はじめに
はじめまして!株式会社オークンのUDです!
今回はあまり参考事例がなく、悪戦苦闘したAWS Data Wranglerの使い方について、もっとも使用頻度の高かったawswrangler.s3.to_parquetとawswrangler.athena.read_sql_queryの使い方を中心にまとめてみたいと思います。
使用したもの
- メタデータカタログ:Glue Data Catalog
- データストア:S3
- Athena
- AWS Data Wrangler
- AWS CDK
- direnv
※なお、テーブル定義の変更はAWS Data Wranglerでは行わない前提で、テーブル定義とデプロイはCDKで行いました。
公式ドキュメント
- AWS Data WranglerのAPI Reference
テーブル設計
テーブル設計の観点においても、to_parquetとread_sql_query両方の側面から設計を考える必要がありました。
パフォーマンスと料金面を考慮してテーブル設計を進める上で、大事なポイントについては以下のページにわかりやすくまとめられています。
上記のページからは見えないつまずきポイントも含めて、テーブル設計で考慮した方が良い主要なポイントをまとめると、次のような内容になります。
| 項目 | Athena | S3 |
|---|---|---|
| 主にかかる料金 | ・スキャンしたデータ1TBにつき5ドル ※別リージョンからデータを読み込むと、S3のデータ転送量がかかるため注意 |
・ストレージの料金 ・PUTの料金 |
| AWS Data Wranglerで主に使用する関数 | awswrangler.athena.read_sql_query | awswrangler.s3.to_parquet 等 |
| 列指向ファイル形式の活用 | 列指向フォーマットの活用し、SELECTする列を指定する事で、指定された列のみをスキャンすることができ、スキャン量を減らせる | ー |
| ファイル圧縮の活用 | snappy等の形式にファイルを圧縮する事で、スキャンするデータ量を減らせる | 圧縮することでストレージ料金が抑えられる |
| パーティションの活用 | WHERE文でよく使用するカラムをパーティションにする事で、スキャン量が減らせる | ・並列処理でto_parquetを使用している場合は、modeをappendにするか、overwrite_partitionsでパーティション設計を並列処理に耐えうるようにする必要がある ・パーティションが多いとPUT回数が増える ※to_parquetもパーティション別に1オブジェクトずつPUTする |
| オブジェクトサイズの目安 | ー | ・ファイルサイズが小さすぎる場合、読み取り処理のオーバーヘッドに時間を費やす事になるため、128MB以上が目安とされている ・S3の料金体系として、128KB以下のオブジェクトは一律で128KBとしてカウントされるため、小さすぎるともったいない |
AWS Data Wranglerの使い方に関するポイント
credentialsの読み込み
AWS Data Wranglerのあらゆる関数の引数で指定することができるboto3_sessionですが、その名の通り、実態はboto3のSessionです。
AWS Data Wranglerの各関数の引数でboto3_sessionを指定しない場合、デフォルトでセットされているSession(DEFAULT_SESSION)を参照します。
DEFAULT_SESSIONは内部的に生成されますが、生成プロセスは様々です。
credentialsが読み込まれる優先順位については、こちらにまとめられています。
例えば、各関数の引数でboto3_sessionを指定せずとも、環境変数からaws_access_key_id、aws_secret_access_key、aws_session_token、aws_default_regionを読み込み、DEFAULT_SESSIONを生成することが可能です。
# 環境変数(.envrcの場合)
export AWS_ACCESS_KEY_ID=""
export AWS_SECRET_ACCESS_KEY=""
export AWS_SESSION_TOKEN=""
export AWS_DEFAULT_REGION=""
# awswrangler.athena.read_sql_query使用箇所
import awswrangler as wr
def sample_def():
query = 'SELECT * FROM sample_table'
wr.athena.read_sql_query(
database='sample_database',
sql=query,
ctas_approach=False,
# boto3_session=, ← 不要になる
max_cache_seconds=0,
max_cache_query_inspections=50,
max_remote_cache_entries=50,
max_local_cache_entries=100,
)
Global Configurationsの活用
AWS Data Wranglerのチュートリアルに記載のあるGlobal Configurationsを使用すると、上記read_sql_queryの各種設定を共通化することが可能です。
import awswrangler as wr
def init_config():
# database名
wr.config.database = "sample_database"
# CTASを有効にするか
wr.config.ctas_approach = False
# 以下、read_sql_query実行時の各種キャッシュに関する設定
wr.config.max_cache_seconds = 0
