はじめに
LLM(Large Language Model)を簡単に扱うためのLangChainという有名なライブラリがあります。そのライブラリには、いくつかのプロンプトエンジニアリングが既に実装されていますが、本稿では、その中で、RAG(Retrieval-Augmented Generation)と呼ばれるテクニックについて簡単に説明し、LangChainに実装されているRAGにおける文書の絞り込み部分に関し、カスタマイズする方法の一例を説明します。なお、本投稿は、私の忘備録的な面もあり、テストコードには、本質でないコードも含まれていることをご了承ください。
RAGの仕組み
LLMを使った文書群に対する質疑応答方式にRAGがあります。その特徴は、LLMを使っている使っているにも関わらず、情報源となる文書群のサイズが大きくなっても、短時間でその文書群に対する質問の回答が得られる点にあります。
RAGの概要図を以下に示し、簡単にその処理内容を説明します。なお、本図では、Embedding、および、LLMにOpenAIのサービスの利用を想定しています。
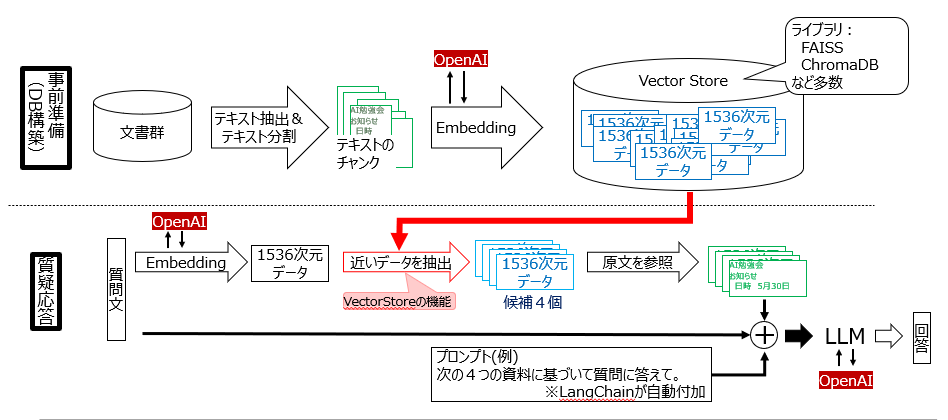
■ 事前準備
-
PDFやHTMLなど各文書からテキスト抽出を行い、ページ単位や一定の文字数毎などにテキストを分割し、テキストチャンクを作ります。チャンクに分割する理由は、LLMのトークン制限に引っかからないようにするためです。
-
テキストチャンク毎にEmbeddingします。図では、OpenAIのtext-embedding-ada-002を利用しています。この場合、各テキストチャンクは、1536次元のベクトルデータに変換されます。
-
変換された1536次元のベクトルデータは、その生成元となったテキストチャックとペアでDBに保存され、のちの検索に備えます。
つまり、事前準備は、文書群をテキストチャンクに分割したのち、それらをEmbeddingしたものをDBに保存する作業になります。
■質疑応答
-
ユーザから質問文が入力されます。
-
質問文を事前準備の時と同じ方法でEmbeddingし、質問文のベクトルデータを取得します。
-
事前準備で作成したDB中の各ベクトルデータの中から、質問文のベクトルデータに近いものを上位N個抽出します。LangChainでは、デフォルトでN=4が設定されています。
-
N個の抽出されたベクトルデータの作成元となる各テキストチャンクを参照します。これらN個のテキストチャンク、および、『これらを参照してユーザの質問文に回答する』ことを指示するプロンプトをLLMに入力し、LLMから回答を得ます。なお、LangChainでは、引数chain_typeで回答作成時のN個のテキストチャンクの利用方法をRetrievalQAのchain_type引数で指定することができます。chain_typeには、"stuff", "map_reduce", "map_rerank", "refine"のいずれかを指定します。
つまり、質疑応答は、まず質問文に近い情報源のテキストチャンクをベクトルデータを用いて検索し、上位N個の抽出されたテキストチャンクに対し、LLMで質問に対する回答を生成する手順になります。
上記のRAGの仕組みは、LangChainに実装されており、簡単に試すことができます。
RAGで期待した回答が得られない?
