はじめに
今回でQiita初投稿となります。
はじめに私の簡単な経歴を紹介します。
新卒〜3年3ヶ月ほど専門商社で営業を行っており、現在はIT業界でプリセールスを行っております。
データ分析に興味を持ち、Aidemyのデータ分析講座(6ヶ月)を受講しています。
今回は最終課題の成果物としてCatboostを用いたアニメのレコメンドシステムの実装にチャレンジしようと思います。
初心者なため拙いコード・記事となりますが温かく見守っていただけますと幸いです。
実装に関して
■実装の背景
アニメのレコメンドシステムを作ろうと思った理由は純粋にアニメ・漫画が好きだからです。
友人にアニメなどをおすすめする事も好きなので、データ分析を用いて相手の好みに合ったアニメをおすすめできたら面白いかなと考えました。
レコメンドシステムはYoutubeやAmazonなどで表示される「あなたへのおすすめ動画や商品」をイメージしていただくとわかりやすいと思います。
■実装のゴール
未知のユーザーが既に視聴したアニメのデータを入力したらおすすめのアニメを10個ほど出力するコードを作りたいと思います。
■実装の流れ
- データの取得
- アニメの類似度を分析
- Catboostのモデル作成
- レコメンドシステム(関数)を作成
■実装環境・データ
kaggle datasetの「Anime Recommendation Database 2020」を利用します。
実装環境もkaggleのNotebookです。
https://www.kaggle.com/datasets/hernan4444/anime-recommendation-database-2020?select=animelist.csv
ランク学習・Catboostに関して
■ランク学習
ランク学習(Ranking learning)は、機械学習の一種であり、主に情報検索や推薦システムの分野で使われる手法です。ランク学習は、複数のデータ間の順序関係を学習し、その順序関係に基づいて新しいデータのランキングを行うことができます。
ランク学習は、一般的な分類や回帰の問題とは異なり、入力データが順序付けられているため、モデルの学習方法も異なります。ランク学習の目的は、与えられた入力データに基づいて、最適な順序を決定することです。
今回もユーザーとアニメのデータを元におすすめのアニメをランキング付けするというような内容となっています。
次のサイトを参考にしながら今回の実装を説明していきたいと思います。
上記サイトにおける変数をそれぞれ私の実装に当てはめると下記のようになります。
q=ユーザー
d=アニメ
Xq,d=ユーザーqとアニメdの特徴量
Yq,d=ユーザーqのアニメdに対する評価
-学習データについて
ユーザーのリストQにはMq個のアニメが含まれます。
ラベルYq,dにはユーザーqのアニメdに対する評価が付与されています。
そしてユーザーqとアニメdのペアから特徴量Xq,dが作られます。
図で表すと下記のようになります。これを学習データとして使用します。

-損失関数について
損失関数=目的関数です。損失関数を最適化することでモデルの精度を高めます。
損失関数がとる値を低くすることでモデルがどのような方向で学習するかを指定することができます。
ランク学習では3つの損失関数が用いられます。
・ポイントワイズ・・・Xq,dとYq,dのセットをみて一つ一つ判断する
例)アクションが好きな人がワンピースを見た時何点つけるか
※他のデータを考慮しない
・ペアワイズ・・・1つずつ比較してランキングを決める
例)A,Bの比較→Aの方が上、B,Cの比較→Cの方が上=A,C,B
・リストワイズ・・・リストの中にある全てを考慮し一番を判断する。
例)20人のクラスから全員を見て、顔が一番かっこいい人を選ぶ
→今回の実装で用いたYetirankはリストワイズ
参考までにリストワイズの損失関数を記載いたします。
L0=∑qL((f(xq,1),yq,1),…,(f(xq,mq),yq,mq))
より知りたい方は上記のサイトやネットで調べてみてください。
■Catboost
CatBoostはCategory Boostingの略で、決定木ベースの勾配ブースティングに基づく機械学習ライブラリです。
勾配ブースティングは、弱い予測器を組み合わせて強力な予測モデルを構築することができるアンサンブル学習アルゴリズムの一つです。
簡単なイメージとして一つ目の決定木で間違った箇所を重点的に学習するというのを繰り返す形になります。

引用:https://toukei-lab.com/gradient-boosting
Catboostを採用した理由としてはカテゴリ変数をそのまま読み込むことができるからでしたが、推論していく中で数値に置き換えた方が良いという判断になったので、そのメリットは発揮されていません。
実装
※出力結果は先頭5行にしているものや、スクショを貼り付けているものがあります。
1 データの取得
まずはDatasetを読み込みます。
# This Python 3 environment comes with many helpful analytics libraries installed
# It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python
# For example, here's several helpful packages to load
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
animelist.csvにはユーザーとそのユーザーの視聴したアニメの評価が含まれています。
全データだと大きすぎるため10万行のデータだけ読み込みます。
ani_lis_df=pd.read_csv("/kaggle/input/anime-recommendation-database-2020/animelist.csv",nrows=100000)
#Use only 100,000 rows because of too much data
