この記事はTSG Advent Calendar 2024の2日目の記事です。
AivisSpeechについて
最近AivisSpeechというText to speechエンジンが登場しましたね。
これはVOICEVOXをベースとしたエンジン・UIで、VOICEVOXと同様オープンソースで公開されています。
さらにこのエンジンはAIVMXと呼ばれる独自規格による音声モデルをサポートしており、AivisHubと呼ばれるモデル共有サイトにて主にACMLライセンスで様々な音声モデルをダウンロードすることができます。
この記事はシリーズものになっており(多分。やる気が続けば)、アドベントカレンダーが終わるまでに
- AivisSpeechエンジンをGoogle Cloud Runにデプロイする形でTTSサーバーを作り、
- Discord上で動作するテキスト読み上げボットを作成する方法を紹介します。
- さらに、応用編としてエンジンを改造することでTTSサーバーの応答速度の高速化にチャレンジします。
まずは第一弾としてこの記事ではAivisSpeechエンジンをGoogle Cloud Runにデプロイするところまでを紹介します。
AivisSpeech Engineをローカルで動かす
まず初めにエンジンをローカルで動かしてみましょう。公式リポジトリはこちらにあります。
クラウドへのデプロイを見据えてUbuntu上で操作します。Pythonのバージョンは3.11.10です。
$ git clone -b 1.0.0 https://github.com/Aivis-Project/AivisSpeech-Engine
$ cd AivisSpeech-Engine
$ python -m venv venv
$ source venv/bin/activate
(venv) $ pip install poetry poetry-plugin-export pre-commit
(venv) $ pre-commit install
(venv) $ poetry install
公式のAnneliモデルをダウンロードしておきます。今回はソースコードから環境構築したのでモデルの保存先は~/.local/share/AivisSpeech-Engine-Dev/Modelsです。
(venv) $ ls ~/.local/share/AivisSpeech-Engine-Dev/Models/
Anneli.aivmx
(venv) $ python run.py
[2024/11/22 22:31:08] INFO: AivisSpeech Engine version latest
[2024/11/22 22:31:08] INFO: Engine root directory: /home/avocado/github/AivisSpeech-Engine
[2024/11/22 22:31:08] INFO: User data directory: /home/avocado/.local/share/AivisSpeech-Engine-Dev
[2024/11/22 22:31:08] INFO: Models directory: /home/avocado/.local/share/AivisSpeech-Engine-Dev/Models
[2024/11/22 22:31:08] INFO: Installed AIVM models:
[2024/11/22 22:31:08] INFO: - Anneli (a59cb814-0083-4369-8542-f51a29e72af7)
[2024/11/22 22:31:08] INFO: Using CPU for inference.
[2024/11/22 22:31:08] INFO: Loading BERT model and tokenizer...
model.onnx: 100%|██████████████████████████████████████████████████████████████████| 1.30G/1.30G [01:01<00:00, 21.2MB/s]
tokenizer_config.json: 100%|███████████████████████████████████████████████████████████| 520/520 [00:00<00:00, 6.02MB/s]
vocab.txt: 100%|████████████████████████████████████████████████████████████████████| 88.2k/88.2k [00:00<00:00, 570kB/s]
special_tokens_map.json: 100%|█████████████████████████████████████████████████████████| 125/125 [00:00<00:00, 1.59MB/s]
tokenizer.json: 100%|█████████████████████████████████████████████████████████████████| 431k/431k [00:00<00:00, 856kB/s]
[2024/11/22 22:32:15] INFO: BERT model and tokenizer loaded. (66.14s)
reading /home/avocado/.local/share/AivisSpeech-Engine-Dev/user.dict_csv-98bb42f1-f920-4fc7-9b92-e091dfebaa65.tmp ... 730932
emitting double-array: 100% |###########################################|
done!
[2024/11/22 22:32:16] INFO: Started server process [15712]
[2024/11/22 22:32:16] INFO: Waiting for application startup.
[2024/11/22 22:32:16] INFO: Application startup complete.
[2024/11/22 22:32:16] INFO: Uvicorn running on http://localhost:10101 (Press CTRL+C to quit)
これでローカルにAPIサーバーが立ち上がりました。話者一覧を見てみます。
$ curl -s http://localhost:10101/speakers | jq .