実際にRAGを試すと、期待した回答が得られないという事象に当たることがあると思います。つまり、欲しい情報は、確実に情報源(文書群)にあるのに、その情報が出てこない・・・。
この場合、まず、上記質疑応答のステップ3でベクトルデータを用いたテキストチャンクの絞り込みで所望の情報が入ったテキストチャンクが抽出されていないことを疑わなければなりません。簡単な対処法として、抽出個数のN=4を増やす方法があります。運が良ければ、それだけで対処ができますが、本質的な解法ではないでしょう。Nを増やせば、LLMへの問合せ回数が増え、回答に時間を要するようになってしまいますし(chain_type="stuff"以外)、最適なNの値も分かりません。
その他、ベクトルデータの類似スコアを参照して、動的にNの値を変更したり、上位N個内で互いに似たテキストチャンクはまとめて一つのテキストチャンクにすることで、実質的にNを増やした効果を狙うなど、様々な対策アイデアが出てくることだと思います。
テキストチャンクからのノイズ除去
上記の問題に対し、ここでは、テキストチャンクに多くのノイズが入っていることが原因であると仮定します。即ち、求める情報の入っているテキストチャンクが、それに含まれるノイズのため、質問文のベクトルデータから遠ざかっている、若しくは、逆に要らないテキストチャンクが、たまたま、ノイズの余計なお世話で質問文のベクトルデータに近づいていると仮定します。これらが発生すると、所望のテキストチャンクが得られにくくなります。
特に、情報源が雑多な大量の文書であった場合、この現象は、多く発生するでしょう。そこで、テキストチャンクをベクトルデータ化するとき、何らかの処理を施し、ノイズを減らすことを考えます。
今回は、LLMを用いて、検索に用いられそうなキーワードを残しながら、ヘッダやフッタ、HTMLにおけるメニュー表示を削除してからベクトルデータを作成することを考えます。その仕組みは、プロンプトを用いてテキストチャンクを校正したのち、ベクトルデータを作成するというものです。
LangChainのRetrievalQAのカスタマイズ
LangChainにはRAGを実装したRetrievalQAというAPIが用意されています。本APIを利用すれば、簡単にRAGを実装できますが、ベクトルデータによる絞り込みに用いるテキストチャンクと、LLMの回答作成時に用いるそれを使い分ける仕組みはまでは用意されていません。幸い、この実現方法の質問が、LangChainの公式GitHubのIssuesに投稿されていました。その回答は、単に、class RetrievalQAWithSourcesChain(BaseQAWithSourcesChain)を参考に自分でクラスを作りなさいとのことでした。
そのクラスは、langchain\chains\qa_with_sources\retrieval.pyで定義されています。そのクラス中の_get_docs()がLLMに渡すためのテキストチャンクを取得する関数であり、これをカスタマイズすることで、目的を達成できそうです。つまり、_get_docs()が呼ばれたとき、
テキストチャンクを加工することで、ベクトルデータ作成時とLLM質問時に用いるテキストチャンクを使い分けることができそうです。
カスタマイズ手順は次の通りです。
- retrieval.pyを自分のプロジェクトにコピーし、ファイル名をmy_retrieval.pyに変更
- クラス名RetrievalQAWithSourcesChainをMyRetrievalQAWithSourcesChainに変更
- テキストチャンクAをベクトルデータ作成時に用いるテキストチャンクBに変更する関数FuncABを作成
- テキストチャンクBをテキストチャンクAに戻す関数FuncBAを作成
- ベクトルデータ作成直前にFuncABを呼び出すコードを挿入
- _get_docs()において、LLMに渡すテキストチャンク取得後にFuncBAを呼び出すコードを挿入
全コードを以下に示します。FuncAB()は、my_summarize_content()の名前で実装してあります。また、FuncBA()は、関数として実装しておらず、直接_get_docs()に埋め込んであります。テストコードでは、FuncABは、doc.page_contentをdoc.metadataに退避させたのち、新しいテキストチャンクをdoc.page_contentに代入する仕様であり、他方、FuncBAは退避したデータをdoc.page_contentに復元する仕様です。また、テストコードでは、通常のRAGを使用する場合と、テキストチャンクを加工する場合のコードの差が分かりやすいように、冒頭のmy_retrieval_switchの変数で、どちらを使うかのスイッチを用意してあります。
# my_retrieval.py
"""Question-answering with sources over an index."""
from concurrent.futures import ThreadPoolExecutor
from typing import Any, Dict, List
# Document.page_contentを要約し、書き換える。
from langchain.chains.summarize import load_summarize_chain
from langchain.docstore.document import Document
from langchain.prompts import PromptTemplate
def my_summarize_content(docs: List[Document], llm) -> Document:
# マルチスレッド用
def summarize_and_replace(chain, doc, count, total):
text_sum = chain.run([doc])
doc.metadata = {"org_metadata": doc.metadata, "org_page_content": doc.page_content}
doc.page_content = text_sum
print(f"終了したスレッド番号:{count + 1} / 全スレッド数{total} \r", end="")
prompt_template = "次の文章は、HTMLデータやPDFなど文書から抽出した非構造化テキストです。このテキストから本文や表構造に注目し、二つ以上の名詞が連結された複合名詞などキーワードとなる単語や説明文や意味を成している文章は削除せず、それらを明示するように、テキストを校正してください。\n###対象のテキスト\n{text}"
summarize_template = PromptTemplate(
template=prompt_template, input_variables=["text"]
)
chain = load_summarize_chain(
llm,
chain_type="stuff",
prompt=summarize_template,
)
# テキストチャンクを加工(マルチスレッドで高速化)
with ThreadPoolExecutor(max_workers=10) as executor:
for count, doc in enumerate(docs):
executor.submit(summarize_and_replace, chain, doc, count, len(docs))
print("\nテキストチャンクの変換を完了")
### オリジナルのRetrieval.pyを改変 ###
(省略:オリジナルのretrieval.pyを参照のこと)
class MyRetrievalQAWithSourcesChain(BaseQAWithSourcesChain):
(省略:オリジナルのretrieval.pyを参照のこと)
def _get_docs(
self, inputs: Dict[str, Any], *, run_manager: CallbackManagerForChainRun
) -> List[Document]:
question = inputs[self.question_key]
