この記事はTSG Advent Calendar 2024の6日目の記事です。
また、この記事は「AivisSpeechを使ったDiscordボットの作成」シリーズのその③(ラスト)です。以前の章はこちら↓
AivisSpeechの推論速度
その①、その②を通してユーザーの入力を音声に変換するサービスを作成しましたが、あらゆるユースケースにおいて応答が返ってくるまでの時間(レイテンシ)は重要になります。特にその②で作成したようなDiscordボットは、ただでさえタイピングをする分だけ反応が遅れるのに、さらにTTSに時間がかかってしまっては肉声を使う人たちとのコミュニケーションが難しくなってしまいます。この記事ではAivisSpeechのモデルを改造することで、音声品質を保ったままレイテンシを短縮する手法について紹介します。
まずは現在のAivisSpeechの推論速度について測定してみます。基本的に生成にかかる時間は生成される音声の長さに比例して伸びるため、様々な文章を入力してその生成時間を測定します。測定環境はその①でデプロイしたGoogle Cloud Run環境で、第一世代、8CPU、メモリ8GiBで測定しています。
| 入力文章 | 生成音声長(秒) | 処理時間(秒) |
|---|---|---|
| こんにちは | 1.06 | 0.77 |
| ウオウオフィッシュライフ | 1.37 | 0.85 |
| 東京特許許可局 | 1.78 | 0.89 |
| 毒を食らわば皿まで | 1.95 | 1.19 |
| あのイーハトーヴォのすきとおった風 | 2.47 | 1.16 |
| えー!なるっちの担当箇所がバグだらけ!? | 3.16 | 1.32 |
| あのイーハトーヴォのすきとおった風、夏でも底に冷たさをもつ青いそら | 5.35 | 2.29 |
| あのイーハトーヴォのすきとおった風、夏でも底に冷たさをもつ青いそら、うつくしい森で飾られたモリーオ市 | 7.67 | 3.32 |
| あのイーハトーヴォのすきとおった風、夏でも底に冷たさをもつ青いそら、うつくしい森で飾られたモリーオ市、郊外のぎらぎらひかる草の波。 | 10.41 | 4.33 |
これを図にプロットすると次のようになります。

生成される音声が1秒伸びるごとにだいたい0.388秒の推論時間がかかっていることがわかります。つまり効率は十分良い(推論時間より生成できる音声のほうが長い)のですが、長文を投げるとその分線形に時間が伸びてしまうことがわかります。
まあ長い文章を投げなければ良いのですが、推論時間より生成できる音声のほうが長いという性質を有効活用しストリーム処理を実装すればこのレイテンシを大きく改善することができます。
ニューラルネットワークのストリーム処理
ストリーム処理とはどんどん流れてくるデータを逐次的に処理していく手法のことで、今回のケースでは音声を頭から少しずつ生成し、出来上がったものから再生バッファに詰めていきます。
ニューラルネットワークに対してこれをやるためには非常に複雑な実装が必要かに思われるかもしれませんが、モデルが畳み込みレイヤーのような局所的な演算しか行わない場合は、入力を適切に分割して順々に推論させることで、オーバーヘッドは多少生じるもののストリーム処理を実現することができます。