#全データは大きすぎるため、10万行だけ利用
display(ani_lis_df.head())
ani_lis_df.info()
ani_lis_df=ani_lis_df.rename(columns={'anime_id': 'MAL_ID'})
ani_lis_df.head(5)
| user_id | MAL_ID | rating | watching_status | watched_episodes | |
|---|---|---|---|---|---|
| 0 | 0 | 67 | 9 | 1 | 1 |
| 1 | 0 | 6702 | 7 | 1 | 4 |
| 2 | 0 | 242 | 10 | 1 | 4 |
| 3 | 0 | 4898 | 0 | 1 | 1 |
| 4 | 0 | 21 | 10 | 1 | 0 |
#make dataframe that japaniese name and MAL_ID
#アニメの名前とIDのリストを作る
ani_csv=pd.read_csv("/kaggle/input/anime-recommendation-database-2020/anime.csv")
display(ani_csv)
ani_name=ani_csv[["MAL_ID","Japanese name"]]
display(ani_name)
ani_name.info()
ani_j_name=ani_csv[["MAL_ID","Score","Japanese name"]]
| user_id | MAL_ID | rating | watching_status | watched_episodes | Japanese name | |
|---|---|---|---|---|---|---|
| 0 | 0 | 67 | 9 | 1 | 1 | バジリスク 甲賀忍法帖 |
| 1 | 14 | 67 | 0 | 6 | 0 | バジリスク 甲賀忍法帖 |
| 2 | 34 | 67 | 10 | 2 | 24 | バジリスク 甲賀忍法帖 |
| 3 | 55 | 67 | 0 | 1 | 0 | バジリスク 甲賀忍法帖 |
| 4 | 57 | 67 | 0 | 1 | 0 | バジリスク 甲賀忍法帖 |
ani_com_lis=pd.merge(ani_lis_df,ani_name,on="MAL_ID")
display(ani_com_lis)
dataset=ani_com_lis.drop(columns=["watching_status","watched_episodes","Japanese name"])
display(dataset)
2 アニメの類似度を調査
それぞれのアニメがどれぐらい似ているかを調べたいと思います。
流れとしてはMatrix Factorization→cos類似度の比較となります。
ここでの作業の目的としては以下2点です。
・Matrix Factorizationをすることによってアニメの特徴量を作成
※ユーザーの特徴量も作成されますが今回は利用しません。
・既に視聴したアニメに似ている=好みだろうという予想に用います
2-1 Matrix Factorization(MF)
今回取得したデータではユーザー数:310、アニメ数:7916となります。
このままでは次元数が多すぎるのでMFを行い、次元削減を行いたいと思います。
MFの説明としては下記サイトがわかりやすいです。
M人のユーザーとN個のアイテムを考えます。
この時ユーザーはN次元のベクトルで表現されますが、これをM >K>0となるK次元に次元削減して変換することを目指す。
引用:https://qiita.com/ysekky/items/c81ff24da0390a74fc6c
今回はユーザー、アニメともに10次元の特徴に圧縮します。
結果として310x10と10x7916のデータフレームが作成されます。
#make dataframe
# データフレームを作成する
anime_w_df=ani_com_lis.drop(columns=["watching_status","watched_episodes","Japanese name"])
anime_w_df = pd.pivot_table(anime_w_df, index='user_id', columns='MAL_ID',values='rating')
#I thought it was not enough that I express feature of animes and users only users watched these animes or not.
#So,I deicided that I would acsept "rating" for expressing these feature.
#"rating"を選んだ理由:アニメとユーザーの特徴を表現するには観たor観てない(0、1)では足りないと判断
#欠損値を0で補完
#fill missing values with (0)
anime_w_df=anime_w_df.fillna(0)
# データフレームを表示する
anime_w_df
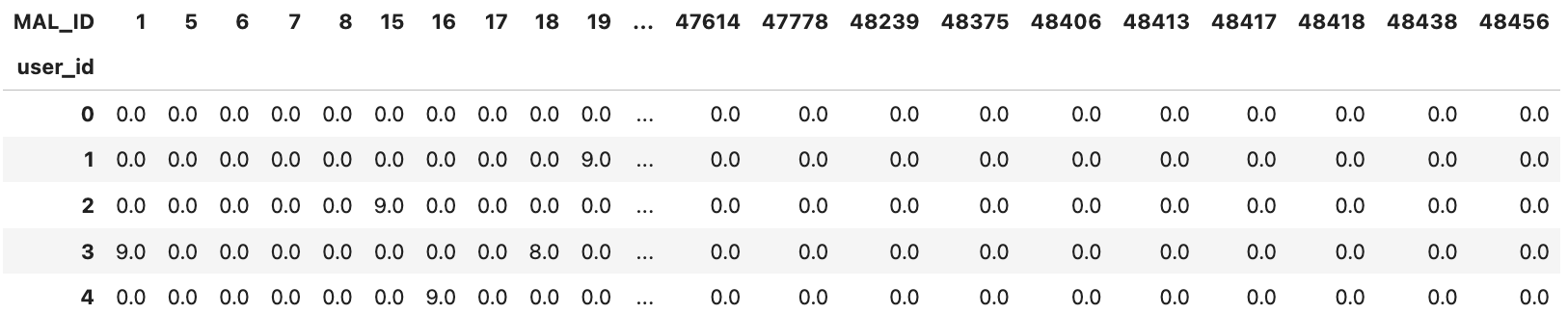
#Userx10、10xAnimeの特徴量を表す行列をそれぞれ作成
#Non-negative Matrix Factorization
from sklearn.decomposition import NMF
nmf_model = NMF(n_components=10,init='random', random_state=0)
User = nmf_model.fit_transform(anime_w_df)
Anime = nmf_model.components_
User_df=pd.DataFrame(User)
User_df.index=anime_w_df.index