docs = self.retriever.get_relevant_documents(
question, callbacks=run_manager.get_child()
)
# page_contentが要約されたものに変更されているので、オリジナルのdocumentに戻す。
new_docs = []
for doc in docs:
doc_replaced = Document(
page_content=doc.metadata["source"]["org_page_content"],
metadata=doc.metadata["source"]["org_metadata"],
)
new_docs.append(doc_replaced)
return self._reduce_tokens_below_limit(new_docs)
(省略:オリジナルのretrieval.pyを参照のこと)
# main.py
import glob
import os
from dotenv import load_dotenv
from langchain.chains import RetrievalQAWithSourcesChain
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import UnstructuredFileLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores.faiss import FAISS
from my_retrieval import MyRetrievalQAWithSourcesChain, my_summarize_content
# 実験用:ベクトルデータ作成用テキストチャンクを加工する(True)か否か(False)のスイッチ
my_retrieval_switch: bool = True
def create_db(llm, embeddings):
# 情報源となる文書群のファイルパスを取得
files_docs = glob.glob("docs/*.pdf", recursive=True)
files_docs += glob.glob("docs/*.html", recursive=True)
# 拡張子に従い、文書を読み出す。
docs = []
for count, file_path in enumerate(files_docs):
# ファイルの拡張子を取得
_, ext = os.path.splitext(file_path)
try:
if ext == ".pdf":
loader = UnstructuredFileLoader(file_path, mode="paged")
doc = loader.load()
# ソース情報にPDFページ番号を追加。
for each_page in doc:
each_page.metadata["source"] += ", p." + str(
each_page.metadata["page_number"]
)
elif ext == ".html":
loader = UnstructuredFileLoader(file_path, mode="single")
doc = loader.load()
# html由来の特殊文字削除
for each_page in doc:
# ゼロ幅スペースを置換する。
# 複合名詞が形成されないようにするため、スペースで置き換える。
each_page.page_content = each_page.page_content.replace(
"\u200b", " "
).replace("\u3000", " ")
# 日本語を考慮してチャンクに分割
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=2000,
chunk_overlap=100,
length_function=len,
separators=["\n\n", "\n", "。", " ", "、", ""],
)
doc_split = text_splitter.split_documents(doc)
# doc内の各文書(PDFではページ単位)をdocsに追加。
docs.extend(doc_split)
except Exception as e:
print(f"テキスト抽出失敗:{file_path}")
print("例外args:", e.args)
if my_retrieval_switch:
# ベクトルデータ作成用テキストチャンクを加工
my_summarize_content(docs, llm)
# Embeddingし、VectorStoreに保存
vectore_store = FAISS.from_texts(
[doc.page_content for doc in docs],
embeddings,
metadatas=[{"source": doc.metadata} for doc in docs],
)
return vectore_store
def qa(vector_store, llm, question):
retriever = vector_store.as_retriever()
retriever.search_kwargs = {"k": 3} # デフォルトのN=4からN=3に変更
if my_retrieval_switch:
chain_each_text = MyRetrievalQAWithSourcesChain.from_chain_type(
llm=llm, retriever=retriever, chain_type="map_reduce"
)
else:
chain_each_text = RetrievalQAWithSourcesChain.from_chain_type(
llm=llm, retriever=retriever, chain_type="map_reduce"
)
result = chain_each_text({"question": question})
print(f"質問:{question}")
result["answer"] = result["answer"].strip("\r\n")
print(f'回答:{result["answer"]}\nソース:{result["sources"]}')
def main():
# open ai key環境変数設定
load_dotenv(r"..\★OPENAI_API_KEY.env")
# 使用するllmを定義
llm = ChatOpenAI(model_name="gpt-4", temperature=0)
embeddings = OpenAIEmbeddings()
# Embedding DBの作成
vector_store = create_db(llm, embeddings)
# Qestion and Answer
qa(vector_store, llm, "全ての休暇の種類を教えて。")
qa(vector_store, llm, "運転業務における注意点を教えて。")
# entry point
if __name__ == "__main__":
main()
RAGを使用した感想
上記のカスタマイズでは、サイドメニューと表構造を持つ複雑なHTMLが情報源に入っていた場合、効果が現れました。ただ、定量的評価は行っていませんので、効果のほどは分かりません。
今回、LangChainのRetrievalQAで特定の情報源に対する質疑応答のLLM応用を体験しました。LangChainを使用すると非常に簡単に実装できる反面、情報源が膨大になると、思うような結果が得られませんでした。そのため、いろいろ実験してみたい内容や改善アイデアがどんどん出てきます。しかし、LangChainを使っている限り、かゆいところに手が届きません。
結局、RAGの仕組み自身は非常に単純なので、FAISS等のVectorStoreライブラリとLLMを使って、自分でRAGをコーディングした方が良いと感じました。その方が、適用先に合わせて自在にカスタマイズでき、精度の高いRAGを構築できると思います。