この記事はUnreal Engine (UE) Advent Calendar 2025の16日目の記事です。
今回は、前から調査を行ってみたかったテーマを研究しました。
テーマは、『音声入力』となります。
まず始めに
本当は『UEで使えるAI機能』をテーマにしたかったのですが、現状だと外部プラグインを使用する必要があり、AI機能がUEエディタの中に組み込まれており、何かを行うというものではありませんでした。
5.7から『AIアシスタント』が追加され、こちらも試してみたのですが、想定していたものではありませんでした。
例えば『ブループリントを自動で作る』『イベントグラフを自動で作る』というような、UnrealEngineの特徴に合わせたAIの成果物を期待してましたが、残念ながらUE5.7ではまだ実現できておらず、文章で手順を解説するだけというところしかできませんでした。
その調査結果だけを書いて記事にしても良かったのですが、アドベントカレンダーに対する個人的なモチベーションが無くなってしまうところであったので少しでテーマの方向性を変更しました。
AIアシスタントについては、今後の発展に期待したいところですね。
結論
最初に調査・検証してみての結論を書いておきます。
音声を取るUEのデフォルトの機能を使うだけでも可能です。
しかし、出力は波形や音量のボリュームといった数値として受け取る事は可能ですが、それを直接文字列にするという事はできず、外部プラグインやAPIに頼る必要があります。
現時点では、『Speech to Text』『Runtime Speech Recognizer』というプラグインを使用する事が近道だと思います。
プラグイン
まずは、UEの機能だけで文字起こしが可能であるかを調査したところ、そこまでの機能はサポートされていませんでした。
そこで見つけたのが『Speech to Text』です。2025年の11月25日のリリースされたばかりのプラグインです。
もっと高価なプラグインとして『Runtime Speech Recognizer』というプラグインもあり、Speech to Textと違い、リアルタイムで文字に起こす事ができるようです。
Speech to Text
- 個人版 : 無料