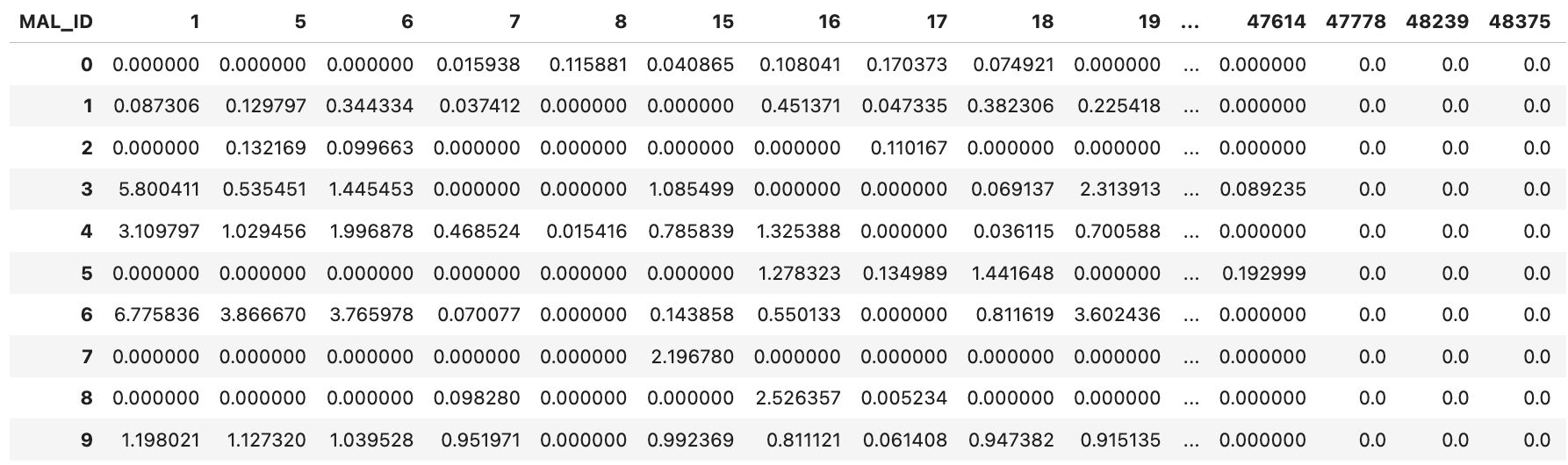
Anime_df=pd.DataFrame(Anime)
Anime_df.columns=anime_w_df.columns
display(Usr_df)
display(Anime_df)
ユーザーの特徴量

アニメの特徴量
2-2 cos類似度
cos類似度は2つのベクトルがどれぐらい似ているかを計算したものです。
1に近いほど類似度が高く-1に近いほど類似度が低くなります。
コサイン類似度とは、ベクトル空間モデルにおいて、文書同士を比較する際に用いられる類似度計算手法。
コサイン類似度は、そのまま、ベクトル同士の成す角度の近さを表現するため、三角関数の普通のコサインの通り、1に近ければ類似しており、0に近ければ似ていないことになる。
引用:https://www.cse.kyoto-su.ac.jp/~g0846020/keywords/cosinSimilarity.html
今回はそれぞれ10次元のベクトルについて類似度を確認します。
内容が難しく感じるかもしれませんが、ライブラリを利用することで実装自体は非常に簡単です。
#cosine similarities of Anime.
from sklearn.metrics.pairwise import cosine_similarity
#Anime_dfのcos類似度を調べるためインデックスとカラムを入れ替える。
Anime_df=Anime_df.transpose()
#既に0~1の数値なので正規化は不要と予想
#It was determined that normalization was unnecessary as the values were already between 0 and 1."
cos_sim_Ani_df=pd.DataFrame(cosine_similarity(Anime_df))
print(cos_sim_Ani_df.shape)
display(cos_sim_Ani_df)

続いてアニメのIDを入力するとcos類似度が近いアニメを10個ほど返してくれる関数を作成します。
# Making a function that inputting a MAL_ID will display about 10 animes titles with the closest cosine similarity.
def cos_sim_top10(i):
row = cos_sim_Ani_df.loc[i]
top_10 = row.sort_values(ascending=False)[1:11]
top_10_df = pd.DataFrame(top_10).reset_index()
top_10_df = top_10_df.rename(columns={'index': 'MAL_ID'})
top_10_name=pd.merge(top_10_df,ani_name,on="MAL_ID")
reco_ani=top_10_name["Japanese name"]
id_to_search = i # 取得したいJapanese nameに対応するMAL_IDを指定する
anime_name = ani_name.loc[ani_name["MAL_ID"] == id_to_search, "Japanese name"].values[0]
print(f"あなたが観たアニメは[{anime_name}]です。")
print("類似度が高いアニメtop10は以下です。")
return(pd.DataFrame(top_10_name))
cos_sim_top10(1000)
出力結果
※アニメによってはcos類似度の計測ができたものが10以下のものもあります。
あなたが観たアニメは[宇宙海賊・キャプテンハーロック]です。
類似度が高いアニメtop10は以下です。
| MAL_ID | 1000 | Japanese name | |
|---|---|---|---|
| 0 | 92 | 0.998420 | 機動新世紀ガンダムX |
| 1 | 999 | 0.997517 | ブルーシード 2 |
| 2 | 3462 | 0.996375 | MINKY MOMO in 夢にかける橋 |
| 3 | 325 | 0.993225 | ピーチガール |
| 4 | 1832 | 0.992366 | 冥王計画ゼオライマー |
| 5 | 1444 | 0.991611 | 太陽の船 ソルビアンカ |
| 6 | 828 | 0.991435 | 人心遊戯 |
| 7 | 605 | 0.990394 | 天使になるもんっ! |
| 8 | 150 | 0.990358 | ブラッドプラス |
| 9 | 2093 | 0.989820 | POPS |
実際にアニメの名前をGoogle検索して定性的に調べてみましたが、おおよそ近しいジャンルのアニメだということがわかりました。
3 Catboostによる分析
CatboostはYandexが開発したオープンソースのソフトウェアライブラリです。
決定木ベースの勾配ブースティングに基づく機械学習ライブラリとなっております。
公式:https://catboost.ai/en/docs/
参考:https://recruit.cct-inc.co.jp/tecblog/machine-learning/catboost/
https://qiita.com/shin_mura/items/3d9ce25a60bdd25a3333
3-1 ユーザーの特徴量を作成
Catboostに学習させるDatasetを作成していきます。
まず各ユーザーが視聴したアニメからそれぞれどのジャンルのアニメを見てるか調べたいと思います。
ユーザーの特徴量としてどのジャンルを多く見ているかが適切だと判断しました。
#I will create users features from output of MF and genr that users watched.