[
{
"name": "Anneli",
"speaker_uuid": "e756b8e4-b606-4e15-99b1-3f9c6a1b2317",
"styles": [
{
"name": "ノーマル",
"id": 888753760,
"type": "talk"
},
{
"name": "通常",
"id": 888753761,
"type": "talk"
},
{
"name": "テンション高め",
"id": 888753762,
"type": "talk"
},
{
"name": "落ち着き",
"id": 888753763,
"type": "talk"
},
{
"name": "上機嫌",
"id": 888753764,
"type": "talk"
},
{
"name": "怒り・悲しみ",
"id": 888753765,
"type": "talk"
}
],
"version": "1.0.0",
"supported_features": {
"permitted_synthesis_morphing": "NOTHING"
}
}
]
ここに表示されている話者IDを指定することでTTSができます。
$ curl -s -XPOST 'http://localhost:10101/audio_query?text=%E3%83%A1%E3%83%AA%E3%83%BC%E3%82%AF%E3%83%AA%E3%82%B9%E3%83%9E%E3%82%B9%EF%BC%81&speaker=888753760' | curl -s -XPOST -H "Content-Type: application/json" -d @- 'http://localhost:10101/synthesis?speaker=888753760' > audio.wav
$ file audio.wav
audio.wav: RIFF (little-endian) data, WAVE audio, Microsoft PCM, 16 bit, mono 44100 Hz
うまくwavファイルを生成できました。
シンプルなエンドポイントを作る
今回の最終目標はdiscordの読み上げボットなので、テキストと話者IDを投げると音声が返ってくるAPIエンドポイントを作ります。
voicevox_engine/app/routers/tts_pipeline.pyのgenerate_tts_pipeline_routerに/ttsというエンドポイントを追加します。
class TTSRequest(BaseModel):
text: str
speaker: StyleId
def generate_tts_pipeline_router(
tts_engines: TTSEngineManager,
preset_manager: PresetManager,
cancellable_engine: CancellableEngine | None,
) -> APIRouter:
"""音声合成 API Router を生成する"""
router = APIRouter()
@router.post(
"/tts",
response_class=FileResponse,
responses={
200: {
"content": {
"audio/wav": {"schema": {"type": "string", "format": "binary"}}
},
}
},
tags=["音声合成"],
summary="テキストから直接音声を合成する",
)
def tts(body: TTSRequest):
text, style_id = body.text, body.speaker
version = LATEST_VERSION
engine = tts_engines.get_engine(version)
accent_phrases = engine.create_accent_phrases(text, style_id)
query = AudioQuery(
accent_phrases=accent_phrases,
speedScale=1.0,
intonationScale=1.0,
tempoDynamicsScale=1.0,
pitchScale=0.0,
volumeScale=1.0,
prePhonemeLength=0.1,
postPhonemeLength=0.1,
pauseLength=None,
pauseLengthScale=1,
outputSamplingRate=engine.default_sampling_rate,
outputStereo=False,
# kana=create_kana(accent_phrases),
kana=text, # AivisSpeech Engine では音声合成時に読み上げテキストも必要なため、kana に読み上げテキストをそのまま入れて返す
)
wave = engine.synthesize_wave(
query, style_id
)
with NamedTemporaryFile(delete=False) as f:
soundfile.write(
file=f, data=wave, samplerate=query.outputSamplingRate, format="WAV"
)
return FileResponse(
f.name,
media_type="audio/wav",
background=BackgroundTask(try_delete_file, f.name),
)
text, speakerをjson形式でrequest bodyに入れて送信することに注意してクエリをテストしてみます
$ curl -s -XPOST \
-H 'Content-Type: application/json' \
-d '{"text":"メリークリスマス","speaker":888753760}' \
"http://localhost:10101/tts" > audio.wav
$ file audio.wav
audio.wav: RIFF (little-endian) data, WAVE audio, Microsoft PCM, 16 bit, mono 44100 Hz
うまくいきました。
Google Cloud Runにデプロイする
次はこのエンジンをクラウドに載せようと思います。
Docker imageの作成
デプロイをする前に先ほどローカルで作った環境をdockerイメージにする必要があります。