このとき入力をどう分割するかというと、モデルのi番目の出力が入力のi-Lからi+L番目までの値のみによって変化するとき(このときの2L+1を受容野と呼んだりします)、それぞれの断片が2Lずつ重複するように入力を分割して推論し、出力時は両端のL要素を切り落としてからつなげることで、全体を一度に推論したときと全く同じ結果を得ることができます。たとえばモデルが一枚のConv1D(kernel=7, padding=3, stride=1)からなる時は下の図のようになり、L=3、つまり適当に断片を切り出してモデルに推論させると両端3要素ずつが本来の出力と異なってしまう(例えばInput[0:9]を推論させるとOutput[0:6]はInput全体を推論したときと同じ結果だが、Output[6:9]はInput[9:]の値に依存するため変化してしまう)ため、Input[0:12], Input[6:18], Input[12:24]...と分割してから推論しそれぞれのOutput[0:9], Output[9:15], Output[15:21]...に該当する部分をつなげることで、Input全体を一度に推論したときと同じOutputを得ることができます。
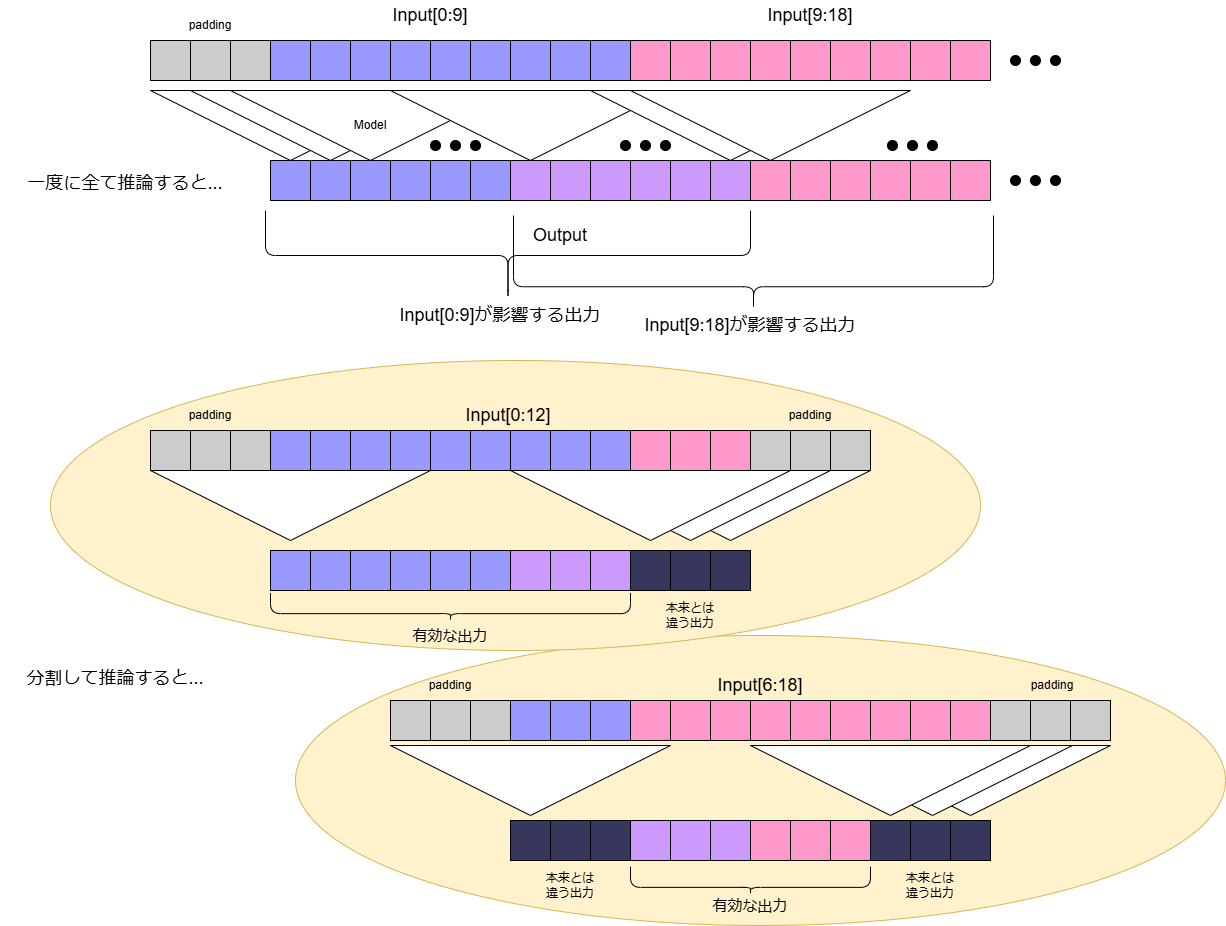
こうすることで、Inputがとても長い系列だった場合でも、Input[0:12]の部分だけ先に推論してしまえば出力の頭部分Output[0:9]がすぐに手に入ることになります。そしてその出力のIO待ち(音声合成であればスピーカーからの出力)をしている間に次の断片Input[6:18]を推論し...と繰り返すことでストリーム処理を行うことができます。
まとめると、入力長がNであると仮定すると推論時間はO(N)となりますが、モデルの受容野が2L+1に制限されているときに限り、入力をそれぞれ2Lずつ重複する長さcの断片に分けて推論を行うことで、レイテンシをO(c)に短縮することが可能です。ただし重複分で無駄な計算を行うため、全体の推論時間はO(N + N*(2L/c))に悪化することになります。注意すべきことは長さc-2Lの出力音声を再生している間に次の入力長さcの推論を終わらせる必要があるため、モデルの推論効率 $\gamma$(生成できる音声長/生成のための推論時間)が $\gamma > \frac{c}{c-2L}$ を満たさなければいけません。これを満たさなかった場合、再生が途中で止まってしまうなどの問題が生じます。
ちなみにこの条件式はかなり悲観的なものになっています。一つの文章を処理している間は再生バッファの"貯金"が持ち越されるため、たまに $\gamma > \frac{c}{c-2L}$ を破ってもたいていの場合はなんとかなります。つまり、$\gamma \leq 1$ のような貧弱なマシンで動かしたい場合や、ギリギリを攻めてもっとレイテンシを縮めたい場合は「最初に用意する再生バッファの長さ $c_0$ 」という変数を追加し、「全体の音声を再生し終わるまでに再生バッファを食いつぶさない」という条件で最適なパラメタ $(c_0, c)$ を探せばよいことになります。
AivisSpeechで利用しているモデル
以上で紹介した分割推論はモデルがConvのみでできている必要があり、Attentionやbidirectional LSTMなどが含まれているモデルでは入力のあらゆる部分が出力に影響するため適用できません。ではAivisSpeechが採用しているモデルでは利用可能でしょうか?