#output of MF is already available .(User_df)
#So I create users feature from genr that users watched.
ani_genr=ani_csv[["MAL_ID","Genres",]]
ani_genr['Genres'].str.split(',')
# カンマ区切りのデータを分割し、新しい列に割り当てる
#Split comma separated data and assign to new columns
genres=set()
# ジャンルのリストを作成
#Create a "genre list"
for genre_list in ani_genr['Genres'].str.split(','):
genres.update(genre_list)
genres = sorted(list(genres))
ani_genr[genres]=0
ani_genr
#Create a function that enter 1 in the applicable genre for each anime
def get_genre_dict(genres):
genre_dict = {}
for genre in genres.split(','):
genre_dict[genre.strip()] = 1
return genre_dict
genre_df = pd.DataFrame(ani_genr['Genres'].apply(get_genre_dict).tolist())
genre_df = genre_df.fillna(0).astype(int)
display(genre_df)
# 元のDataFrameとジャンルの1または0の値を含むDataFrameを結合
# Combine the original dataframe and this dataframe.
result_df = pd.concat([ani_genr["MAL_ID"], genre_df], axis=1)
display(result_df)
ani_genr_df=result_df
#Combine user_df and ani_genr_df.
user_genr_df=pd.merge(ani_lis_df,ani_genr_df,on="MAL_ID")
display(user_genr_df)
display(user_genr_df["user_id"].value_counts())
#Count the number of times uses have watched an anime.
user_genr_df=pd.merge(ani_lis_df,ani_genr_df,on="MAL_ID")
display(user_genr_df["user_id"].value_counts())
#Normalize views for each genre.(0~1)
user_genr_series_dict={}
for group_id,group_df in user_genr_df.groupby("user_id"):
user_genr_series=group_df.sort_values(by="rating",ascending=False).iloc[:31,5:].sum()/group_df.iloc[:,5:].sum()
user_genr_series=user_genr_series.fillna(0)
user_genr_series_dict[group_id]=user_genr_series
user_genr_feature_df=pd.DataFrame(user_genr_series_dict).T
user_genr_feature_df
ユーザーが視聴した各アニメが該当するジャンルの列に"1"を入力。
| user_id | MAL_ID | rating | watching_status | watched_episodes | Action | Adventure | Comedy | Drama | Sci-Fi | Space | Mystery | Shounen | Police | Supernatural | Magic | Fantasy | Sports | Josei | Romance | Slice of Life | Cars | Seinen | Horror | Psychological | Thriller | Super Power | Martial Arts | School | Ecchi | Vampire | Military | Historical | Dementia | Mecha | Demons | Samurai | Game | Shoujo | Harem | Music | Shoujo Ai | Shounen Ai | Kids | Hentai | Parody | Yuri | Yaoi | Unknown | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 67 | 9 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 14 | 67 | 0 | 6 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 34 | 67 | 10 | 2 | 24 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 55 | 67 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 57 | 67 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
その後ユーザーごと(user_id)にどのジャンルを見ているか合計します。
ユーザーが視聴したアニメのジャンルごとの合計数をアニメの視聴数で割ることによりデータを正規化します。
正規化する理由は視聴したアニメの数がユーザーごとにばらつきがあるからです。
例えばアニメを10個視聴したユーザーと100個視聴したユーザーを考える時、どちらもジャンル:アクションの視聴回数が10だった場合、前者は10/10、後者は10/100となります。
この場合、純粋なアクションの視聴回数だけで比べてしまうと両者の差がなくなってしまうと考えました。
正規化後の出力結果が下記です。
※下記データフレームではindex = user_idと考えてください。
例えばユーザー0はアクション、アドベンチャー、コメディのジャンルを多く視聴していることがわかります。
| Action | Adventure | Comedy | Drama | Sci-Fi | Space | Mystery | Shounen | Police | Supernatural | Magic | Fantasy | Sports | Josei | Romance | Slice of Life | Cars | Seinen | Horror | Psychological | Thriller | Super Power | Martial Arts | School | Ecchi | Vampire | Military | Historical | Dementia | Mecha | Demons | Samurai | Game | Shoujo | Harem | Music | Shoujo Ai | Shounen Ai | Kids | Hentai | Parody | Yuri | Yaoi | Unknown | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.461538 | 0.485714 | 0.475000 | 0.392857 | 0.111111 | 0.0 | 0.272727 | 0.375000 | 0.500000 | 0.466667 | 0.428571 | 0.521739 | 0.000000 | 1.000000 | 0.500000 | 0.300000 | 0.000 | 0.000000 | 0.500000 | 0.166667 | 0.000000 | 0.454545 | 0.000000 | 0.333333 | 0.000000 | 0.500000 | 0.428571 | 0.666667 | 0.0 | 0.000000 | 0.00 | 1.00 | 0.400000 | 0.625000 | 0.000000 | 0.000000 | 0.0 | 0.0 | 0.0 | 0.0 | 0.333333 | 0.0 | 0.0 | 0.0 |