- プロ(企業向け)版 : 4671円
Runtime Speech Recognizer
- 個人版 : 23362円
- プロ(企業向け)版 : 46726円
検証環境
UnrealEngine5.7.1
サンプル
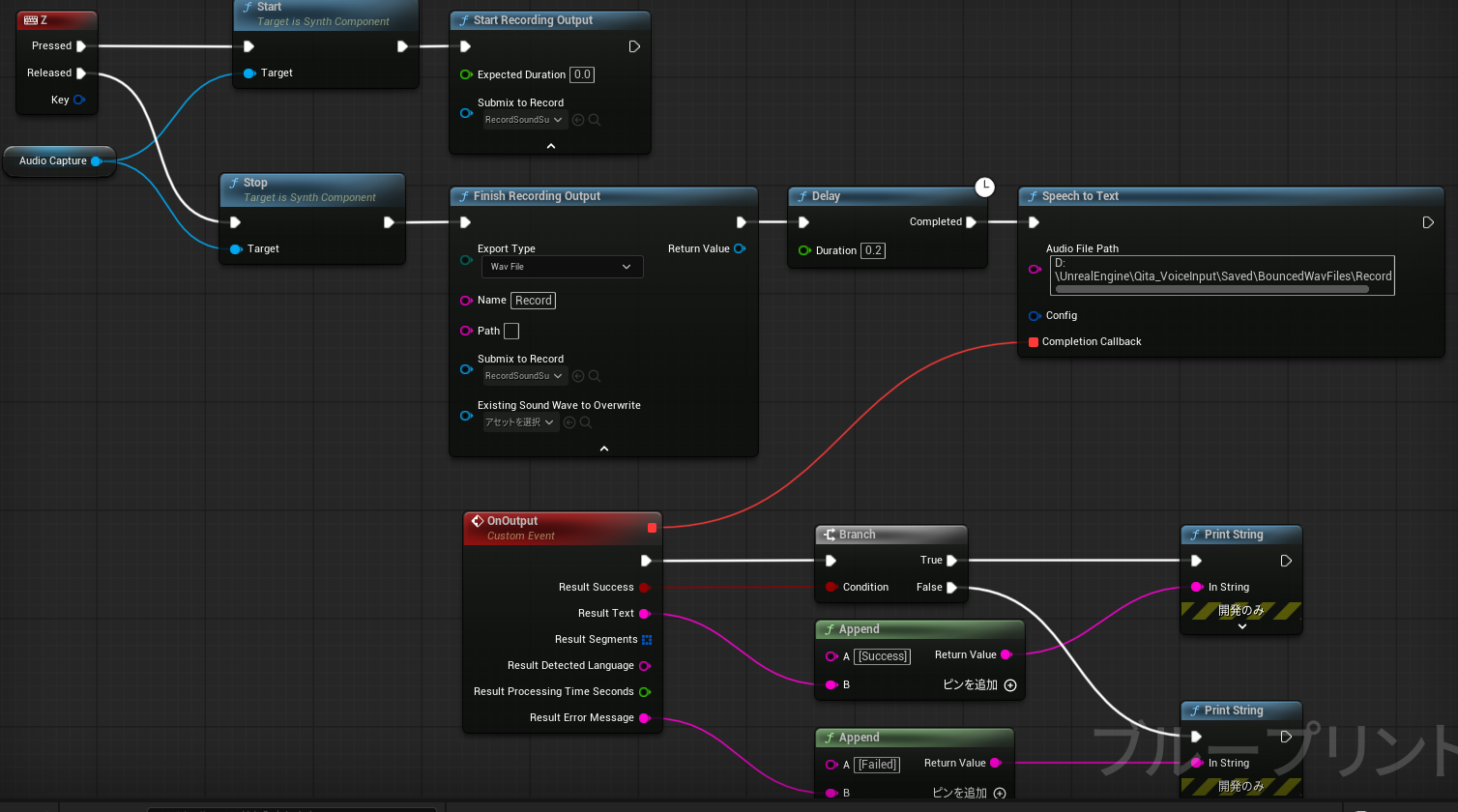
サンプルで作成したブループリントです。
時間も中々取れず、動画の内容を多く活用しています。
プラグイン設定
AudioCaptureComponentを使用する為、AudioCaptureプラグインを有効にします。

また、SpeechtoTextのプラグインも有効化し、文字起こしを実行するノードを使えるようにします。

アセット準備
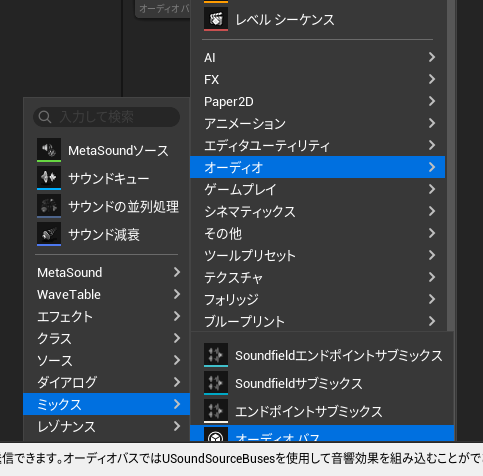
事前の準備として、『サウンドサブミックス』『オーディオバス』の二つのアセットを作成しておきます。
サウンドサブミックスは、オーディオ ➡ ミックス ➡ サウンドサブミックスを選び作成します。

オーディオバスは、オーディオ ➡ ミックス ➡ オーディオバスを選び作成します。
学習モデルをダウンロード
Githubの説明にも記載がありますが、学習モデルを自前でダウンロードして、特定の場所におく必要があります。
学習モデルは、Hugging Faceから、ggml-base.binをダウンロードしてきます。
ダウンロードしたら、プロジェクト内のコンテンツの下に『STTModels』フォルダを作成し中に置きます。
800MBもある大きいモデルもあるみたいなので、精度や性能が気になる方は試してみるのもいいかも知れません。
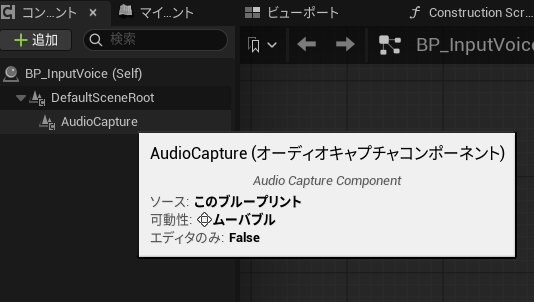
コンポーネント設定
コンポーネントには、Audio Capture Componentを追加します。
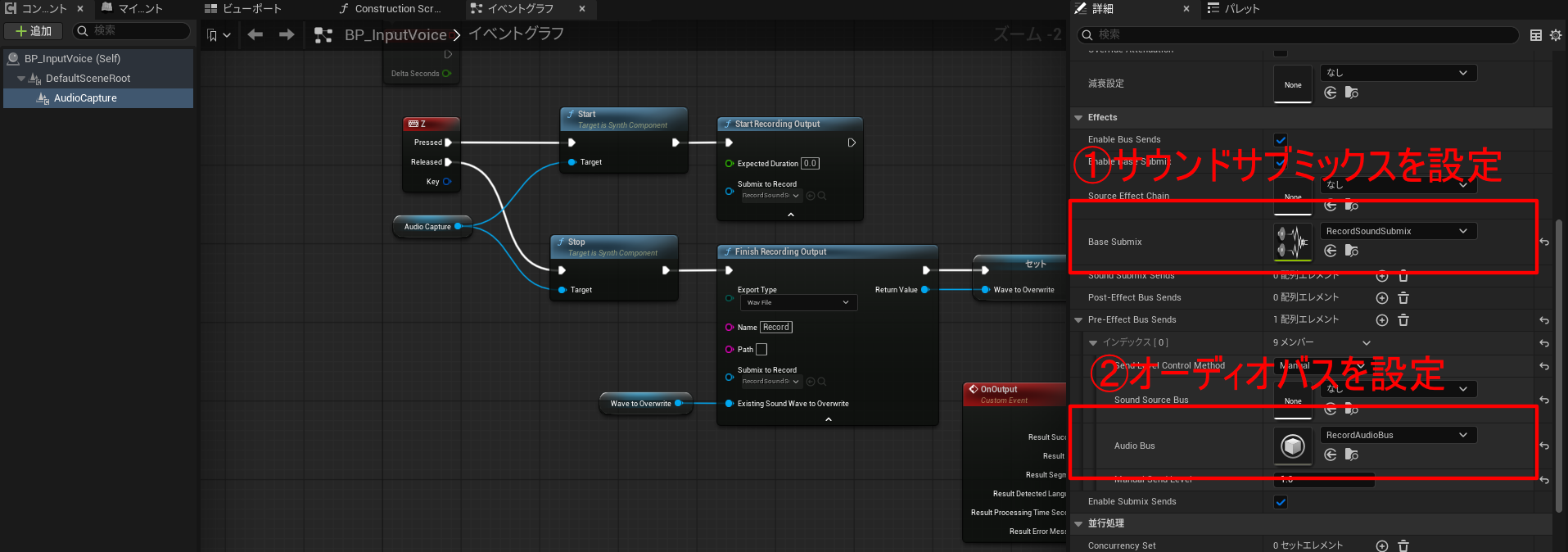
また、コンポーネントに先ほど作成したサウンドサブミックスとオーディオバスを割り当てます。
以下の場所に割り当ててください。
ノード説明
StartノードとStopノード
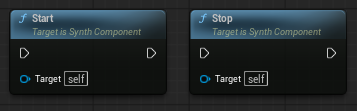
