背景
最近、主要なLLMサービスのAPIを利用した実験やPoCなどを行う機会が増えてきており、LLMを活用する際に「日本語テキストをどれくらいのトークン数として見積もればよいのか」という問題に直面する場面が増えてきました。ネットの記事を検索してみると、「英語よりもトークン数は多くなる傾向」「日本語は1.3文字ほどを見積もれば良い」などの記事が見られるものの、
- 文章のドメインの違い(難しい文章、ネットの文章など)からどのくらいトークン数の違いが生まれるのか?
- トークン数だけでなく、コストとして考えるとどれが一番安くなるのか?
といった疑問があったため実際に自分で調べてみることにしました。
今回は、以下の4つの主要LLMについて、日本語1文字あたりのトークン数を調査してみました。
- GPT-5
- Claude Sonnet 4.5
- Gemini 2.5 Pro
- Grok 4
(記事を書く速度が遅く、Claude Opus 4.5やGemini3などの最先端モデルで揃えられていません![]() )
)
これらのLLMのトークンカウントAPIを使って、オープンデータとして提供されている以下のデータを投入してみます。
- 青空文庫データセット から2,000件
- ニコニコ大百科のオープンデータ から1,000件
青空文庫は硬めの表現の多い文学小説が主体となっているため、レアな単語に使われるレアな漢字が多くなり、それが結果として一般的な文章よりもトークン数が増えそうなイメージがあり(おそらくByte Pair Encodingの仕組みからしてそうなるはず)、一方のニコニコ大百科データではネットの一般的な文章に近く、ボキャブラリー自体は狭くなるためトークン数のばらつきは小さくなりそう、といったイメージで採用しています。
調査方法
各モデルでのトークンカウント
各モデルにはPython向けモジュールが提供されており、その機能としてテキストをトークン化するものが用意されています。しかも、これらはいずれも無料で(OpenAI以外ではAPIキーの発行は必要ながらもAPI利用量にはカウントされず)使用できます。
| モデル | 使用ライブラリ | 備考 |
|---|---|---|
| ChatGPT | tiktoken | API Keyがいらず、ローカルで完結 |
| Claude | anthropic-sdk-python | API Keyが必要 |
| Gemini | python-genai | API Keyが必要 |
| Grok | xai-sdk-python | API Keyが必要 |
比較するツールを作る
これら4種類のトークナイザを雑に同時に叩いてコストを計算するようなものが欲しかったのですが、ざっと探したところ見つかりませんでした。そこで、ClaudeCodeにお任せして作ってもらいました。
これはStreamlitアプリとしてブラウザからテキストを貼り付けて比較する(あるいはテキストファイルをアップロードして比較する)ことも、モジュールとしてコードから呼び出すこともできます。
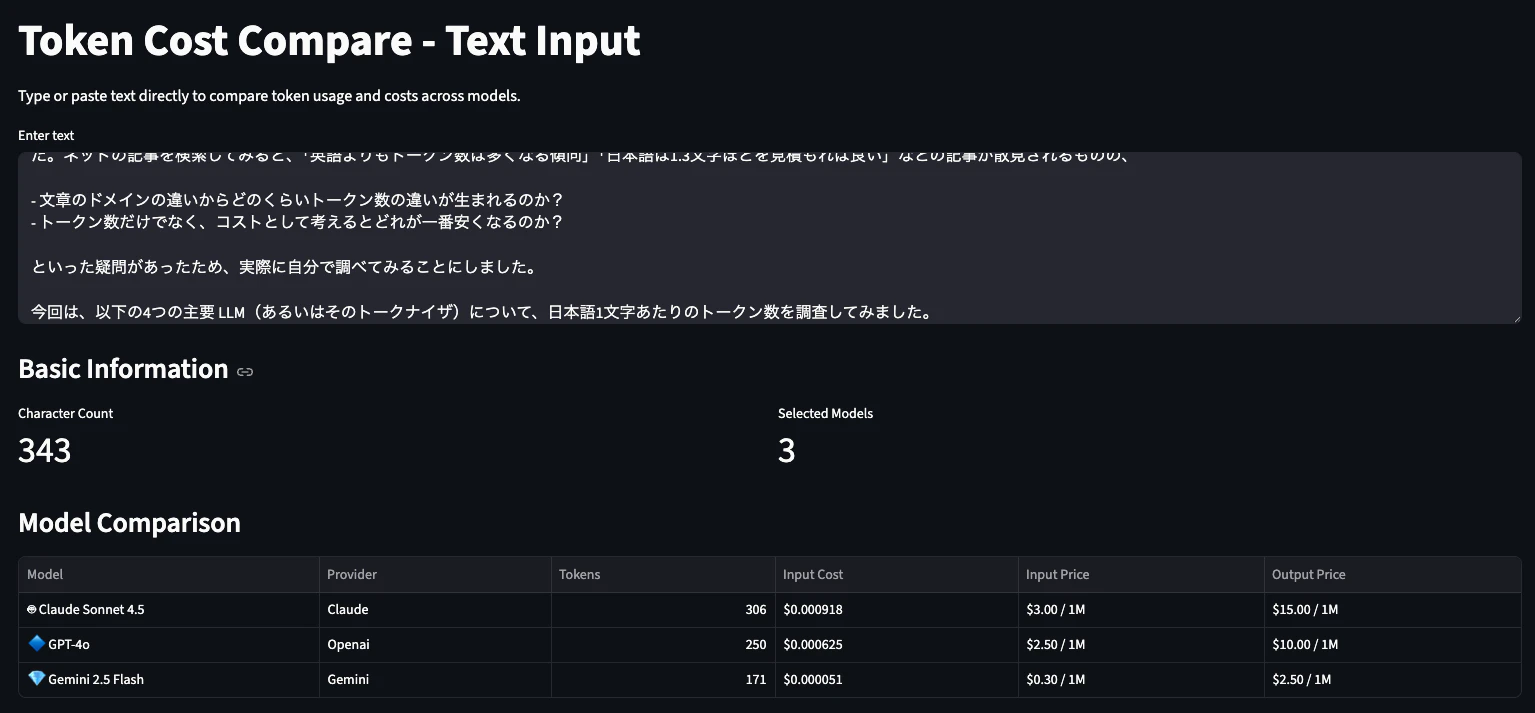
Streamlitで動くアプリ: https://token-cost-compare.streamlit.app/Text_Input
