Hugging Face の transformers ライブラリの基礎として、GPT2のテキスト生成モデルを題材として、ライブラリ内のクラス構造について調査しました。
前回のおさらい
前回の記事
https://qiita.com/_kawauso_/items/523128d9b1c9722bb0a8
例)言語モデリング(テキスト生成)タスク
- 1.言語モデルは、GPT2(
gpt2-xl)を用いる - 2.トークナイザは、AutoTokenizer クラスを用いてインスタンス化する
- 内部で
gpt2-xlに適したトークナイザが自動的に選択される - 戻り値は GPT2TokenizerFast クラスのインスタンス
- 内部で
- 3.モデルは、テキスト生成タスク用の AutoModelForCausalLM クラスを用いてインスタンス化する
- 内部で
gpt2-xlに適したモデルが自動的に選択される - 戻り値は GPT2LMHeadModel クラスのインスタンス
- 内部で
import torch
from torch import Tensor
from jaxtyping import Float # torch用typingモジュール
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.models.gpt2.modeling_gpt2 import GPT2LMHeadModel
from transformers.models.gpt2.tokenization_gpt2_fast import GPT2TokenizerFast
from transformers.tokenization_utils_base import BatchEncoding
### 1. モデル名
model_name: str = "gpt2-xl"
### 2. トークナイザのロード
tokenizer: GPT2TokenizerFast = AutoTokenizer.from_pretrained(model_name)
### 3. モデルのロード
model: GPT2LMHeadModel = AutoModelForCausalLM.from_pretrained(model_name).to('cuda')
### 4. 入力の準備
# 4.1. 単語列
text: str = "The capital of Japan is"
# 4.2. エンコード
inputs: BatchEncoding = tokenizer(text, return_tensors='pt').to(model.device)
### 5. 推論
outputs: Float[Tensor, '1 tokens'] = model.generate(
inputs = inputs['input_ids'],
attention_mask = inputs['attention_mask'],
pad_token_id = tokenizer.eos_token_id, # 50256 = '<|endoftext|>'
max_new_tokens = 20,
do_sample = True,
temperature = 0.7,
top_p = 0.5,
) # -> torch.Size([1, tokens])
### 6. 結果の取得・表示
output: Float[Tensor, 'tokens'] = outputs[0]
output_text: str = tokenizer.decode(output)
print(output_text)
上記のコードに登場する
- .from_pretrained()
- .to('cuda')
- .generate()
- input_ids
- attention_mask
- do_sample
などのメソッドや引数がどのクラスに紐づいているか気になったので、今回調査した。
今回のトピック
Hugging Face の transformersライブラリの中身、特にクラス構造、を理解するために、クラス図を作成した。
GPT2のテキスト生成モデルである GPT2LMHeadModelクラス を起点にライブラリの中身を見ながら作成した。
クラス図1(サマリ、継承関係のみ)
まずは継承関係のみを可視化する。
レンダリングに時間がかかるかもしれない。
- GPT2のテキスト生成モデルである ⓪GPT2LMHeadModel クラスは、テキスト生成に限らずすべてのGPT2系モデルにとっての基底クラスである ①GPT2PreTrainedModel クラスと、テキスト生成用の共通機能を提供する ②GenerationMixin クラスを継承している