イメージの軽量化のために、ローカルのリポジトリに以下の変更をさらに加えた環境をDockerfileとして記述します。
diff --git a/pyproject.toml b/pyproject.toml
index b791b85..6dffa10 100644
--- a/pyproject.toml
+++ b/pyproject.toml
@@ -89,12 +89,6 @@ aivmlib = { git = "https://x-access-token:github_pat_11AJLTV7Q0LW9wXdYid0Oa_nHO4
style-bert-vits2 = { git = "https://github.com/tsukumijima/Style-Bert-VITS2", rev = "e834299b27e6378d9b3062f1b270f38414a94389" }
# OS に応じて適切な ONNX Runtime プラグインをインストール
onnxruntime = "^1.20.0"
-onnxruntime-directml = { version = "^1.20.0", markers = "sys_platform == 'win32' and (platform_machine == 'x86_64' or platform_machine == 'AMD64')" }
-onnxruntime-gpu = [
- # Windows では若干速度は落ちるが onnxruntime-directml で代用できるのとファイルサイズがデカいので、当面インストールしない
- # { version = "^1.20.0", markers = "sys_platform == 'win32' and (platform_machine == 'x86_64' or platform_machine == 'AMD64')" },
- { version = "^1.20.0", markers = "sys_platform == 'linux' and platform_machine == 'x86_64'" },
-]
[tool.poetry.group.dev.dependencies]
pysen = "^0.11.0"
$ mkdir docker
$ git diff > docker/diff.patch # pyprojectの変更とttsエンドポイント追加の変更をパッチにする
$ cp -r ~/.local/share/AivisSpeech-Engine-Dev/ docker/AivisSpeech-Engine-Dev/
$ rm docker/AivisSpeech-Engine-Dev/Logs/*
上で作ったdockerディレクトリでDockerfileを作ります。
FROM python:3.11.10-bookworm
RUN git clone -b 1.0.0 https://github.com/Aivis-Project/AivisSpeech-Engine /opt/AivisSpeech-Engine
WORKDIR /opt/AivisSpeech-Engine
RUN pip install poetry poetry-plugin-export pre-commit
COPY ./diff.patch /opt/AivisSpeech-Engine/
RUN patch -p1 < diff.patch
RUN poetry config virtualenvs.create false
RUN poetry lock --no-update && poetry install && rm -rf /root/.cache/pypoetry
COPY ./AivisSpeech-Engine-Dev /root/.local/share/AivisSpeech-Engine-Dev/
ENV PORT=10101
CMD ["sh", "-c", "python run.py --host 0.0.0.0 --port $PORT"]
~/AivisSpeech-Engine/docker$ docker build -t asengine:1.0.0 .
~/AivisSpeech-Engine/docker$ docker run -it --rm -p 10101:10101 asengine:1.0.0
[2024/11/22 15:00:07] INFO: AivisSpeech Engine version latest
[2024/11/22 15:00:07] INFO: Engine root directory: /opt/AivisSpeech-Engine
[2024/11/22 15:00:07] INFO: User data directory: /root/.local/share/AivisSpeech-Engine-Dev
[2024/11/22 15:00:07] INFO: Models directory: /root/.local/share/AivisSpeech-Engine-Dev/Models
[2024/11/22 15:00:07] INFO: Installed AIVM models:
[2024/11/22 15:00:07] INFO: - Anneli (a59cb814-0083-4369-8542-f51a29e72af7)
[2024/11/22 15:00:07] INFO: Using CPU for inference.
[2024/11/22 15:00:07] INFO: Loading BERT model and tokenizer...
[2024/11/22 15:00:09] INFO: BERT model and tokenizer loaded. (2.34s)
reading /root/.local/share/AivisSpeech-Engine-Dev/user.dict_csv-539df93d-d297-47fd-8de3-580c9e514dd2.tmp ... 730932
emitting double-array: 100% |###########################################|
done!
[2024/11/22 15:00:11] INFO: Started server process [7]
[2024/11/22 15:00:11] INFO: Waiting for application startup.
[2024/11/22 15:00:11] INFO: Application startup complete.