| 1 | 0.225806 | 0.242424 | 0.142857 | 0.340000 | 0.529412 | 0.0 | 0.375000 | 0.236842 | 0.000000 | 0.147059 | 0.166667 | 0.272727 | 0.190476 | 0.000000 | 0.080000 | 0.000000 | 0.000 | 0.333333 | 0.666667 | 0.416667 | 0.600000 | 0.357143 | 0.181818 | 0.163265 | 0.000000 | 0.000000 | 0.857143 | 0.250000 | 0.0 | 0.333333 | 0.25 | 0.00 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.0 | 0.0 |
| 2 | 0.174603 | 0.209302 | 0.138889 | 0.196078 | 0.151515 | 0.0 | 0.100000 | 0.168317 | 0.666667 | 0.131579 | 0.045455 | 0.065574 | 0.277778 | 0.000000 | 0.076923 | 0.111111 | 0.000 | 0.161290 | 0.117647 | 0.222222 | 0.176471 | 0.343750 | 0.222222 | 0.082353 | 0.061728 | 0.133333 | 0.250000 | 0.000000 | 0.0 | 0.500000 | 0.08 | 0.00 | 0.083333 | 0.000000 | 0.062500 | 0.000000 | 0.0 | 0.0 | 0.0 | 0.0 | 0.250000 | 0.0 | 0.0 | 0.0 |
| 3 | 0.086957 | 0.114286 | 0.074419 | 0.134831 | 0.145455 | 1.0 | 0.065217 | 0.092105 | 0.333333 | 0.076923 | 0.043478 | 0.107143 | 0.125000 | 0.000000 | 0.063380 | 0.115385 | 0.125 | 0.098361 | 0.142857 | 0.107143 | 0.157895 | 0.000000 | 0.000000 | 0.060150 | 0.024096 | 0.000000 | 0.083333 | 0.250000 | 0.0 | 0.071429 | 0.00 | 0.25 | 0.125000 | 0.100000 | 0.014493 | 0.000000 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.0 | 0.0 |
| 4 | 0.130435 | 0.176471 | 0.166667 | 0.280488 | 0.105263 | 0.0 | 0.259259 | 0.093750 | 0.500000 | 0.250000 | 0.250000 | 0.166667 | 0.000000 | 0.428571 | 0.258065 | 0.256410 | 0.000 | 0.400000 | 0.428571 | 0.285714 | 0.200000 | 0.181818 | 0.333333 | 0.225806 | 0.000000 | 0.600000 | 0.500000 | 0.277778 | 0.0 | 0.250000 | 0.00 | 0.00 | 0.000000 | 0.306122 | 0.166667 | 0.333333 | 0.0 | 0.0 | 0.0 | 0.0 | 0.000000 | 0.0 | 0.0 | 0.0 |
ユーザーが視聴したアニメの数も特徴量に追加します。
# Create a dataframe of views per user
w_num=user_genr_df.groupby("user_id")["MAL_ID"].count()
w_num_df=pd.DataFrame(w_num)
w_num_df=w_num_df.rename(columns={"MAL_ID":"w_num"})
w_num_df
最終的なDatasetは下記となります。
user_id,MAL_ID(アニメのID)、rating(ユーザーのそのアニメに対する評価)、
AnimeをMFした結果、ユーザーのジャンルごとの視聴数、ユーザーのアニメ視聴数。
100,000行x58列
# Merge dataset,User_df and user_genr_feature_df,w_num_df
dataset_2=pd.merge(dataset,Anime_df,left_on="MAL_ID",right_index=True)
print(len(dataset_2))
dataset_2=pd.merge(dataset_2,user_genr_feature_df,left_on="user_id",right_index=True)
dataset_2=pd.merge(dataset_2,w_num_df,left_on="user_id",right_index=True)
dataset_2
| user_id | MAL_ID | rating | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | Action | Adventure | Comedy | Drama | Sci-Fi | Space | Mystery | Shounen | Police | Supernatural | Magic | Fantasy | Sports | Josei | Romance | Slice of Life | Cars | Seinen | Horror | Psychological | Thriller | Super Power | Martial Arts | School | Ecchi | Vampire | Military | Historical | Dementia | Mecha | Demons | Samurai | Game | Shoujo | Harem | Music | Shoujo Ai | Shounen Ai | Kids | Hentai | Parody | Yuri | Yaoi | Unknown | w_num | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 67 | 9 | 0.000000 | 0.276708 | 0.000000 | 0.000000 | 0.584097 | 1.152570 | 0.216397 | 0.000000 | 0.000000 | 0.875310 | 0.461538 | 0.485714 | 0.475 | 0.392857 | 0.111111 | 0.0 | 0.272727 | 0.375 | 0.5 | 0.466667 | 0.428571 | 0.521739 | 0.0 | 1.0 | 0.5 | 0.3 | 0.0 | 0.0 | 0.5 | 0.166667 | 0.0 | 0.454545 | 0.0 | 0.333333 | 0.0 | 0.5 | 0.428571 | 0.666667 | 0.0 | 0.0 | 0.0 | 1.0 | 0.4 | 0.625 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.333333 | 0.0 | 0.0 | 0.0 | 74 |
| 36 | 0 | 6702 | 7 | 1.750210 | 0.244625 | 0.461659 | 5.598710 | 2.188344 | 4.407551 | 0.000000 | 2.384597 | 0.000000 | 0.815328 | 0.461538 | 0.485714 | 0.475 | 0.392857 | 0.111111 | 0.0 | 0.272727 | 0.375 | 0.5 | 0.466667 | 0.428571 | 0.521739 | 0.0 | 1.0 | 0.5 | 0.3 | 0.0 | 0.0 | 0.5 | 0.166667 | 0.0 | 0.454545 | 0.0 | 0.333333 | 0.0 | 0.5 | 0.428571 | 0.666667 | 0.0 | 0.0 | 0.0 | 1.0 | 0.4 | 0.625 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.333333 | 0.0 | 0.0 | 0.0 | 74 |