実はAivisSpeechが採用しているStyle-Bert-VITS2において、Decoderと呼ばれる最後の処理部分がHiFi-GANというアーキテクチャになっており、これはConvとConvTransposeのみからなるため分割推論を適用することができます。
また、このHiFi-GANはなかなか処理が重く、同じくHiFi-GANを利用しているVOICEVOXでも推論時間全体の約9割近くがこのHiFi-GANに費やされていることが分かっています。そのためAivisSpeechにおいてもこの部分がボトルネックである可能性が高く、もしそうならここだけをストリーム処理しても十分にレイテンシを短縮することができます。そこで、まずAivisSpeechのモデルからDecoderを切り離し、Decoder以前と以降でそれぞれどれくらいの推論時間がかかっているかを調査しました。
Decoderの処理時間
AivisSpeechが対応しているAIVMXフォーマットはONNXと互換性があるため、ONNXとして処理することでDecoderを切り離すことができます。詳しい方法は省略しますが、今回はDecoder入り口のLeakyReLU-ConvTranspose間で切り離します。
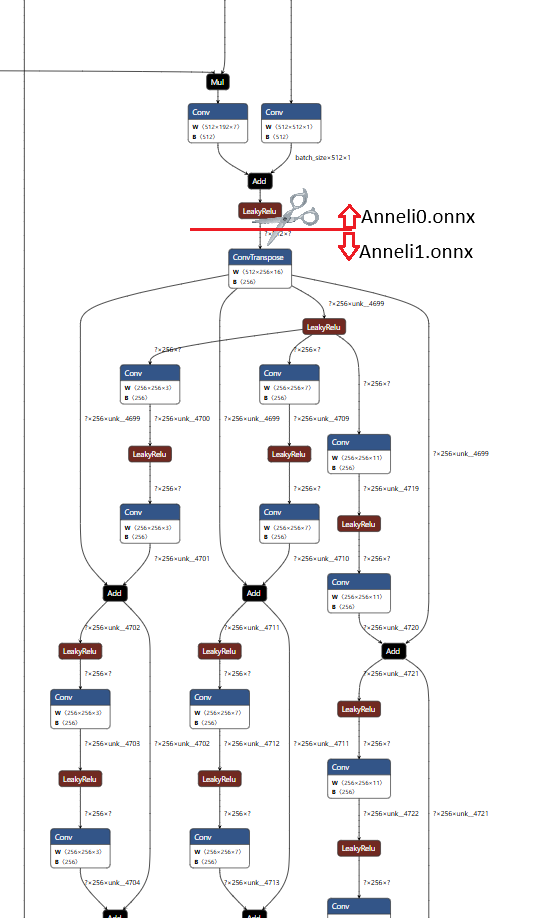
これにより作成したAnneli0.onnx(Decoder以外)とAnneli1.onnx(Decoder)の推論時間を比較します。
| 生成音声長 | Decoder以外の処理時間 | Decoderの処理時間 | 全体の処理時間 | Decoderの処理割合 |
|---|---|---|---|---|
| 1.06 | 0.377 | 0.413 | 0.81 | 51% |
| 1.40 | 0.426 | 0.554 | 0.98 | 57% |
| 1.80 | 0.426 | 0.628 | 1.06 | 59% |
| 1.90 | 0.397 | 0.674 | 1.07 | 63% |
| 2.51 | 0.431 | 0.880 | 1.31 | 67% |
| 3.12 | 0.534 | 1.097 | 1.63 | 67% |
| 5.31 | 0.761 | 1.752 | 2.51 | 70% |
| 7.73 | 1.293 | 2.455 | 3.75 | 65% |
| 10.43 | 1.919 | 3.313 | 5.23 | 63% |
表からわかる通り、Decoderは全体の60%ほどの処理時間をかけています。VOICEVOXほどではありませんが、こちらでもDecoderのストリーム処理は十分に恩恵がありそうです。
Decoderのストリーム処理
マージン幅の計算
Decoderを分割推論させるにあたり、このモデルの受容野を求める必要があります。この受容野はConvolutionのカーネルサイズやdilationのパラメタなどに影響して変化しますが、静的に解析せずとも以下のように入力に注入したnanがどこまで伝播するかで測ることができます。
import onnxruntime
import numpy as np
h = np.zeros((1, 512, 100), np.float32)
h[0,0,0] = np.nan # 左端にnanを置き、これがどれだけ広がるか見る
session = onnxruntime.InferenceSession(
"AivisSpeech-Engine-Dev/Models/Anneli1.onnx",
providers=['CPUExecutionProvider']
)
outputs = session.run(["output"], {"feature": h})[0].ravel()
rightmost_nan = np.where(np.isnan(outputs))[0].max().item() # 受容野の半分(右方向に与える影響幅)
assert np.all(np.isnan(outputs[:rightmost_nan+1])) # all nan
assert np.all(np.isfinite(outputs[rightmost_nan+1:])) # all numeric