[2024/11/22 15:00:11] INFO: Uvicorn running on http://0.0.0.0:10101 (Press CTRL+C to quit)
これでdocker上でサーバーを立てることができました。
Google Cloud Runのセットアップ
こちらと大体流れは一緒ですが、今回はローカル上でdocker buildしたのでローカルからGCPを叩いてみます。
新しいプロジェクトを作成
今回はaivis-gcrという名前で作成しました。
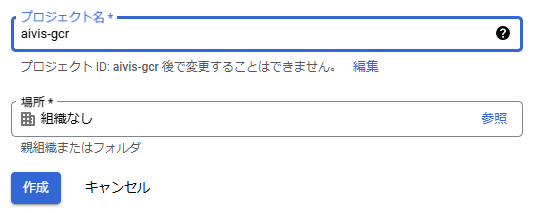
利用するArtifact RegistryとCloud Runを有効化しておきます。

Google Cloud CLIのセットアップ
https://cloud.google.com/sdk/docs/install-sdk?hl=ja#deb に従ってCLIをセットアップします。
$ gcloud --version
Google Cloud SDK 502.0.0
alpha 2024.11.15
beta 2024.11.15
bq 2.1.9
bundled-python3-unix 3.11.9
core 2024.11.15
gcloud-crc32c 1.0.0
gsutil 5.31
そして gcloud auth login を実行してGoogleアカウントにログインします。
Artifact Registryにリポジトリを作成する
aivis-speechという名前でリポジトリを作成します。
$ gcloud artifacts repositories create aivis-speech --repository-format=docker \
--location=us-central1 --description="AivisSpeech Engine" \
--project=aivis-gcr
Create request issued for: [aivis-speech]
...
$ gcloud artifacts repositories list --project=aivis-gcr
Listing items under project aivis-gcr, across all locations.
ARTIFACT_REGISTRY
REPOSITORY FORMAT MODE DESCRIPTION LOCATION LABELS ENCRYPTION CREATE_TIME UPDATE_TIME SIZE (MB)
aivis-speech DOCKER STANDARD_REPOSITORY AivisSpeech Engine us-central1 Google-managed key 2024-11-23T00:44:31 2024-11-23T00:44:31 0
無事作成できていることがわかります。
Artifact Registryにimageをpushする
先ほど作成した asengine:1.0.0 というdockerイメージにリージョン名-docker.pkg.dev/プロジェクト名/リポジトリ名/dockerイメージ名:タグ名のタグをつけてアップロードします。
$ gcloud auth configure-docker us-central1-docker.pkg.dev
$ docker tag asengine:1.0.0 us-central1-docker.pkg.dev/aivis-gcr/aivis-speech/asengine:1.0.0
$ docker push us-central1-docker.pkg.dev/aivis-gcr/aivis-speech/asengine:1.0.0
Cloud Runにimageをデプロイする
次にArtifact Registry上のdockerイメージをCloud Runにデプロイし、サーバーを立ててみます。
が、その前に少しやることがあります。
サービスアカウントの作成
このままdockerイメージをCloud Runにデプロイし、パブリックにサーバーを公開しても良いのですが、関係ない人がアクセスしてしまうと自分の財布が痛んでしまいます。そこでサービスアカウントを作成し、それに紐づいたIDトークンを認証することで限られたプログラム(今回はDiscordボット)のみがアクセスできるようにします。
これからデプロイするTTSサーバーを叩きたいプログラムに所持させるためのサービスアカウントを作成します。今回はdiscord-tts-botというIDにします。
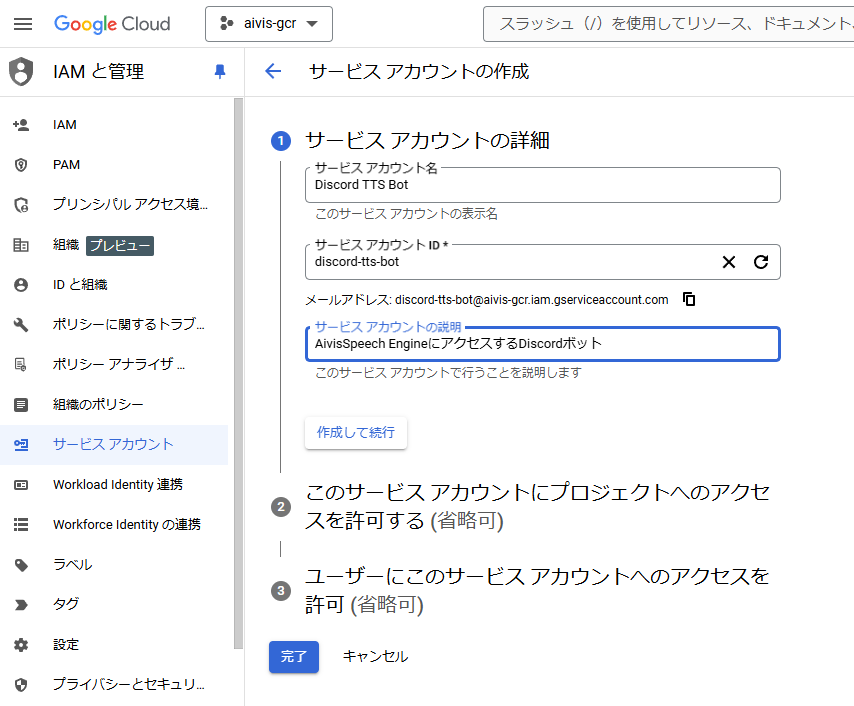
そしてサービスアカウントのキーを作成し、ローカルに保存します。これはDiscordボットを作る時に認証用の秘密鍵として利用します。
ここで作成したキーは漏洩しないように厳重に管理してください。うっかりパブリックリポジトリにPushしたりしないように...