Audio Capture Componentの録音機能の開始と終了を行います。
SpeechtoTextは、直接、ボイス情報を文字に直せない為、一度、wavファイルに直します。
StartRecordingOutputノード

入力した音声をサブミックスに送ります。『SubmixRecord』には作成したサウンドサブミックスを割り当ててください。
FinishRecordingOutputノード
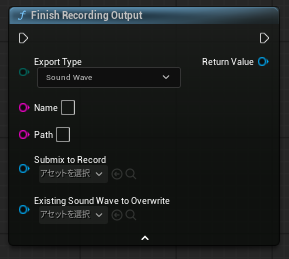
サウンドサブミックスに貯めた内容をwavに書き出します。
- 『EcportType』は、『WavFile』を指定
- 『Name』は、ファイル名
- 『Path』は、出力先のフォルダ。空白の場合は、『Saved\BouncedWavFiles』の中に書き出す
- 『SubmixtoRecord』は、作成したサウンドサブミックスを指定
- 『Existing Sound Wave to Overwride』は、念の為、変数をResultに入れており、その結果を代入
SpeechtoTextノード
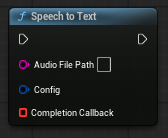
wavからテキストに直します。
- 『Audio File Path』は、wavファイルを指定
- 『Config』は、オプション
- 『Complete Callback』は、実行終了後のコールバックでカスタムイベントを作る
最後に
今年は、AIエージェント元年と言われ、2026年はいよいよ本格的に盛り上がると言われています。
手による入力を極力減らし、『1ステップでのタスクの完結』するAIエージェントが生活に浸透してくる事でしょう。
また、裸眼による立体視ディスプレイも研究が進み、その内、物理的なキーボードやマウスからも解放されていくのではないかと考えています。
そして、声によるコマンド実行や脳の思考を読み取って、タスクを実行するという入力トリガーも大きく変化してきて、今後、音声入力は更に必要になってくる分野ではないかと思います。
また、今回の調査をきっかけに『whisper』にも興味を持ったので、他の言語でも使用可能な手段があるか調べてみたいと思いますました。