| 182 | 0 | 242 | 10 | 0.000000 | 0.000000 | 0.000000 | 0.112882 | 0.160118 | 0.035051 | 0.850556 | 0.000000 | 0.000000 | 0.033387 | 0.461538 | 0.485714 | 0.475 | 0.392857 | 0.111111 | 0.0 | 0.272727 | 0.375 | 0.5 | 0.466667 | 0.428571 | 0.521739 | 0.0 | 1.0 | 0.5 | 0.3 | 0.0 | 0.0 | 0.5 | 0.166667 | 0.0 | 0.454545 | 0.0 | 0.333333 | 0.0 | 0.5 | 0.428571 | 0.666667 | 0.0 | 0.0 | 0.0 | 1.0 | 0.4 | 0.625 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.333333 | 0.0 | 0.0 | 0.0 | 74 |
| 198 | 0 | 4898 | 0 | 0.737837 | 0.009427 | 0.000000 | 1.743726 | 1.843295 | 10.742312 | 1.314800 | 0.000000 | 0.028865 | 0.681549 | 0.461538 | 0.485714 | 0.475 | 0.392857 | 0.111111 | 0.0 | 0.272727 | 0.375 | 0.5 | 0.466667 | 0.428571 | 0.521739 | 0.0 | 1.0 | 0.5 | 0.3 | 0.0 | 0.0 | 0.5 | 0.166667 | 0.0 | 0.454545 | 0.0 | 0.333333 | 0.0 | 0.5 | 0.428571 | 0.666667 | 0.0 | 0.0 | 0.0 | 1.0 | 0.4 | 0.625 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.333333 | 0.0 | 0.0 | 0.0 | 74 |
| 321 | 0 | 21 | 10 | 0.229667 | 0.300072 | 0.000000 | 8.260938 | 3.037132 | 0.621107 | 0.393269 | 1.936368 | 0.000000 | 0.913227 | 0.461538 | 0.485714 | 0.475 | 0.392857 | 0.111111 | 0.0 | 0.272727 | 0.375 | 0.5 | 0.466667 | 0.428571 | 0.521739 | 0.0 | 1.0 | 0.5 | 0.3 | 0.0 | 0.0 | 0.5 | 0.166667 | 0.0 | 0.454545 | 0.0 | 0.333333 | 0.0 | 0.5 | 0.428571 | 0.666667 | 0.0 | 0.0 | 0.0 | 1.0 | 0.4 | 0.625 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.333333 | 0.0 | 0.0 | 0.0 | 74 |
3-2 Catboostによる学習
CatboostではデータをPoolとして渡します。
[rating]を目的変数としてtrain_poolを作成しています。
データの構成は下記画像のようなイメージです。

import catboost as cb
#プールを作成
# Create Pool
dataset_cb=dataset_2.sort_values("user_id")
train_pool=cb.Pool(dataset_cb.iloc[:,3:].values,label=dataset_cb["rating"].values,group_id=dataset_cb["user_id"].values)
display(dataset_cb.iloc[:,3:])
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | Action | Adventure | Comedy | Drama | Sci-Fi | Space | Mystery | Shounen | Police | Supernatural | Magic | Fantasy | Sports | Josei | Romance | Slice of Life | Cars | Seinen | Horror | Psychological | Thriller | Super Power | Martial Arts | School | Ecchi | Vampire | Military | Historical | Dementia | Mecha | Demons | Samurai | Game | Shoujo | Harem | Music | Shoujo Ai | Shounen Ai | Kids | Hentai | Parody | Yuri | Yaoi | Unknown | w_num | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.000000 | 0.276708 | 0.000000 | 0.000000 | 0.584097 | 1.152570 | 0.216397 | 0.000000 | 0.0 | 0.875310 | 0.461538 | 0.485714 | 0.475 | 0.392857 | 0.111111 | 0.0 | 0.272727 | 0.375 | 0.5 | 0.466667 | 0.428571 | 0.521739 | 0.0 | 1.0 | 0.5 | 0.3 | 0.0 | 0.0 | 0.5 | 0.166667 | 0.0 | 0.454545 | 0.0 | 0.333333 | 0.0 | 0.5 | 0.428571 | 0.666667 | 0.0 | 0.0 | 0.0 | 1.0 | 0.4 | 0.625 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.333333 | 0.0 | 0.0 | 0.0 | 74 |
| 2799 | 1.008921 | 0.000000 | 0.000000 | 0.446081 | 3.127967 | 0.090929 | 1.301598 | 0.027160 | 0.0 | 1.093882 | 0.461538 | 0.485714 | 0.475 | 0.392857 | 0.111111 | 0.0 | 0.272727 | 0.375 | 0.5 | 0.466667 | 0.428571 | 0.521739 | 0.0 | 1.0 | 0.5 | 0.3 | 0.0 | 0.0 | 0.5 | 0.166667 | 0.0 | 0.454545 | 0.0 | 0.333333 | 0.0 | 0.5 | 0.428571 | 0.666667 | 0.0 | 0.0 | 0.0 | 1.0 | 0.4 | 0.625 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.333333 | 0.0 | 0.0 | 0.0 | 74 |
| 2760 | 0.007449 | 0.187020 | 0.000000 | 0.851277 | 1.088286 | 0.568960 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.461538 | 0.485714 | 0.475 | 0.392857 | 0.111111 | 0.0 | 0.272727 | 0.375 | 0.5 | 0.466667 | 0.428571 | 0.521739 | 0.0 | 1.0 | 0.5 | 0.3 | 0.0 | 0.0 | 0.5 | 0.166667 | 0.0 | 0.454545 | 0.0 | 0.333333 | 0.0 | 0.5 | 0.428571 | 0.666667 | 0.0 | 0.0 | 0.0 | 1.0 | 0.4 | 0.625 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.333333 | 0.0 | 0.0 | 0.0 | 74 |
| 2617 | 1.316057 | 0.000000 | 0.000000 | 5.448125 | 3.551649 | 4.243665 | 0.000000 | 2.350967 | 0.0 | 0.724335 | 0.461538 | 0.485714 | 0.475 | 0.392857 | 0.111111 | 0.0 | 0.272727 | 0.375 | 0.5 | 0.466667 | 0.428571 | 0.521739 | 0.0 | 1.0 | 0.5 | 0.3 | 0.0 | 0.0 | 0.5 | 0.166667 | 0.0 | 0.454545 | 0.0 | 0.333333 | 0.0 | 0.5 | 0.428571 | 0.666667 | 0.0 | 0.0 | 0.0 | 1.0 | 0.4 | 0.625 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.333333 | 0.0 | 0.0 | 0.0 | 74 |
