened dynamic library dxgi.dll
2022-12-03 18:40:39.326213: I tensorflow/stream_executor/platform/default/dso_loader.cc:97] Successfully opened dynamic library d3d12.dll
2022-12-03 18:40:39.769719: I tensorflow/core/common_runtime/dml/dml_device_cache.cc:250] DirectML device enumeration: found 1 compatible adapters.
2022-12-03 18:40:39.769961: I tensorflow/core/common_runtime/dml/dml_device_cache.cc:186] DirectML: creating device on adapter 0 (AMD Radeon(TM) Graphics)
2022-12-03 18:40:39.881219: I tensorflow/stream_executor/platform/default/dso_loader.cc:97] Successfully opened dynamic library Kernel32.dll
[name: "/device:CPU:0"
device_type: "CPU"
memory_limit: 268435456
locality {
}
incarnation: 6714692032343997380
, name: "/device:DML:0"
device_type: "DML"
memory_limit: 19489579111
locality {
}
incarnation: 16074882633434391058
physical_device_desc: "{\"name\": \"AMD Radeon(TM) Graphics\", \"vendor_id\": 4098, \"device_id\": 5761, \"driver_version\": \"31.0.12028.2\"}"
]
ちゃんとRadeonが認識されてるようです。
squeezenetを動かす
公式のsamplesにあったsqueezenetを動作させてみます。
まずは公式のgitをcloneして、その中のDirectML/TensorFlow/TF1/squeezenet/に移動したら、以下を実行します。
pip install -r requirements.txt
python train.py
そうすると以下のような感じでトレーニングが開始されます。
Train Step 0 : 0.1875
Evaluation Step 0 : 0.1
Train Step 1 : 0.1875
Train Step 2 : 0.03125
Train Step 3 : 0.0625
(中略)
Train Step 1778 : 0.625
Train Step 1779 : 0.5938
Train Step 1780 : 0.5312
Train Step 1781 : 0.6875
Train Step 1782 : 0.625