(↑しばらく使われてないと"アプリが起動していません"的な表示になってしまうのですが、青いボタンを押すと使えるようになります)
コード内で使いたい場合は、pipかuvでインストールし、
# pipの場合
$ pip install git+https://github.com/106-/token-cost-compare.git
# uvの場合
$ uv pip install git+https://github.com/106-/token-cost-compare.git
以下のようにコードを書くことでモデルごとにカウントすることができます。
from token_cost_compare import TokenCounter
text = "Hello, world! This is a test message."
counter = TokenCounter(
anthropic_api_key="xxxxxx", # AnthropicのAPI Key
google_api_key="xxxxxx", # AI StudioかVertexAIのAPI Key
xai_api_key="xxxxxx" # xAIのAPI Key
)
# 比較したいモデルたち
models = ["GPT-5", "Claude Sonnet 4.5", "Gemini 2.5 Pro", "Grok 4"]
# 使えるモデルの一覧は
# https://github.com/106-/token-cost-compare/blob/main/src/token_cost_compare/model_registry.py#L9-L33
# にあります
# 比較実行
result = counter.compare(text, models)
display(result)
# [{'success': True,
# 'tokens': 10,
# 'cost': 1.25e-05,
# 'input_price': 1.25,
# 'output_price': 10.0,
# 'model_id': 'gpt-5',
# 'provider': 'openai',
# 'model_name': 'GPT-5'},
# ...
# のように結果が返ってくる
実験結果
さて、実際にトークン数を比較してみます。記事ごと・小説ごとにトークン化し、そのトークン数を文字数で割ったものをプロットします。
ニコニコ大百科
データセット中にある2023年のデータから1,000件分をランダムに抽出し、それでトークン数を調査してみました。データはHTML文章として用意されているため、BeautifulSoupでタグを除外したテキストを作り、そのテキストで調査しました。
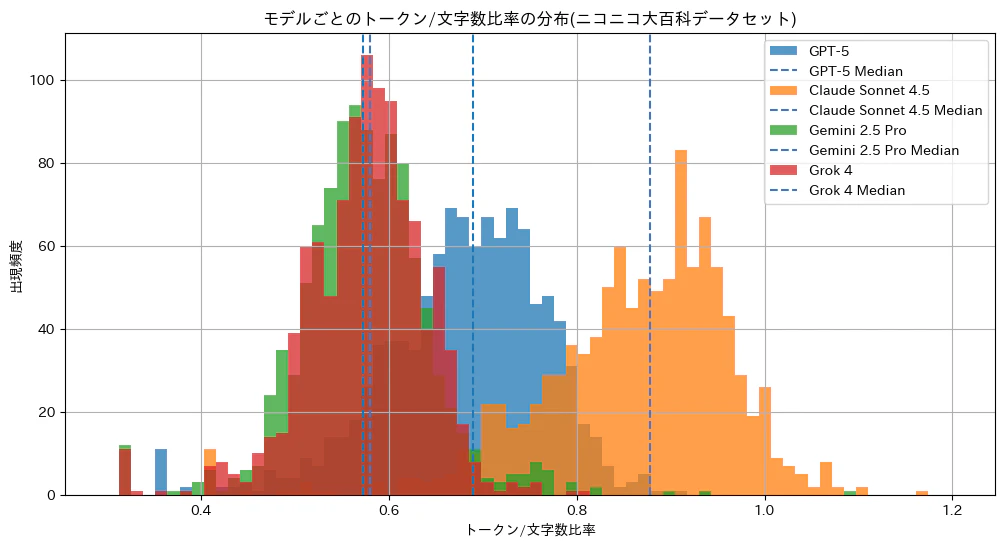
上の図は記事ごとのトークン数を文字数で割ったものの分布を表し、また縦の破線はそれぞれの中央値を表す図となっています。それぞれの色の山は各モデルごとの分布を表し、山が右に移動しているほど文章あたりのトークン数が長くなる傾向にあり、つまりコストもそれに対応して嵩むといえます。