| 2602 | 0.159276 | 0.000000 | 0.299858 | 0.020605 | 0.522427 | 0.000000 | 0.000000 | 0.055497 | 0.0 | 0.037965 | 0.461538 | 0.485714 | 0.475 | 0.392857 | 0.111111 | 0.0 | 0.272727 | 0.375 | 0.5 | 0.466667 | 0.428571 | 0.521739 | 0.0 | 1.0 | 0.5 | 0.3 | 0.0 | 0.0 | 0.5 | 0.166667 | 0.0 | 0.454545 | 0.0 | 0.333333 | 0.0 | 0.5 | 0.428571 | 0.666667 | 0.0 | 0.0 | 0.0 | 1.0 | 0.4 | 0.625 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.333333 | 0.0 | 0.0 | 0.0 | 74 |
ハイパーパラメータを設定してモデルを学習させます。
# Setting hyperparameters
params_dict={
"loss_function":"YetiRank",
"iterations":100,
"verbose":20,
"learning_rate":0.01,
"max_depth":4
}
# Training the model
model=cb.CatBoostRanker(**params_dict)
model.fit(train_pool,eval_set=train_pool)
学習した後、試しにユーザー90についておすすめのアニメを予想していきます。
df_result=dataset_cb.groupby("user_id").get_group(90)
df_result_pred = model.predict(df_result.iloc[:, 3:])
df_result["pred"] = df_result_pred
df_result
df_result[["MAL_ID","rating","pred"]].sort_values(by="pred",ascending=False).head(10)
"pred"の値が大きいほどそのユーザーに対してのおすすめ度が高いので、結果を"pred"について降順にしています。
ratingが0のアニメも入っていますが、ユーザー90が高く評価したアニメも上位に入っていることがわかります。
| MAL_ID | rating | pred | |
|---|---|---|---|
| 2290 | 199 | 8 | 0.683373 |
| 11441 | 16498 | 9 | 0.597095 |
| 9649 | 16894 | 0 | 0.582325 |
| 13340 | 4224 | 0 | 0.581175 |
| 9551 | 11771 | 10 | 0.578436 |
| 6282 | 6547 | 0 | 0.554471 |
| 11262 | 23273 | 0 | 0.541396 |
| 9327 | 30831 | 10 | 0.536209 |
| 5614 | 20507 | 7 | 0.522366 |
| 358 | 21 | 10 | 0.520547 |
3-3 モデルの精度確認
3-2で作成したモデルの精度を確認していきます。
損失関数には"Yetirank"を採用しています
Yetirankについて
公式:https://catboost.ai/en/docs/concepts/loss-functions-ranking#YetiRank
また今回は1つのユーザーIDに紐づくデータが学習データと検証データに分かれないようにグループKFoldを用いて精度を確認していきます。
例)ユーザー0のデータは全て学習用データに使用され、検証データでは使われないようにする
from sklearn.model_selection import GroupKFold
gkf = GroupKFold(n_splits=4)
groups = dataset["user_id"]
params_dict={
"loss_function":"YetiRank",
"iterations":50,
"verbose":20,
"learning_rate":0.01,
"max_depth":4,
"use_best_model":True,
"eval_metric":"QueryRMSE"
}
result_dict_list=[]
for fold, (train_index, val_index) in enumerate(gkf.split(dataset_cb, groups=groups)):
train_gkf, val_gkf = dataset_cb.iloc[train_index].sort_values(by="user_id"), dataset_cb.iloc[val_index].sort_values(by="user_id")
train_pool=cb.Pool(train_gkf.iloc[:,3:].values,label=train_gkf["rating"].values,group_id=train_gkf["user_id"].values)
val_pool =cb.Pool(val_gkf.iloc[:,3:].values,label=val_gkf["rating"].values,group_id=val_gkf["user_id"].values)
model=cb.CatBoostRanker(**params_dict)
model.fit(train_pool,eval_set=val_pool)
val_metrics=model.eval_metrics(val_pool,['QueryRMSE'])
#ここで作成した4つのモデルを最後の節で使用するためそれぞれ辞書のリストとして保存
result_dict={
"model":model,
"metrics":val_metrics
}
result_dict_list.append(result_dict)
出力結果
0: learn: 3.3378808 test: 3.3192821 best: 3.3192821 (0) total: 181ms remaining: 8.89s
20: learn: 3.3209473 test: 3.3024343 best: 3.3024343 (20) total: 3.63s remaining: 5.01s
40: learn: 3.3071507 test: 3.2888276 best: 3.2888276 (40) total: 7.06s remaining: 1.55s
49: learn: 3.3021109 test: 3.2839410 best: 3.2839410 (49) total: 8.59s remaining: 0us
bestTest = 3.283941028
bestIteration = 49
0: learn: 3.3333687 test: 3.3313644 best: 3.3313644 (0) total: 166ms remaining: 8.14s
20: learn: 3.3163516 test: 3.3136824 best: 3.3136824 (20) total: 3.65s remaining: 5.04s
40: learn: 3.3035703 test: 3.3002708 best: 3.3002708 (40) total: 7.15s remaining: 1.57s
49: learn: 3.2985857 test: 3.2950472 best: 3.2950472 (49) total: 8.74s remaining: 0us
bestTest = 3.295047248
bestIteration = 49
0: learn: 3.3348862 test: 3.3262841 best: 3.3262841 (0) total: 176ms remaining: 8.62s
20: learn: 3.3178353 test: 3.3090614 best: 3.3090614 (20) total: 3.67s remaining: 5.06s
40: learn: 3.3047343 test: 3.2958173 best: 3.2958173 (40) total: 7.14s remaining: 1.57s
