Hara, Kensho, Hirokatsu Kataoka, and Yutaka Satoh. "Learning spatio-temporal features with 3D residual networks for action recognition." Proceedings of the ICCV Workshop on Action, Gesture, and Emotion Recognition. Vol. 2. No. 3. 2017.
1.どんなもの?
ResNetsを拡張して3DCNNに適用
ActivityNetおよびKineticsデータセットを3D ResNetsで評価
Kineticsで訓練された3D ResNetsは、C3Dなどの比較的浅いネットワークより優れた結果が得られた
2.先行研究と比べてどこがすごいの?
動画像認識のアプローチには2DCNNを用いたtwo-streamやC3Dがある
3DCNNは、2DCNNのアーキテクチャに比べて比較的浅いが2DCNNの手法と互角である
ResNetsを3DCNNに適用することで,3DCNNより深く収束時の損失も小さくなることが期待できる(I3Dのinceptionよりもいい結果が期待できる)
3.技術や手法のキモはどこにあるか?
入力データ
50%の確率で画像が反転
ランダムに選択したところの16フレーム
画像を角4つと中心から選んでクロップして3×16×112×112の形にする
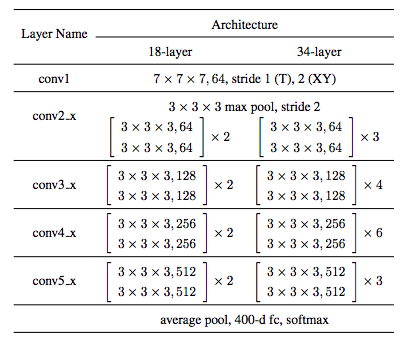
3DResNets
ResNetの18層版と34層版で実装
畳み込みカーネル:3x3x3
各畳み込み層の後にバッチ正規化とReLU
※第一層はC3D同様,時間情報を潰さないように時間方向のストライドサイズは1
最適化手法:SGD
学習率:0.1 収束したら1/10にする
4.どうやって有効だと検証した?
ActivityNetとKineticsデータセットを使用
ActivitityNetはResNet18層版で実装→C3Dの方がいい結果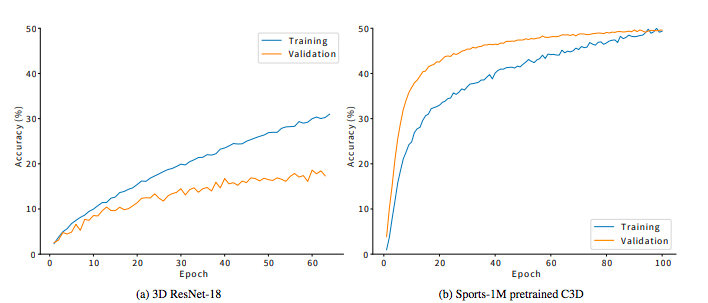
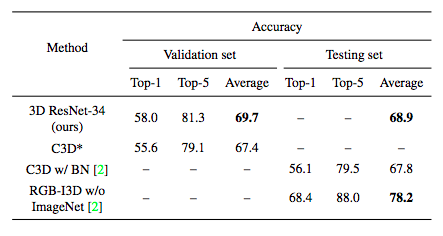
KineticsデータセットではResNet34層で実装→ResNet版がいい結果
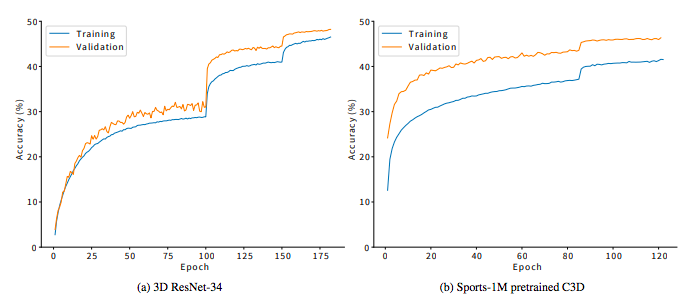
C3Dが浅すぎることを示している.3DResNetsはKineticsデータセットを使用するときに適している.
5.議論はあるか?
RGB-I3Dがいい結果を出しているが,GPUのメモリの問題のため,3×16×112×112であるのに対して、RGB-I3Dのサイズは3×64×224×224である.高空間分解能および時間的長さが高いため、認識精度が向上すると考えられる.