print("input length", h.shape[-1])
print("output length", len(outputs))
ratio = len(outputs) / h.shape[-1]
print("ratio", ratio)
receptive = rightmost_nan * 2 + 1
print("receptive field (output) is", receptive)
print("receptive field (time) is", receptive / 44100, "sec")
print("receptive field (input) is", int(np.ceil(receptive / ratio)))
print("margin (input) must be", int(np.ceil(rightmost_nan / ratio)))
結果は次のようになりました
input length 100
output length 51200
ratio 512.0
receptive field (output) is 11109
receptive field (time) is 0.2519047619047619 sec
receptive field (input) is 22
margin (input) must be 11
つまり、このDecoderは入力の0.25秒に相当する部分を局所的に参照しながら推論しており、また入力特徴量の長さを512倍した結果が44100Hzの音声長になることが分かります。そのため入力特徴量のフレームレートは44100/512=86.13Hzであり、秒数で表現されたある区間[start, end]を推論したい場合は、入力特徴量のそれにあたる区間[start*86.13, end*86.13]の左右にL=11フレームずつのマージンを付加した上でモデルに入れる必要があります。
この $L=11$ と音声1秒当たりの全体推論時間 $1/\gamma = 0.388$ をもとに前述の $\gamma > \frac{c}{c-2L}$ を解くと、最適な断片幅$c$は36フレームとなります。そこでこの記事では安全側に倒して50フレーム(=0.58秒)ずつ推論することにします。
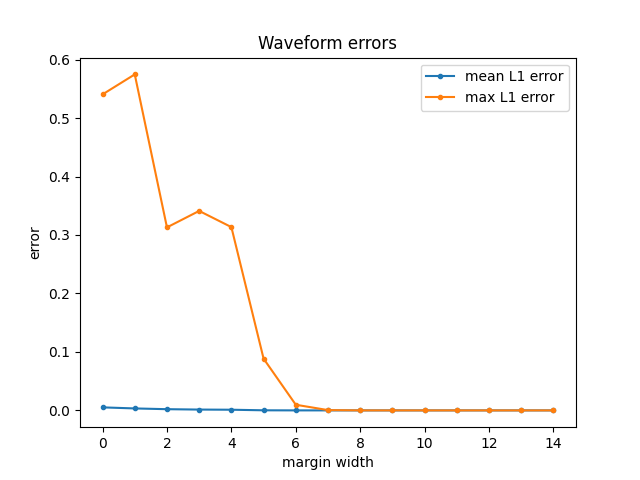
まずは算出したマージン幅L=11が妥当なものかどうかを検証します。今まで通り全体を音声合成したものと、様々なマージン幅で分割推論した場合の音声波形を比べ、誤差がどうなるか調査しました。
適当な文章でDecoderの手前まで計算したものfeature.npyを用意し、Decoder推論を一括・分割でそれぞれ行い生成された音声の絶対値誤差を比較したのが以下の図になります。
また、誤差を対数で評価するPSNR(高い方が品質が良い)では次のようになります。

この図からわかる通り、マージン幅が9以上になれば分割推論でもほとんど同一な音声を再現することが可能です。
ちなみに、マージン幅が小さすぎる場合だと以下のように分割位置で大きな誤差が発生していることがわかります。
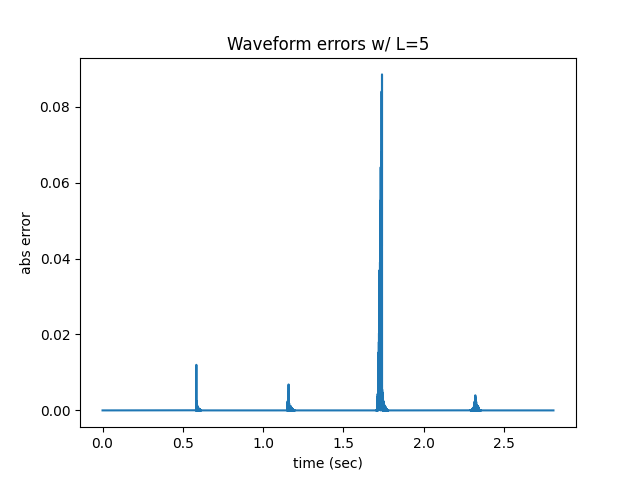
以上よりマージン幅はL=11でよさそうです。
yield文を活用した分割推論の実装
ここからはAivisSpeech Engineの実装と内部で利用しているStyle-Bert-VITS2 を改造することで分割推論による音声合成を実装します。まずはStyle-Bert-VITS2のTTSモデルを、yieldによって逐次的に音声を返すジェネレータに書き換えます。
# generatorを返す関数に書き換える
def infer_onnx(
text: str,
style_vec: NDArray[Any],
sdp_ratio: float,
noise_scale: float,
noise_scale_w: float,
length_scale: float,
sid: int, # In the original Bert-VITS2, its speaker_name: str, but here it's id
language: Languages,
hps: HyperParameters,