49: learn: 3.2995989 test: 3.2906453 best: 3.2906453 (49) total: 8.94s remaining: 0us
bestTest = 3.290645303
bestIteration = 49
0: learn: 3.3408498 test: 3.3110542 best: 3.3110542 (0) total: 183ms remaining: 8.98s
20: learn: 3.3237815 test: 3.2956900 best: 3.2956900 (20) total: 3.74s remaining: 5.17s
40: learn: 3.3094921 test: 3.2828626 best: 3.2828626 (40) total: 7.29s remaining: 1.6s
49: learn: 3.3041911 test: 3.2781436 best: 3.2781436 (49) total: 8.89s remaining: 0us
bestTest = 3.278143556
bestIteration = 49
上記結果より3番目(※0オリジン)に出てきたモデルが一番精度が高いと判断します。
本来であればハイパーパラメータをチューニングをすることによって、精度を上げる必要がありますが今回は割愛します。
4 レコメンドシステムの作成(関数)
最後にレコメンドシステムを作成します。
ここではユーザーが見たアニメのリスト(w_list)を入力するとおすすめのアニメTop10を返してくれる関数を作成します。
関数作成の大まかな流れを記載します。
1. 入力されたw_listに格納されたアニメID(MAL_ID)からそれぞれcos類似度が近いアニメを
20件ずつ取得(重複しているものは片方だけ残す)
2. 上記のアニメについてMFで作成したアニメの特徴量を結合
3. 3-1の実装と同じようにユーザーが視聴したアニメについてジャンルごとの視聴回数を
集計してアニメの視聴回数で割ることで正規化
4. 3で作成したものをユーザーの特徴量として各行に割り当てる
5. 3-3で作成したモデルでは3番目(※0オリジン)のモデルが高いため、
3番目のモデルで予想する。
6. 予想結果を"pred"(おすすめ度)順に並び替えてTop10のアニメを表示
#未知のユーザーが視聴したアニメのリストを入れる
w_list=[]
def reco_anime(w_list):
w_j_list=[]
for i in w_list:
id_to_search = i # 取得したいJapanese nameに対応するMAL_IDを指定する
anime_name = ani_name.loc[ani_name["MAL_ID"] == id_to_search, "Japanese name"]
w_j_list.append(anime_name)
#各視聴アニメごとにcos類似度が近いアニメを20件取得、MFの結果と結合
row=cos_sim_Ani_df.loc[i]
top_20=row.sort_values(ascending=False)[1:21]
top_20_df = pd.DataFrame(top_20).reset_index()
top_20_df = top_20_df.rename(columns={'index': 'MAL_ID',i:"cos_sim"})
top_20_df_mf=pd.merge(top_20_df,Anime_df,on="MAL_ID").drop(columns="cos_sim")
if i==w_list[0]:
top_20_df_mf_com=top_20_df_mf
else:
top_20_df_mf_com=pd.concat([top_20_df_mf_com,top_20_df_mf],axis=0)
reco_df=top_20_df_mf_com.drop_duplicates(subset="MAL_ID").reset_index().drop(columns="index")
reco_df["user_id"]=0
reco_df
#ここでは視聴したアニメのジャンルからユーザーの特徴量を作成しています。
for i in w_list:
anime_genr=anime_genr_df.drop(columns=["Score","Japanese name"])
user_genr=anime_genr.query(f"MAL_ID=={i}")
if i==w_list[0]:
user_genr_com=user_genr
else:
user_genr_com=pd.concat([user_genr_com,user_genr],axis=0)
user_f=user_genr_com.reset_index().drop(columns="index")
user_f=(user_f.iloc[:,2:].sum()/len(w_list)).fillna(0)
user_f["many"]=len(w_list)
user_f["user_id"]=0
user_f=pd.DataFrame(user_f).T
user_f
reco_user_f=pd.merge(reco_df,user_f,on="user_id")
reco_user_f=reco_user_f.drop(columns="user_id")
reco_user_f
#アニメとユーザーの特徴量を元に3で作成したモデルでおすすめアニメを予想→上位10個を表示しています。
reco_ani_pred = result_dict_list[3]["model"].predict(reco_user_f.iloc[:, 2:])
reco_user_f["pred"]=reco_ani_pred
reco_user_f=reco_user_f[["MAL_ID","pred"]].sort_values(by="pred",ascending=False)
recomend_anime_10=pd.DataFrame(pd.merge(reco_user_f,ani_name,on="MAL_ID")["Japanese name"].head(10))
return recomend_anime_10
試しに視聴済みアニメのID(MAL_ID)を[50,34,21,99]にして予想してみます。
w_list=[50,34,21,99]
reco_anime(w_list)
| Japanese name | |
|---|---|
| 0 | ツバサ・クロニクル |
| 1 | トリニティ・ブラッド |
| 2 | 機動天使エンジェリックレイヤー |
| 3 | ハンター×ハンター\u3000G・I\u3000Final |
| 4 | テニスの王子様 |
| 5 | ママレード・ボーイ |
| 6 | モンスター |
| 7 | 少年陰陽師 |
| 8 | 天上天下 |
| 9 | 金色のコルダ ~primo passo~ ひと夏のアンコール |
無事におすすめのアニメTop10を表示させることができました。
モデル改善に関して
・Numpyを用いて利用するデータの数を増やす。
今回はデータが大きく、実装に時間がかかってしまうため10万行しか読み込みませんでした。
それもあり若干偏りがあるデータだったと感じております。DataFrameではなくNumpyのndarrayとすることでより大きなデータを扱えるのでその実装もチャレンジしてみたいと思います。
・ハイパーパラメータチューニング
割愛したハイパーパラメータチューニングも実装したいと思います。
グループKFoldのbestIterationが全て49のためiteration数を増やせば、さらに精度が上がることが予想されます。
・データの取得方法
Anime Recommendation Database 2020には今回利用していないデータがあります。
そのユーザーがそのアニメを何話まで視聴したかなどより細かいデータを特徴量として取り扱うことで、予想の精度が上がると思われます。
おわりに
未経験の状態からAidemyのデータ分析コースを受講することによって、データ分析をするにあたって最低限の知識とスキルを身につけれられたのではないかと感じております。しかし、まだまだ未熟なため引き続き学習を進めていきたいと考えております。
今後の予定としては下記に取り組む予定です。
・kaggleのコンペに参加してデータ分析の経験を積む
・統計学を学習する(今年中に統計検定2級を取得する)
・売上データを分析して売上アップにつながるような提案ができるようになる。
→現職がIT製品の営業支援も行うプリセールスなので現場で使えるスキルにできればと考えております。
最終目標としてはkaggle expertの称号を取得して、データ分析のスキル証明ができればと思っております。
初めて作成したブログを最後まで読んでいただきありがとうございます。
今後も作成した成果物を記事にまとめて発信できればと思いますので少しでも見ていただけたら嬉しいです。