トークン長の順序としてはGeminiとGrokが最も短く、次いでChatGPT、そしてClaudeのようになりました。Gemini/Grokは短めの位置にまとまっている一方、ChatGPTとClaudeはブレが大きめに出ているようです。
| モデル | token/文字 中央値 | 入力: 100万文字あたりコスト | 出力: 100万文字あたりコスト |
|---|---|---|---|
| GPT-5 | 0.68 | $0.85 | $6.80 |
| Claude Sonnet 4.5 | 0.87 | $2.61 | $13.05 |
| Gemini 2.5 Pro | 0.57 | $0.71 | $5.70 |
| Grok 4 | 0.57 | $1.71 | $8.55 |
次に、この中央値からコストを考えてみます。"100万文字あたり"のカラムはこの中央値から、100万文字のテキストを入力/出力した際のコストになります。Geminiはトークン数が短くなる上にトークンあたりのコストも安いため、合わせた相乗効果でかなり安めのコストで利用できそうですね。
気になるのはGeminiとGrokの傾向が奇妙なほど似ているところですが、ChatGPTに教えてもらったところこれは偶然ではなく、両者は同じSentencePieceによってトークン化しているので似るだけの理由はありそうです。
青空文庫
こちらはデータセットから2,000件分を抽出し、そのトークン数を調べました。
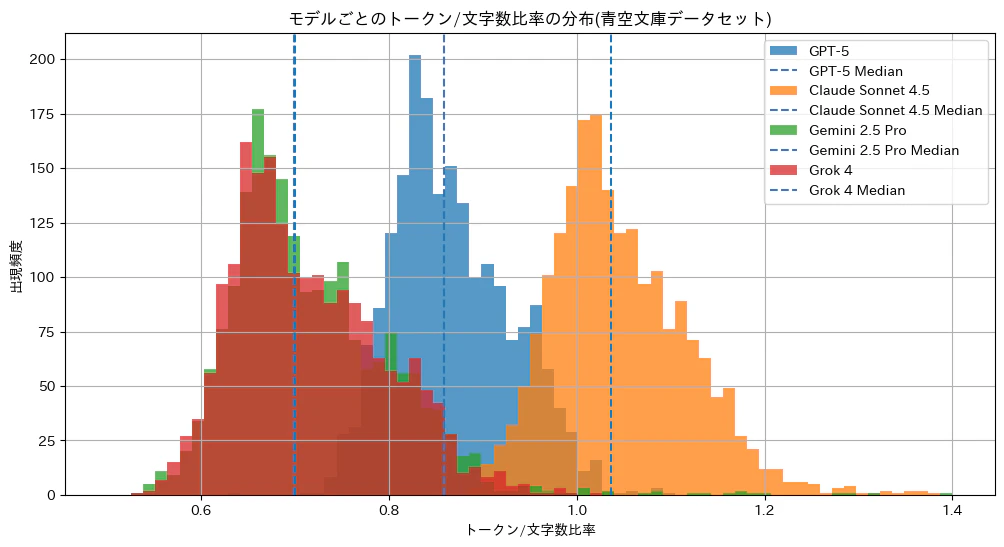
| モデル | token/文字 中央値 | 入力: 100万文字あたり | 出力: 100万文字あたり |
|---|---|---|---|
| GPT-5 | 0.85 | $1.06 | $8.50 |
| Claude Sonnet 4.5 | 1.03 | $3.09 | $15.45 |
| Gemini 2.5 Pro | 0.70 | $0.88 | $7.00 |
| Grok 4 | 0.69 | $2.07 | $10.35 |
全体の傾向として、いずれのモデルもニコニコ大百科のデータよりトークン数が増加しています。Claudeではトークン/文字数比が1.0を超えることも珍しくないようです。そしてこちらでもGeminiとGrokの傾向はかなり似ていると言えそうです。
まとめ
得られた知見として、
- 基本的に
Gemini ≒ Grok < ChatGPT < Claudeの順番にトークン数が増えていく - コストは
Gemini < ChatGPT < Grok < Claudeのように増えていく - ネットの一般的な文章であれば、Gemini/Grokでは一文字→0.57 token、ChatGPT→0.68 token、Claude→0.87 token程度で見積もることができるかも
- 文章のドメインによる違いは思ったよりもあり、トークン数はいずれのLLMサービスでも無料でカウントできるので、気になる場合は前もって調べておくべき
といったところでしょうか。Claudeのコストは嵩みがちであり、その答えとしてトークン数を削減できるとされるOpus4.5が登場したのもなかなか納得の行く流れと言えそうですね。
お読みいただきありがとうございました!