機械学習初心者のためのMNIST
はじめに
Googleが提供を開始したディープラーニング用のライブラリTensorFlowについて、忘備録ついでに投稿させてもらいます。TensorFlowはTutorialの解説が詳しいので、それを日本語にしてみました。
・TensorFlowについて-> http://www.tensorflow.org/
・今回の翻訳原本-> http://www.tensorflow.org/tutorials/mnist/beginners/index.md
生粋の日本人なので違和感のある翻訳もあると思いますが、ご了承ください。
今回のTutorialは岡谷さんの著書「深層学習」の第2章に対応しているので合わせて読むと良いかもしれません。
それでは、今回作成するモデルは Soft max Regressionと言われるモデルです。
MNISTデータ
MNISTデータを読み込みます。
import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
ダウンロードデータは2つの部分に分けられます。60,000点の訓練データ(mnist.train)と10,000点のテストデータ(minist.test)です。
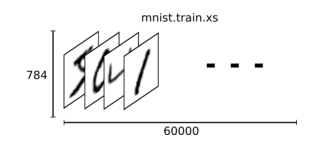
全てのMNISTデータは、手書きのデジタル画像とそれに対応するラベルのデータ、の2つの要素から成り立ちます。ここでは手書き画像をxs、ラベルデータをysと呼びます。
(ex, mnist.train.imagesとmnist.train.labels)
それぞれの手書き画像は
28 pixels × 28 pixels = 784個の数字
つまり数字の列(ベクトル)にしてしまっているわけです。
これは2次元の情報を捨ててしまっていることに対応しています。最高難度の手法ではこの2次元の情報も組み込みますが、今回はここまで考えません。
以上の結果、mnist.train.imagesはテンソル(≒ n次元行列 )となり、その形は[60000,784]です。
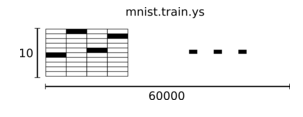
対応するラベルデータは、"one-hot ベクトル"として表現します。
ex,
0 -> [1,0,0,0,0,0,0,0,0,0,0]
3 -> [0,0,0,1,0,0,0,0,0,0,0]
つまりmnist.train.labelsは[6000,10]の配列です。
Softmax回帰
Softmax回帰は自然で単純なモデルです。もしある対象に確率を付し、他の対象にもそれぞれ確率を付したい場合にsoftmaxが役に立ちます。
(例:この画像は9である可能性が80%で、8である可能性が5%で...)
与えられた画像がある特定のクラスに所属しているということを計算でいうために、私たちはピクセルの値の重み付き合計を計算します。
そのweightは、意味を持ちます。赤い部分は「ネガティブな重み」を、青い部分は「ポジティブな重み」を表します。(*青が数字っぽくも見えるような..?)

Regressionの実行
効率的なpythonによる計算を行うために、私たちはたいていNumpyなどの、重い計算をpythonの外で行わせるライブラリを利用します。しかし、pythonに戻ってくるときに大きな計算コストがかかってしまいます。もしGPUや異なる並列計算を行いたい場合、これらは非常に好ましくありません。
TensorFlowは、一つの重い命令をpythonから独立に行わせる代わりに、関連する命令のグラフ全てをpythonの完全に外側で記述することを可能にしました。
overhead .. ハードウェアの管理やプログラム管理にかかるコスト
まずtensorflowをインポートします。
import tensorflow as tf
先に述べたような相互に関連する命令をシンボリック(象徴的)な変数を操作することで記述します。
x = tf.placeholder("float",[None,784])
xは特定にの値ではなく、それはplaceholderと呼ばれます。TensorFlowに計算を実行しろと頼むときに入力する値です。
MNIST画像の入力数値は784次元ベクトルに変換されました。これらを[None, 784]の2次元テンソルとして表現します。
他にもweightやbiasesもモデルには必要です。このようなときにVariableを用います。Variableとは変更可能なテンソルで、TensorFlowの相互作用する命令のグラフに"住んで"います。
w = tf.Variable(tf.zeros([784,10]))
b = tf.Variable(tf.zeros([10]))
今回はWとbを、0しかもっていないようなVariableとして作りました。これからW,bを学習させるので、初期値が何であったかは大して問題ではありません。
こうしてモデルを実行できます!
y = tf.nn.softmax(tf.matmul(x,W)+b)
tf.matmul(x,W)でxとWの掛け算をとり、それにbを加え、その結果をtf.nn.softmaxでSoftmax関数に代入していると思われます。xを2次元テンソルとしていたのはWとの掛け算が取れるからです。
(おそらく matmul = matrix multiple)
学習
機械学習としてなにが良いモデル化を定量的に評価するために誤差関数を用います。今回はcross-entropyと呼ばれる誤差関数を用います。
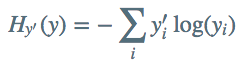
ここでyは今回予測した結果の確率分布で、y'が真の分布です。
cross-entropyを実行するために、まずは、正しい正解を入力するための新しいplaceholderを加える必要があります。
y_ = tf.placeholder("float",[None,10])
そしてcross-entropyを実行できます。
cross_entropy = -tf.reduce_sum(y_*tf.log(y))
tf.log(y)でyの各要素の対数を計算し、y_の各値との掛け算を計算し、最後にtf.reduce_sumでテンソルの全ての要素を足し合わせています。
TensorFlowでは学習は簡単に行えます。TensorFlowは自身の計算の全グラフを知っているので、自動的にbackpropagationアルゴリズムを使うことができるのです。backpropagationアルゴリズムは効率的に、どのように変数が最小化するべき誤差関数に影響するかを明らかにしてくれます。
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
今回は、TensorFlowにcross_entropyを、Gradient descentアルゴリズムを用いて、0.01のlearning rateで最小化するよう命令しています。gradient descentはシンプルな手続きで、TensorFlowはシンプルにそれぞれの変数を、誤差が小さくなる方向に少しだけ変更してくれます。
しかしTensorFlowはたくさんの最適化アルゴリズムを備えていて、それらを使うことは非常に簡単です。
モデルを訓練させる前に一つだけ、設定した変数を初期化するための命令を加えなければなりません。(*まだ実行はされていない!)
init = t.initialize_all_bariables()
ようやく、セッションを始めることができます。変数を初期化する命令を実行しましょう。
sess = tf.Session()
sess.run(init)
そして訓練を1000回繰り返します!
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
ループの各ステップで、用意した訓練データセットから100個のランダムなデータ点の"バッチ"を取得しています。そしてtrain_stepを実行し、各バッチデータを与え、placeholderを変更していきます。
ランダムなデータから成る"小さなバッチ"を使う手法は確率的訓練(stochastic training)と呼ばれていて、今回の場合はstochastic gradient descentです。
作り上げたモデルの評価
まず初めに、正しく予測を行ったものを把握します。tf.argmaxは非常に便利な関数で、いくつかの軸に沿ってテンソルが最も大きい要素をもっているその値を返してくれます。例えば、tf.argmax(y,1)は各インプットに対して最も確からしいラベルを返し、tf.argmax(y_,1)は正解のラベルを返します。そしてtf.equalで私たちの予測が当たっていたかを判定することができます。
correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(y_,1))
この結果として、ブール値のリストが返されます。扱いやすいようにFloat値の数字に変換して、平均を取ります。例えば、[True, False, True, True]は[1,0,1,1]となり平均は0.75です。
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
最後に、私たちはテストデータに対する予測の正答率を訪ねます
print sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels})
この結果は91%程度になるでしょう。