onnx_session_0: onnxruntime.InferenceSession,
onnx_session_1: onnxruntime.InferenceSession,
onnx_providers: Sequence[Union[str, tuple[str, dict[str, Any]]]],
skip_start: bool = False,
skip_end: bool = False,
assist_text: Optional[str] = None,
assist_text_weight: float = 0.7,
given_phone: Optional[list[str]] = None,
given_tone: Optional[list[int]] = None,
) -> Generator[NDArray[Any], None, None]:
h = infer_onnx_0( # 元のinfer_onnxからDecoderの手前までの処理をとってくる
text,
style_vec,
sdp_ratio,
noise_scale,
noise_scale_w,
length_scale,
sid,
language,
hps,
onnx_session_0,
onnx_providers,
skip_start,
skip_end,
assist_text,
assist_text_weight,
given_phone,
given_tone,
)
yield from infer_onnx_1( # 分割推論版Decoderの処理
h,
onnx_session_1,
onnx_providers,
)
def infer_onnx_1(
feat: NDArray[Any],
onnx_session: onnxruntime.InferenceSession,
onnx_providers: Sequence[Union[str, tuple[str, dict[str, Any]]]],
) -> Generator[NDArray[Any], None, None]:
...
io_binding = onnx_session.io_binding()
CHUNK = 50
MARGIN = 11
for i in range(0, feat.shape[1], CHUNK):
left_margin = min(i, MARGIN)
right_margin = min(feat.shape[1] - (i+CHUNK), MARGIN)
fseg = feat[None, :, i-left_margin : i+CHUNK+right_margin]
for name, value in zip(["feature"], [fseg]):
gpu_tensor = onnxruntime.OrtValue.ortvalue_from_numpy(
value, device_type, device_id
)
io_binding.bind_ortvalue_input(name, gpu_tensor)
# 推論の実行
io_binding.bind_output(output_name, device_type)
onnx_session.run_with_iobinding(io_binding)
output = io_binding.get_outputs()[0].numpy()[0, 0]
output = output[left_margin*512 : len(output) - right_margin*512]
yield output
class TTSModel:
def __init__(
self,
model_path: Path,
config_path: Union[Path, HyperParameters],
style_vec_path: Union[Path, NDArray[Any]],
device: str = "cpu",
onnx_providers: Sequence[Union[str, tuple[str, dict[str, Any]]]] = ["CPUExecutionProvider"],
) -> None:
...