Cloud Runサービスの作成
ついにdockerイメージのデプロイを行います。Cloud Runコンソールからサービスの作成を選択し、Artifact Registry上のイメージ名を設定、認証は「認証が必要」を選択、他はなるべく安くなるように以下のように設定しています。
- リクエストの処理中にのみ CPU を割り当てる
- インスタンスの最小数:0 ... これが1以上だとずっとサーバーが立ち上がるため一日中課金されます
- リソース:8GBメモリ 8CPU ... メモリは4GB以下だと起動できないようです
- リクエストのタイムアウト:10秒 ... あまり長いとDiscordボットが黙ったままになる可能性があります
- インスタンス当たりの最大同時リクエスト数:1
- 実行環境:第一世代 ... コールドスタート(インスタンス数0から1へのスケール)が速いらしいので
- インスタンスの最大数:3 ... アクセスが集中してもこの最大数までしか立ち上がりません
「認証が必要」というオプションを選択しないと上で作ったサービスアカウントの意味がなくなってしまいます。
エンドポイントURLも一応秘密にしておきましょう。
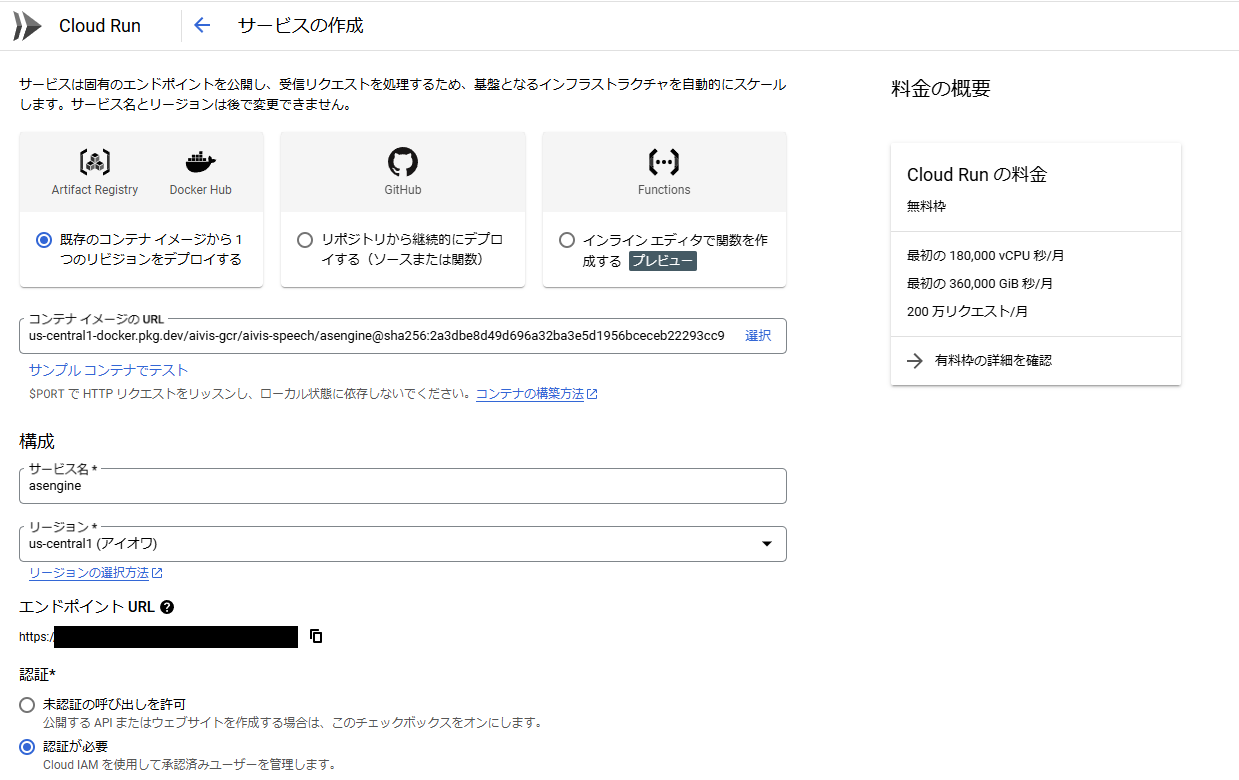
サービス名にチェックマークが付けば成功です。
サービスアカウントの紐づけ
試しにエンドポイントURLにアクセスしてみるとわかりますが、Forbiddenエラーが返ってきます。これはアクセスの際に認証が必要なためです。
先ほど作成したdiscord-tts-botサービスアカウントがアクセスできるように設定しましょう。
Cloud Runサービス一覧のところでサービスのチェックボックスを選択すると、権限というボタンが現れるのでそこから権限タブを開き、「プリンシパルを追加」を選択します。

そこで先ほど作成したサービスアカウントに紐づいているメールアドレス(サービスアカウントページで確認できます)を選択し、Cloud Run Invoker (Cloud Run 起動元)を割り当てます。
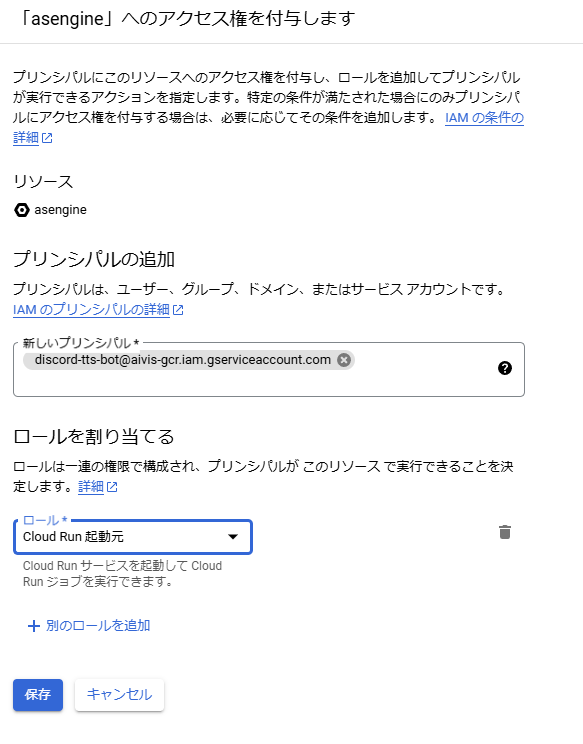
サービスアカウントからのAPIアクセス