- ①は、HuggingFace上のすべての事前学習済モデルにとっての基底クラスである PreTrainedModel クラスを継承している
- ②は、モデルに連続バッチ推論機能を付与するための ContinuousMixin クラスを継承している
- ⓪以外にも、例えば、以下のクラスなどが①を継承している
- Transformer本体を表す GPT2Model クラス
- 質問応答(QA)タスク専用のモデルである GPT2ForQuestionAnswering クラス
- トークン分類タスク専用のモデルである GPT2ForTokenClassification クラス
クラス図2(サマリ、依存関係も含む)
継承関係に加えて、引数でもらってきたり(use)、戻り値として返したり(return)するクラスも含めてクラス図を描画した。
-
テキスト生成タスク専用モデルである ⓪GPT2LMHeadModel クラスは、
- Transformer本体および線形層(ヘッド)から構成されるため、③GPT2Model クラスおよび torch.nn.Linear クラスに依存している
- ⓪は、テキスト生成結果を出力するため、それを表すデータクラスである CausalMLOutputWithCrossAttension クラスに依存している
- このクラスがないと⓪は出力結果を作成・返却できない、という意味で依存している
-
⓪と同様に、
- QAタスク専用モデルも、その出力結果を表すデータクラス QuestionAnsweringModelOutput に依存している
- トークン分類タスク専用モデルも、その出力結果を表すデータクラス TokenClassificationOutput に依存している
- 入出力のデータをクラスとしてモデル化するよくあるパターン
細かい点は割愛する。
クラス図3(詳細、属性やメソッドも含む)
★: よく使う引数、属性、メソッド
例:
- pretrained_model_name_or_path = "gpt2-xl"
- model = from_pretrained(pretrained_model_name_or_path = "gpt2-xl")
- model = from_pretrained(model_name).to('cuda')
- outputs: tocrh.Tensor = model.generate(
inputs_ids = encoded_inputs["inputs_ids"],
attention_mask = encoded_inputs["attention_mask"],
do_sample = False # Dreedy-decoding
) - outputs: CausalLMOutputWithCrossAttentions = model.forward(**encoded_inputs)
- last_logits = outputs.logits[0, -1]
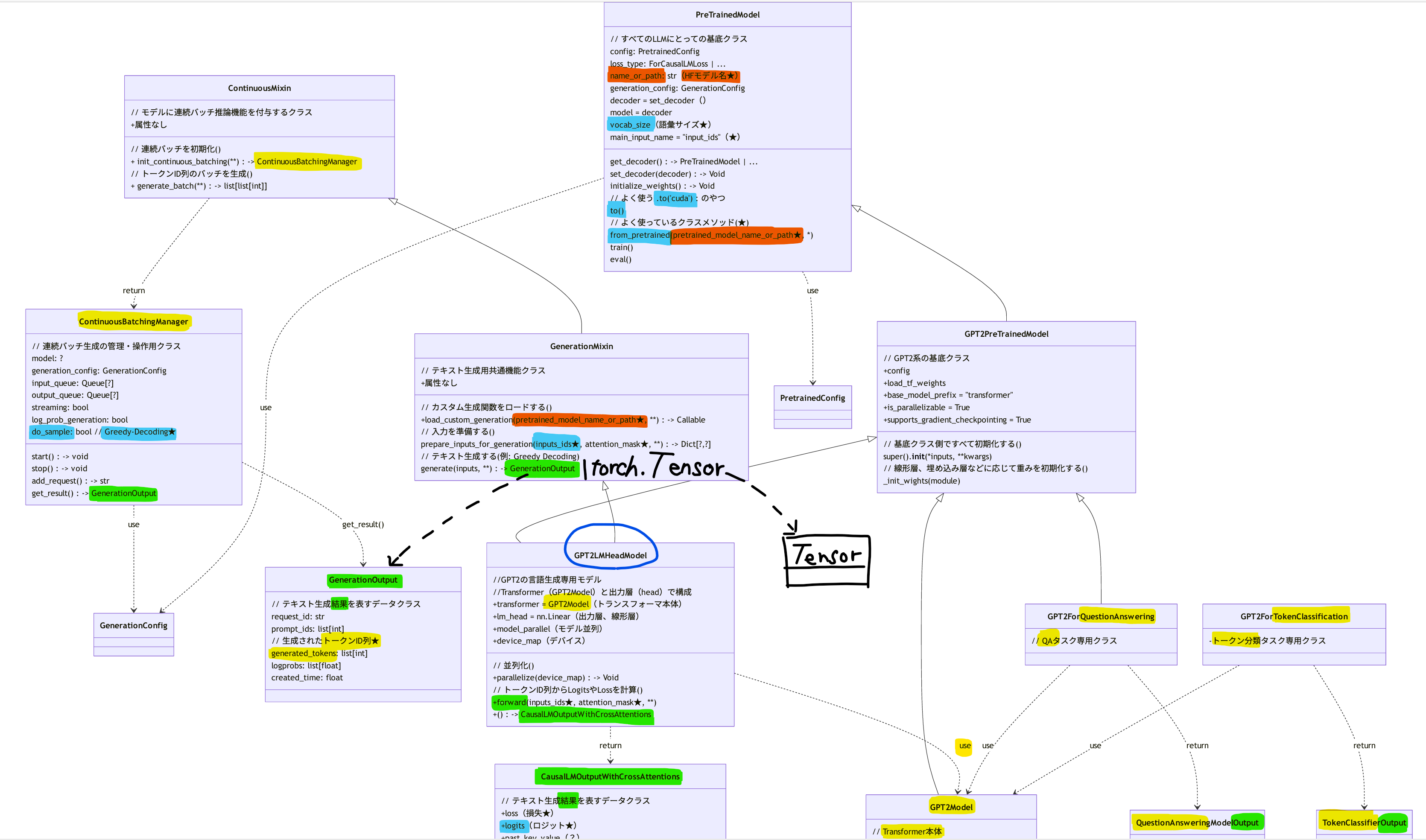
⓪GPT2LMHeadModelは、①GPT2PreTrainedModelと②GenerationMixinを直接継承している。
このとき、上述したコード内に登場していたメソッド・引数と各クラスの紐づきは、以下の通りであった。
- .from_pretrained() → ①の親クラス(PreTrainedModel)のメソッド
- .to('cuda') → ①の親クラス(PreTrainedModel)のメソッド
-
.generate() → ②のメソッド
- 戻り値は torch.Tensor または GenerateOutput(図にTensor型を手書きで追記した)
- デフォルトは torch.Tensor
-
return_dict_in_generate=True を引数に渡すと GenerateOutput 型
- 実際はその型エイリアスの実態である GenerateDecoderOnlyOutput クラスのインスタンス
- Tensorよりも多くの情報を保持しており、Attention機構の分析や内部状態の追跡といった事後分析が必要な場合に = True とするらしい
- input_ids → ⓪のforward()、②のprepare_inputs_for_generation() の引数
- attention_mask → input_idsと同じ
- do_sample → ②の親クラス(ContinuousMinxin)の依存先である ContinuousMatchingManeger の属性
以上。
けっこう時間がかかったが、一度クラス構造を理解しておけば今後ソースコードを見たときの理解が早くなり、投資した時間を十分回収できると感じている。
クラス設計の参考にもなるので一石二鳥かもしれない。