# Decoder以外とDecoderのonnx_sessionをそれぞれ保持する
self.onnx_session_0: Optional[onnxruntime.InferenceSession] = None
self.onnx_session_1: Optional[onnxruntime.InferenceSession] = None
...
def infer(...): # (sample rate, floatの音声波形)を返すGenerator
...
audio_generator = infer_onnx(...)
...
for audio in audio_generator:
if not (pitch_scale == 1.0 and intonation_scale == 1.0):
_, audio = adjust_voice(
fs=self.hyper_parameters.data.sampling_rate,
wave=audio,
pitch_scale=pitch_scale,
intonation_scale=intonation_scale,
)
yield (self.hyper_parameters.data.sampling_rate, audio)
そしてAivisSpeech Engineの側で44.1kHzから48kHzへの変換、前後無音追加などの後処理、そしてOgg Opusへの変換などを行います。
class StyleBertVITS2TTSEngine(TTSEngine):
def synthesize_wave(
self,
query: AudioQuery,
style_id: StyleId,
enable_interrogative_upspeak: bool = True,
) -> Generator[NDArray[np.float32], None, None]:
...
raw_wave_generator = model.infer(
text=text,
given_phone=given_phone_list,
given_tone=given_tone_list,
language=Languages.JP,
speaker_id=local_speaker_id,
style=local_style_name,
style_weight=style_weight,
sdp_ratio=sdp_ratio,
length=length,
pitch_scale=pitch_scale,
line_split=False,
)
for i, (raw_sample_rate, raw_wave) in enumerate(raw_wave_generator):
if i == 0:
# 無音追加
pre_silence_length = int(raw_sample_rate * query.prePhonemeLength)
silence_wave_pre = np.zeros(pre_silence_length, dtype=np.float32)
raw_wave = np.concatenate((silence_wave_pre, raw_wave))
# 生成した音声の音量調整/サンプルレート変更/ステレオ化を行ってから返す
wave = raw_wave_to_output_wave(query, raw_wave, raw_sample_rate)
yield wave
/ttsエンドポイントもストリーミング処理に変更しますが、wav音声を返す方式のままだとヘッダに入れるファイルサイズ等の計算が面倒なので、ストリーミングに適したフォーマットに変更します。検討したのは以下の三つで、最終的にOggOpusにしました。
- linear PCM: 音声を無圧縮で返す。音声波形を適切にバイナリに変換するだけなので実装が一番楽。Discordの音声再生に対応させたい場合は「48kHz ステレオ リトルエンディアン符号付き16bit linear PCM」で返す必要がある。
- Opus: 音声を圧縮して返す形式で、ストリーミングに強い。今回のようにインターネットを経由する場合は圧縮した方が良いかも。固定の長さ(数十ミリ秒)の音声を1フレームとして逐次的に圧縮し送信する。Opusフレームには自身のサイズがおそらく書かれておらず、連続的に送信する際は各フレームの区切り位置を明示する必要があり送受信の実装が面倒。
- OggOpus: OpusをOggコンテナに入れた音声フォーマット。再生側もストリーミングに対応しているため、適切なOggヘッダに続いてOpusを詰めたOggページを送ればストリーミング再生が可能。
OggやOpusのエンコーダはPyOggを利用しました。
import io
from pyogg import OpusBufferedEncoder, OggOpusWriter # apt-get install opus-toolsが必要
def generate_tts_pipeline_router(...):
...