紐づけたサービスアカウントを用いてTTSサーバーにアクセスするには、まずローカルにダウンロードしてあるキーファイルをGoogleの認証ライブラリに渡してトークンIDを発行してもらい、そのトークンIDと一緒にTTSサーバーにリクエストを送るという流れになります。いったんライブラリではなくgcloud CLIでこの流れをテストしてみましょう。
まずサービスアカウントに接続
$ gcloud auth activate-service-account \
discord-tts-bot@aivis-gcr.iam.gserviceaccount.com \
--key-file *******.json
Activated service account credentials for: [discord-tts-bot@aivis-gcr.iam.gserviceaccount.com]
そしてアクティブアカウントがdiscord botのサービスアカウントになっているか確認
$ gcloud auth list
Credentialed Accounts
ACTIVE ACCOUNT
* discord-tts-bot@aivis-gcr.iam.gserviceaccount.com
print-identity-tokenで得られるトークンIDをBearerトークンとしてヘッダに入れてアクセス
$ curl \
-H "Authorization: Bearer $(gcloud auth print-identity-token)" \
-H 'Content-Type: application/json' \
-d '{"text":"メリークリスマス","speaker":888753760}' \
"https://<Cloud RunのエンドポイントURL>/tts" \
> audio_cloud.wav
waveファイルが降ってきたら成功です。
まとめ
この記事ではAivisSpeechというテキスト音声合成ライブラリをGoogle Cloud Runにデプロイし、TTSサービスを作る方法を紹介しました。次回はこのサービスを使ってDiscordボットを作成してみます。