wr.config.max_cache_query_inspections = 50
wr.config.max_remote_cache_entries = 50
wr.config.max_local_cache_entries = 100
def sample_def():
query = 'SELECT * FROM sample_table'
wr.athena.read_sql_query(
sql=query,
)
if __name__ == "__main__":
init_config()
sample_def()
read_sql_queryのctas_approachについて
awswrangler.athena.read_sql_queryのctas_approachをTrueにするとCTASが有効になり、一時テーブルがGlue上に作成され、クエリ結果がS3に他のストレージ形式 (Parquet、ORC など) として保存されます。
このクエリ結果を参照することによりAthenaのパフォーマンスが向上するため、クエリの結果が中〜大規模になる場合は高速となります。
ただし、一時テーブルをGlue上に作成する必要があるため、Glueでのテーブルの作成・削除権限が必要になります。
to_parquetのmodeについて
MYSQL等のRDBに慣れている方は、RDBをイメージしながら実装を進めると痛い目を見ます…。何度データが消えたことか…。
データの実態はあくまでS3のオブジェクトですので、appendはファイルのcreate、overwrite系はファイルのdelete&createが行われている事がイメージできていると理解しやすいと思います。
| mode | 仕様・注意点 |
|---|---|
| append | ・to_parquetの度にバケットまたはパーティションにオブジェクトが追加される |
| overwrite | ・バケットまたは全てのパーティションのオブジェクトをdeleteした後に、新しいオブジェクトを作成する ・パーティションを含む場合は、Glueのパーティション情報も更新される ※全てのパーティションのオブジェクトが一度deleteされるため、誤って消滅してしまわないように、実装・開発上は細心の注意が必要 |
| overwrite_partitions | ・対象のパーティション配下のオブジェクトをdeleteした後に、新しいオブジェクトを作成する ・パーティションを含む場合は、Glueのパーティション情報も更新される |
to_parquetと合わせて使用したい関数
modeがoverwriteの場合、テーブル定義の変更もto_parquet時に行えてしまいますが、テーブルの定義変更をto_parquet時に行わない場合、wr.catalog.get_table_locationでデータセットのパスを取得し、wr.catalog.get_table_typesで列名とデータ型がセットになったdictを取得すると処理が楽になります。
例えば、とあるビデオストリーミングサービスで扱っているテーブルが次のような構造をしていた場合
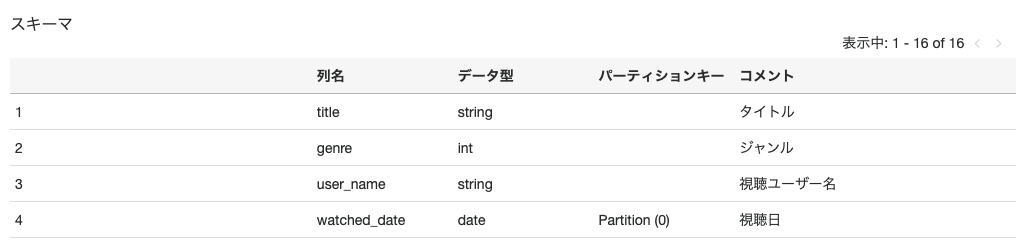
to_parquetを行う場合は次のようなコードになります。
import awswrangler as wr
from datetime import datetime
import pandas as pd
def init_config():
# database名
wr.config.database = "sample_database"
def sample_to_parquet():
# サンプルのdataframeを作成
watched_date = datetime(2021, 12, 20).date()
dict_watched_history = dict(
title=['スターウォーズ', 'キングスマン', 'インセプション'],
genre=['SF', 'アクション', 'サスペンス'],
user_name=['太郎', 'Mr.SASUKE', 'UD'],
watched_date=[watched_date, watched_date, watched_date]
)
df = pd.DataFrame(data=dict_watched_history)
# テーブル名
table_name = 'sample_watched_video_history'
# datasetとして指定しているS3のパスを取得
s3_dataset_location_path = wr.catalog.get_table_location(table=table_name)
# テーブル定義からdtypeを取得
dtype = wr.catalog.get_table_types(table=table_name)
# to_parquet処理
wr.s3.to_parquet(
df=df,
path=s3_dataset_location_path,
dataset=True,
table=table_name,
mode='overwrite_partitions',
dtype=dtype,
schema_evolution=False,
partition_cols=['watched_date']
)
if __name__ == "__main__":
init_config()
sample_to_parquet()
おわりに
上記は、クローラを使用しないかなり限定的な利用用途にはなりますが、同じような使い方をされる方の参考になれば幸いです。
次回は、to_parquetしたオブジェクトのロールバックについて、悪戦苦闘した内容を書きたいと思います。