@router.post(
"/tts",
response_class=StreamingResponse,
responses={
200: {
"content": {
"audio/opus": {"schema": {"type": "string", "format": "binary"}}
},
}
},
tags=["音声合成"],
summary="テキストから直接音声を合成する",
)
def tts(body: TTSRequest):
text, style_id = body.text, body.speaker
version = LATEST_VERSION
engine = tts_engines.get_engine(version)
accent_phrases = engine.create_accent_phrases(text, style_id)
query = AudioQuery(
accent_phrases=accent_phrases,
speedScale=1.0,
intonationScale=1.0,
tempoDynamicsScale=1.0,
pitchScale=0.0,
volumeScale=1.0,
prePhonemeLength=0.1,
postPhonemeLength=0.1,
pauseLength=None,
pauseLengthScale=1,
outputSamplingRate=48000, # 48kHz固定
outputStereo=False,
kana=text,
)
wave_generator = engine.synthesize_wave(query, style_id)
encoder = OpusBufferedEncoder()
encoder.set_application("audio") # TTSなので音声用圧縮"voip"でもいいかも
encoder.set_channels(1)
encoder.set_frame_size(20)
encoder.set_sampling_frequency(48000)
writer = OggOpusWriter(io.BytesIO(), encoder)
def binary_gen():
for wave in wave_generator:
wave = (wave.clip(-1, 1) * 32767).astype('<i2')
writer.write(bytearray(wave.tobytes()))
yield writer._file.getvalue()
writer._file = io.BytesIO()
writer.close()
yield writer._file.getvalue()
return StreamingResponse(binary_gen(), media_type="audio/opus")
Discordボットをストリーム処理に対応させる
これでOgg-Opusが降ってくるようになったのでDiscordボットをこれに対応させます。変更箇所は少なく、AudioResourceを作成する際のinputTypeをOgg-Opusにするだけです。
...
} else {
// speak
mutex.runExclusive(async () => {
if (connection) {
const {data} = await getSpeech(cloud_client, message.content);
const resource = createAudioResource(data, {inputType: StreamType.OggOpus});
const playFinished = new Promise<void>((resolve) => {
audioPlayer?.once(AudioPlayerStatus.Idle, resolve);
audioPlayer?.play(resource);
});
let timeout;
await Promise.race([
playFinished,
new Promise<void>((resolve) => {
timeout = setTimeout(() => {
console.log(`timeout. message: ${message.content}`);
audioPlayer?.removeAllListeners();
audioPlayer?.stop();
resolve();
}, 10 * 1000);
}),
]);
clearTimeout(timeout);
}
});
}
...
これで当初の推論速度とストリーム版のレイテンシを比較してみると以下のようになります。
| 生成音声長(秒) | ナイーブ処理の時間(秒) | ストリーム処理のレイテンシ(秒) |
|---|---|---|
| 1.06 | 0.77 | 0.803 |
| 1.37 | 0.85 | 1.002 |
| 1.78 | 0.89 | 1.384 |
| 1.95 | 1.19 | 1.207 |
| 2.47 | 1.16 | 0.994 |
| 3.16 | 1.32 | 1.316 |
| 5.35 | 2.29 | 1.571 |
| 7.67 | 3.32 | 2.112 |
| 10.41 | 4.33 | 2.794 |
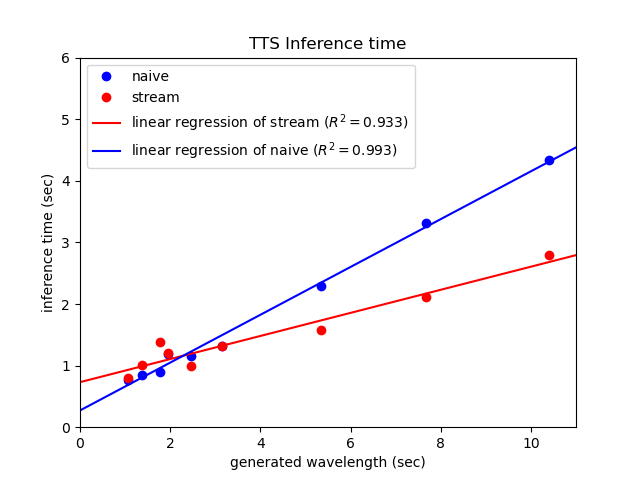
ある程度のオーバーヘッドが生まれてしまっていますが、生成音声2秒がを超えるとストリーム処理の方が有利になっていることが分かります。
(おまけ)VOICEVOXでの活動
というようなことを現在VOICEVOXに実装中です。様々なマシンで様々なユーザーが使うというのもあり、ここで書いたようなコードをポンと入れるわけにはいかないのですが着実に進んでいます。
まとめ
これで「AivisSpeechを使ったDiscordボットの作成」シリーズは完結です。僕自身色々と勉強できてためになりました。