Train Step 1783 : 0.4688
Train Step 1784 : 0.6875
Train Step 1785 : 0.5312
Train Step 1786 : 0.6875
Train Step 1787 : 0.7188
Train Step 1788 : 0.6562
Train Step 1789 : 0.75
Train Step 1790 : 0.6562
Train Step 1791 : 0.75
Train Step 1792 : 0.5625
Train Step 1793 : 0.5938
Train Step 1794 : 0.4688
Train Step 1795 : 0.75
Train Step 1796 : 0.625
Train Step 1797 : 0.625
Train Step 1798 : 0.7188
Train Step 1799 : 0.5938
Train Step 1800 : 0.5938
Evaluation Step 1800 : 0.4809
無事終了すれば、1800ステップのトレーニングが行われるそうです。
私の環境では、実施完了まで5分くらいかかりました。
早速動かしてみましょう。サンプルの中に評価用の画像があるので、それを使って動作を確認してみます。
python src/predict_squeezenet.py --model_dir data --data_format NCHW --image data/cifar10_images/test/ship/0001.png
data/cifar10_images/test/ship/0001.png: predicted ship
なるほど
python src/predict_squeezenet.py --model_dir data --data_format NCHW --image data/cifar10_images/test/frog/0001.png
data/cifar10_images/test/frog/0001.png: predicted frog
いいですね
python src/predict_squeezenet.py --model_dir data --data_format NCHW --image data/cifar10_images/test/bird/0011.png
data/cifar10_images/test/bird/0011.png: predicted bird
ちゃんと動いてますね。
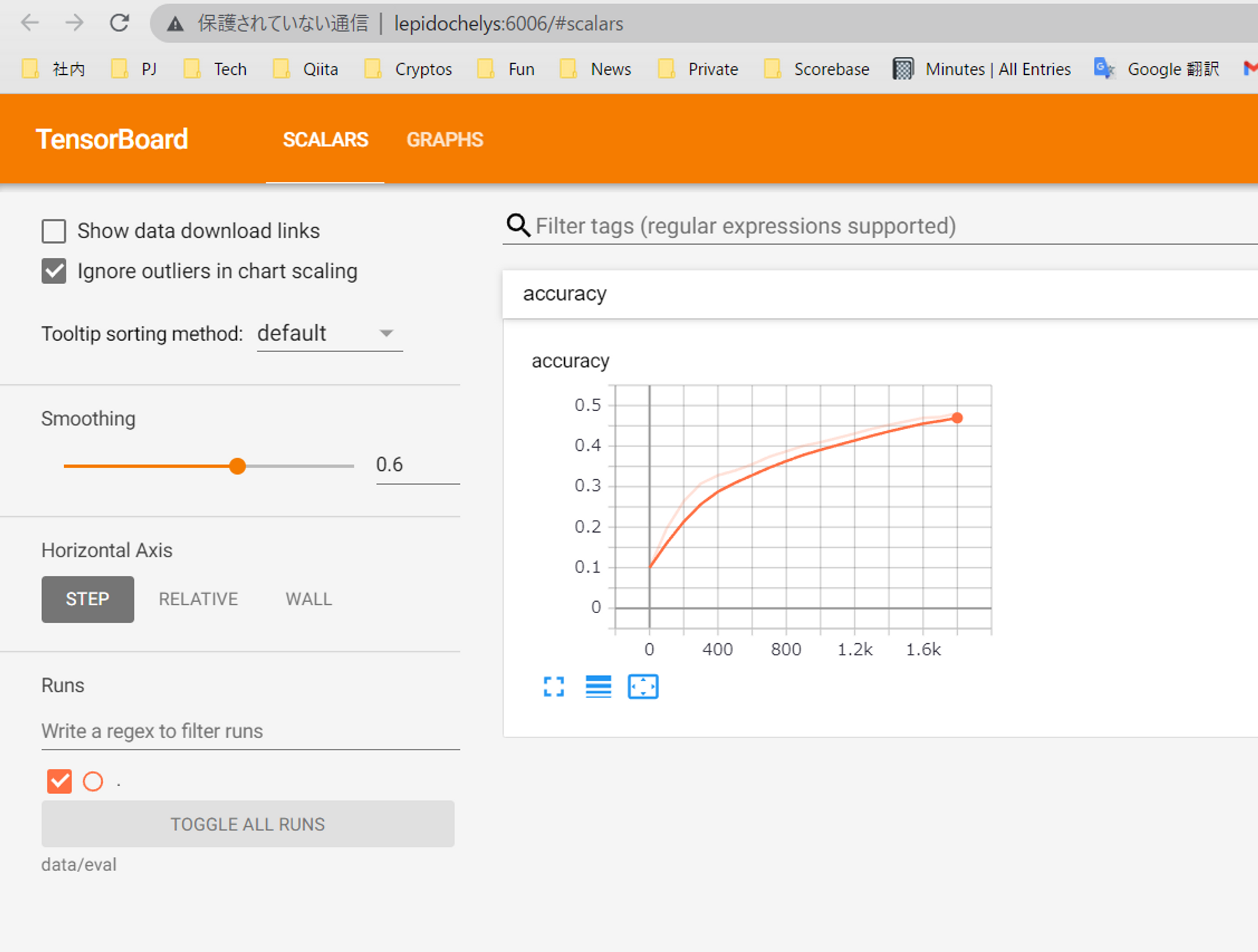
モデルの学習状況などを可視化できるtensorboardも実行できます。
tensorboard --logdir data/eval
とすると、localhost:6006で開くことができます。
これはモデルの学習精度を表しているようです。
Graphsタブでは、ノードの情報などが参照できます。細かいチューニングを行う際はこうした情報を参照することになるのですかね。
まとめ
DirectMLを使って、MLを試せる環境を作ることができました。
お試し的な使い方であれば十分使えそうなので、引き続きいろいろ試してみたいと思います。
(でもそのうち物足りなくなってNvidiaのGPUが欲しくなる可能性もありますが・・・)